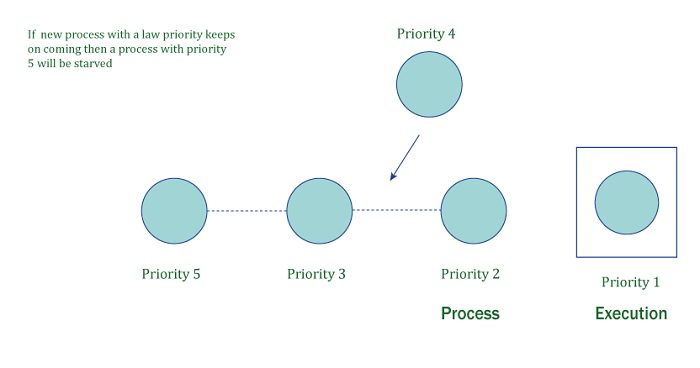
운영 체제 및 동시성 프로그래밍에서 중요한 문제로, 특정 프로세스가 필요한 자원을 지속적으로 얻지 못해 실행되지 못하는 상황. 자원 관리 문제로, 낮은 우선순위 프로세스가 높은 우선순위 프로세스에 의해 자원이 계속 점유되어 무기한 대기하는 상황으로 주로 우선순위 기반 스케줄링에서 발생하며, 시스템 성능과 공정성에 부정적인 영향을 미친다.
importthreadingimportqueueimporttimefromdataclassesimportdataclassfromtypingimportOptionalimportrandom@dataclassclassTask:id:intpriority:intcreation_time:floatwait_time:float=0defupdate_wait_time(self):self.wait_time=time.time()-self.creation_timedefshould_boost_priority(self)->bool:"""우선순위 부스팅이 필요한지 확인"""returnself.wait_time>10# 10초 이상 대기시 부스팅classFairScheduler:def__init__(self):self.high_priority_queue=queue.PriorityQueue()self.low_priority_queue=queue.PriorityQueue()self.lock=threading.Lock()self.running=Truedefadd_task(self,task:Task):"""작업 추가"""withself.lock:iftask.priority>5:self.high_priority_queue.put((-task.priority,task))else:self.low_priority_queue.put((-task.priority,task))defprocess_tasks(self):"""작업 처리"""whileself.running:next_task=self._get_next_task()ifnext_task:self._execute_task(next_task)def_get_next_task(self)->Optional[Task]:"""다음 처리할 작업 선택"""withself.lock:# 모든 낮은 우선순위 작업 검사 및 부스팅low_priority_tasks=[]whilenotself.low_priority_queue.empty():_,task=self.low_priority_queue.get()task.update_wait_time()iftask.should_boost_priority():print(f"Boosting priority of task {task.id}")task.priority=10# 우선순위 부스팅self.high_priority_queue.put((-task.priority,task))else:low_priority_tasks.append((-task.priority,task))# 낮은 우선순위 작업 다시 큐에 넣기fortask_tupleinlow_priority_tasks:self.low_priority_queue.put(task_tuple)# 높은 우선순위 큐에서 먼저 확인ifnotself.high_priority_queue.empty():returnself.high_priority_queue.get()[1]# 낮은 우선순위 큐에서 확인ifnotself.low_priority_queue.empty():returnself.low_priority_queue.get()[1]returnNonedef_execute_task(self,task:Task):"""작업 실행"""print(f"Executing task {task.id} (Priority: {task.priority}, "f"Wait time: {task.wait_time:f}s)")# 작업 실행 시뮬레이션time.sleep(random.uniform(0.1,0.5))defsimulate_starvation():"""기아 상태 시뮬레이션"""scheduler=FairScheduler()# 스케줄러 실행 스레드scheduler_thread=threading.Thread(target=scheduler.process_tasks)scheduler_thread.start()# 높은 우선순위 작업 지속적 생성defgenerate_high_priority_tasks():task_id=0whilescheduler.running:task=Task(id=task_id,priority=random.randint(7,10),creation_time=time.time())scheduler.add_task(task)task_id+=1time.sleep(random.uniform(0.1,0.3))# 낮은 우선순위 작업 생성defgenerate_low_priority_tasks():task_id=1000# 구분을 위한 시작 IDwhilescheduler.running:task=Task(id=task_id,priority=random.randint(1,4),creation_time=time.time())scheduler.add_task(task)task_id+=1time.sleep(random.uniform(0.5,1.0))# 작업 생성 스레드 시작high_priority_generator=threading.Thread(target=generate_high_priority_tasks)low_priority_generator=threading.Thread(target=generate_low_priority_tasks)high_priority_generator.start()low_priority_generator.start()# 일정 시간 후 시뮬레이션 종료time.sleep(30)scheduler.running=False# 모든 스레드 종료 대기scheduler_thread.join()high_priority_generator.join()low_priority_generator.join()if__name__=="__main__":simulate_starvation()