Event Brokers
이벤트 브로커는 현대 분산 시스템과 마이크로서비스 아키텍처의 핵심 구성 요소로, 비동기 통신과 시스템 간 느슨한 결합을 가능하게 한다. Event Broker 는 이벤트 생성자 (Producer) 와 이벤트 소비자 (Consumer) 사이에서 중개자 역할을 수행한다.

이벤트 브로커 기초 개념
이벤트 브로커란?
이벤트 브로커는 이벤트 생산자 (Producer) 와 소비자 (Consumer) 사이에서 메시지를 중개하는 미들웨어이다. 생산자는 이벤트를 발행 (publish) 하고, 소비자는 관심 있는 이벤트를 구독 (subscribe) 하는 발행 - 구독 (Pub/Sub) 패턴을 기반으로 한다.
이벤트 브로커의 핵심 기능
- 메시지 라우팅: 적절한 소비자에게 메시지 전달
- 메시지 버퍼링: 일시적인 부하 증가나 소비자 장애 시 메시지 임시 저장
- 메시지 필터링: 특정 조건에 맞는 메시지만 전달
- 메시지 변환: 필요에 따라 메시지 형식 변환
- 신뢰성 보장: 메시지 전달 보장, 순서 유지 등
이벤트 브로커의 주요 이점
- 느슨한 결합 (Loose Coupling): 생산자와 소비자가 서로를 직접 알 필요 없음
- 확장성 (Scalability): 시스템 구성 요소를 독립적으로 확장 가능
- 탄력성 (Resilience): 일부 서비스 실패 시에도 전체 시스템 작동 가능
- 비동기 처리: 즉각적인 응답이 필요 없는 작업의 효율적 처리
주요 이벤트 브로커 시스템 비교
Apache Kafka
특징:
- 높은 처리량과 내구성 제공
- 분산 커밋 로그 아키텍처
- 메시지 순서와 내구성 보장
- 파티션 기반 확장성
적합한 사용 사례:
- 대용량 로그 처리
- 실시간 데이터 파이프라인
- 이벤트 소싱 아키텍처
- 장기간 메시지 보존 필요 시
RabbitMQ
특징:
- AMQP 프로토콜 구현
- 다양한 메시징 패턴 (라우팅, 토픽, RPC 등) 지원
- 관리 용이성
- 플러그인 시스템
적합한 사용 사례:
- 복잡한 라우팅 요구사항
- 우선순위 큐
- 지연 메시지 처리
- 다양한 프로토콜 지원 필요 시
Apache Pulsar
특징:
- 멀티 테넌트 아키텍처
- 저장소와 브로커 계층 분리
- 무제한 메시지 보존
- Kafka 와 RabbitMQ 의 장점 결합
적합한 사용 사례:
- 멀티 테넌트 환경
- 지역 간 복제 필요 시
- 장기 데이터 보존과 스트리밍 처리 결합
NATS
특징:
- 초경량 아키텍처
- 낮은 지연 시간
- 간단한 설정과 운영
- 서비스 발견 기능 내장
적합한 사용 사례:
- 클라우드 네이티브 애플리케이션
- IoT 장치 통신
- 실시간 서비스 간 통신
AWS SNS/SQS, Google Pub/Sub, Azure Service Bus
특징:
- 관리형 서비스 (서버리스)
- 클라우드 제공업체 통합
- 자동 확장 및 관리
적합한 사용 사례:
- 해당 클라우드 플랫폼에서 운영되는 시스템
- 인프라 관리 부담 최소화 필요 시
실무 구현 가이드
Apache Kafka 구현 예제
기본 설정:
| |
Java 생산자 코드:
| |
Java 소비자 코드:
| |
Spring Boot 에서의 Kafka 사용 예제
의존성 설정 (build.gradle):
애플리케이션 설정 (application.yml):
| |
이벤트 모델:
이벤트 생산자 서비스:
| |
이벤트 소비자 서비스:
| |
심화 주제
이벤트 스트리밍과 처리
Kafka Streams 사용 예제
| |
이벤트 소싱 (Event Sourcing) 패턴
이벤트 소싱은 시스템의 상태 변화를 이벤트 시퀀스로 저장하는 패턴이다.
이벤트 소싱 구현 예제:
| |
장애 복구 및 내구성 전략
메시지 전달 보장 수준
- 최대 한 번 전달 (At most once)
- 메시지가 전달되지 않을 수 있음
- 성능이 중요하고 데이터 손실이 허용되는 경우
- 최소 한 번 전달 (At least once)
- 메시지가 중복 전달될 수 있음
- 소비자 측에서 멱등성 처리 필요
- Kafka 의 기본 모드
- 정확히 한 번 전달 (Exactly once)
- 가장 엄격한 보장 수준
- 트랜잭션 및 멱등성 프로듀서 사용
- 성능 비용 증가
Kafka 의 내구성 설정
| |
대규모 분산 시스템에서의 이벤트 브로커 활용
멀티 데이터 센터 복제
Kafka MirrorMaker 2.0 설정 예시:
스트리밍 데이터 파이프라인 구축
Kafka Connect 로 데이터 파이프라인 구축:
| |
이벤트 브로커 설계 및 운영 모범 사례
토픽 설계 원칙
- 문제 도메인 기반 토픽 정의
- 비즈니스 도메인 개념과 일치하는 토픽 네이밍
- 예:
orders,payments,inventory-changes
- 적절한 파티션 수 결정
- 처리량에 맞는 파티션 수 설정
- 파티션 수 = 목표 처리량 / 단일 파티션 처리량
- 파티션 수가 많을수록 관리 복잡성 증가
- 효과적인 키 선택
- 관련 이벤트가 같은 파티션에 들어가도록 키 선택
- 예: 주문 ID 를 키로 사용하여 주문 관련 이벤트 순서 보장
최적화
- 배치 처리 활용
- 프로듀서:
batch.size,linger.ms조정 - 소비자: 적절한
fetch.min.bytes,fetch.max.wait.ms설정
- 프로듀서:
- 압축 사용
- 네트워크 대역폭 절약 및 처리량 향상
compression.type=snappy또는lz4권장
- 적절한 버퍼 크기 설정
- 프로듀서:
buffer.memory - 소비자:
fetch.max.bytes
- 프로듀서:
모니터링 및 알림 전략
핵심 메트릭 모니터링
- 브로커 레벨: CPU, 메모리, 디스크 I/O, 네트워크 I/O
- 토픽 레벨: 처리량 (초당 메시지 수), 지연 시간, 복제 지연
- 소비자 그룹 레벨: 소비자 지연 (Consumer lag), 처리 시간
Prometheus 및 Grafana 를 활용한 모니터링 시스템 구축
알림 규칙 설정
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21# Prometheus 알림 규칙 예시 groups: - name: kafka_alerts rules: - alert: KafkaConsumerLagHigh expr: kafka_consumergroup_lag > 10000 for: 10m labels: severity: warning annotations: summary: "Kafka consumer lag high" description: "Consumer group {{ $labels.consumergroup }} on topic {{ $labels.topic }} has lag of {{ $value }} messages" - alert: KafkaBrokerDown expr: kafka_server_active_controller_count == 0 for: 1m labels: severity: critical annotations: summary: "Kafka broker down" description: "No active controller in the Kafka cluster"
확장성 및 고가용성 설계
클러스터 크기 결정
- 데이터 보존 기간, 복제 인수, 메시지 크기, 처리량 고려
- 용량 계획:
(메시지 수/초 × 평균 메시지 크기 × 보존 기간 × 복제 인수) / 브로커 수
파티션 재할당 전략
1 2 3 4 5 6 7 8 9 10# 파티션 재분배 계획 생성 cat > reassign.json << EOF { "version": 1, "partitions": [ {"topic": "high-volume-topic", "partition": 0, "replicas": [1,2,3]}, {"topic": "high-volume-topic", "partition": 1, "replicas": [2,3,1]}, {"topic": "high-volume-topic", "partition": 2, "replicas": [3,1,2]} ] }
EOF
# 파티션 재분배 실행
kafka-reassign-partitions.sh --bootstrap-server kafka:9092 \
--reassignment-json-file reassign.json --execute
```
롤링 재시작 및 무중단 업그레이드
실제 사례 연구 및 문제 해결
대용량 로그 처리 시스템
요구사항:
- 초당 10 만 로그 메시지 처리
- 7 일간 로그 보존
- 로그 타입별 처리 로직 분리
해결책:
토픽 설계:
- 로그 타입별 토픽 생성:
app-logs,system-logs,security-logs - 각 토픽 24 개 파티션으로 시작 (확장성 확보)
- 로그 타입별 토픽 생성:
프로듀서 설정:
1 2 3 4 5 6 7 8 9Properties props = new Properties(); props.put("bootstrap.servers", "kafka1:9092,kafka2:9092,kafka3:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("compression.type", "lz4"); props.put("batch.size", 65536); // 64KB props.put("linger.ms", 10); // 10ms 대기 시간으로 배치 처리 props.put("buffer.memory", 67108864); // 64MB props.put("acks", "1"); // 리더만 확인 (처리량 중시)소비자 그룹 설계:
- 로그 유형별 소비자 그룹 구성
- 각 소비자 그룹 내 인스턴스 수 = 파티션 수
- 탄력적인 스케일링을 위한 Kubernetes StatefulSet 사용
로그 처리 파이프라인:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32// 로그 처리 소비자 예시 @KafkaListener(topics = "app-logs", groupId = "app-logs-processor") public void process(ConsumerRecord<String, String> record) { try { LogEvent logEvent = parseLogEvent(record.value()); // 로그 레벨에 따른 처리 switch (logEvent.getLevel()) { case "ERROR": alertingService.sendAlert(logEvent); break; case "WARN": anomalyDetector.analyze(logEvent); break; } // Elasticsearch에 저장 elasticsearchClient.index( IndexRequest.of(i -> i .index("app-logs-" + logEvent.getDate()) .id(record.key()) .document(logEvent) ) ); } catch (Exception e) { // 에러 로깅 및 처리 log.error("로그 처리 중 오류 발생: " + record.key(), e); // 오류 토픽으로 전송 (DLQ 패턴) kafkaTemplate.send("app-logs-errors", record.key(), record.value() + "||ERROR:" + e.getMessage()); } }
마이크로서비스 간 통신 시스템
요구사항:
- 주문 처리 시스템 내 마이크로서비스 간 통신
- 각 서비스의 독립적 배포와 확장
- 서비스 장애 시에도 시스템 지속 운영
해결책:
토픽 설계:
- 도메인 이벤트별 토픽:
orders,payments,inventory,shipping - 명령 토픽:
order-commands,payment-commands등
- 도메인 이벤트별 토픽:
이벤트 중심 아키텍처 구현:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97// 주문 생성 핸들러 @RestController public class OrderController { @Autowired private KafkaTemplate<String, OrderEvent> kafkaTemplate; @PostMapping("/orders") public ResponseEntity<OrderCreatedResponse> createOrder(@RequestBody CreateOrderRequest request) { // 주문 ID 생성 String orderId = UUID.randomUUID().toString(); // 주문 생성 이벤트 OrderCreatedEvent event = OrderCreatedEvent.builder() .orderId(orderId) .customerId(request.getCustomerId()) .items(request.getItems()) .totalAmount(calculateTotal(request.getItems())) .status("CREATED") .timestamp(LocalDateTime.now()) .build(); // 이벤트 발행 kafkaTemplate.send("orders", orderId, event) .addCallback( result -> log.info("주문 이벤트 발행 성공: " + orderId), ex -> log.error("주문 이벤트 발행 실패: " + orderId, ex) ); // 응답 반환 return ResponseEntity.accepted().body(new OrderCreatedResponse(orderId)); } } // 재고 서비스의 주문 이벤트 소비자 @Service public class InventoryEventHandler { @Autowired private InventoryService inventoryService; @Autowired private KafkaTemplate<String, InventoryEvent> kafkaTemplate; @KafkaListener(topics = "orders", groupId = "inventory-service") public void handleOrderEvent(OrderCreatedEvent event) { try { // 재고 확인 및 할당 boolean allItemsAvailable = inventoryService.reserveItems(event.getItems()); // 결과 이벤트 발행 InventoryEvent resultEvent; if (allItemsAvailable) { resultEvent = new InventoryReservedEvent( event.getOrderId(), event.getItems()); } else { resultEvent = new InventoryShortageEvent( event.getOrderId(), inventoryService.findUnavailableItems(event.getItems())); } kafkaTemplate.send("inventory", event.getOrderId(), resultEvent); } catch (Exception e) { log.error("재고 처리 중 오류: " + event.getOrderId(), e); // 재시도 로직 또는 오류 이벤트 발행 } } } // 주문 조정 서비스 (오케스트레이터) @Service public class OrderOrchestratorService { // 다양한 이벤트 구독 후 주문 상태 업데이트 @KafkaListener(topics = "inventory", groupId = "order-orchestrator") public void handleInventoryEvent(InventoryEvent event) { if (event instanceof InventoryReservedEvent) { // 결제 명령 발행 initiatePaymentProcess(event.getOrderId()); } else if (event instanceof InventoryShortageEvent) { // 주문 취소 이벤트 발행 sendOrderCancellationEvent(event.getOrderId(), "재고 부족: " + ((InventoryShortageEvent) event).getUnavailableItems()); } } @KafkaListener(topics = "payments", groupId = "order-orchestrator") public void handlePaymentEvent(PaymentEvent event) { if (event instanceof PaymentSucceededEvent) { // 배송 명령 발행 initiateShippingProcess(event.getOrderId()); } else if (event instanceof PaymentFailedEvent) { // 주문 취소 및 재고 롤백 sendOrderCancellationEvent(event.getOrderId(), "결제 실패: " + ((PaymentFailedEvent) event).getReason()); rollbackInventory(event.getOrderId()); } } }내구성 및 재시도 메커니즘:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41// 멱등 소비자 설계 @Service public class IdempotentConsumer<T> { @Autowired private JdbcTemplate jdbcTemplate; public boolean processOnce(String eventId, String consumerGroup, Consumer<T> processor, T event) { // 처리 이력 확인 boolean alreadyProcessed = checkIfProcessed(eventId, consumerGroup); if (!alreadyProcessed) { try { // 이벤트 처리 processor.accept(event); // 처리 이력 기록 markAsProcessed(eventId, consumerGroup); return true; } catch (Exception e) { log.error("이벤트 처리 실패: " + eventId, e); throw e; } } else { log.info("이미 처리된 이벤트: " + eventId); return false; } } private boolean checkIfProcessed(String eventId, String consumerGroup) { Integer count = jdbcTemplate.queryForObject( "SELECT COUNT(*) FROM processed_events WHERE event_id = ? AND consumer_group = ?", Integer.class, eventId, consumerGroup); return count != null && count > 0; } private void markAsProcessed(String eventId, String consumerGroup) { jdbcTemplate.update( "INSERT INTO processed_events (event_id, consumer_group, processed_at) VALUES (?, ?, ?)", eventId, consumerGroup, new Timestamp(System.currentTimeMillis())); } }
실시간 분석 및 대시보드 시스템
요구사항:
- 웹사이트 사용자 활동 실시간 분석
- 세션별 사용자 행동 추적
- 실시간 KPI 대시보드
해결책:
데이터 파이프라인 설계:
- 원시 이벤트 수집 토픽:
user-activities - 세션별 집계 토픽:
user-sessions - 지표별 집계 토픽:
real-time-metrics
- 원시 이벤트 수집 토픽:
Kafka Streams 처리 로직:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86public class UserActivityProcessor { public static void main(String[] args) { Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "user-activity-processor"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka:9092"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); // 활동 이벤트 스트림 생성 KStream<String, String> activityEvents = builder.stream("user-activities"); // 이벤트 유형별 분리 KStream<String, String>[] branches = activityEvents.branch( // 페이지 조회 이벤트 (key, value) -> value.contains("\"type\":\"page_view\""), // 클릭 이벤트 (key, value) -> value.contains("\"type\":\"click\""), // 검색 이벤트 (key, value) -> value.contains("\"type\":\"search\""), // 기타 이벤트 (key, value) -> true ); // 페이지뷰 집계 branches[0] .map((key, value) -> extractUserIdAndPage(value)) .groupByKey() .windowedBy(TimeWindows.of(Duration.ofMinutes(1))) .count() .toStream() .map((windowedKey, count) -> { String metricKey = "pageviews_" + windowedKey.key() + "_" + formatWindowTime(windowedKey.window()); return KeyValue.pair(metricKey, String.valueOf(count)); }) .to("real-time-metrics"); // 세션별 활동 집계 activityEvents .groupByKey() .windowedBy(SessionWindows.with(Duration.ofMinutes(30))) .aggregate( // 세션 초기값 () -> "[]", // 이벤트 추가 집계 함수 (sessionId, event, sessionEvents) -> appendEvent(sessionEvents, event), // 세션 병합 함수 (대부분의 경우 사용되지 않음) (key, session1, session2) -> mergeSessionEvents(session1, session2), // 세션 이벤트 저장에 JSON Serde 사용 Materialized.with(Serdes.String(), Serdes.String()) ) .toStream() .map((windowedKey, events) -> { String sessionKey = windowedKey.key() + "_" + formatWindowTime(windowedKey.window()); return KeyValue.pair(sessionKey, events); }) .to("user-sessions"); // 실시간 전환율 계산 KStream<String, Double> conversionRates = activityEvents .groupByKey() .windowedBy(TimeWindows.of(Duration.ofMinutes(5))) .aggregate( () -> new PageConversionTracker(), (key, event, tracker) -> tracker.trackEvent(event), Materialized.with(Serdes.String(), new JsonSerde<>(PageConversionTracker.class)) ) .toStream() .map((windowedKey, tracker) -> { String metricKey = "conversion_rate_" + formatWindowTime(windowedKey.window()); return KeyValue.pair(metricKey, tracker.calculateConversionRate()); }); conversionRates.to("real-time-metrics", Produced.with(Serdes.String(), Serdes.Double())); // 토폴로지 생성 및 스트림 시작 KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); // 종료 처리 Runtime.getRuntime().addShutdownHook(new Thread(streams::close)); } // 헬퍼 메소드들 (JSON 파싱, 키 추출, 세션 병합 등) }Elasticsearch 로 집계 데이터 전송:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17// Kafka Connect Elasticsearch 싱크 설정 { "name": "metrics-elasticsearch-sink", "config": { "connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", "tasks.max": "1", "topics": "real-time-metrics", "connection.url": "http://elasticsearch:9200", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false", "key.ignore": "false", "schema.ignore": "true", "type.name": "metrics", "behavior.on.null.values": "delete" } }Grafana 대시보드 구현:
- Elasticsearch 데이터 소스 추가
- 실시간 업데이트 대시보드 구성
- 시각화 패널:
- 페이지뷰 트렌드
- 전환율 게이지
- 활성 사용자 수
- 세션 지속 시간 분포
이벤트 브로커 선택 가이드
최적의 이벤트 브로커 선택은 다음 요소에 따라 달라진다:
- 데이터 양과 처리량 요구사항
- 대용량 처리: Kafka, Pulsar
- 중소규모: RabbitMQ, NATS
- 지연 시간 요구사항
- 초저지연: NATS
- 일반 메시징: RabbitMQ
- 대량 처리 중심: Kafka
- 기능 요구사항
- 복잡한 라우팅: RabbitMQ
- 장기 데이터 보존: Kafka, Pulsar
- 멀티테넌시: Pulsar
- 운영 환경
- 클라우드 네이티브: 관리형 서비스 (AWS MSK, Google Pub/Sub)
- 온프레미스: Kafka, RabbitMQ
- 하이브리드: Pulsar
아키텍처 진화 방향
- 메시 아키텍처로의 전환
- 중앙집중식에서 분산형 이벤트 메시로 발전
- 도메인별 브로커 분리 및 연동
- 서버리스 이벤트 처리의 부상
- 인프라 관리 부담 감소
- 이벤트 기반 함수 실행 모델 확산
- 빅데이터 및 AI 와의 통합
- 실시간 스트림 처리와 AI 모델 결합
- 지능형 이벤트 라우팅 및 분석
용어 정리
| 용어 | 설명 |
|---|---|
참고 및 출처
1. 주제의 분류 적절성
“Event Brokers”(이벤트 브로커) 는 “Computer Science and Engineering > Backend Development > Event and Message Brokers > Fundamentals” 분류에 매우 적합합니다. 이벤트 브로커는 이벤트 기반 아키텍처 (EDA, Event-Driven Architecture) 의 핵심 인프라로, 백엔드 시스템의 확장성, 비동기성, 실시간성, 유연성을 실현하는 데 필수적인 미들웨어입니다 [4][14][6].
2. 200 자 요약
이벤트 브로커는 이벤트 발행자와 구독자 간의 메시지 교환을 중개하는 미들웨어로, 비동기 통신, 실시간 데이터 분배, 서비스 간 결합도 감소, 확장성 및 장애 복원력을 제공합니다. Pub/Sub, 스트리밍, 다양한 QoS(서비스 품질) 와 같은 고급 기능을 지원하며, 현대 백엔드 아키텍처의 핵심 역할을 담당합니다 [4][14][16].
3. 전체 개요 (250 자 내외)
이벤트 브로커는 이벤트 기반 아키텍처에서 이벤트 발행자 (Producer) 와 구독자 (Consumer) 사이의 이벤트 메시지 흐름을 중개하는 미들웨어입니다. 이벤트 브로커는 Pub/Sub, 스트리밍, 다양한 QoS, 보안, 트랜잭션, 확장성, 장애 복구 등 다양한 기능을 제공하며, 시스템 간 결합도를 낮추고, 실시간 데이터 분배와 비동기 처리를 지원합니다. 대표 솔루션으로는 Solace, Kafka, AWS EventBridge, Azure Event Grid 등이 있으며, 다양한 산업에서 실시간 분석, 알림, IoT, 마이크로서비스 통합 등 광범위하게 활용됩니다 [4][14][6][16].
핵심 개념
- 이벤트 브로커 (Event Broker): 이벤트 발행자와 구독자 사이에서 이벤트 메시지를 중개하는 미들웨어. 이벤트의 저장, 라우팅, 필터링, 전달, 보안, 품질 보장 (QoS) 등 다양한 역할을 수행 [4][14][16].
- Pub/Sub(발행 - 구독): 이벤트를 특정 주제 (Topic) 에 발행하면, 해당 주제를 구독한 모든 소비자가 이벤트를 수신하는 방식 [2][3][4].
- 토픽 (Topic): 이벤트 메시지를 분류하고 라우팅하는 논리적 채널. 계층적 구조와 와일드카드 구독 등 다양한 방식 지원 [2][3].
- QoS(서비스 품질): 이벤트 전달 보장 수준 (Exactly once, At least once, At most once 등)[6][14].
- 비동기 통신: 발행자와 구독자가 직접 연결되지 않고, 이벤트 브로커를 통해 비동기적으로 통신 [4][5][14].
목적 및 필요성
- 서비스 간 결합도 감소 및 유연성 확보
- 실시간 데이터 분배 및 비동기 처리
- 장애 복원력, 확장성, 신뢰성 강화
- 다양한 시스템 및 프로토콜 간 통합 지원
- 고가용성 및 분산 환경 지원 [4][5][14][16].
주요 기능 및 역할
- 이벤트 저장, 라우팅, 필터링, 전달
- Pub/Sub, 스트리밍, 요청 - 응답 등 다양한 메시징 패턴 지원
- QoS, 트랜잭션, 이벤트 순서 보장, 중복 방지
- 인증, 권한, 암호화 등 보안 기능
- 모니터링, 장애 복구, 확장성 관리 [6][14][16][11].
특징
- 느슨한 결합 (Loose Coupling), 비동기성, 실시간성, 확장성
- 다양한 배포 형태 (온프레미스, 클라우드, SaaS)
- 다양한 프로토콜 및 클라이언트 지원
- 이벤트 저장 및 재전송, 이벤트 소싱 지원
- 고가용성, 장애 복원력, 분산 처리 [4][14][16].
핵심 원칙
- 발행자와 구독자 간의 완전한 분리 (Decoupling)
- 신뢰성 있는 이벤트 전달 (중복 방지, 순서 보장)
- 확장성, 장애 복원력, 보안, 유연성
- 표준화된 메시징 패턴 및 프로토콜 준수 [4][14][16].
주요 원리 및 작동 원리
- **이벤트 발행자 (Producer)**가 이벤트를 브로커에 발행
- **이벤트 브로커 (Event Broker)**가 이벤트를 저장, 라우팅, 필터링
- **이벤트 구독자 (Consumer)**가 구독한 토픽의 이벤트를 수신
- 브로커는 QoS, 보안, 장애 복구 등 다양한 내부 로직을 적용
작동 원리 다이어그램
| |
- Pub/Sub, 스트리밍, QoS, 이벤트 저장 등 다양한 기능 내장
구조 및 아키텍처
필수 구성요소
| 구성 요소 | 기능 및 역할 |
|---|---|
| Producer(발행자) | 이벤트 생성 및 브로커에 발행 |
| Event Broker(브로커) | 이벤트 저장, 라우팅, 필터링, 전달, 보안, QoS |
| Consumer(구독자) | 구독한 토픽의 이벤트 수신 및 처리 |
| Topic/Channel | 이벤트 분류, 라우팅, 구독 관리 |
선택 구성요소
| 구성 요소 | 기능 및 역할 |
|---|---|
| Event Store | 이벤트 영속 저장, 이벤트 소싱, 감사, 재처리 지원 |
| Schema Registry | 이벤트 메시지 구조 관리 및 호환성 보장 |
| 모니터링/관리 도구 | 성능, 장애, 트래픽 모니터링 및 관리 |
| Event Router | 라우팅 규칙 기반 이벤트 분배 |
구조 다이어그램 예시
구현 기법
| 구현 기법 | 정의/구성 | 목적 | 실제 예시 (시스템/시나리오) |
|---|---|---|---|
| Pub/Sub | 토픽 기반 1:N 이벤트 분배 | 실시간 데이터 분배, 확장성 | Kafka, Solace, AWS EventBridge |
| 스트리밍 | 실시간 데이터 스트림 처리 | 대용량 실시간 처리 | Kafka, Pulsar |
| 이벤트 소싱 | 이벤트 로그 기반 상태 관리 | 데이터 추적, 복구 | Kafka, EventStoreDB |
| QoS 조정 | 이벤트 전달 보장 수준 설정 | 신뢰성, 중복 방지 | Exactly once, At least once, At most once |
장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 결합도 감소 | 발행자 - 구독자 완전 분리, 유연한 확장 |
| 신뢰성 | QoS, 장애 복구, 이벤트 저장 | |
| 실시간성 | 실시간 데이터 분배, 스트리밍 | |
| 확장성 | 대용량 트래픽, 수평 확장 용이 | |
| 다양한 패턴 | Pub/Sub, 스트리밍, 이벤트 소싱 등 지원 | |
| ⚠ 단점 | 복잡성 | 운영, 모니터링, 장애 분석 난이도 |
| 지연 | 브로커 장애, 네트워크 이슈 시 지연 가능 | |
| 일관성 | Eventually Consistent, 즉각적 일관성 어려움 | |
| 운영 비용 | 인프라, 관리, 보안 등 추가 리소스 필요 |
도전 과제
- 이벤트 순서 보장, 중복 방지, 트랜잭션 처리
- 장애 복구, 데이터 유실 방지, 확장성 관리
- 운영 복잡성, 실시간 모니터링 및 장애 탐지
- 스키마/버전 관리, 보안 강화 [14][16][11].
분류에 따른 종류 및 유형
| 분류 기준 | 종류/유형 | 설명 |
|---|---|---|
| 메시징 패턴 | Pub/Sub, 스트리밍, 이벤트 소싱 | 이벤트 전달 방식에 따른 분류 |
| 아키텍처 | 토픽 기반, 로그 기반, 큐 기반 | 내부 저장/분배 구조 |
| 배포 형태 | 온프레미스, 클라우드, SaaS | 배포 및 운영 방식 |
| QoS | Exactly once, At least once, At most once | 이벤트 전달 보장 수준 |
| 대표 제품 | Solace, Kafka, AWS EventBridge, Azure Event Grid, IBM MQ 등 | 주요 상용/오픈소스 솔루션 |
실무 적용 예시
| 적용 분야 | 적용 예시 | 설명 |
|---|---|---|
| 실시간 분석 | Kafka | 대용량 실시간 로그 스트림 분배 |
| 알림 서비스 | Solace | 다양한 채널로 이벤트 분배 |
| IoT | MQTT, Solace | 센서 데이터 실시간 수집/분배 |
| 데이터 파이프라인 | AWS EventBridge | 데이터 이동 및 ETL 자동화 |
| 마이크로서비스 통합 | Azure Event Grid | 서비스 간 이벤트 기반 통합 |
활용 사례 (시나리오)
시나리오: 글로벌 이커머스 실시간 주문/알림 시스템
시스템 구성
- 주문 서비스 (Producer) → Kafka(이벤트 브로커, Topic: order-events) → 결제/알림/배송 서비스 (Consumer)
- 알림 서비스 → Solace(이벤트 브로커, Topic: notification) → 이메일/SMS/푸시 서버
시스템 다이어그램
Workflow
- 주문 발생 시 order 이벤트를 Kafka 에 발행
- 결제, 알림, 배송 서비스가 각자 필요한 이벤트만 구독
- 알림 서비스는 Solace 를 통해 다양한 채널로 이벤트 분배
- 장애 발생 시 브로커가 이벤트 임시 저장, 재시도
담당 역할
- Kafka: 대용량 이벤트 스트림, Pub/Sub, 실시간 처리
- Solace: 다양한 채널, QoS, 이벤트 분배
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 메시지 패턴 | Pub/Sub 등 요구에 맞는 패턴 선택 | 시스템 요구사항 분석 후 설계 |
| 확장성 | 트래픽 증가 대비 수평 확장성 확보 | 클러스터링, 파티셔닝 적용 |
| 장애 복구 | 데이터 유실 방지, 장애 격리 | 복제, 백업, 장애 복구 시나리오 구축 |
| 모니터링 | 성능, 지연, 장애 실시간 모니터링 | APM, 대시보드, 알림 설정 |
| 보안 | 인증, 암호화, 접근 제어 | TLS, ACL, 권한 분리 적용 |
| 스키마 관리 | 이벤트 구조 일관성 유지 | Schema Registry, 버전 관리 도입 |
최적화하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 이벤트 크기 | 이벤트 최소화, 불필요 데이터 제거 | 10MB 이하, 경량 포맷 사용 |
| 브로커 설정 | 최적화된 토픽/파티션 구성 | 테스트 기반 튜닝, 병렬 처리 |
| 네트워크 | 대역폭, 지연 최소화 | 전용 네트워크, 로컬 배치 |
| 리소스 할당 | CPU/메모리/디스크 충분히 확보 | 오토스케일링, 모니터링 |
| 오류 처리 | 재시도, 백오프, DLQ 적용 | 자동화된 오류 처리 로직 구현 |
| 캐싱/비동기 | 병렬/비동기 처리로 처리량 증대 | 캐시, 비동기 API 활용 |
2025 년 기준 최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 클라우드 네이티브 | 매니지드 브로커 서비스 | Kafka, Solace 등 클라우드 통합, 자동 확장 |
| AI/ML | AI 기반 트래픽 예측, 자동 튜닝 | AI 가 이벤트 패턴 분석, 리소스 자동 할당 |
| IoT | 초경량 브로커, MQTT 확산 | IoT 데이터 실시간 수집/분배 |
| 보안 | 고급 암호화, 인증 강화 | TLS, OAuth 등 보안 강화 추세 |
| 이벤트 메시시 | 글로벌 이벤트 메시시 | 멀티 브로커 연결, 글로벌 분산 이벤트 처리 |
주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 메시징 패턴 | Pub/Sub, 스트리밍, 이벤트 소싱 | 다양한 패턴 조합으로 유연한 통신 |
| 스키마 관리 | Schema Registry | 이벤트 구조 일관성, 호환성 보장 |
| 장애 복구 | 복제, 파티셔닝 | 데이터 유실 방지, 고가용성 |
| 실시간성 | 스트리밍, 이벤트 소싱 | 대용량 실시간 데이터 처리 |
| 운영 자동화 | 오토스케일링, AI 기반 튜닝 | 운영 효율성 및 장애 대응 강화 |
앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 시장 성장 | 이벤트 브로커 시장 | 연평균 20% 이상 성장, IoT/클라우드 영향 |
| AI 통합 | AI/ML 기반 브로커 | 예측, 자동화, 장애 탐지 강화 |
| IoT 확장 | 초경량 브로커 | 엣지/IoT 환경에 최적화 |
| 이벤트 메시시 | 글로벌 메시시 | 멀티 브로커, 글로벌 분산 트래픽 |
| 보안 | 고급 보안 기능 | 데이터 보호, 규제 대응 강화 |
하위 주제 및 추가 학습 필요 내용
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 메시징 패턴 | Pub/Sub, 스트리밍, 이벤트 소싱 | 각 패턴별 특징, 적용법 |
| 브로커 비교 | Kafka, Solace, EventBridge 등 | 주요 브로커별 장단점, 아키텍처 |
| 스키마 관리 | Schema Registry | 이벤트 구조 관리, 버전 호환성 |
| 장애 복구 | 복제, 파티셔닝, DLQ | 고가용성, 장애/오류 처리 |
| 보안 | 인증, 암호화, 접근제어 | 보안 설계 및 운영 가이드 |
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 아키텍처 | 이벤트 메시시, 글로벌 분산 | 멀티 브로커, 이벤트 메시시 구조 |
| 운영 | 모니터링, 오토스케일링 | 실시간 성능/장애 관리 |
| 성능 | 튜닝, 최적화 | 브로커별 성능 최적화 방법 |
| 클라우드 | 매니지드 서비스 | 클라우드 기반 브로커 활용법 |
| 개발 | API, SDK 활용 | 다양한 언어/플랫폼 연동법 |
용어 정리
| 용어 | 설명 |
|---|---|
| Pub/Sub | 발행 - 구독 패턴, 이벤트를 여러 구독자에게 분배하는 구조 |
| Topic | 이벤트 메시지 분류 및 라우팅 논리적 채널 |
| QoS | 이벤트 전달 보장 수준 (Exactly once, At least once, At most once) |
| Event Mesh | 복수 브로커를 연결한 글로벌 분산 구조 |
| Schema Registry | 이벤트 메시지 구조 (스키마) 관리 시스템 |
| DLQ(Dead Letter Queue) | 처리 실패 이벤트 임시 저장 큐 |
| 오토스케일링 | 자동 리소스 확장/축소 기능 |
참고 및 출처
- Solace Event Broker 개념 및 기능
- Solace Docs - What Are Event Brokers?
- Gartner Event Broker 시장 가이드
- PubNub Event Broker 설명
- Azure Event Broker 아키텍처 예시
- EDA 실무 적용 사례
- EDA 성능 최적화 및 브로커 튜닝
- Gartner Event Broker 비교 및 선택 가이드
Citations:
[1] https://talent500.com/blog/how-to-implement-event-driven-architecture-for-complex-backend-systems/
[2] https://www.linkedin.com/pulse/eda-fundamentals-sap-advanced-event-mesh-mahesh-dash-mrpge
[3] https://docs.solace.com/Cloud/Event-Portal/event-portal-topic-addresses.htm
[4] https://docs.solace.com/Get-Started/what-are-event-brokers.htm
[5] https://solace.com/blog/why-developers-pubsub-plus-event-driven-architecture/
[6] https://www.gartner.com/reviews/market/event-brokers
[7] https://estuary.dev/blog/event-driven-architecture-examples/
[8] https://learn.microsoft.com/en-us/azure/architecture/example-scenario/integration/queues-events
[9] https://tyk.io/learning-center/event-driven-architecture-best-practices/
[10] https://www.site24x7.com/blog/troubleshooting-latency-issues-in-event-driven-architectures
[11] https://solace.com/blog/gartner-how-to-choose-an-event-broker/
[12] https://cerexio.com/axon-real-time-event-broker-platform
[13] https://www.cognitivemarketresearch.com/e-brokerage-market-report
[14] https://solace.com/what-is-an-event-broker/
[15] https://solace.com/resources/solace-event-driven-architecture-resources/gartner-market-guide-for-event-brokers
[16] https://www.pubnub.com/guides/event-driven-architecture/
[17] https://dev.to/jhonifaber/introduction-to-event-driven-architecture-eda-3ioj
[18] https://risingwave.com/blog/real-world-applications-of-event-driven-architecture-10-examples/
[19] https://aws.amazon.com/blogs/architecture/best-practices-for-implementing-event-driven-architectures-in-your-organization/
[20] https://ibm.github.io/event-automation/es/installing/capacity-planning/
[21] https://solace.com/resources/pubsub-event-broker/why-pubsub-is-the-worlds-best-event-broker-2-video
[22] https://dev.to/hamzakhan/understanding-event-driven-architecture-a-guide-for-backend-developers-3bne
[23] https://help.pubsub.em.services.cloud.sap/Get-Started/what-are-event-brokers.htm
[24] https://solace.com/blog/gartners-latest-advice-on-how-to-choose-an-event-broker/
[25] https://www.nucamp.co/blog/coding-bootcamp-backend-with-python-2025-eventdriven-architectures-how-backend-systems-are-changing-in-2025
[26] https://netmetic.wordpress.com/2020/07/17/gartners-advise-on-how-to-choose-an-event-broker-2/
[27] https://en.wikipedia.org/wiki/Event-driven_architecture
[28] https://www.ibm.com/think/topics/message-brokers
[29] https://developer.confluent.io/patterns/event-stream/event-broker/
[30] https://rasa.com/docs/rasa/next/event-brokers/
[31] https://solace.com/what-is-event-driven-architecture/
[32] https://www.gartner.com/en/documents/4004081
[33] https://slashdot.org/software/event-brokers/
[34] https://dzone.com/articles/top-5-considerations-when-selecting-an-event-broke
[35] https://insights.daffodilsw.com/blog/event-driven-architecture-explained-with-real-world-examples
[36] https://www.gartner.com/en/documents/5834147
[37] https://help.pubsub.em.services.cloud.sap/Cloud/Deployment-Considerations/deployment-options-ownership.htm
[38] https://www.rtinsights.com/dont-be-let-down-by-the-middleman-ensure-your-event-broker-is-the-best-in-the-business-for-your-business/
[39] https://www.wearemci.com/en/insights/10-game-changing-event-trends-for-associations-in-2025
[40] https://remo.co/blog/event-industry-statistics
[41] https://hsmai.eu/2025/01/30/9-event-trends-that-will-shape-2025/
[42] https://www.linkedin.com/pulse/b2b-event-trends-2025-insights-engaging-sustainable-anna-anisin-orxic
[43] https://www.encoreglobal.com/news-releases/2024-outlook-research-insights-driving-the-events-industry/
[44] https://www.eventible.com/learning/event-trends/
[45] https://docs.solace.com/Get-Started/tutorial/event-broker-basics.htm
[46] https://rasa.com/docs/rasa-pro/production/event-brokers/
[47] https://tyk.io/learning-center/what-is-event-driven-architecture/
[48] https://www.b2match.com/blog/how-to-organize-an-impactful-brokerage-event
[49] https://docs.solace.com/Messaging/Topic-Architecture-Best-Practices.htm
[50] https://help.sap.com/docs/integration-suite/sap-integration-suite/f72428ff67db467ab1673e85a9b61927.html
Perplexity 로부터의 답변: pplx.ai/share 좋습니다. 다음은 “Event Brokers” 주제에 대한 체계적인 조사 및 정리입니다. 이 내용은 AWS, Confluent, Red Hat 등 공식 자료 기반으로 정리되었습니다.
✅ 1. 주제의 분류 적절성
분류: Computer Science and Engineering > Backend Development > Event and Message Brokers > Fundamentals
적절성: ✔ 매우 적절합니다.
Event Broker는 백엔드 아키텍처의 메시징, 비동기 처리, 시스템 해석 및 설계에 직접적으로 관련되며, 특히 마이크로서비스 환경에서 필수적인 구성 요소입니다.
✅ 2. 요약 문장 (200자 이내)
Event Broker는 이벤트 기반 아키텍처에서 시스템 간 메시지를 중개하여, 비동기 통신, 느슨한 결합, 확장성 있는 설계를 가능하게 하는 핵심 인프라 컴포넌트입니다.
✅ 3. 전체 개요 (250자 이내)
Event Broker는 이벤트 기반 아키텍처에서 이벤트를 생산자에서 소비자로 전달하는 메시징 컴포넌트입니다. 마이크로서비스, 클라우드 네이티브 환경에서 시스템 간 느슨한 결합과 비동기 통신을 통해 확장성과 장애 격리에 기여하며, 실시간 데이터 스트리밍, 알림 시스템, 자동화 워크플로우 등 다양한 곳에 활용됩니다.
✅ 4. 핵심 개념
| 항목 | 설명 |
|---|---|
| Event | 시스템 내 상태 변화나 행동을 나타내는 데이터 단위. 예: “OrderPlaced” |
| Event Producer | 이벤트를 생성하여 브로커에 전달하는 주체. 예: 주문 서비스 |
| Event Consumer | 이벤트를 구독하고 처리하는 주체. 예: 재고 서비스 |
| Event Broker | 이벤트를 수신하고 적절한 소비자에게 전달하는 중재자 역할. |
| Topic / Channel | 이벤트를 분류해주는 라우팅 단위. 구독자는 토픽을 기준으로 메시지를 받음. |
| Event-Driven Architecture (EDA) | 이벤트를 중심으로 동작하는 아키텍처 패턴. 서비스 간 느슨한 결합과 확장성 지원. |
✅ 5. 주제별 상세 조사 (참고사항 반영)
5.1 목적 및 필요성
비동기 통신 지원: 요청-응답 구조를 벗어나 서비스 간 독립성 보장
확장성: 생산자, 소비자가 독립적으로 확장 가능
장애 격리: 서비스 장애 시에도 이벤트 처리 보장
실시간 반응성: 사용자 행동에 빠른 대응
5.2 주요 기능 및 역할
| 기능 | 설명 |
|---|---|
| 이벤트 수신 | 생산자가 생성한 이벤트 수신 |
| 이벤트 저장 | 디스크 기반의 로그 또는 큐 형태로 보관 |
| 이벤트 라우팅 | 토픽 기반 또는 규칙 기반으로 소비자에게 전달 |
| 이벤트 재처리 | 실패한 이벤트의 재시도 또는 리플레이 기능 제공 |
| 메시지 순서 보장 | FIFO(First In First Out) 보장 (선택적) |
| 메시지 중복 제거 | 멱등성(idempotency) 보장 기능 제공 |
5.3 특징
비동기, 느슨한 결합
Pub/Sub 또는 Queue 모델 채택
높은 처리량과 신뢰성
스케일 아웃(Scale-out) 구조 지원
5.4 핵심 원칙
| 원칙 | 설명 |
|---|---|
| 비동기 메시징 | 서비스 간 직접 호출 대신 이벤트를 통해 상호작용 |
| 느슨한 결합 | 시스템 간 독립성 유지 |
| 발행-구독 (Pub/Sub) | 이벤트 브로커가 생산자-소비자 간 직접 연결을 제거 |
| 리액티브 처리 | 이벤트 기반 반응형 프로세싱 가능 |
5.5 주요 원리 및 작동 원리
작동 흐름 다이어그램:
Producer는 이벤트를 Broker에게 보냄
Broker는 토픽 또는 규칙 기반으로 Consumer에게 전달
Consumer는 이벤트를 비동기적으로 수신하고 처리
5.6 구조 및 아키텍처
✅ 필수 구성 요소
| 구성 요소 | 설명 |
|---|---|
| Producer | 이벤트를 생성해 브로커에 전달 |
| Broker | 이벤트를 수신, 저장, 라우팅 |
| Consumer | 이벤트를 수신해 처리 수행 |
| Topic / Channel | 메시지 분류 단위 |
| Storage (Log) | 이벤트 내구성 보장, 재처리를 위한 저장소 |
🔁 선택 구성 요소
| 구성 요소 | 설명 |
|---|---|
| Rule Engine | 이벤트 라우팅에 조건 기반 처리 적용 |
| Event Router | 이벤트를 다양한 소비자에게 라우팅 |
| Retry Queue / DLQ | 실패 이벤트를 위한 재처리 큐 구성 |
✅ 아키텍처 다이어그램 (간단화)
5.7 구현 기법
| 구현 방식 | 정의 | 주요 구성 | 목적 | 예시 |
|---|---|---|---|---|
| Pub/Sub | 발행자가 메시지를 전송하고 구독자가 수신 | Topic, Subscriber | 비동기 통신 | Kafka, Pulsar |
| Queue-based | 메시지가 큐에 쌓이고 소비자가 처리 | Queue, Consumer | 순차적 처리, 병렬성 제한 | RabbitMQ, SQS |
| Rule-based Routing | 조건 기반으로 라우팅 | Rule, EventPattern | 조건 기반 처리 | AWS EventBridge |
| Replay / Log-based | 이벤트를 저장하고 재생 가능 | Storage, Offset | 재처리 및 감사 | Kafka log |
5.8 장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 확장성 | 생산자/소비자의 독립적 스케일링 가능 |
| 유연성 | 마이크로서비스 통합 용이 | |
| 장애 격리 | 일부 소비자가 실패해도 전체 영향 없음 | |
| 이벤트 저장 | 과거 이벤트 재처리 가능 | |
| ⚠ 단점 | 설계 복잡도 | 메시지 흐름과 데이터 흐름 이해 필요 |
| 중복 처리 위험 | 멱등성 구현 필요 | |
| 모니터링 부담 | 메시지 지연/손실 추적 필요 | |
| 순서 보장 이슈 | 다중 파티션 사용 시 순서 깨질 수 있음 |
5.9 분류에 따른 종류 및 유형
| 분류 기준 | 유형 | 설명 |
|---|---|---|
| 메시징 모델 | Pub/Sub | 다수 소비자 대상 이벤트 분배 |
| 큐 기반 | 단일 소비자 처리 (FIFO) | |
| 전달 보장 | At-most-once | 최대 한 번, 손실 가능 |
| At-least-once | 중복 가능, 반드시 한 번 이상 | |
| Exactly-once | 중복 없이 정확히 한 번 | |
| 배포 형태 | 클라우드 기반 | AWS EventBridge, GCP Pub/Sub |
| 온프레미스 | Kafka, RabbitMQ, NATS |
좋습니다. 이어서 실무 적용 예시부터 정리해드리겠습니다.
✅ 5.10 실무 적용 예시
| 사례 | 설명 |
|---|---|
| 주문 처리 시스템 | 사용자가 상품을 주문하면 OrderCreated 이벤트를 발행하고, 결제, 재고, 배송 서비스가 이를 소비함 |
| 실시간 알림 시스템 | 게시글에 댓글이 달리면 이벤트를 통해 사용자에게 푸시 알림을 전송 |
| IoT 센서 네트워크 | 센서가 측정한 데이터를 이벤트로 브로커에 보내고, 분석 서비스가 이를 실시간 처리 |
| 로그 수집 및 분석 | 다양한 마이크로서비스에서 발생하는 로그를 이벤트로 Kafka에 전송하고, ELK(Elasticsearch, Logstash, Kibana)로 분석 |
| 결제 거래 흐름 추적 | 사용자의 결제 이벤트 흐름을 전송하여 상태 변화 추적 및 자동화 처리 수행 |
✅ 5.11 활용 사례
📌 상황: 이커머스 플랫폼의 실시간 주문-배송 연동
시나리오 설명:
고객이 주문을 완료하면 결제, 재고 확인, 배송 예약 등의 처리가 순차적으로 이루어짐. 각 단계는 독립된 마이크로서비스로 구성되어 있음.
사용 시스템 구성:
| 구성 요소 | 기술 |
|---|---|
| 이벤트 브로커 | Apache Kafka |
| 주문 서비스 | Spring Boot (Producer) |
| 결제 서비스 | Node.js |
| 재고 서비스 | Python FastAPI |
| 배송 서비스 | Golang |
| 알림 서비스 | Firebase Messaging (Consumer) |
워크플로우:
주문 발생 →
OrderCreated이벤트 Kafka에 발행결제/재고 서비스는 해당 이벤트 구독 후 처리
결제 완료 →
PaymentSuccess이벤트 발행배송 서비스는 이를 구독하고 배송 스케줄링
알림 서비스는 각 단계의 이벤트를 수신하여 사용자에게 알림 전송
역할 분담:
Kafka: 모든 이벤트의 전달 및 순서 제어
각 서비스: 자신의 도메인 처리만 책임, 이벤트에 반응
✅ 5.12 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 멱등성 처리 | 중복 메시지로 인한 중복 처리 방지 필요 | 메시지에 ID 부여, 상태 체크 후 처리 |
| 이벤트 스키마 관리 | 필드 추가/변경 시 하위 호환성 이슈 | Avro + Schema Registry 사용 |
| 소비자 장애 복구 | 소비자 실패 시 데이터 유실 위험 | Retry + Dead Letter Queue 구성 |
| 보안 및 인증 | 브로커 접근 제어 필요 | TLS, SASL, IAM 정책 구성 |
| 운영 모니터링 | 메시지 지연, 실패 추적 필수 | Prometheus, Grafana, Kafka UI 도입 |
| 데이터 유실 방지 | 브로커 저장소나 파티션 장애 시 손실 발생 가능 | Replication, 메시지 영속화 설정 |
✅ 5.13 성능을 최적화하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 처리량 (Throughput) | 초당 메시지 전송량 제한 | 배치 전송, 압축 사용, 프로듀서 설정 조정 |
| 지연시간 (Latency) | 소비자 수신 지연 | 빠른 네트워크, 바이너리 포맷(Avro 등) 사용 |
| 저장 공간 | 로그 기반 브로커는 저장공간 이슈 있음 | 보존 기간 설정, 압축 활성화 |
| 파티션 설계 | 너무 적으면 병렬성 부족, 많으면 오버헤드 증가 | 토픽 설계 시 키 기반 파티션 전략 사용 |
| 메시지 크기 | 큰 메시지는 처리 및 전송 부담 | 파일은 별도 저장, 링크만 이벤트에 포함 |
| 소비자 병렬성 | 단일 소비자는 처리량 한계 | Consumer Group으로 수평 확장 |
✅ 5.14 2025년 기준 최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 기술 | Apache Kafka 4.0 | KRaft 기반으로 Zookeeper 제거, 관리 단순화 |
| 클라우드 | AWS EventBridge 성장 | 이벤트 중심 SaaS 간 통합 허브로 확장 |
| 표준화 | AsyncAPI | 메시징 기반 API 명세화 도구로 도입 확산 |
| 아키텍처 | Event Mesh | 다양한 브로커를 통합하는 메시지 네트워크 개념 확대 |
| 보안 | 메시지 레벨 암호화 | 데이터 보안 요구 증가에 따라 메시지 단위 보호 강화 |
✅ 5.15 주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 운영 자동화 | 브로커 오토스케일링 | Kubernetes 기반 자동 확장 구현 확대 |
| 고가용성 | 다중 브로커 클러스터 | 장애 대비용 이중화 구성이 보편화 |
| 메시지 포맷 | Protobuf, Avro | 성능, 용량, 스키마 진화성에서 주목받는 포맷 |
| Event Replay | Kafka, Pulsar 등에서 지원 | 장애 시 재처리 및 감사용으로 활용 증가 |
✅ 5.16 앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 아키텍처 전환 | 이벤트 기반 설계 표준화 | 기존 REST 기반 시스템도 이벤트 중심으로 재편 중 |
| 산업 확산 | IoT, AI 기반 시스템 증가 | 실시간 데이터 수집 및 반응형 처리가 필수화됨 |
| 통합 표준 | AsyncAPI + OpenAPI 연동 | 메시징과 REST API 명세 통합 시도 활발 |
| 서비스화 | Event Broker as a Service | Kafka, EventBridge 등 완전관리형 서비스 확산 지속 |
✅ 5.17 하위 주제별 추가 학습 목록
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 아키텍처 | Event Mesh | 다중 브로커 통합과 글로벌 이벤트 전파 |
| 설계 전략 | 이벤트 스키마 설계 | 이벤트 정의 시 필수 고려사항 및 버전 관리 |
| 보안 | 메시징 인증 및 암호화 | TLS, OAuth, IAM 기반 접근 제어 기법 |
| 테스트 | 이벤트 기반 통합 테스트 | E2E 흐름 테스트 및 시뮬레이션 전략 |
| 성능 | 이벤트 병렬 처리 전략 | Partition, Consumer Group 구성 전략 학습 |
✅ 5.18 관련 분야별 추가 학습 목록
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 데이터 엔지니어링 | Kafka Connect / Kafka Streams | 외부 시스템 연동 및 스트림 처리 학습 |
| DevOps | Kafka 클러스터 운영 | 배포, 모니터링, 확장 전략 학습 |
| 클라우드 아키텍처 | AWS EventBridge, SNS/SQS | 완전관리형 메시징 서비스 설계 |
| AI/ML | 실시간 추론 트리거 | 이벤트 기반 ML 모델 실행 자동화 |
| 보안 | Event Audit Logging | 이벤트 추적을 위한 로깅 및 감사 전략 |
🧾 용어 정리
| 용어 | 설명 |
|---|---|
| Event Broker | 이벤트를 생산자에서 소비자로 전달하는 중간 시스템 |
| Pub/Sub | 발행-구독 모델로, 하나의 발행자가 다수 소비자에게 메시지를 전파 |
| Dead Letter Queue (DLQ) | 처리 실패한 메시지를 보관하여 별도로 처리하는 큐 |
| AsyncAPI | 메시지 기반 API 명세를 위한 표준 포맷 |
| Event Mesh | 다양한 브로커를 하나의 통합 메시지 시스템처럼 연결한 구조 |
🔗 참고 및 출처
필요하시면 “Event Broker 구축 예제 코드”, “Kafka vs EventBridge 비교”, “Kafka 모니터링 지표 및 실전 대시보드 구성”도 제공해드릴 수 있습니다. 어떤 부분을 더 살펴볼까요?
아래에 요청하신 세 가지 항목을 실무 기준으로 구체적으로 정리해드립니다:
✅ 1. Event Broker 구축 예제 코드 (Kafka 기반, Python)
🎯 목표:
Kafka를 사용하여 Event Broker 환경을 구축하고 간단한 Producer-Consumer 이벤트 흐름을 구현합니다.
📦 구성:
Apache Kafka
Python (
kafka-python라이브러리)
1-1. 설치 준비
| |
1-2. Python Producer 코드
| |
1-3. Python Consumer 코드
| |
✅ 2. Kafka vs AWS EventBridge 비교
| 항목 | Apache Kafka | AWS EventBridge |
|---|---|---|
| 설치 형태 | 자체 호스팅 또는 Confluent Cloud | 완전관리형 (서버리스) |
| 프로토콜 | TCP 기반 고속 스트리밍 | HTTP 기반 이벤트 버스 |
| 스키마 관리 | Avro + Schema Registry | JSON + Schema Registry |
| 이벤트 처리 | 고속, 실시간, 다중 소비자 | 규칙 기반 라우팅, 느린 이벤트 처리 가능 |
| 통합성 | 외부 도구와의 커스텀 연동 용이 | AWS 서비스와의 통합 강력 |
| 보안 | TLS, ACL 등 자체 구성 | IAM, 리소스 정책 통합 |
| 사용 사례 | 실시간 로그, 스트리밍 분석 | SaaS 이벤트 통합, 워크플로우 트리거링 |
| 장점 | 고성능, 유연성, 재처리 가능 | 간단한 설정, 완전관리형 |
| 단점 | 운영 복잡, 설정 어려움 | Throughput 제한, 제약된 커스터마이징 |
🧠 추천 시나리오:
Kafka: 대량의 실시간 데이터 처리 및 복잡한 이벤트 스트림 처리
EventBridge: 서버리스 아키텍처, AWS 서비스 간 이벤트 통합 중심
✅ 3. Kafka 모니터링 지표 및 실전 대시보드 구성 (Prometheus + Grafana)
📊 주요 지표
| 지표 | 설명 |
|---|---|
kafka_server_brokertopicmetrics_messages_in_total | 초당 수신 메시지 수 |
kafka_server_brokertopicmetrics_bytes_in_total | 수신 바이트 수 |
kafka_server_brokertopicmetrics_bytes_out_total | 전송 바이트 수 |
kafka_server_replicamanager_underreplicated_partitions | 동기화 안된 파티션 수 |
kafka_network_requestmetrics_requests_total | 총 네트워크 요청 수 |
kafka_controller_kafkacontroller_activecontrollercount | 활성 컨트롤러 수 (1이 아니면 비정상) |
kafka_log_logsize | 토픽/파티션별 로그 사이즈 |
🛠️ 실전 대시보드 구성
- Exporter 설치
Kafka용 JMX Exporter 사용:
- Prometheus 설정 예시
- Grafana 대시보드 템플릿
ID:
7589(confluentinc 제공 Kafka Dashboard)대시보드 포함 항목:
브로커별 처리량
파티션 상태
lag 상태
consumer group health
메시지 지연 현황
필요하시면 다음 항목도 추가 제공 가능합니다:
Kafka + Flink 실시간 분석 연동 예제
EventBridge를 사용한 AWS 서비스 오케스트레이션 사례
Kafka Streams와 KSQL 사용법
원하시는 방향이 있다면 이어서 더 지원하겠습니다.
이벤트 및 메시지 브로커
1. 주제의 분류 적절성 확인
“Event and Message Brokers"는 “Computer Science and Engineering” > “Backend Development” 분류가 매우 적절합니다. 이벤트 및 메시지 브로커는 백엔드 시스템의 핵심 구성 요소로, 분산 시스템에서 비동기 통신을 가능하게 하고 시스템 간 결합도를 낮추는 데 중요한 역할을 합니다.
2. 요약 (200자 내외)
이벤트 및 메시지 브로커는 서로 다른 시스템이나 애플리케이션 간 비동기 통신을 가능하게 하는 미들웨어로, 메시지 브로커는 안전한 메시지 전달과 라우팅에 중점을 두고, 이벤트 브로커는 대용량 데이터 처리와 이벤트 기록 보존에 중점을 둡니다. 대표적으로 메시지 브로커는 RabbitMQ, 이벤트 브로커는 Apache Kafka가 있습니다.
3. 개요 (250자 내외)
이벤트 및 메시지 브로커는 현대 백엔드 아키텍처에서 핵심적인 통신 메커니즘을 제공하는 미들웨어 시스템입니다. 이들은 분산 시스템에서 애플리케이션 간의 느슨한 결합을 가능하게 하고, 비동기 통신을 통해 시스템 확장성과 안정성을 높입니다. 메시지 브로커가 메시지의 안전한 전달과 순서 보장에 중점을 두는 반면, 이벤트 브로커는 대용량 이벤트 데이터의 실시간 처리와 영구 저장에 특화되어 있습니다.
4. 핵심 개념
메시지 브로커(Message Broker)
메시지 브로커는 서로 다른 시스템이나 애플리케이션 간의 메시지를 안전하게 송수신하도록 중개하는 소프트웨어입니다. 주요 목적은 메시지를 검증, 변환, 라우팅하여 적절한 수신자에게 전달하는 것입니다. 메시지 브로커는 메시지를 일시적으로 저장하고, 소비자가 처리될 때까지 보관합니다.
이벤트 브로커(Event Broker)
이벤트 브로커는 시스템에서 발생하는 이벤트를 중계하는 미들웨어로, 이벤트 데이터를 로그 방식으로 저장하여 대용량 데이터를 효율적으로 처리할 수 있습니다. 이벤트 브로커는 이벤트 데이터를 영구적으로 저장하며, 소비자가 필요할 때 특정 시점부터 이벤트를 다시 소비할 수 있는 특징이 있습니다.
생산자-소비자 패턴(Producer-Consumer Pattern)
메시지/이벤트 브로커에서는 메시지를 보내는 측(생산자, Producer)과 메시지를 받는 측(소비자, Consumer) 간의 통신 패턴입니다. 생산자는 브로커에 메시지를 발행하고, 소비자는 브로커로부터 메시지를 구독합니다.
비동기 통신(Asynchronous Communication)
메시지/이벤트 브로커의 핵심 개념으로, 시스템 간에 실시간으로 응답을 기다리지 않고 독립적으로 작동할 수 있게 합니다. 이는 시스템의 확장성과 장애 대응력을 높입니다.
느슨한 결합(Loose Coupling)
시스템 간 의존성을 최소화하는 설계 원칙으로, 메시지/이벤트 브로커를 통해 서비스들이 직접적인 연결 없이도 통신할 수 있게 합니다. 이를 통해 시스템 변경이나 확장 시 다른 시스템에 미치는 영향을 최소화할 수 있습니다.
5. 주제와 관련하여 조사할 내용
목적 및 필요성
메시지 및 이벤트 브로커의 주요 목적은 분산 시스템에서 비동기 통신을 가능하게 하는 것입니다. 이를 통해 다음과 같은 필요성을 해결합니다:
- 시스템 간 느슨한 결합 구현: 서비스 간 직접적인 의존성을 제거하여 각 서비스가 독립적으로 개발, 배포, 확장될 수 있도록 합니다.
- 부하 분산: 갑작스러운 트래픽 증가나 대량 요청 시에도 메시지를 일시적으로 저장하고 순차적으로 처리할 수 있습니다.
- 안정성 향상: 수신 시스템이 일시적으로 사용 불가능한 상황에서도 메시지를 보존하여 나중에 처리할 수 있습니다.
- 확장성 지원: 시스템 규모가 커지고 복잡해질수록 직접 연결 방식은 관리하기 어려워지므로, 브로커를 통한 중앙화된 통신 채널을 제공합니다.
- 비동기 처리: 응답을 기다리지 않고 처리할 수 있어 시스템 효율성이 향상됩니다.
주요 기능 및 역할
- 메시지 라우팅: 메시지를 적절한 수신자에게 전달합니다.
- 메시지 변환: 다양한 프로토콜과 데이터 형식 간 변환을 지원합니다.
- 메시지 저장: 소비자가 처리할 수 있을 때까지 메시지를 안전하게 저장합니다.
- 메시지 필터링: 특정 조건에 맞는 메시지만 선별하여 전달합니다.
- 부하 분산: 여러 소비자 간에 메시지를 분산시켜 처리 효율을 높입니다.
- 신뢰성 보장: 메시지 전달 성공 여부를 확인하고, 필요시 재전송합니다.
- 이벤트 지속성: 이벤트 브로커의 경우, 이벤트를 영구적으로 저장하여 나중에 접근할 수 있게 합니다.
특징
- 비동기 통신: 송신자와 수신자가 동시에 활성화되어 있지 않아도 메시지 교환이 가능합니다.
- 메시지 버퍼링: 대량의 메시지를 일시적으로 저장하여 처리 부하를 분산합니다.
- 확장성: 메시지 양이 증가해도 시스템을 수평적으로 확장할 수 있습니다.
- 장애 내구성: 시스템 일부가 실패해도 전체 시스템 중단 없이 계속 작동합니다.
- 다양한 통신 패턴 지원: 일대일, 일대다, 발행-구독 등 다양한 통신 패턴을 지원합니다.
- 플랫폼 독립성: 다양한 프로그래밍 언어와 플랫폼 간 통신을 가능하게 합니다.
핵심 원칙
- 메시지 지향 미들웨어(Message-Oriented Middleware, MOM) 원칙: 시스템 간 통신을 메시지 교환으로 추상화합니다.
- 발행-구독(Publish-Subscribe) 원칙: 메시지 생산자와 소비자 간의 느슨한 결합을 촉진합니다.
- 점대점(Point-to-Point) 원칙: 한 생산자가 하나의 소비자에게 메시지를 전달하는 방식입니다.
- 메시지 보존 원칙: 메시지는 소비될 때까지 안전하게 보존되어야 합니다.
- 멱등성(Idempotency) 원칙: 동일한 메시지가 여러 번 처리되더라도 시스템 상태는 동일해야 합니다.
- 순서 보장 원칙: 특정 상황에서는 메시지의 처리 순서가 보장되어야 합니다.
- 장애 격리 원칙: 한 시스템의 장애가 다른 시스템에 영향을 미치지 않아야 합니다.
주요 원리 및 작동 원리
메시지 브로커와 이벤트 브로커의 작동 원리는 다음과 같습니다:
메시지 브로커 작동 원리
- 메시지 생성(Production): 생산자(Producer)가 메시지를 생성하여 브로커에 전송합니다.
- 메시지 수신 및 검증: 브로커는 메시지를 수신하고 유효성을 검증합니다.
- 메시지 라우팅: 브로커는 메시지의 라우팅 키나 주제(Topic)에 따라 메시지를 적절한 큐나 교환소(Exchange)로 라우팅합니다.
- 메시지 저장: 메시지는 큐에 저장되어 소비자가 처리할 수 있을 때까지 대기합니다.
- 메시지 소비(Consumption): 소비자(Consumer)는 큐에서 메시지를 가져와 처리합니다.
- 확인(Acknowledgment): 메시지 처리가 완료되면 소비자는 브로커에게 확인 메시지를 보내고, 브로커는 해당 메시지를 큐에서 제거합니다.
이벤트 브로커 작동 원리
- 이벤트 생성(Publication): 생산자(Publisher)가 이벤트를 생성하여 브로커에 발행(Publish)합니다.
- 이벤트 저장: 이벤트는 로그 형태로 영구적으로 저장됩니다.
- 이벤트 구독(Subscription): 소비자(Subscriber)는 특정 주제(Topic)나 파티션(Partition)을 구독합니다.
- 이벤트 배포: 브로커는 이벤트를 관련된 구독자에게 전달합니다.
- 이벤트 소비(Consumption): 구독자는 이벤트를 받아 처리합니다. 이때 이벤트는 로그에서 삭제되지 않고 유지됩니다.
- 오프셋 관리: 소비자는 자신이 어디까지 이벤트를 소비했는지에 대한 오프셋(Offset)을 관리하며, 필요시 이전 이벤트부터 다시 소비할 수 있습니다.

구조 및 아키텍처
메시지 브로커 아키텍처
메시지 브로커 시스템은 다음과 같은 주요 구성 요소로 이루어져 있습니다:
필수 구성요소
- 브로커(Broker): 메시지 라우팅과 전달을 담당하는 중심 구성 요소입니다.
- 교환소(Exchange): 생산자로부터 받은 메시지를 라우팅 규칙에 따라 적절한 큐로 전달하는 역할을 합니다.
- 큐(Queue): 메시지가 소비자에게 전달되기 전에 임시 저장되는 공간입니다.
- 바인딩(Binding): 교환소와 큐를 연결하는 규칙으로, 어떤 메시지가 어떤 큐로 전달될지 결정합니다.
- 생산자(Producer): 메시지를 생성하여 브로커에게 전송하는 역할을 합니다.
- 소비자(Consumer): 큐에서 메시지를 가져와 처리하는 역할을 합니다.
선택 구성요소
- 가상 호스트(Virtual Host): 여러 사용자나 애플리케이션이 동일한 브로커를 독립적으로 사용할 수 있도록 논리적으로 분리하는 기능입니다.
- 메시지 우선순위(Priority): 특정 메시지에 우선순위를 부여하여 처리 순서를 조정할 수 있습니다.
- 메시지 TTL(Time-To-Live): 메시지가 큐에서 얼마나 오래 유지될지 설정할 수 있습니다.
- 데드 레터 교환소(Dead Letter Exchange): 처리에 실패한 메시지를 별도로 관리할 수 있는 특수 교환소입니다.
- 클러스터링(Clustering): 고가용성과 확장성을 위해 여러 브로커 노드를 연결할 수 있습니다.
메시지 브로커 아키텍처 다이어그램
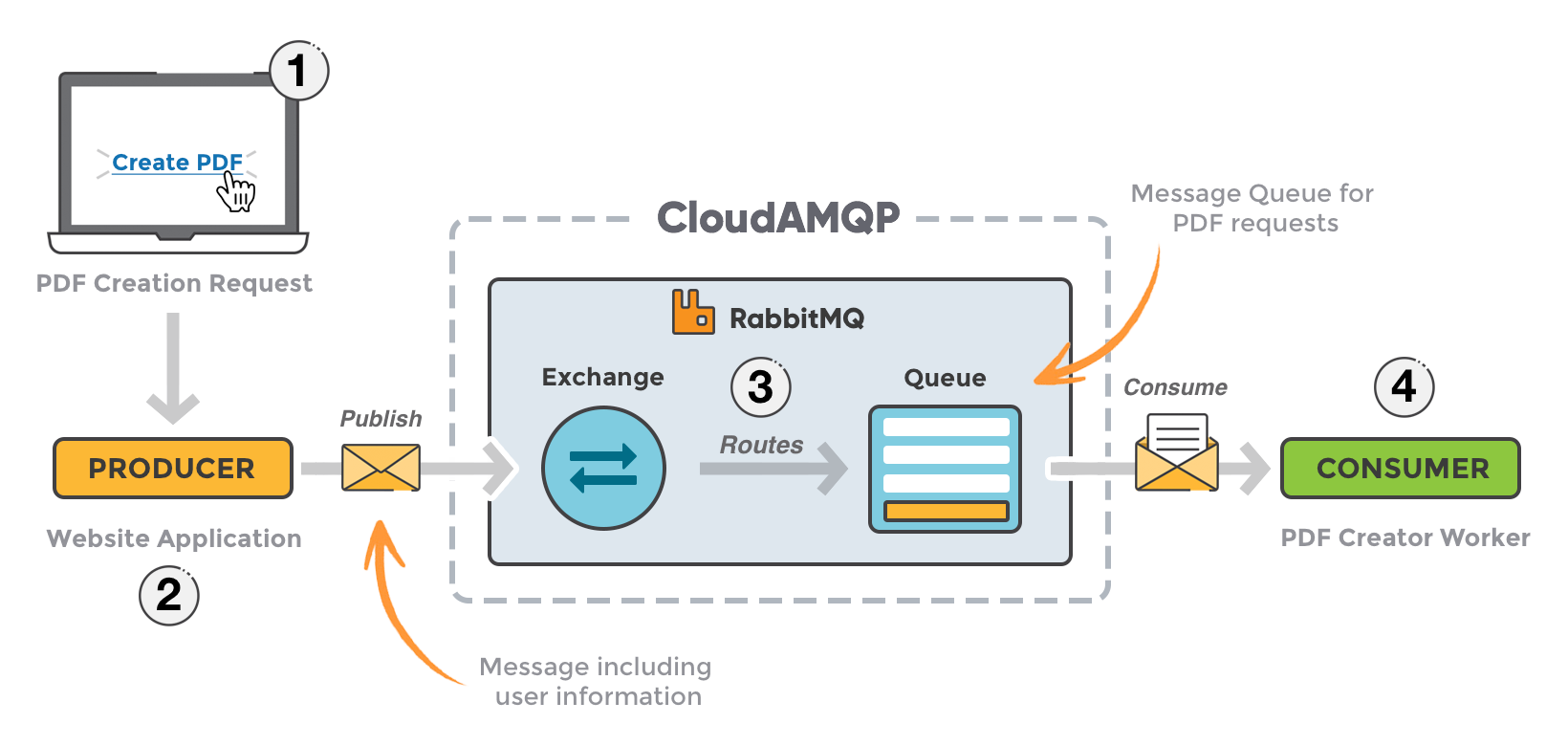
이벤트 브로커 아키텍처
이벤트 브로커 시스템은 다음과 같은 주요 구성 요소로 이루어져 있습니다:
필수 구성요소
- 브로커(Broker): 이벤트 수신, 저장, 전달을 담당하는 중심 노드입니다.
- 주제(Topic): 관련 이벤트를 그룹화하는 논리적 채널입니다.
- 파티션(Partition): 주제 내에서 이벤트를 분산 저장하고 병렬 처리하기 위한 물리적 분할입니다.
- 로그(Log): 이벤트가 영구적으로 저장되는 순차적 데이터 구조입니다.
- 생산자(Producer): 이벤트를 생성하여 브로커에게 전송하는 역할을 합니다.
- 소비자(Consumer): 브로커로부터 이벤트를 가져와 처리하는 역할을 합니다.
- 소비자 그룹(Consumer Group): 동일한 이벤트 스트림을 처리하는 소비자들의 집합입니다.
선택 구성요소
- 레플리케이션(Replication): 고가용성을 위해 파티션 데이터를 여러 브로커에 복제합니다.
- 지연 주제(Delayed Topic): 특정 시간 후에 처리되어야 하는 이벤트를 위한 특수 주제입니다.
- 컴팩션(Compaction): 동일한 키를 가진 이벤트 중 최신 이벤트만 보존하는 기능입니다.
- 스키마 레지스트리(Schema Registry): 이벤트 데이터의 스키마를 관리하고 검증하는 컴포넌트입니다.
- 스트림 처리(Stream Processing): 이벤트 스트림을 실시간으로 변환하고 처리하는 기능입니다.
이벤트 브로커 아키텍처 다이어그램

구현 기법
1. 발행-구독(Publish-Subscribe) 패턴
정의: 메시지 발행자(Publisher)가 특정 주제(Topic)나 채널에 메시지를 게시하고, 해당 주제를 구독한 모든 구독자(Subscriber)에게 메시지가 전달되는 방식입니다.
구성:
- 발행자(Publisher): 주제(Topic)에 메시지를 발행합니다.
- 주제(Topic): 메시지를 카테고리별로 분류합니다.
- 구독자(Subscriber): 특정 주제(Topic)를 구독하고 관련 메시지를 수신합니다.
목적:
- 발행자와 구독자 간의 느슨한 결합을 제공합니다.
- 일대다(one-to-many) 통신을 가능하게 합니다.
- 비동기 메시지 전달을 지원합니다.
실제 예시:
| |
2. 점대점(Point-to-Point) 패턴
정의: 메시지 발신자가 특정 큐에 메시지를 전송하고, 하나의 소비자만이 해당 메시지를 처리하는 방식입니다.
구성:
- 발신자(Sender): 큐에 메시지를 전송합니다.
- 큐(Queue): 메시지를 일시적으로 저장합니다.
- 수신자(Receiver): 큐에서 메시지를 가져와 처리합니다.
목적:
- 메시지가 정확히 한 번만 처리되도록 보장합니다.
- 부하 분산을 위해 여러 수신자 간에 메시지를 분배할 수 있습니다.
- 메시지의 순서 보장을 지원합니다.
실제 예시:
| |
3. 요청-응답(Request-Reply) 패턴
정의: 클라이언트가 서버에 요청 메시지를 보내고, 서버가 응답 메시지를 반환하는 방식입니다.
구성:
- 클라이언트(Client): 요청 메시지를 전송하고 응답을 기다립니다.
- 서버(Server): 요청 메시지를 처리하고 응답 메시지를 생성합니다.
- 요청 큐(Request Queue): 클라이언트의 요청 메시지가 저장됩니다.
- 응답 큐(Reply Queue): 서버의 응답 메시지가 저장됩니다.
목적:
- 비동기적 요청-응답 패턴을 구현합니다.
- 분산 시스템에서 RPC(Remote Procedure Call)를 구현할 수 있습니다.
- 클라이언트와 서버 간의 느슨한 결합을 제공합니다.
실제 예시:
| |
4. 이벤트 소싱(Event Sourcing) 패턴
정의: 시스템의 상태 변화를 일련의 이벤트로 저장하고, 이벤트를 재생하여 현재 상태를 복원하는 방식입니다.
구성:
- 이벤트 저장소(Event Store): 모든 이벤트를 시간 순서대로 저장합니다.
- 이벤트 생성자(Event Producer): 상태 변화를 이벤트로 발행합니다.
- 이벤트 소비자(Event Consumer): 이벤트를 처리하여 시스템 상태를 업데이트합니다.
- 스냅샷(Snapshot): 성능 향상을 위해 특정 시점의 시스템 상태를 저장합니다.
목적:
- 시스템의 모든 상태 변화에 대한 감사 추적(audit trail)을 제공합니다.
- 시스템 상태를 특정 시점으로 복원할 수 있는 시간 여행(time travel) 기능을 지원합니다.
- 상태 변화의 이유와 의도를 명확하게 표현할 수 있습니다.
- 높은 확장성과 동시성을 제공합니다.
실제 예시(시스템 구성):
- 이벤트 저장소: Apache Kafka, Event Store DB
- 이벤트 처리: Spring Cloud Stream, Akka Streams
- 스냅샷 저장소: MongoDB, PostgreSQL
| |
5. 명령 쿼리 책임 분리(CQRS: Command Query Responsibility Segregation) 패턴
정의: 시스템의 명령(상태 변경)과 쿼리(상태 조회)를 분리하여 각각에 최적화된 모델을 사용하는 패턴입니다. 종종 이벤트 소싱과 함께 사용됩니다.
구성:
- 명령 모델(Command Model): 시스템 상태를 변경하는 작업을 처리합니다.
- 쿼리 모델(Query Model): 시스템 상태를 조회하는 작업을 처리합니다.
- 이벤트 버스(Event Bus): 명령 모델의 변경 사항을 쿼리 모델에 전파합니다.
- 읽기 저장소(Read Store): 쿼리 성능 최적화를 위한 특수한 형태의 데이터 저장소입니다.
목적:
- 읽기와 쓰기 작업을 분리하여 각각에 최적화된 성능을 제공합니다.
- 복잡한 도메인 모델과 간단한 쿼리 모델의 분리를 지원합니다.
- 확장성이 높은 시스템 아키텍처를 구현할 수 있습니다.
- 읽기 모델과 쓰기 모델 간의 낮은 결합도를 제공합니다.
실제 예시:
| |
장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 느슨한 결합(Loose Coupling) | 서비스 간 직접적인 의존성이 없어 각 서비스를 독립적으로 개발, 배포, 확장할 수 있습니다. |
| 비동기 통신 | 요청-응답 패턴과 달리 즉각적인 응답을 기다리지 않아도 되므로, 시스템 효율성이 향상됩니다. | |
| 부하 분산 | 갑작스러운 트래픽 증가 시에도 메시지를 버퍼링하여 순차적으로 처리할 수 있어 시스템 안정성이 높아집니다. | |
| 장애 격리 | 한 서비스의 장애가 다른 서비스에 직접적인 영향을 미치지 않습니다. | |
| 확장성 | 생산자와 소비자를 독립적으로 확장할 수 있어 시스템 확장이 용이합니다. | |
| 다양한 통신 패턴 지원 | 점대점, 발행-구독, 요청-응답 등 다양한 통신 패턴을 지원합니다. | |
| ⚠ 단점 | 복잡성 증가 | 분산 시스템 디버깅이 어렵고, 메시지 라우팅, 재시도 등의 복잡한 로직이 필요합니다. |
| 일관성 보장의 어려움 | 일시적인 데이터 불일치가 발생할 수 있으며, 최종 일관성(eventual consistency)에 의존해야 합니다. | |
| 운영 오버헤드 | 브로커 설정, 모니터링, 확장 등 추가적인 | |
| 운영 부담이 있습니다. | ||
| 메시지 순서 보장의 어려움 | 분산 환경에서 메시지 순서를 완벽하게 보장하기 어려울 수 있습니다. | |
| 브로커 장애 위험 | 브로커 자체가 시스템의 단일 장애 지점(SPOF)이 될 수 있습니다. |
도전 과제
일관성과 순서 보장: 분산 환경에서 메시지/이벤트의 순서를 보장하고 일관성을 유지하는 것은 어렵습니다. 특히 파티셔닝과 샤딩을 사용할 때 더욱 어렵습니다.
확장성과 성능: 대용량 메시지/이벤트 처리 시 브로커의 확장성과 성능을 유지하는 것이 중요합니다. 특히 브로커가 단일 장애 지점이 되지 않도록 분산 아키텍처를 설계해야 합니다.
메시지 중복 처리: 네트워크 장애 등으로 인해 동일한 메시지가 여러 번 전송될 수 있으므로, 멱등성(idempotency)을 구현하여 중복 처리를 방지해야 합니다.
데드레터 처리: 실패한 메시지를 처리하기 위한 데드레터 큐(Dead Letter Queue) 및 재시도 메커니즘을 구현해야 합니다.
보안과 인증: 브로커 접근 제어, 메시지/이벤트 암호화, 인증 등의 보안 메커니즘을 구현해야 합니다.
모니터링과 디버깅: 분산 시스템에서 메시지/이벤트 흐름을 추적하고 디버깅하는 것은 어렵습니다. 효과적인 모니터링 및 로깅 전략이 필요합니다.
스키마 진화: 시간이 지남에 따라 메시지/이벤트 스키마가 변경될 수 있으므로, 하위 호환성을 유지하면서 스키마를 진화시키는 방법이 필요합니다.
장애 복구와 내구성: 브로커 장애 시 메시지/이벤트 손실을 방지하고 신속하게 복구할 수 있는 메커니즘이 필요합니다.
분류에 따른 종류 및 유형
| 분류 | 유형 | 특징 | 사용 사례 | 대표 기술 |
|---|---|---|---|---|
| 통신 모델 | 점대점(Point-to-Point) | 하나의 발신자에서 하나의 수신자로 메시지 전달 | 작업 큐, 부하 분산 | RabbitMQ, ActiveMQ |
| 발행-구독(Publish-Subscribe) | 하나의 발행자에서 여러 구독자로 메시지 전달 | 이벤트 알림, 브로드캐스트 | Kafka, MQTT | |
| 요청-응답(Request-Reply) | 요청 메시지 전송 후 응답 메시지 수신 | RPC, 분산 서비스 | RabbitMQ, ZeroMQ | |
| 메시지 저장 방식 | 인메모리(In-memory) | 메시지를 메모리에 저장하여 빠른 처리 | 실시간 데이터 처리 | Redis |
| 디스크 기반(Disk-based) | 메시지를 디스크에 저장하여 내구성 보장 | 중요 트랜잭션, 장기 저장 | Kafka, RabbitMQ | |
| 하이브리드(Hybrid) | 인메모리와 디스크 기반 접근 방식 결합 | 성능과 내구성 모두 중요한 경우 | Apache Pulsar | |
| 브로커 유형 | 메시지 브로커(Message Broker) | 메시지를 큐에 저장하고 소비 후 삭제 | 작업 큐, 비동기 통신 | RabbitMQ, ActiveMQ |
| 이벤트 브로커(Event Broker) | 이벤트를 로그에 저장하고 유지 | 이벤트 소싱, 스트림 처리 | Kafka, EventStoreDB | |
| 서비스 버스(Service Bus) | 메시지 라우팅, 변환, 조정 기능 | 엔터프라이즈 통합 | Azure Service Bus, NServiceBus | |
| 분산 아키텍처 | 중앙 집중형(Centralized) | 단일 브로커 인스턴스 또는 클러스터 | 소규모 시스템, 간단한 통합 | Redis PubSub |
| 분산형(Distributed) | 여러 브로커 노드가 분산되어 작동 | 대규모 시스템, 고가용성 필요 | Kafka, RabbitMQ 클러스터 | |
| 메시 아키텍처(Mesh) | 브로커 간 직접 통신 지원 | 글로벌 분산 시스템 | NATS, Kafka MirrorMaker | |
| 프로토콜 | AMQP | 고급 메시지 큐 프로토콜 | 엔터프라이즈 메시징 | RabbitMQ, ActiveMQ |
| MQTT | 경량 M2M 통신 프로토콜 | IoT, 모바일 | Mosquitto, HiveMQ | |
| STOMP | 심플 텍스트 지향 메시징 프로토콜 | 웹 애플리케이션 | RabbitMQ, ActiveMQ | |
| Kafka 프로토콜 | 바이너리 TCP 기반 프로토콜 | 대용량 스트리밍 | Kafka |
실무 적용 예시
| 분야 | 사용 사례 | 설명 | 적용 기술 |
|---|---|---|---|
| 전자상거래 | 주문 처리 | 주문 접수 후 결제, 재고 확인, 배송 등의 프로세스를 비동기적으로 처리 | RabbitMQ, Amazon SQS |
| 금융 | 결제 시스템 | 결제 요청을 안전하게 처리하고 관련 시스템(회계, 사기 감지 등)에 알림 | Kafka, ActiveMQ |
| 물류 | 재고 관리 | 재고 변경 이벤트를 처리하여 재고 수준을 실시간으로 추적 | Kafka, RabbitMQ |
| IoT | 센서 데이터 수집 | 대량의 센서 데이터를 수집하여 분석 시스템으로 전달 | MQTT, Kafka |
| 소셜 미디어 | 알림 서비스 | 사용자 활동(댓글, 좋아요 등)에 대한 알림을 실시간으로 처리 | Redis PubSub, Kafka |
| 게임 | 멀티플레이어 게임 | 플레이어 간 상호작용 및 게임 상태 변경 이벤트 처리 | NATS, Redis PubSub |
| 데이터 분석 | 실시간 분석 | 발생하는 이벤트를 실시간으로 수집하여 분석 파이프라인으로 전달 | Kafka, Apache Pulsar |
| 마이크로서비스 | 서비스 간 통신 | 서비스 간 느슨한 결합을 유지하면서 데이터 교환 | RabbitMQ, Kafka |
| 모니터링 | 로그 수집 | 분산 시스템의 로그 데이터를 중앙 집중화하여 모니터링 | Kafka, Fluentd |
| 클라우드 | 이벤트 기반 자동화 | 클라우드 리소스 변경 이벤트에 대응하여 작업 자동화 | AWS EventBridge, Azure Event Grid |
활용 사례
금융 거래 처리 시스템(RabbitMQ와 Kafka를 활용한 하이브리드 아키텍처)
시나리오: 대형 금융 기관에서 다양한 채널(웹, 모바일, ATM 등)을 통해 들어오는 거래 요청을 안정적으로 처리하고, 관련 시스템(계정 관리, 사기 감지, 회계, 감사, 고객 알림 등)과 통합하는 시스템을 구축해야 합니다.
시스템 구성:
RabbitMQ 클러스터:
- 거래 요청 수신 및 초기 처리
- 작업 큐를 통한 부하 분산
- 트랜잭션 보장을 위한 메시지 확인(acknowledgment) 메커니즘 활용
Apache Kafka 클러스터:
- 모든 거래 이벤트 기록 및 유지
- 다양한 시스템에 이벤트 스트림 제공
- 실시간 분석 및 모니터링 지원
서비스 컴포넌트:
- 거래 처리 서비스: 실제 거래 로직 실행
- 사기 감지 서비스: 실시간으로 이상 거래 탐지
- 알림 서비스: 고객에게 거래 알림 전송
- 분석 서비스: 거래 패턴 분석 및 리포트 생성
- 아카이브 서비스: 이벤트를 장기 저장소에 보관
시스템 다이어그램:
| |
워크플로우:
- 고객이 다양한 채널을 통해 거래 요청을 시작합니다.
- API 게이트웨이가 요청을 수신하고 기본 유효성 검사를 수행합니다.
- 트랜잭션 유효성 검증 서비스가 요청을 검증하고 필요한 변환을 수행합니다.
- 트랜잭션 라우팅 서비스가 요청 유형에 따라 적절한 RabbitMQ 큐로 메시지를 라우팅합니다.
- RabbitMQ는 메시지를 적절한 트랜잭션 처리 서비스로 전달합니다.
- 트랜잭션 처리 서비스는 거래를 처리하고 결과를 데이터베이스에 저장합니다.
- 데이터베이스 변경 사항은 Kafka Connect의 CDC(Change Data Capture)를 통해 Kafka로 전파됩니다.
- 알림 서비스는 RabbitMQ로부터 처리 결과를 수신하고 고객에게 알림을 전송합니다.
- Kafka에 저장된 이벤트 스트림은 실시간 분석 시스템, 사기 감지 시스템 등 다양한 소비자가 활용합니다.
- 장기 보관이 필요한 이벤트는 이벤트 아카이빙 시스템으로 전송됩니다.
역할 및 책임:
- RabbitMQ: 신뢰성 있는 메시지 전달, 작업 큐 관리, 트랜잭션 처리 보장
- Kafka: 이벤트 스트림 저장 및 배포, 실시간 데이터 파이프라인 제공
- 서비스 컴포넌트: 비즈니스 로직 처리, 데이터 변환, 고객 상호작용 관리
이 아키텍처의 주요 이점은 다음과 같습니다:
- 고가용성과 확장성을 제공하는 분산 설계
- RabbitMQ를 통한 안정적인 트랜잭션 처리
- Kafka를 통한 완전한 이벤트 기록 및 실시간 분석 지원
- 시스템 컴포넌트 간의 느슨한 결합으로 유지보수성 향상
- 장애 상황에서도 데이터 손실 방지 및 빠른 복구
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 고려사항 | 설명 | 권장사항 |
|---|---|---|
| 메시지/이벤트 스키마 설계 | 메시지 구조와 데이터 형식이 시스템 통합에 큰 영향을 미침 | 스키마 레지스트리 도입, 버전 관리 체계 구축, 하위 호환성 유지 |
| 배포 전략 | 브로커 인프라의 가용성과 확장성이 전체 시스템에 영향을 줌 | 클러스터링, 고가용성 설정, 지역 분산 배포, 장애 조치(failover) 메커니즘 구현 |
| 모니터링 및 알림 | 브로커 및 메시지 흐름에 대한 가시성 확보가 중요 | 포괄적인 모니터링 도구 도입, 주요 지표 대시보드 구성, 자동 알림 설정 |
| 메시지 우선순위 | 중요한 메시지가 적시에 처리되어야 함 | 우선순위 큐 활용, 중요 메시지용 전용 채널 구성, QoS(Quality of Service) 설정 적용 |
| 메시지 재시도 및 실패 처리 | 일시적 장애로 인한 메시지 처리 실패 대응 필요 | 지수 백오프 재시도 전략, 데드레터 큐(DLQ) 구현, 실패 메시지 모니터링 및 알림 |
| 보안 및 인증 | 브로커 접근 제어 및 메시지 보안이 중요 | TLS/SSL 암호화 적용, 강력한 인증 메커니즘 구현, 세분화된 접근 제어 설정 |
| 일관성 보장 | 분산 환경에서 메시지 순서 및 처리 보장이 어려움 | 파티션 키 전략 수립, 메시지 ID 및 타임스탬프 활용, 멱등 소비자 구현 |
| 용량 계획 | 메시지 볼륨 및 브로커 리소스 요구사항 예측 필요 | 부하 테스트 수행, 확장 계획 수립, 자동 스케일링 메커니즘 구현 |
| 로깅 및 추적 | 메시지 흐름 추적 및 문제 해결 필요 | 상관관계 ID 도입, 분산 추적 시스템 구현, 구조화된 로깅 표준 적용 |
| 백업 및 복구 | 데이터 손실 방지 및 재해 복구 계획 필요 | 정기적 백업 수행, 복구 계획 문서화, 복구 훈련 실시 |
최적화하기 위한 고려사항 및 주의할 점
| 고려사항 | 설명 | 권장사항 |
|---|---|---|
| 메시지 크기 | 큰 메시지는 네트워크 대역폭과 브로커 성능에 영향을 줌 | 메시지 크기 제한 설정, 대용량 콘텐츠는 외부 저장소 활용, 메시지 압축 적용 |
| 배치 처리 | 개별 메시지 처리는 오버헤드가 크므로 성능 저하 가능 | 생산자 및 소비자 배치 설정 최적화, 배치 크기와 지연 시간 균형 조정 |
| 브로커 설정 | 기본 설정이 모든 워크로드에 최적화되지 않음 | 메모리, 디스크 I/O, 네트워크 설정 최적화, 하드웨어 리소스에 맞는 JVM 튜닝 |
| 파티션 전략 | 파티션 수와 배치가 처리량과 순서에 영향을 줌 | 워크로드에 적합한 파티션 수 설정, 균형 잡힌 파 |
최적화하기 위한 고려사항 및 주의할 점 (계속)
| 고려사항 | 설명 | 권장사항 |
|---|---|---|
| 파티션 전략 | 파티션 수와 배치가 처리량과 순서에 영향을 줌 | 워크로드에 적합한 파티션 수 설정, 균형 잡힌 파티션 키 선택, 핫 파티션 방지 |
| 네트워크 최적화 | 네트워크 지연 및 대역폭이 성능에 영향을 줌 | 브로커와 클라이언트 간 네트워크 최적화, 지리적으로 가까운 배치, TCP 설정 튜닝 |
| 소비자 그룹 설계 | 소비자 그룹 구성이 병렬 처리에 영향을 줌 | 워크로드에 맞는 소비자 수 조정, 균형 잡힌 파티션 할당 전략 선택 |
| 캐싱 전략 | 반복 데이터 접근이 성능을 저하시킬 수 있음 | 클라이언트 측 캐싱 적용, 읽기 전용 복제본 활용, 캐시 무효화 전략 수립 |
| 디스크 I/O | 디스크 성능이 메시지 지속성에 영향을 줌 | SSD 활용, RAID 구성 최적화, 로그 세그먼트 설정 조정 |
| 메시지 압축 | 압축이 네트워크 사용량은 줄이지만 CPU 사용량은 증가 | 메시지 특성에 맞는 압축 알고리즘 선택, 압축 수준과 성능 사이의 균형 조정 |
| 필터링 최적화 | 클라이언트 측 필터링이 불필요한 네트워크 사용 유발 | 서버 측 필터링 활용, 토픽/파티션 설계 최적화, 이벤트 필터링 패턴 도입 |
| 모니터링 오버헤드 | 과도한 모니터링이 성능에 영향을 줄 수 있음 | 샘플링 기반 모니터링 적용, 중요 지표 선별, 모니터링 주기 최적화 |
| 보존 정책 | 오래된 메시지 저장이 스토리지 성능에 영향을 줌 | 적절한 보존 기간 설정, 계층형 스토리지 활용, 압축 정책 최적화 |
| 클라이언트 라이브러리 선택 | 클라이언트 라이브러리에 따라 성능 차이 발생 | 최신 버전의 공식 클라이언트 사용, 비동기 API 활용, 커넥션 풀링 구현 |
2025년 기준 최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 메시지 브로커 기술 | 서버리스 메시징 | 클라우드 제공업체의 완전 관리형 서버리스 메시징 솔루션이 확산되어 운영 부담을 크게 줄이고 유연한 확장성을 제공합니다. |
| Edge 메시징 | 엣지 컴퓨팅 환경에서도 작동하는 경량화된 메시지 브로커들이 등장하여 IoT 및 분산 애플리케이션을 위한 지연 시간 최소화와 오프라인 지원이 가능해졌습니다. | |
| WebSocket 및 WebTransport 통합 | 최신 메시지 브로커들은 WebSocket과 더 새로운 WebTransport 프로토콜을 기본적으로 지원하여 웹 애플리케이션과의 연결성이 강화되었습니다. | |
| 이벤트 중심 아키텍처 | 이벤트 메시 | 단일 중앙 브로커에 의존하지 않고 여러 브로커가 분산 네트워크를 형성하는 이벤트 메시(Event Mesh) 아키텍처가 확산되고 있습니다. |
| 하이브리드/멀티클라우드 이벤트 라우팅 | 서로 다른 클라우드 환경과 온프레미스 시스템 간의 원활한 이벤트 라우팅을 지원하는 솔루션이 발전하여 기업의 멀티클라우드 전략을 지원합니다. | |
| 이벤트 기반 서버리스 | 이벤트에 반응하여 자동으로 확장되는 서버리스 함수와 메시지/이벤트 브로커의 통합이 더욱 강화되었습니다. | |
| 데이터 관리 | 실시간 데이터 파이프라인 | 메시지/이벤트 브로커를 중심으로 실시간 데이터 파이프라인을 구축하는 패턴이 확산되어 데이터 레이크, 웨어하우스와의 통합이 강화되었습니다. |
| 스키마 진화 관리 | 메시지/이벤트 스키마의 버전 관리와 진화를 지원하는 고급 도구가 발전하여 장기적인 시스템 유지 관리 부담이 감소했습니다. | |
| 컴플라이언스 및 데이터 거버넌스 | 메시지/이벤트 브로커에서의 데이터 처리에 대한 규제 준수와 거버넌스 기능이 강화되어 민감한 데이터 처리 지원이 개선되었습니다. | |
| 개발자 경험 | 저코드/노코드 통합 | 시각적 도구를 통해 메시지/이벤트 흐름을 설계하고 관리할 수 있는 저코드/노코드 솔루션이 발전하여 개발자가 아닌 사용자도 통합 파이프라인을 구축할 수 있게 되었습니다. |
| AI 지원 디버깅 | 분산 메시징 시스템에서 문제를 진단하고 해결하는 AI 기반 도구가 등장하여 복잡한 디버깅 과정을 간소화합니다. | |
| API 우선 접근 방식 | 메시지/이벤트 브로커가 API 관리 플랫폼과 긴밀하게 통합되어 API와 이벤트 기반 통신의 경계가 모호해지고 있습니다. |
주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 핵심 기술 발전 | eBPF 기반 브로커 최적화 | eBPF(extended Berkeley Packet Filter) 기술을 활용하여 커널 레벨에서 메시지 라우팅 및 필터링을 최적화하는 기법이 도입되고 있습니다. |
| 영속성과 지연 시간 균형 | 비휘발성 메모리(NVRAM)와 같은 신기술을 활용해 높은 영속성과 낮은 지연 시간을 동시에 제공하는 메시지 브로커가 등장하고 있습니다. | |
| 양자 내성 암호화 | 향후 양자 컴퓨팅 위협에 대비한 양자 내성 암호화를 적용한 메시지/이벤트 브로커 보안 기능이 연구 중입니다. | |
| 새로운 패러다임 | 메시지-쿼리 통합 | 메시지 브로커와 데이터베이스 쿼리 기능이 통합된 하이브리드 시스템이 등장하여 이벤트와 상태 관리의 경계가 모호해지고 있습니다. |
| 네트워크 메시 통합 | 서비스 메시(Service Mesh)와 이벤트 메시(Event Mesh)의 통합을 통해 일관된 통신 인프라를 제공하는 접근 방식이 발전하고 있습니다. | |
| 상태 중심 메시징(State-centric Messaging) | 단순 이벤트 전달을 넘어 분산 상태 관리와 메시징을 결합한 새로운 패러다임이 등장하고 있습니다. | |
| 도메인 특화 솔루션 | IoT 특화 브로커 | 리소스 제약 환경, 간헐적 연결성, 엣지 처리를 고려한 IoT 특화 메시지/이벤트 브로커가 발전하고 있습니다. |
| 금융 거래용 고성능 브로커 | 나노초 지연 시간, 확정적 전달, 규제 준수를 보장하는 금융 특화 메시지 브로커가 개발되고 있습니다. | |
| AI/ML 파이프라인 통합 | 대규모 AI/ML 데이터 파이프라인에 최적화된 이벤트 스트리밍 플랫폼이 등장하여 모델 훈련 및 추론 워크플로우를 지원합니다. | |
| 운영 혁신 | 자가 최적화 브로커 | 워크로드 패턴을 학습하여 자동으로 설정을 최적화하는 인공지능 기반 메시지 브로커가 연구되고 있습니다. |
| 탄소 발자국 최적화 | 에너지 효율성을 고려한 메시지 라우팅 및 저장 전략을 통해 데이터센터 탄소 발자국을 줄이는 접근 방식이 주목받고 있습니다. | |
| 통합 가시성 도구 | 여러 브로커와 환경에 걸친 메시지/이벤트 흐름을 통합적으로 시각화하고 모니터링하는 도구가 개발되고 있습니다. |
앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 기술 통합 | 분산 원장 기술(DLT) 통합 | 블록체인/DLT 기술과 메시지/이벤트 브로커의 통합이 확대되어 메시지 불변성, 추적성, 신뢰성을 강화하는 솔루션이 확산될 것으로 예상됩니다. |
| 엣지-클라우드 연속성 | 엣지 컴퓨팅과 클라우드 환경 간의 원활한 메시지/이벤트 흐름을 지원하는 통합 브로커 솔루션이 중요해질 것입니다. | |
| AI 기반 브로커 | AI가 메시지 라우팅, 필터링, 우선순위 지정에 활용되어 상황에 맞는 지능적인 메시지 처리를 제공하는 브로커가 등장할 것입니다. | |
| 새로운 응용 분야 | 디지털 트윈 플랫폼 | 물리적 자산과 디지털 트윈 간의 실시간 동기화를 위한 핵심 인프라로 메시지/이벤트 브로커가 활용될 것입니다. |
| 메타버스 커뮤니케이션 | 대규모 가상 환경에서 시공간 이벤트를 처리하기 위한 특화된 메시지/이벤트 브로커가 발전할 것입니다. | |
| 자율 시스템 조정 | 자율 시스템 간의 협업과 조정을 위한 의사결정 플랫폼으로 이벤트 브로커의 역할이 확대될 것입니다. | |
| 아키텍처 진화 | 멀티모달 이벤트 처리 | 다양한 유형(텍스트, 이미지, 오디오, 동영상 등)의 이벤트 데이터를 처리하기 위한 메시지/이벤트 브로커 기능이 확장될 것입니다. |
| 양자 메시징 | 양자 컴퓨팅과 양자 통신 기술을 활용한 고도로 안전한 메시지 브로커가 연구 개발될 것입니다. | |
| 공간 이벤트 처리 | 지리적 위치와 공간 관계를 고려한 이벤트 라우팅 및 처리 기능이 강화될 것입니다. | |
| 생태계 발전 | 이벤트 마켓플레이스 | 조직 간에 이벤트를 안전하게 공유하고 거래할 수 있는 이벤트 마켓플레이스가 발전할 것입니다. |
| 크로스 도메인 표준화 | 다양한 산업 분야에 걸친 이벤트 스키마와 메시지 형식의 표준화가 진행될 것입니다. | |
| 오픈소스 혁신 | 새로운 메시징 패러다임을 구현한 혁신적인 오픈소스 브로커가 등장하여 생태계가 더욱 다양화될 것입니다. |
추가 학습 주제
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 메시지 브로커 심화 | AMQP 프로토콜 | Advanced Message Queuing Protocol의 세부 사항과 구현 기법에 대한 심층 이해 |
| 메시지 라우팅 전략 | 복잡한 라우팅 토폴로지와 패턴 설계 및 구현 방법 | |
| 브로커 내부 아키텍처 | 메시지 브로커의 내부 구현과 최적화 기법에 대한 이해 | |
| 이벤트 브로커 심화 | 파티셔닝 전략 | 대규모 이벤트 처리를 위한 파티션 설계와 최적화 방법 |
| 이벤트 컴팩션 | 이벤트 스트림의 효율적인 압축 및 관리 기법 | |
| 스트림 처리 토폴로지 | 복잡한 이벤트 처리 파이프라인 설계 및 구현 방법 | |
| 분산 시스템 | CAP 이론과 브로커 설계 | 일관성, 가용성, 분할 내성 간의 트레이드오프와 브로커 설계에 미치는 영향 |
| 분산 합의 알고리즘 | Raft, Paxos 등 분산 시스템의 합의 알고리즘과 메시지 브로커 적용 | |
| 비동기 패턴 | 콜백, 프로미스, 리액티브 프로그래밍 등 비동기 통신 패턴 | |
| 패턴 및 아키텍처 | 사가 패턴 | 분산 트랜잭션 관리를 위한 메시지 기반 사가 패턴 구현 |
| 이벤트 소싱 심화 | 복잡한 도메인을 위한 이벤트 소싱 설계 및 구현 | |
| 메시징 패턴 카탈로그 | 다양한 메시징 패턴과 응용 사례 분석 | |
| 성능 및 운영 | 고성능 메시징 | 저지연, 고처리량 메시징 시스템 설계 및 구현 |
| 대규모 운영 | 수백 개의 브로커 노드로 구성된 클러스터 관리 및 운영 | |
| 장애 복구 전략 | 다양한 장애 시나리오에 대응하는 복구 전략 | |
| 보안 | 메시지 보안 | 메시지 암호화, 인증, 무결성 보장 기법 |
| 접근 제어 | 세분화된 메시지 접근 제어 정책 설계 및 구현 | |
| 보안 위협 분석 | 메시지 브로커 환경의 잠재적 보안 위협과 대응 방안 | |
| 클라우드 네이티브 | 쿠버네티스 통합 | 쿠버네티스 환경에서의 메시지 브로커 배포 및 운영 |
| 서버리스 메시징 | AWS Lambda, Azure Functions 등과의 통합 패턴 | |
| 클라우드 간 메시징 | 멀티클라우드 환경에서의 메시지/이벤트 브로커 활용 | |
| 특수 도메인 | IoT 메시징 | 리소스 제약 환경에서의 효율적인 메시징 구현 |
| 실시간 분석 | 이벤트 스트림을 활용한 실시간 분석 파이프라인 구축 | |
| 규제 준수 | 금융, 의료 등 규제 산업에서의 메시지 브로커 활용 |
추가 학습 내용
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 프로그래밍 언어 | 리액티브 프로그래밍 | 비동기 이벤트 스트림 처리를 위한 리액티브 프로그래밍 패러다임과 도구 |
| 함수형 프로그래밍 | 불변성과 부작용 없는 함수를 활용한 이벤트 처리 접근 방식 | |
| 동시성 모델 | 다양한 프로그래밍 언어의 동시성 모델과 메시지 처리 적용 | |
| 데이터 엔지니어링 | 데이터 파이프라인 설계 | 메시지/이벤트 브로커를 중심으로 한 데이터 파이프라인 아키텍처 |
| 스키마 설계 | 효율적인 메시지/이벤트 스키마 설계 원칙과 방법론 | |
| ETL과 ELT 통합 | 메시지/이벤트 브로커를 활용한 ETL/ELT 프로세스 구현 | |
| DevOps | 브로커 자동화 | 메시지/이벤트 브로커의 자동화된 배포, 설정, 관리 |
| 지속적 통합/배포 | 메시지 기반 시스템의 CI/CD 파이프라인 구축 | |
| 카오스 엔지니어링 | 메시지/이벤트 브로커 환경에서의 회복력 테스트 | |
| 인공지능 | ML 파이프라인 통합 | 이벤트 스트림을 활용한 ML 모델 훈련 및 서빙 |
| 이상 탐지 | 메시지/이벤트 스트림에서의 이상 탐지 기법 | |
| 스트림 기반 의사결정 | 실시간 이벤트를 기반으로 한 인공지능 의사결정 시스템 | |
| 시스템 설계 | 대규모 분산 시스템 | 수천만 사용자를 지원하는 메시지/이벤트 기반 시스템 설계 |
| 장애 내성 설계 | 다양한 장애 시나리오에 대응하는 시스템 아키텍처 | |
| 글로벌 배포 전략 | 지역 분산된 메시지/이벤트 브로커 인프라 구축 |
용어 정리
| 용어 | 설명 |
|---|---|
| AMQP(Advanced Message Queuing Protocol) | 메시지 지향 미들웨어를 위한 개방형 표준 프로토콜로, 클라이언트와 브로커 간의 통신에 사용됩니다. |
| 바인딩(Binding) | 메시지 브로커에서 교환소(Exchange)와 큐(Queue)를 연결하는 규칙으로, 어떤 메시지가 어떤 큐로 전달될지 결정합니다. |
| CDC(Change Data Capture) | 데이터베이스의 변경 사항을 실시간으로 추적하여 이벤트 스트림으로 변환하는 기술입니다. |
| 소비자(Consumer) | 메시지/이벤트 브로커로부터 메시지를 수신하여 처리하는 애플리케이션 또는 서비스입니다. |
| CQRS(Command Query Responsibility Segregation) | 명령(상태 변경)과 쿼리(상태 읽기)를 분리하는 아키텍처 패턴입니다. |
| DLQ(Dead Letter Queue) | 처리에 실패한 메시지를 저장하는 특수한 큐로, 나중에 분석하거나 재처리하는 데 사용됩니다. |
| 교환소(Exchange) | 메시지 브로커에서 메시지를 수신하여 라우팅 규칙에 따라 적절한 큐로 전달하는 컴포넌트입니다. |
| 이벤트 소싱(Event Sourcing) | 상태 변화를 일련의 이벤트로 저장하고, 이벤트를 재생하여 현재 상태를 복원하는 패턴입니다. |
| 멱등성(Idempotency) | 동일한 메시지가 여러 번 처리되더라도 시스템 상태가 동일하게 유지되는 속성입니다. |
| 메시지 브로커(Message Broker) | 메시지 검증, 변환, 라우팅을 통해 서로 다른 시스템 간의 통신을 중개하는 소프트웨어입니다. |
| MQTT(Message Queuing Telemetry Transport) | 경량 메시징 프로토콜로, 주로 IoT 기기 간 통신에 사용됩니다. |
| 오프셋(Offset) | 이벤트 스트림에서 소비자가 어디까지 메시지를 소비했는지 추적하는 위치 지표입니다. |
| 파티션(Partition) | 이벤트 브로커에서 주제(Topic)를 물리적으로 분할하여 병렬 처리를 가능하게 하는 단위입니다. |
| 생산자(Producer) | 메시지/이벤트 브로커에 메시지를 발행하는 애플리케이션 또는 서비스입니다. |
| 발행-구독(Publish-Subscribe) | 발행자가 메시지를 주제(Topic)에 발행하고, 해당 주제를 구독한 모든 구독자가 메시지를 수신하는 패턴입니다. |
| 큐(Queue) | 메시지 브로커에서 메시지가 소비자에게 전달되기 전까지 저장되는 버퍼입니다. |
| 사가(Saga) | 분산 트랜잭션을 구현하기 위해 일련의 로컬 트랜잭션과 보상 트랜잭션을 조합하는 패턴입니다. |
| 스키마 레지스트리(Schema Registry) | 메시지/이벤트 스키마를 중앙에서 관리하고 유효성을 검증하는 컴포넌트입니다. |
| STOMP(Simple Text Oriented Messaging Protocol) | 텍스트 기반의 간단한 메시징 프로토콜로, 다양한 언어와 플랫폼에서 쉽게 구현할 수 있습니다. |
| 주제(Topic) | 이벤트 브로커에서 특정 카테고리의 이벤트를 그룹화하는 논리적 채널입니다. |