-- SELECT: 데이터를 조회하는 기본 키워드
-- 지정된 컬럼의 데이터를 결과셋으로 반환
SELECTemployee_id,first_name,salaryFROMemployees;-- FROM: 데이터를 가져올 테이블을 지정
-- 여러 테이블을 콤마로 구분하거나 JOIN을 사용할 수 있음
SELECT*FROMemployees,departments;-- DISTINCT: 결과에서 중복된 행을 제거하는 데 사용
-- 기본 DISTINCT 사용
-- 부서별 unique한 직무 목록 조회
SELECTDISTINCTjob_idFROMemployees;-- 여러 컬럼에 DISTINCT 적용
-- 부서와 직무의 unique한 조합 조회
SELECTDISTINCTdepartment_id,job_idFROMemployees;-- COUNT와 함께 사용
-- 회사에 존재하는 직무 개수 조회
SELECTCOUNT(DISTINCTjob_id)asunique_jobsFROMemployees;-- GROUP BY와 함께 사용
SELECTdepartment_id,COUNT(DISTINCTjob_id)asjob_typesFROMemployeesGROUPBYdepartment_id;
-- LIMIT - 반환되는 결과의 최대 행 수를 제한합니다.
SELECT*FROMemployeesLIMIT10-- 상위 10개 행만 반환
-- OFFSET - 결과의 시작 위치를 지정합니다. LIMIT와 함께 자주 사용됩니다.
SELECT*FROMemployeesLIMIT10OFFSET20-- 21번째부터 30번째 행을 반환
-- FETCH - SQL 표준의 LIMIT와 유사한 기능을 합니다.
SELECT*FROMemployeesFETCHFIRST10ROWSONLY-- 페이지당 10개 항목, 3번째 페이지 조회
SELECT*FROMproductsORDERBYnameLIMIT10OFFSET20;-- (페이지 번호 - 1) * 페이지 크기 = OFFSET
-- WHERE: 조건절을 지정하여 특정 조건을 만족하는 데이터만 조회
-- AND, OR을 사용하여 여러 조건 조합 가능
SELECT*FROMemployeesWHEREsalary>50000ANDdepartment_id=10;-- IN: 값 목록 중 포함 여부
-- BETWEEN: 범위 조건
-- LIKE: 패턴 매칭
-- IS NULL: NULL 값 확인
SELECT*FROMemployeesWHEREdepartment_idIN(10,20,30)ANDsalaryBETWEEN40000AND60000ANDfirst_nameLIKE'김%'ANDmanager_idISNOTNULL;-- CASE - 조건에 따라 다른 값을 반환합니다.
-- WHEN - CASE 문에서 조건을 지정합니다.
-- THEN - 조건이 참일 때 반환할 값을 지정합니다.
-- ELSE - 모든 조건이 거짓일 때 반환할 값을 지정합니다.
SELECTname,CASEWHENage<20THEN'Young'WHENage<60THEN'Adult'ELSE'Senior'ENDasage_groupFROMusers;
-- GROUP BY: 지정된 컬럼을 기준으로 데이터를 그룹화
-- 주로 집계 함수와 함께 사용
SELECTdepartment_id,AVG(salary)FROMemployeesGROUPBYdepartment_id;-- ORDER BY: 결과를 정렬
-- ASC(오름차순), DESC(내림차순) 지정 가능
SELECT*FROMemployeesORDERBYsalaryDESC,first_nameASC;-- HAVING: GROUP BY로 그룹화된 데이터에 대한 조건 지정
-- WHERE는 개별 행에 대한 조건, HAVING은 그룹에 대한 조건
SELECTdepartment_id,AVG(salary)FROMemployeesGROUPBYdepartment_idHAVINGAVG(salary)>50000;
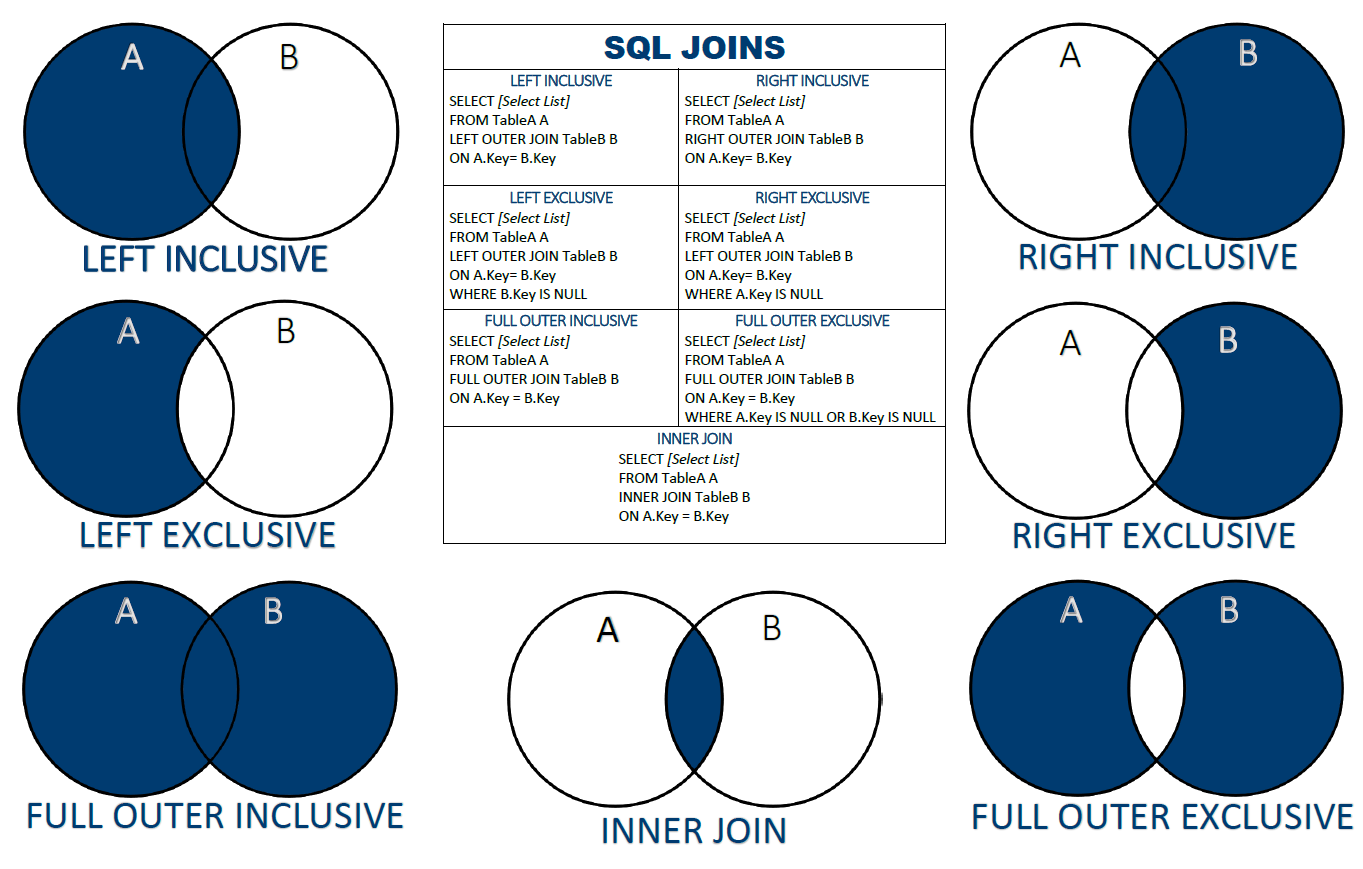
-- JOIN: 여러 테이블을 연결
-- INNER JOIN: 두 테이블에서 일치하는 데이터만 가져옵니다.
-- LEFT JOIN: 왼쪽 테이블의 모든 데이터와 오른쪽 테이블의 일치하는 데이터를 가져옵니다.
-- RIGHT JOIN: 오른쪽 테이블의 모든 데이터와 왼쪽 테이블의 일치하는 데이터를 가져옵니다.
-- FULL JOIN: 양쪽 테이블의 모든 데이터를 가져옵니다.
-- ON: 조인 조건 지정
SELECTe.first_name,d.department_nameFROMemployeeseJOINdepartmentsdONe.department_id=d.department_id;SELECTc.customer_name,o.order_dateFROMcustomerscLEFTJOINorderso-- 주문이 없는 고객도 포함
ONc.customer_id=o.customer_idWHEREo.amount>1000-- 고액 주문만 필터링
ORDERBYo.order_dateDESC;-- 최근 주문순 정렬
각 JOIN 유형은 데이터를 결합하는 방식이 다르므로, 상황에 따라 적절한 JOIN을 선택하여 사용해야 한다. INNER JOIN은 가장 일반적으로 사용되며, LEFT JOIN과 RIGHT JOIN은 누락된 데이터를 포함해야 할 때 유용하다. CROSS JOIN은 모든 조합을 생성하므로 주의해서 사용해야 하며, SELF JOIN은 계층 구조나 순위를 다룰 때 유용하다.
-- 직원과 부서 정보를 매칭하여 조회
-- 부서가 할당된 직원만 조회됨
SELECTe.employee_id,e.first_name,d.department_nameFROMemployeeseINNERJOINdepartmentsdONe.department_id=d.department_id;-- 다중 테이블 INNER JOIN
-- 직원, 부서, 위치 정보를 모두 매칭
SELECTe.first_name,d.department_name,l.cityFROMemployeeseINNERJOINdepartmentsdONe.department_id=d.department_idINNERJOINlocationslONd.location_id=l.location_id;
-- 모든 직원 정보와 해당되는 부서 정보 조회
-- 부서가 없는 직원도 포함됨
SELECTe.employee_id,e.first_name,d.department_nameFROMemployeeseLEFTJOINdepartmentsdONe.department_id=d.department_id;-- 부서가 없는 직원만 조회
SELECTe.employee_id,e.first_nameFROMemployeeseLEFTJOINdepartmentsdONe.department_id=d.department_idWHEREd.department_idISNULL;
-- 모든 부서 정보와 해당되는 직원 정보 조회
-- 직원이 없는 부서도 포함됨
SELECTd.department_name,e.first_nameFROMemployeeseRIGHTJOINdepartmentsdONe.department_id=d.department_id;-- 직원이 없는 부서만 조회
SELECTd.department_nameFROMemployeeseRIGHTJOINdepartmentsdONe.department_id=d.department_idWHEREe.employee_idISNULL;
FULL OUTER JOIN
FULL OUTER JOIN은 양쪽 테이블의 모든 레코드를 반환한다.
MySQL에서는 직접 지원하지 않지만, LEFT JOIN과 RIGHT JOIN을 UNION하여 구현할 수 있다.
-- 모든 직원과 모든 부서 정보를 조회
-- 매칭되지 않는 레코드도 모두 포함
SELECTe.first_name,d.department_nameFROMemployeeseFULLOUTERJOINdepartmentsdONe.department_id=d.department_id;-- 매칭되지 않는 레코드만 조회
SELECTe.first_name,d.department_nameFROMemployeeseFULLOUTERJOINdepartmentsdONe.department_id=d.department_idWHEREe.employee_idISNULLORd.department_idISNULL;
SELECTe.first_name,d.department_nameFROMemployeeseINNERJOINdepartmentsdONe.department_id=d.department_idWHEREe.salary>50000-- 먼저 필터링
ANDd.location_id=1700;
-- IS NULL - NULL 값을 확인합니다.
예:SELECT*fromusersWHEREphone_numberISNULL-- IS NOT NULL - NULL이 아닌 값을 확인합니다.
예:SELECT*fromusersWHEREemailISNOTNULL-- IFNULL/COALESCE - NULL 값을 다른 값으로 대체합니다.
예:SELECTIFNULL(phone,'No Phone')ascontactSELECTCOALESCE(phone,email,'No Contact')ascontact
-- UNION - 두 쿼리 결과를 합치고 중복을 제거합니다.
-- UNION ALL - 두 쿼리 결과를 중복 제거 없이 합칩니다.
-- INTERSECT - 두 쿼리 결과의 교집합을 반환합니다.
-- EXCEPT/MINUS - 첫 번째 쿼리 결과에서 두 번째 쿼리 결과를 뺀 차집합을 반환합니다.
예시:SELECTnameFROMemployeesUNIONSELECTnameFROMcontractors;
-- EXISTS: 서브쿼리 결과의 존재 여부 확인
-- 주문이 있는 고객만 조회
SELECTcustomer_nameFROMcustomerscWHEREEXISTS(SELECT1FROMordersoWHEREo.customer_id=c.customer_id);-- IN: 서브쿼리 결과 중 하나와 일치
-- 서울에 있는 부서의 직원들 조회
SELECTemployee_id,first_nameFROMemployeesWHEREdepartment_idIN(SELECTdepartment_idFROMdepartmentsWHERElocation='Seoul');-- ANY: 서브쿼리 결과 중 하나라도 조건 만족
-- 자신의 부서 평균 급여보다 많이 받는 직원 조회
SELECTfirst_name,salaryFROMemployeese1WHEREsalary>ANY(SELECTAVG(salary)FROMemployeese2WHEREe2.department_id=e1.department_id);-- ALL: 서브쿼리 결과 모두와 조건 만족
-- 모든 부서의 평균 급여보다 많이 받는 직원 조회
SELECTfirst_name,salaryFROMemployeesWHEREsalary>ALL(SELECTAVG(salary)FROMemployeesGROUPBYdepartment_id);-- SOME: ANY와 동일한 의미
SELECTfirst_name,salaryFROMemployeesWHEREsalary>SOME(SELECTsalaryFROMemployeesWHEREdepartment_id=20);
-- 각 부서별 평균 급여보다 많이 받는 직원 조회
SELECTe1.first_name,e1.salary,e1.department_idFROMemployeese1WHEREsalary>(SELECTAVG(salary)FROMemployeese2WHEREe2.department_id=e1.department_id);
-- FROM 절에서 서브쿼리 사용
SELECTe.first_name,d.avg_salaryFROMemployeeseJOIN(SELECTdepartment_id,AVG(salary)asavg_salaryFROMemployeesGROUPBYdepartment_id)dONe.department_id=d.department_idWHEREe.salary>d.avg_salary;
-- 서브쿼리보다 JOIN이 더 효율적인 경우
-- 비효율적인 방법:
SELECT*FROMemployeeseWHEREdepartment_idIN(SELECTdepartment_idFROMdepartmentsWHERElocation_id=1700);-- 효율적인 방법:
SELECTe.*FROMemployeeseJOINdepartmentsdONe.department_id=d.department_idWHEREd.location_id=1700;
-- CREATE: 데이터베이스 객체 생성
CREATETABLEemployees(employee_idINTPRIMARYKEY,first_nameVARCHAR(50));-- ALTER: 데이터베이스 객체 수정
ALTERTABLEemployeesADDCOLUMNemailVARCHAR(100);-- DROP: 데이터베이스 객체 삭제
DROPTABLEemployees;-- TRUNCATE: 테이블 데이터 전체 삭제
TRUNCATETABLEtemp_data;
-- PRIMARY KEY: 기본키 지정
-- FOREIGN KEY: 외래키 지정
-- UNIQUE: 고유값 제약조건
-- CHECK: 값의 범위나 조건 지정
-- DEFAULT: 기본값 지정
CREATETABLEorders(order_idINTPRIMARYKEY,customer_idINTFOREIGNKEYREFERENCEScustomers(id),order_dateDATEDEFAULTCURRENT_DATE,amountDECIMAL(10,2)CHECK(amount>0));
-- INSERT: 새로운 데이터 추가
INSERTINTOemployees(first_name,last_name,salary)VALUES('길동','홍',50000);-- UPDATE: 기존 데이터 수정
UPDATEemployeesSETsalary=salary*1.1WHEREdepartment_id=20;-- DELETE: 데이터 삭제
DELETEFROMemployeesWHEREemployment_status='RESIGNED';-- MERGE: 데이터 병합 (업서트)
MERGEINTOtarget_tabletUSINGsource_tablesON(t.id=s.id)WHENMATCHEDTHENUPDATEWHENNOTMATCHEDTHENINSERT;
-- CREATE INDEX - 인덱스를 생성합니다.
-- DROP INDEX - 인덱스를 삭제합니다.
-- EXPLAIN - 쿼리의 실행 계획을 확인합니다.
예시:CREATEINDEXidx_emailONusers(email);EXPLAINSELECT*FROMusersWHEREemail='test@example.com';
-- CREATE VIEW - 가상 테이블(뷰)을 생성합니다.
-- ALTER VIEW - 기존 뷰를 수정합니다.
-- DROP VIEW - 뷰를 삭제합니다.
-- MATERIALIZED VIEW - 실제 데이터를 저장하는 뷰를 생성합니다.
예시:CREATEVIEWactive_employeesASSELECT*FROMemployeesWHEREstatus='active';
-- TRIM - 문자열 앞뒤의 공백을 제거합니다.
-- LTRIM - 문자열 왼쪽의 공백을 제거합니다.
-- RTRIM - 문자열 오른쪽의 공백을 제거합니다.
-- REPLACE - 문자열 내의 특정 문자를 다른 문자로 대체합니다.
예시:SELECTTRIM(' Hello World ')ascleaned_text,REPLACE(email,'@','[at]')asmasked_emailFROMusers;
-- DATE_ADD/DATEADD - 날짜에 특정 기간을 더합니다.
-- DATE_SUB/DATESUB - 날짜에서 특정 기간을 뺍니다.
-- DATE_TRUNC - 날짜를 특정 단위로 잘라냅니다.
-- EXTRACT - 날짜에서 특정 부분(년, 월, 일 등)을 추출합니다.
예시:SELECTDATE_ADD(current_date,INTERVAL1MONTH)asnext_month,EXTRACT(YEARFROMhire_date)ashire_yearFROMemployees;
-- WITH (CTE) - Common Table Expression을 정의합니다.
-- TEMPORARY/TEMP - 임시 테이블을 생성합니다.
예시:WITHmonthly_salesAS(SELECTDATE_TRUNC('month',sale_date)asmonth,SUM(amount)astotalFROMsalesGROUPBYDATE_TRUNC('month',sale_date))SELECT*FROMmonthly_sales;