Column Oriented
컬럼형 데이터베이스(Columnar database) 또는 컬럼 지향 데이터베이스(Column-oriented database)는 NoSQL 데이터베이스의 한 유형으로, 데이터를 행이 아닌 열 단위로 저장하는 특징을 가지고 있다.
이러한 구조는 대규모 데이터 분석과 복잡한 쿼리 처리에 최적화되어 있다.
컬럼형 데이터베이스는 대규모 데이터 분석, 데이터 웨어하우징, 비즈니스 인텔리전스 등의 분야에서 뛰어난 성능을 보인다. 특히 읽기 위주의 작업과 대량의 데이터를 다루는 환경에서 그 장점이 두드러진다.
그러나 트랜잭션 처리나 실시간 데이터 업데이트가 빈번한 환경에서는 상대적으로 성능이 떨어질 수 있으므로, 사용 목적과 환경에 따라 적절히 선택해야 한다.
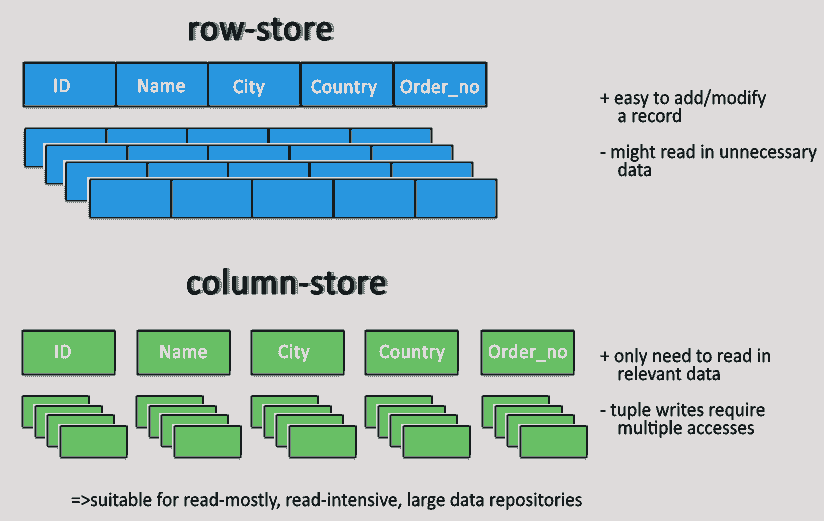
컬럼형 데이터베이스의 기본 개념
컬럼형 데이터베이스는 데이터를 열 단위로 저장한다.
예를 들어, 다음과 같은 테이블이 있다고 가정해보자:
| column 1 | column 2 | column 3 |
|---|---|---|
| item 11 | item 12 | item 13 |
| item 21 | item 22 | item 23 |
이 데이터는 컬럼형 데이터베이스에서 다음과 같이 저장된다:
| item 11 | item 21 | item 12 | item 22 | item 13 | item 23 |
|---|
즉, 각 열의 데이터가 연속적으로 저장되는 구조이다.
| |
컬럼형 데이터베이스의 특징
데이터 압축: 같은 열의 데이터는 유사한 형식을 가지므로 효율적인 압축이 가능하다.
빠른 쿼리 성능: 특정 열에 대한 쿼리를 실행할 때, 필요한 열만 읽으면 되므로 I/O를 줄이고 성능을 향상시킨다.
확장성: 대규모 데이터셋을 처리하는 데 적합하며, 수평적 확장이 용이하다.
분석 최적화: 집계 함수와 같은 분석 작업에 특히 효과적이다.
희소 데이터 처리: 누락된 값이 많은 데이터셋을 효율적으로 처리할 수 있다.
컬럼형 데이터베이스의 장단점
장점
- 빠른 데이터 검색과 집계: 특정 열에 대한 연산이 빠르다.
- 효율적인 저장 공간 사용: 데이터 압축률이 높아 저장 공간을 절약할 수 있다.
- 분석 쿼리 성능 향상: OLAP 작업에 최적화되어 있다.
단점
- 쓰기 성능 저하: 데이터 삽입이나 업데이트가 상대적으로 느리다.
- 트랜잭션 처리 비효율: OLTP 작업에는 적합하지 않다.
- 단일 레코드 조회 비효율: 여러 열의 데이터를 동시에 조회할 때 성능이 저하될 수 있다.
주요 사용 사례
- 데이터 웨어하우징: 대규모 데이터 저장 및 분석에 적합하다.
- 비즈니스 인텔리전스: 복잡한 보고서 생성과 데이터 시각화에 유용하다.
- 빅데이터 분석: 대용량 데이터셋에 대한 실시간 분석이 가능하다.
- 시계열 데이터 분석: IoT 데이터나 로그 분석과 같은 시계열 데이터 처리에 효과적이다.
- 머신러닝과 AI: 특징 추출 및 대규모 데이터셋 처리에 활용된다.
주요 컬럼형 데이터베이스 예시
- Apache Cassandra: 분산 NoSQL 데이터베이스로, 컬럼 패밀리 모델을 채택했다.
- Amazon Redshift: AWS의 데이터 웨어하우스 솔루션으로, 대규모 분석에 최적화되어 있다.
- Google BigQuery: 구글의 서버리스 데이터 웨어하우스로, 페타바이트 규모의 데이터 분석이 가능하다.
- ClickHouse: 실시간 분석 처리에 특화된 오픈소스 컬럼형 DBMS이다.
- Snowflake: 클라우드 기반의 데이터 웨어하우스 솔루션이다.