Message Broker
메시지 브로커는 다양한 애플리케이션, 서비스, 시스템 간 메시지 교환을 중개하는 미들웨어로, 비동기 통신, 결합도 감소, 확장성, 신뢰성, 장애 복원력 등 백엔드 시스템에 필수적인 역할을 한다. 메시지 큐 (Queue), 토픽 (Topic), 교환기 (Exchange) 등 다양한 구조를 통해 Point-to-Point, Publish/Subscribe 등 다양한 패턴을 지원하며, RabbitMQ, Kafka, ActiveMQ, Amazon SQS 등 다양한 솔루션이 존재한다. 메시지 브로커는 마이크로서비스, IoT, 실시간 데이터 처리, 대용량 트래픽 분산 등 다양한 분야에서 활용된다.
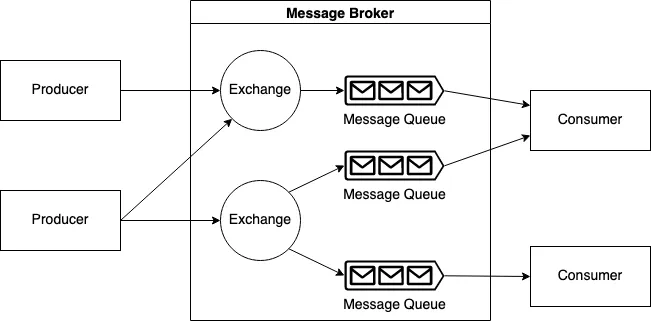
배경
등장 배경:
- 분산 시스템의 복잡성 증가
- 서비스 간 직접 통신의 한계
- 시스템 결합도 감소 필요성
- 비동기 처리 요구사항 증가
역사적 발전:
- 1960 년대: 메인프레임 환경에서 메시지 큐잉 개념 등장
- 1990 년대: 분산 시스템 확산으로 메시지 미들웨어 발전
- 2000 년대: 웹 서비스와 SOA (Service-Oriented Architecture) 확산
- 2010 년대: 클라우드와 마이크로서비스 아키텍처 보편화
목적 및 필요성
주요 목적:
- 시스템 분리 (Decoupling): 서비스 간 의존성 감소
- 확장성 (Scalability): 시스템 부하 분산
- 신뢰성 (Reliability): 메시지 전달 보장
- 유연성 (Flexibility): 동적 라우팅 및 변환
필요성:
- 대규모 분산 시스템에서 서비스 간 통신 복잡성 관리
- 일시적 서비스 장애 시 메시지 손실 방지
- 다양한 프로토콜과 데이터 형식 간 변환 필요
- 실시간 이벤트 처리 요구사항 증가
핵심 개념
메시지 브로커 (Message Broker) 란, 분산 시스템에서 애플리케이션 간 메시지 교환을 중개하는 미들웨어 소프트웨어이다. 송신자와 수신자 사이에서 메시지를 저장, 라우팅, 변환하는 역할을 수행한다.
기본 개념
| 범주 | 개념 | 설명 |
|---|---|---|
| 1. 역할 (Role) | Producer | 메시지를 생성하여 브로커에 발송하는 역할의 애플리케이션 또는 서비스 |
| Consumer | 브로커로부터 메시지를 수신하고 처리하는 역할의 애플리케이션 또는 서비스 | |
| Consumer Group | 동일한 토픽을 구독하는 소비자들의 집합으로, 부하 분산 및 병렬 처리를 가능하게 함 | |
| 2. 구조 (Structure) | Queue | 선입선출 (FIFO) 방식의 메시지 저장소, Point-to-Point 통신 모델에 사용됨 |
| Topic | Pub/Sub 구조에서 메시지를 발행하고 구독하는 논리적 채널 | |
| Partition | 대용량 메시지 처리를 위해 토픽을 나눈 단위, Kafka 등에서 사용 | |
| Offset | 특정 파티션 내 메시지의 고유 위치를 나타내는 식별자 | |
| Exchange | (AMQP 기반) 메시지를 큐로 라우팅하기 위한 전략 설정 컴포넌트 (direct, fanout, topic 등) | |
| Routing Key | 메시지의 목적지 큐를 결정하는 키 값 (AMQP 모델에서 Exchange 와 함께 동작) | |
| Dead Letter Queue | 처리 실패 메시지를 따로 저장해 추후 재처리하거나 분석할 수 있는 특수 큐 | |
| 3. 동작 (Behavior) | Message | 전송되는 데이터 단위. 메타데이터 (헤더) 와 실제 데이터 (페이로드) 로 구성 |
| Message Routing | 메시지를 특정 규칙에 따라 적절한 큐 또는 소비자에게 전달하는 과정 | |
| Message Filtering | 메시지를 조건에 따라 선별적으로 라우팅하거나 소비자에게 전달하는 기능 | |
| 4. 운영 특성 (Operations) | Message Broker | 생산자와 소비자 사이에서 메시지를 안전하게 중개하고 관리하는 미들웨어 시스템 |
| Asynchronous Communication | 메시지를 비동기적으로 처리하여 송신자가 응답을 기다리지 않아도 되는 통신 방식 | |
| ACK (Acknowledgment) | 메시지를 성공적으로 수신 및 처리했음을 브로커에 알리는 신호 | |
| Durability | 시스템 장애나 브로커 다운 시에도 메시지를 손실 없이 보존하는 특성 |
실무 구현 연관성
- 시스템 설계 측면: 마이크로서비스 아키텍처에서 서비스 간 통신 구현
- 성능 측면: 비동기 처리를 통한 시스템 처리량 향상
- 안정성 측면: 메시지 지속성과 장애 복구 메커니즘 구현
- 확장성 측면: 수평적 확장이 가능한 분산 시스템 구현
주요 기능 및 역할
핵심 기능:
- 메시지 라우팅 (Message Routing): 목적지 결정 및 전달
- 메시지 큐잉 (Message Queuing): 임시 저장 및 순서 관리
- 메시지 변환 (Message Transformation): 형식 및 프로토콜 변환
- 전달 보장 (Delivery Guarantee): 메시지 손실 방지
- 로드 밸런싱 (Load Balancing): 부하 분산
시스템에서의 역할:
- 중재자 (Mediator): 서비스 간 통신 중개
- 버퍼 (Buffer): 일시적 과부하 상황 완충
- 게이트웨이 (Gateway): 외부 시스템과의 인터페이스
- 이벤트 허브 (Event Hub): 이벤트 중심 아키텍처의 중심
특징
기술적 특징:
- 비동기 통신 (Asynchronous Communication): 송수신자 독립 실행
- 메시지 지속성 (Message Persistence): 디스크 기반 저장
- 트랜잭션 지원 (Transaction Support): ACID 속성 보장
- 클러스터링 (Clustering): 고가용성 및 확장성
운영적 특징:
- 모니터링 (Monitoring): 실시간 상태 추적
- 관리 도구 (Management Tools): 웹 기반 관리 인터페이스
- 보안 (Security): 인증, 권한 부여, 암호화 지원
- 표준 호환성 (Standards Compliance): JMS, AMQP 등 표준 지원
핵심 원칙
- 메시지 지향 (Message-Oriented): 모든 통신은 메시지를 통해 이루어진다.
- 비동기성 (Asynchronicity): 생산자와 소비자는 동시에 활성화될 필요가 없다.
- 일관성 (Consistency): 모든 메시지는 정확히 한 번 또는 최소 한 번 전달되어야 한다.
- 신뢰성 (Reliability): 메시지는 손실되지 않아야 한다.
- 확장성 (Scalability): 메시지 양이 증가해도 효율적으로 처리할 수 있어야 한다.
- 내구성 (Durability): 시스템 장애 시에도 메시지가 유지되어야 한다.
설계 원칙:
- 느슨한 결합 (Loose Coupling): 서비스 간 독립성 유지
- 높은 가용성 (High Availability): 24/7 서비스 제공
- 확장성 (Scalability): 부하 증가에 따른 확장 가능
- 일관성 (Consistency): 메시지 순서 및 상태 보장
- 내결함성 (Fault Tolerance): 장애 상황 대응
주요 원리 및 작동 원리
메시지 전달 원리:
sequenceDiagram
participant P as Producer
participant B as Message Broker
participant C as Consumer
P->>B: 1. Send Message
B->>B: 2. Store in Queue
B->>B: 3. Route Message
C->>B: 4. Request Message
B->>C: 5. Deliver Message
C->>B: 6. Acknowledge
B->>B: 7. Remove from Queue
작동 방식:
- 메시지 수신: 프로듀서로부터 메시지 받기
- 메시지 저장: 큐 또는 토픽에 임시 저장
- 라우팅 결정: 메시지 목적지 결정
- 메시지 전달: 컨슈머에게 메시지 전송
- 확인 처리: 전달 완료 확인 및 정리
구조 및 아키텍처
graph TB
subgraph "Producer Applications"
P1[Producer 1]
P2[Producer 2]
P3[Producer 3]
end
subgraph "Message Broker Cluster"
subgraph "Broker Node 1"
Q1[Queue Manager]
R1[Router]
S1[Storage]
end
subgraph "Broker Node 2"
Q2[Queue Manager]
R2[Router]
S2[Storage]
end
LB[Load Balancer]
end
subgraph "Consumer Applications"
C1[Consumer 1]
C2[Consumer 2]
C3[Consumer 3]
end
P1 --> LB
P2 --> LB
P3 --> LB
LB --> Q1
LB --> Q2
Q1 --> C1
Q2 --> C2
Q1 --> C3
구성요소
| 구분 | 구성요소 | 기능 | 역할 | 특징 |
|---|---|---|---|---|
| 필수 | 메시지 큐 매니저 (Queue Manager) | 큐 생성, 관리, 삭제 | 메시지 저장소 관리 | FIFO, 우선순위 지원 |
| 라우터 (Router) | 메시지 목적지 결정 | 라우팅 규칙 적용 | 컨텐츠 기반, 토픽 기반 | |
| 스토리지 엔진 (Storage Engine) | 메시지 지속성 보장 | 디스크 저장 관리 | 트랜잭션, 복제 지원 | |
| 프로토콜 어댑터 (Protocol Adapter) | 다양한 프로토콜 지원 | 프로토콜 변환 | AMQP, MQTT, HTTP | |
| 선택 | 메시지 변환기 (Transformer) | 데이터 형식 변환 | 프로토콜 간 변환 | XML, JSON, 바이너리 |
| 보안 모듈 (Security Module) | 인증 및 권한 관리 | 접근 제어 | SSL/TLS, OAuth | |
| 모니터링 도구 (Monitoring Tool) | 성능 추적 | 상태 감시 | 대시보드, 알림 | |
| 관리 콘솔 (Management Console) | 시스템 관리 | 설정 및 운영 | 웹 UI, REST API |
구현 기법
| 구현 기법 분류 | 패턴/기법 이름 | 정의 및 목적 | 구성 요소 | 실제 예시 (시스템/시나리오) | |
|---|---|---|---|---|---|
| 1. 메시징 패턴 | Point-to-Point (P2P) | 1:1 메시지 전달로 소비자 간 경쟁 처리 수행, 작업 큐 기반 병렬 처리에 적합 | Producer, Queue, Consumer | 주문 처리, 비동기 태스크 큐 (RabbitMQ Simple Queue, SQS 등) | |
| Publish/Subscribe | 1:N 메시지 브로드캐스트, 이벤트 전파 및 상태 동기화용 구조 | Publisher, Topic, Subscribers | 사용자 이벤트 알림, 실시간 로그 처리 (Kafka, Redis PubSub 등) | ||
| Request/Reply | 동기적 요청 - 응답 구조를 비동기 메시지 기반으로 구현, RPC 대체 | Request Queue, Response Queue, Client, Server | 마이크로서비스 간 사용자 인증 요청 (gRPC-like via MQ) | ||
| Competing Consumers | 하나의 큐를 여러 컨슈머가 병렬적으로 소비하여 수평 확장성 및 Throughput 확보 | Shared Queue, Multiple Consumers | 이미지 처리 워커, ETL 작업 분산 처리 | ||
| Event Sourcing | 상태 저장 대신 모든 변경을 이벤트로 기록, 시간 기반 복원 및 감사 가능 | Event Producer, Event Store, Replayer | 금융 거래, 사용자 행동 추적 로그 저장 (Kafka, EventStore 등) | ||
| 2. 메시지 라우팅 | Direct Routing | 정확한 라우팅 키를 기준으로 메시지를 특정 큐에 전달 | Exchange, Routing Key, Queue | 주문 유형에 따라 결제/배송 서비스 분기 (RabbitMQ Direct Exchange) | |
| Topic Routing | 와일드카드 기반 키 패턴으로 메시지를 큐에 매핑 | Exchange, Routing Key Pattern, Queue | logs.error, logs.# (RabbitMQ Topic Exchange) | ||
| Fan-out | 메시지를 모든 바인딩 큐에 복사 → 브로드캐스트용 | Exchange, Multiple Queues | 실시간 대시보드 동기화, 로그 전파 (RabbitMQ Fanout, Kafka 등) | ||
| Header-based Routing | 헤더 값 기준 라우팅 (내용이 아닌 메타데이터 기반) | Exchange, Headers, Queues | 메시지 우선순위/서비스 타입 분기 (RabbitMQ Headers Exchange) | ||
| Content-based Routing | 메시지 페이로드를 파싱하여 라우팅 | 메시지 필터, 파서, 다중 큐 | 이메일 필터, 실시간 알림 필터링 (Apache Camel 등) | ||
| 3. 신뢰성 / 보장 기법 | DLQ (Dead Letter Queue) | 실패한 메시지를 별도 큐에 보관, 재처리 및 장애 분석 가능 | Primary Queue, DLQ | 비정상 메시지 보관 후 수동/자동 재처리 (Kafka, RabbitMQ DLQ) | |
| Exactly-once Delivery | 중복 없이 정확히 한 번만 전달 보장, 복잡한 구현 필요 | Offset Commit, Transaction, Idempotent Producer | 금융 트랜잭션, 재고 처리 (Kafka Transactions API 등) | ||
| At-least-once Delivery | 한 번 이상 전달 보장, 재시도 허용하며 멱등성 설계 필요 | ACK, Retry, Consumer Offset | 로그 수집, 알림 전송 (Kafka, RabbitMQ, Pulsar 기본) | ||
| Idempotent Messaging | 동일 메시지에 대해 여러 번 처리해도 결과가 동일하도록 설계 | Unique ID, Deduplication Logic | 알림 중복 제거, 트랜잭션 중복 방지 | ||
| 4. 메시지 저장/전송 | In-memory Messaging | 속도 우선의 비휘발성 저장소 없는 메시지 처리 | RAM 기반 브로커 또는 캐시 구조 | Redis PubSub, MemQueue | |
| Persistent Messaging | 메시지를 디스크에 저장해 내구성 보장 및 재처리 가능 | Write-ahead Log, Persistent Queue | Kafka, Pulsar, SQS, RabbitMQ durable queue | ||
| Streaming / Log-based | 이벤트 로그 저장 기반의 파티셔닝/오프셋 기반 스트리밍 | Topic, Partition, Offset, Consumer Group | Kafka Streams, Pulsar Functions, Flink Streaming 등 |
장점
| 카테고리 | 항목 | 설명 |
|---|---|---|
| 1. 아키텍처 유연성 | 시스템 결합도 완화 (Decoupling) | 송신자와 수신자가 직접 연결되지 않고 브로커를 통해 간접 통신하므로 독립적인 배포, 확장, 테스트가 용이함 |
| 다양한 메시징 패턴 지원 | Queue, Pub/Sub, Routing 등 다양한 통신 구조를 지원하여 아키텍처 설계에 유연성을 제공함 | |
| 유연한 서비스 진화/확장 가능 | 구성 요소 간 영향 없이 기능 추가/변경 가능. MSA, 이벤트 기반 아키텍처와 궁합이 뛰어남 | |
| 2. 신뢰성/복원력 | 메시지 유실 방지 | 메시지를 디스크에 영속적으로 저장하거나 ACK 기반 처리로 안정성 보장 |
| 재처리 및 복구 지원 | DLQ, Retry Policy 등으로 실패 메시지 추적 및 재처리 가능 | |
| 트랜잭션 및 정확한 전달 보장 | Exactly-once, At-least-once 등의 QoS 정책으로 메시지 전달 신뢰성 보장 | |
| 3. 확장성/성능 | 수평 확장성 (Scalability) | Consumer Group, Partition 기반의 분산 처리로 트래픽 증가에 유연 대응 가능 |
| 비동기 처리로 성능 최적화 | 송신자 - 수신자 간 비동기 처리로 응답 속도 단축, 병렬 처리 극대화 가능 | |
| 부하 분산 (Load Distribution) | 여러 Consumer 간 자연스러운 작업 분배로 시스템 과부하 방지 | |
| 4. 운영 효율성 | 지속 가능한 메시지 보관 | 메시지 저장 기간 설정 (TTL), 로그 기반 저장으로 이벤트 소싱, 리플레이 등 다양한 기능 가능 |
| QoS 및 제어 정책 활용 가능 | 우선순위 큐, TTL, 흐름 제어, 트랜잭션 정책 등으로 세밀한 메시지 흐름 제어 가능 | |
| 모니터링 및 장애 격리 용이 | 구성 요소 간 격리로 장애 전파 최소화. APM, 메시지 추적 시스템 연동 가능 |
단점과 문제점 그리고 해결방안
단점
| 항목 | 설명 | 해결방안 |
|---|---|---|
| 복잡성 증가 | 메시지 브로커 도입으로 전체 아키텍처가 복잡해지고 학습 곡선 증가 | 아키텍처 문서화, 표준 운영 도구 도입, 운영자 교육 강화 |
| 비동기 흐름 추적 어려움 | 비동기 구조로 인해 디버깅 및 이벤트 흐름 파악이 어려움 | Correlation ID, OpenTelemetry 등 분산 추적 도구 도입 |
| 메시지 순서 유지 어려움 | 다중 Consumer 및 파티셔닝 구조에서 메시지 순서 보장 어려움 | 순서 키 (Key) 기반 파티셔닝, 단일 Consumer 처리, 메시지 시퀀싱 적용 |
| 중복 메시지 처리 필요 | 네트워크 장애, 재전송 등으로 동일 메시지가 중복 처리될 수 있음 | Idempotency 설계, 메시지 ID 추적, 중복 방지 로직 도입 |
| 네트워크/브로커 의존성 | 네트워크/브로커 장애 시 전체 시스템에 영향 미칠 수 있음 | 브로커 복제 구성, 멀티 브로커 클러스터 구성, 이중화된 네트워크 구성 |
| 성능 오버헤드 | 직렬화/역직렬화, 네트워크 전송 등으로 인한 지연 발생 | 경량 포맷 (Avro, Protobuf), 배치 전송, 압축 적용, 네트워크 최적화 |
| 리소스 병목 가능성 | 큐/브로커 과부하 시 시스템 전체 지연 유발 가능 | 오토스케일링, 병렬 파티션 구조 도입, 워커 수동 증설 |
| 운영 및 테스트 어려움 | 메시지 흐름 및 외부 시스템 의존성으로 통합 테스트가 어려움 | Testcontainers, Mock Broker, Consumer Contract Testing 도입 |
문제점
| 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방안 |
|---|---|---|---|---|---|
| 메시지 유실 | ACK 누락, 브로커 장애, 저장 실패 | 데이터 손실, 트랜잭션 불일치 | 메시지 전송 로그, DLQ/오프셋 미매칭 탐지 | 강제 ACK 설정, 복제, 재전송 정책 적용 | DLQ + Retry Queue 구성, 복제된 브로커로 재시도 |
| 메시지 중복 처리 | 재전송, 네트워크 타임아웃, Producer 재시도 | 중복 실행, 데이터 무결성 훼손 | 중복 메시지 로그, 이벤트 ID 추적 | Idempotency 키 기반 설계, 메시지 식별 ID 부여 | 중복 제거 처리 로직 도입, 보상 트랜잭션 적용 |
| 순서 보장 실패 | 파티셔닝 분산, 병렬 처리, 네트워크 지연 | 순서 바뀐 처리, 업무 로직 오류 발생 | 메시지 시퀀스 로그, 이벤트 흐름 시각화 | 순서 키, 단일 파티션 적용 | 메시지 시퀀싱, 재정렬 로직, 순서 보정 큐 적용 |
| 큐 오버플로우 | Consumer 처리 속도 < Producer 전송 속도 | 큐 적체, 시스템 병목 | 큐 길이 모니터링, 처리량 대비 TPS 초과 경보 | 백프레셔 적용, 처리 속도 개선 | Auto Scaling, Rate Limiting, 스로틀링 도입 |
| 데드 레터 큐 누적 | 처리 실패 반복, DLQ 미정리 | 스토리지 과다 사용, 재처리 실패 | DLQ 상태 모니터링, 실패율 추적 | Retry 제한 설정, 오류 분류 | DLQ 자동 정리 주기 설정, 실패 원인 분석 및 코드 개선 |
| 부적절한 라우팅 | 잘못된 라우팅 키, Exchange 설정 오류 | 메시지 누락, 잘못된 큐 전송 | 라우팅 로그 분석, 미전달 메시지 탐지 | 라우팅 키 패턴 일관화, Exchange 유형 적절 구성 | 메시지 테스트 자동화, 미스매치 로그 경고 트리거 구성 |
| 처리 지연 | 워커 부족, 트래픽 급증, 부하 예측 실패 | 응답 지연, SLA 위반 | 지연 시간 모니터링, 큐 소비 속도 분석 | 워커 자동 증설, 부하 예측 기반 계획 수립 | 수평 확장, 병렬 소비자 구성, 파티션 수 증가 |
도전 과제
| 카테고리 | 과제 항목 | 원인 또는 문제점 | 영향/위험 요소 | 대응 전략 및 해결 방법 |
|---|---|---|---|---|
| 1. 메시징 설계 및 일관성 | 메시지 순서 보장 | 분산 시스템에서 파티션 간 병렬 처리 시 순서 유지 어려움 | 순서 역전으로 인한 데이터 불일치, 상태 오류 | Partition Key 사용, FIFO Queue 설계, Ordering ID 활용 |
| Exactly-once Delivery | 중복 전송, 중복 소비 가능성 | 트랜잭션 오류, 재처리 중복, 중복 과금 등 위험 발생 | Idempotent Producer, Kafka Transactions, 메시지 ID 기반 deduplication | |
| 중복 수신 및 메시지 유실 | 네트워크 장애, 비 ACK 소비, 브로커 장애 | 데이터 손실, 중복 처리, 상태 정합성 파괴 | ACK 체계 강화, DLQ 구성, 멱등성 설계, 재시도 백오프 적용 | |
| 트랜잭션 처리 어려움 | 다중 메시지 및 시스템 간 원자성 보장 어려움 | 부분 커밋으로 인한 데이터 정합성 문제 | Outbox 패턴, Saga, 이벤트 기반 트랜잭션 분리 설계 | |
| 2. 확장성 및 성능 | 큐 병목/지연 발생 | Producer 속도 > Consumer 처리 속도 | 메시지 지연, Lag 증가, 사용자 응답 저하 | Auto-scaling, Consumer 증설, Queue Sharding, Rate Limiting 적용 |
| 대규모 확장 시 라우팅 복잡도 | 도메인 분리 미흡, 큐/토픽 설계 기준 없음 | 관리 포인트 증가, 라우팅 충돌 | 도메인 기반 큐 설계, Exchange 패턴 활용, 명확한 메시지 도메인 설계 기준 수립 | |
| 서버리스 환경 통합 어려움 | FaaS 는 장시간 연결 및 세션 상태 유지 불가 | 메시지 손실, 지연 증가, 재처리 복잡성 | Push 기반 Pub/Sub 연동, CloudEvent + Lambda 최적화 | |
| 성능 최적화 한계 | I/O, 네트워크, 메시지 포맷 비효율 | Throughput 저하, 리소스 낭비 | 배치 처리, 직렬화 포맷 최적화 (Avro, Protobuf), 메시지 크기 관리 | |
| 3. 관측성 및 운영 | 메시지 흐름 가시성 부족 | 큐 내부는 비가시적이며 중간 상태 확인 어려움 | 디버깅/장애 분석 불가, SLA 위반 | 메시지 추적 ID 부여, 분산 트레이싱 (OpenTelemetry), 상태 대시보드 구성 |
| Consumer Lag 관리 어려움 | Lag 증감 패턴 실시간 모니터링 어려움 | 메시지 적체, 소비자 병목 | Lag 지표 수집 및 Alerting, 대시보드 기반 워커 수 증감 자동화 | |
| 운영 자동화 부재 | 리소스 수동 관리, 장애 탐지 지연 | 운영 인건비 증가, 장애 장기화 | Auto-scaling, Self-healing 정책, 메시징 플랫폼 전용 오퍼레이터 도입 (e.g., Strimzi, KEDA) | |
| 모니터링/알림 미흡 | 시스템 지표 부족, 경보 체계 미도입 | SLA 위반, 실시간 대응 실패 | Prometheus + Alertmanager, 로그 기반 알림 시스템 연동 | |
| 4. 장애 및 복구 | 브로커 장애 대응 | 단일 장애점 (SPOF), 복제 지연 | 메시지 손실, 서비스 중단 | 고가용성 클러스터 구성, Leader Election, 복제 지연 지표 모니터링 |
| DLQ 처리 복잡성 | DLQ 메시지 재처리 로직 미비 | 영구 손실 또는 중복 재처리 | DLQ → Retry Queue 자동 전환, 오류 분류에 따른 처리 정책 분리 | |
| 백프레셔 대응 미흡 | 소비 속도 초과 생산 발생 시 시스템 오버로드 | 메시지 유실, API Time-out | Rate Limit, Circuit Breaker, 생산자 전송 제어 적용 | |
| 5. 보안 및 규정 준수 | 접근 제어/암호화 부족 | 인증/인가 체계 미흡, 평문 메시지 전달 | 데이터 노출, 인증 우회 가능성 | SASL, TLS, RBAC, 메시지 암호화 (AES, KMS) 도입 |
| 규제 대응 한계 | GDPR, HIPAA 등 요구 조건 미준수 | 법적 책임, 보안 인증 실패 | 데이터 암호화, 감사 로그, 민감 정보 필드 마스킹 | |
| 제로 트러스트 미적용 | 외부 연결 및 경계 기반 보안에 의존 | 내부 공격자 접근 위험 증가 | Zero Trust Architecture, 서비스 간 Mutual TLS 적용 | |
| 6. 이기종 환경 연동 | 멀티 클라우드/온프레미스 연동 | 이기종 브로커 간 메시지 포맷/프로토콜 상이 | 표준화 부족, 복잡한 변환 로직 필요 | 표준 메시징 포맷 (CloudEvents), 브로커 간 메시지 브리지 (Kafka MirrorMaker, Event Mesh 등) 사용 |
| 데이터 포맷/스키마 충돌 | JSON/Avro/Protobuf 혼용 시 포맷 충돌 발생 | 역직렬화 오류, 소비 실패 | Schema Registry 활용, 스키마 버전 관리 및 호환성 테스트 체계 구축 |
분류에 따른 종류 및 유형
| 분류 기준 | 유형 | 설명 및 특징 | 대표 제품 | 주요 적용 사례 |
|---|---|---|---|---|
| 1. 메시징 패턴 | Queue (Point-to-Point) | 1:1 지시 기반 메시징, 작업 큐 처리에 적합 | RabbitMQ, Amazon SQS | Task Queue, 비동기 요청 분산 |
| Topic (Pub/Sub) | 1:N 브로드캐스트 메시징, 이벤트 알림이나 상태 전파에 적합 | Apache Kafka, Google Pub/Sub | 이벤트 스트리밍, 알림 시스템 | |
| 하이브리드 모델 | Queue 와 Topic 혼합 구조, MSA 환경에서 유연한 처리 흐름 구성 | Azure Event Grid, RabbitMQ (Exchange 활용) | 상태 변경 + 작업 실행 분리 구조 | |
| 2. 메시지 전달 보장 | At-most-once | 메시지 유실 가능성 있음, 속도 우선 | UDP 기반 전송 등 일부 경량 서비스 | 모니터링 알림, 비중요 로그 수집 |
| At-least-once | 중복 가능성 존재, 신뢰성 우선 | 대부분 브로커 기본 설정 | 결제 요청, 주문 이벤트 등 | |
| Exactly-once | 중복 없이 정확히 한 번만 처리. 구현 복잡도 높음 | Apache Kafka (Transactional), Pulsar | 금융 트랜잭션, 정산 시스템 | |
| 3. 처리 방식 | Pull 방식 | Consumer 가 직접 메시지를 끌어오는 방식 | Kafka, SQS | 배치 처리, 수동 처리 트리거 |
| Push 방식 | Broker 가 자동으로 메시지를 푸시 | RabbitMQ, SNS | 실시간 알림, 이벤트 기반 동작 | |
| 4. 배포 및 운영 방식 | 온프레미스 (Self-Hosted) | 자체 인프라에 브로커 설치. 커스터마이징 가능하나 관리 비용 높음 | RabbitMQ, ActiveMQ, Kafka | 금융사, 폐쇄망 운영, 고보안 환경 |
| 클라우드 관리형 (Managed) | 클라우드에서 완전관리형 서비스로 제공. 설치/운영 부담 없음 | Amazon SQS/SNS, Azure Service Bus, GCP Pub/Sub | 클라우드 네이티브 시스템 | |
| 하이브리드 브로커 | 온프레미스와 클라우드 간 연계 지원 | AWS EventBridge, Azure Event Grid | 클라우드 전환, 다중 환경 연동 | |
| 5. 내부 아키텍처 | 중앙 집중형 (Centralized) | 단일 브로커/노드가 모든 메시지를 통제. 관리 단순하지만 장애에 취약 | RabbitMQ, ActiveMQ | 중소규모 시스템, 단일 노드 서비스 |
| 분산형 (Distributed) | 메시지 로그 및 처리를 여러 노드에 분산. 내결함성, 수평 확장성 우수 | Apache Kafka, Apache Pulsar | 실시간 분석, 대규모 트래픽 처리 | |
| 6. 저장 방식 (내구성) | 휘발성 메시지 (In-Memory) | 메시지 저장 없이 전송. 속도는 빠르나 장애 복원 불가 | Redis Pub/Sub, ZeroMQ | 실시간 알림, 게임 이벤트 |
| 영속 메시지 (Persistent Storage) | 메시지를 디스크에 저장. 메시지 유실 방지 가능 | Kafka, RabbitMQ (Durable Queue) | 결제 이벤트, 감사 로그 | |
| 7. 표준 프로토콜 | AMQP | 고신뢰 메시징을 위한 국제 표준 프로토콜. Exchange, Queue, Binding 모델 | RabbitMQ, Apache Qpid | 금융 메시징, 기업 간 데이터 연동 |
| MQTT | 경량 메시징 프로토콜. IoT/모바일 환경 최적화 | Mosquitto, HiveMQ | 센서 데이터 전송, 스마트홈 | |
| Kafka Protocol | Kafka 고유의 TCP 기반 프로토콜. 고성능 스트리밍 처리 최적화 | Apache Kafka, Confluent | 실시간 로그 처리, 스트림 분석 | |
| STOMP/HTTP/WebSockets | 브라우저 기반 통신 또는 텍스트 메시징 지원 | WebSocket API Gateway, Spring STOMP | 대화형 웹 앱, 실시간 UI 이벤트 |
주요 Message Broker 기술 비교
| 항목 | Apache Kafka | RabbitMQ | Apache Pulsar |
|---|---|---|---|
| 개발 주체 | LinkedIn → Apache | Pivotal Software | Yahoo → Apache |
| 언어 | Scala, Java | Erlang | Java |
| 프로토콜 | 자체 프로토콜 | AMQP, MQTT, STOMP 등 | 자체 프로토콜, Kafka 호환, AMQP 지원 예정 |
| 주요 아키텍처 | 분산 로그 스트림 기반 | 메시지 큐 + 교환기 구조 | 브로커 - 스토리지 분리형 계층 아키텍처 |
| 메시지 저장 방식 | 로그 기반 디스크 영구 저장 | 메모리 or 디스크, 기본 삭제 처리 | Apache BookKeeper 기반 분산 로그 저장 |
| 메시지 전달 모델 | Pull (소비자가 가져감) | Push (브로커가 푸시) | Pull / Push 모두 지원 |
| 순서 보장 | 파티션 내 순서 보장 | 큐 내 순서 보장 | 파티션 내 순서 보장 |
| 처리량 | 매우 높음 (수백만 TPS 이상) | 중간 (수십만 TPS 수준) | 매우 높음 (Kafka 이상 성능도 가능) |
| 지연 시간 | 낮음 (밀리초 단위) | 매우 낮음 (서브밀리초, 소규모 메시지에 최적화) | 낮음 (BookKeeper 기반 안정된 지연 시간) |
| 확장성 | 수평 확장 용이 (파티션 기반 확장) | 제한적 확장 (클러스터링은 가능하나 제약 있음) | 브로커 - 스토리지 독립 확장 → 매우 우수 |
| 내결함성 | 복제, 다중 브로커 구조, 장애 복구 지원 | 클러스터 구성으로 가능 | 내장 복제 + BookKeeper → 강력한 장애 회복 지원 |
| 멀티 테넌시 | 제한적 | 제한적 | 기본적으로 멀티 테넌시 지원 |
| 지리적 복제 | 외부 도구 (MirrorMaker 등) 필요 | 제한적 지원 | 기본 내장 (멀티 리전 구성 용이) |
| 토픽 구조 | 파티셔닝된 평면 구조 | 교환기 - 큐 바인딩 방식 | 계층형 네임스페이스 + 토픽 구조 |
| 운영 복잡성 | ZooKeeper/KRaft 필요, 설정 복잡 | 비교적 단순, 관리 UI 제공 | 구성요소 다양 (ZooKeeper, BookKeeper 등), 높은 운영 난이도 |
| 모니터링 도구 | Kafka Manager, Confluent CC 등 | 기본 내장 UI + 다양한 플러그인 | Pulsar Manager, 자체 메트릭 제공 |
| 개발자 경험 | 강력한 기능, 높은 러닝 커브 | 직관적인 개념, 쉬운 진입 | 통합 API, 다소 복잡하지만 다양한 기능 내장 |
| 사용 사례 | 대용량 로그 수집, 스트리밍 분석, 이벤트 소싱, 모니터링 등 | 마이크로서비스 통신, 작업 큐, RPC, 백엔드 비동기 처리 등 | 멀티 리전 메시징, 하이브리드 큐 + 스트림, 실시간 분석 등 |
| 커뮤니티 생태계 | 매우 활발, 기업 도입 많음 | 성숙한 생태계, 오래된 레퍼런스 존재 | 신생 커뮤니티, 빠르게 성장 중 |
| 추가 기능 | Kafka Streams, Kafka Connect, KSQL 등 | 다양한 플러그인 기반 확장 | Functions, SQL, Schema Registry, 다중 메시징 모델 지원 |
| 비용 효율성 | 대용량 처리에 적합, 인프라 대비 효율적 | 중소규모에 적합, 저비용으로 시작 가능 | 스토리지 - 컴퓨팅 분리 → 장기적 비용 절감에 유리 |
실무에서 효과적으로 적용하기 위한 고려사항
| 카테고리 | 항목 | 고려사항 | 권장사항 |
|---|---|---|---|
| 설계 (Architecture) | 메시지 패턴 선택 | 요구사항에 맞는 1:1(Queue), 1:N(Pub/Sub) 패턴 선택 필요 | CQRS, Saga, Work Queue 등 아키텍처 패턴 적용 |
| 메시지 구조 설계 | 명확하고 일관된 스키마, 향후 변경 고려 | Avro/Protobuf 등 구조화된 포맷 + Schema Registry 도입 | |
| 메시지 크기 관리 | 대형 메시지는 네트워크 병목 및 처리 지연 유발 가능 | 대용량 데이터는 외부 저장소 (Blob) 로 분리, 메시지엔 참조만 포함 | |
| 우선순위 처리 | 중요 메시지는 선처리 가능해야 함 | 우선순위 큐 구성, 전용 토픽 또는 채널 분리 | |
| 메시지 순서 보장 | 파티셔닝/병렬 처리 시 순서가 깨질 수 있음 | 순서 키 (key) 설정, 단일 파티션/워커 처리, 메시지 버퍼링 | |
| 확장성 구조 설계 | 수요 증가에 따라 자동 확장 가능한 구조 필요 | Consumer Group + Partitioning + Auto Scaling 도입 | |
| 신뢰성 및 복원력 | 중복 메시지 처리 (멱등성) | 네트워크 재시도/중복 전송에 대한 방어 필요 | 상태 기반 처리 로직, 멱등성 키 적용, Exactly-once 처리 |
| 장애 복구 | 처리 실패, 시스템 다운 등에 대비한 구조 필요 | DLQ 구성, Retry Policy 설정, 복제/백업 시나리오 수립 | |
| 보존 정책 | 메시지 유효 기간과 저장 공간 관리 필요 | TTL(Time To Live) 설정, 보존 주기별 GC 설정 | |
| 운영 (Operation) | 성능 최적화 | 처리량 및 지연시간 모니터링 필요 | 배치 전송 설정, 압축 알고리즘 최적화 (e.g. snappy, lz4) |
| 실시간 모니터링 및 지표 수집 | 장애 조기 감지 및 분석을 위한 실시간 메트릭 필요 | Prometheus + Grafana, Micrometer, Kafka Exporter 등 활용 | |
| 트레이싱/로그 | 메시지 흐름 추적 및 원인 분석 가능해야 함 | OpenTelemetry, Trace ID, 로그 컨텍스트 연계 | |
| 운영 자동화 | 운영자 개입 최소화 및 효율적인 운영 필요 | 오토스케일링, 알림 시스템, 자가 치유 메커니즘 도입 | |
| 용량 계획 | 예측 가능한 부하 대비 필요 | 예상 메시지 크기 × TPS 기반 용량 산정 + 알림 설정 | |
| 보안 (Security) | 인증 및 접근 제어 설정 | 민감 데이터 및 시스템 보호 필수 | TLS/mTLS, IAM, RBAC, ACL 적용 |
| 메시지 암호화 | 데이터 기밀성 보장 | 메시지 레벨 암호화 또는 네트워크 암호화 사용 | |
| 권한 세분화 | 다중 테넌시 또는 조직 구조에 따른 접근 제어 필요 | 리소스 단위 권한 정책, 서비스 계정 기반 인증 구성 | |
| 테스트 및 개발 | 테스트 전략 | 통합 테스트 환경 구축의 어려움 존재 | Testcontainers, Wiremock, Consumer Driven Contract Test 적용 |
| 스키마 호환성 검증 | 메시지 포맷 변경 시 하위 시스템 오류 발생 가능 | Schema Registry 기반 버전 관리 및 유효성 검증 | |
| 클라이언트 라이브러리 선택 | 언어 및 기능별 라이브러리 차이 존재 | 공식 라이브러리 우선 사용, 성능 및 기능 비교 테스트 후 선택 | |
| 개발환경 연동 | 로컬 개발 및 테스트 환경의 설정 어려움 | 로컬 브로커 컨테이너 도입 (e.g., Test Kafka, RabbitMQ Docker 등) |
Message Broker 아키텍처 선택 전략
| 선택 기준 | 권장 브로커 | 이유 |
|---|---|---|
| 레거시 시스템 통합 필요 (JMS 기반) | Apache ActiveMQ | Java EE 기반 시스템 연동에 최적화 |
| 간단한 작업 처리 큐가 필요한 경우 | Amazon SQS | 관리형, 서버리스 친화적 |
| 고성능, 고확장성 실시간 이벤트 처리 | Google Pub/Sub | 글로벌 스트리밍, Auto Scale |
| 순서 보장이 매우 중요한 업무 | AWS SQS FIFO / Azure Service Bus Session | 순서 보장 + 중복 방지 |
| 복잡한 라우팅 및 다양한 프로토콜 지원 | RabbitMQ | Direct, Topic, Fanout 라우팅 지원, 다양한 프로토콜 가능 |
| 전사 이벤트 허브 구성이 필요한 경우 | Azure Service Bus / Pub/Sub | 대규모 메시징 허브 구축 가능 |
메시지 포맷 관리 (Avro / Protobuf) 및 스키마 레지스트리
메시지 브로커 기반의 시스템에서 메시지 포맷은 송신자와 수신자가 동일한 데이터 구조를 이해하고 처리하기 위한 핵심 요소이다. 특히 마이크로서비스 아키텍처, 이벤트 스트리밍, 실시간 분석 환경에서 메시지 포맷의 일관성과 호환성을 유지하는 것은 시스템의 안정성과 진화를 가능하게 한다.
대표적인 바이너리 포맷으로는 Apache Avro와 Google Protocol Buffers (Protobuf) 가 있으며, 이들과 함께 사용되는 스키마 레지스트리는 메시지 스키마의 등록, 관리, 버전 제어를 지원한다.
메시지 포맷 비교
| 항목 | Avro | Protobuf |
|---|---|---|
| 출처 | Apache | |
| 스키마 포함 | 메시지에 스키마 일부 포함 가능 | 메시지에 스키마 포함 안 됨 |
| 속도 | 빠름 (JSON 대비) | 매우 빠름 |
| 스키마 정의 방식 | JSON 기반 IDL | .proto DSL |
| 버전 호환성 | 우수 (Backward/Forward) | 제한적 (Strict ID) |
| 압축/크기 | 작음 | 매우 작음 |
| 동적 스키마 처리 | 좋음 (런타임 변경 가능) | 제한적 (컴파일 필요) |
| 지원 언어 | 다수 (Java, Python 등) | 다수 (특히 gRPC 연계) |
| Kafka 와 통합 | Confluent Schema Registry 와 연동 | Yes |
- Avro/Protobuf 는 JSON 보다 작고 빠르며, 시스템 간 인터페이스 일관성을 유지할 수 있다.
- 스키마 레지스트리는 메시지 구조 변경을 관리하고, 시스템 간 버전 충돌을 예방하는 필수 구성 요소이다.
- 메시지 기반 시스템의 확장성, 안정성, 유지보수성을 확보하려면 반드시 스키마 관리 체계를 갖춰야 한다.
스키마 레지스트리
스키마 레지스트리 (Schema Registry) 는 메시지에 대한 스키마를 등록, 조회, 검증, 버전 관리하는 중앙 저장소이다.
보통 Kafka 나 브로커 환경에서 메시지를 발행하거나 구독할 때 스키마 ID 를 기준으로 역직렬화를 수행한다.
| 기능 | 설명 |
|---|---|
| 스키마 등록 | 새로운 메시지 형식 등록 및 버전 관리 |
| 스키마 검증 | 기존 스키마와의 호환성 검사 |
| 역직렬화 지원 | 소비자가 스키마 ID 기반으로 데이터 해석 |
| REST API | 스키마 CRUD 제공 |
| Subject 관리 | 주제 (topic) 별 스키마 관리 |
Avro + Confluent Schema Registry
flowchart LR
P["Producer (Avro)"] -->|Send to Kafka| K(Kafka Topic)
K -->|Schema ID 포함| SR[Schema Registry]
C[Consumer] -->|Schema ID| SR
SR -->|Fetch schema| C
메시지 구조 (Avro + Schema Registry)
실무 사용 예시
스키마 정의 (
user.avsc)Python 에서 직렬화
1 2 3 4 5 6 7 8 9 10 11import avro.schema import avro.io import io schema = avro.schema.parse(open("user.avsc").read()) buf = io.BytesIO() writer = avro.io.DatumWriter(schema) encoder = avro.io.BinaryEncoder(buf) writer.write({"id": "u123", "email": "user@example.com"}, encoder) binary_data = buf.getvalue()
메시지 호환성 전략
| 전략 | 설명 | 사용 예 |
|---|---|---|
| Backward compatible | 신규 필드 추가, 기본값 지정 | 소비자는 구버전이지만 데이터는 최신 |
| Forward compatible | 필드 삭제 또는 기본값 유지 | Producer 는 구버전, Consumer 는 신버전 |
| Full compatibility | 양방향 모두 호환 | Enterprise 환경 권장 |
스키마 레지스트리 구성 전략
| 구성 항목 | 권장 사항 |
|---|---|
| Subject 명명 규칙 | <topic>-value, <topic>-key |
| 자동 등록 여부 | Producer 에서 자동 등록 가능하도록 설정 |
| 호환성 모드 | 개발 단계: NONE, 운영 단계: BACKWARD |
| 다중 환경 지원 | dev/stage/prod 별 스키마 분리 |
권장 설계 패턴
| 패턴 | 설명 |
|---|---|
| Schema-first 개발 | 계약 (스키마) 부터 정의 후 Producer/Consumer 구현 |
| Versioned Subject | topic 마다 명확한 version suffix 운영 |
| Validation Layer | Kafka Connect, Schema Registry Interceptor 등 사용 |
| Fallback 처리 | 호환 실패 시 기본 로직 처리 추가 |
메시지 보장 방식
메시지 전송 보장 방식 (Delivery Semantics) 은 메시지 브로커 기반 시스템에서 신뢰성과 정합성 확보를 위한 핵심 설계 요소이다. 시스템의 장애, 네트워크 지연, Consumer 실패 등 다양한 상황에서 어떻게 메시지가 전송되고 처리되었는지를 보장하는 방식에 따라 전체 시스템의 동작 방식이 달라진다.
Exactly-once vs. At-least-once
| 보장 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| At-most-once | 최대 한 번만 처리됨. 유실 가능성 있음 | 빠름, 단순함 | 유실 가능성 있음 |
| At-least-once | 최소 한 번 처리됨. 중복 가능성 있음 | 안정성 높음 | 중복 처리 이슈 |
| Exactly-once | 정확히 한 번만 처리됨 | 고신뢰성 | 복잡도 및 리소스 증가 |
- At-least-once는 기본 보장 방식이며 대부분의 메시지 브로커가 이 방식을 채택한다.
- Exactly-once는 고신뢰 처리가 필요한 금융/거래 도메인에서 필요하며, 추가적인 트랜잭션 제어 및 중복 방지 로직이 필수이다.
- Kafka 는 Idempotent Producer + Transaction API + Consumer Commit 제어를 통해 정확히 한 번 메시지 처리 구성을 지원한다.
전송 보장 방식의 실무 적용 예시:
| 예시 시스템 | 사용 방식 | 이유 |
|---|---|---|
| 알림 시스템 | At-most-once | 유실되어도 시스템 영향 없음 |
| 결제 처리 | Exactly-once | 중복 결제 방지 필수 |
| 로그 수집 | At-least-once | 중복 로그는 허용되나 유실은 안 됨 |
| 주문 처리 | At-least-once 또는 Exactly-once | 중복은 되도록 방지, 유실은 절대 안 됨 |
구현 예시
At-least-once 구현 (RabbitMQ + Python)
RabbitMQ 의 기본 처리 방식은 At-least-once.
메시지를 받은 후 명시적으로 ACK 하지 않으면 브로커는 재전송을 시도한다.
| |
Exactly-once 구현 개요 (Kafka 기준)
Kafka 는 기본적으로 At-least-once 처리지만, 아래 기능을 조합해 Exactly-once Semantics (EOS) 를 구현할 수 있다:
구성 요소:
| 요소 | 설명 |
|---|---|
| Idempotent Producer | 동일 메시지 중복 전송 방지 |
| Transactional Producer | 메시지 배치 단위로 commit/abort |
| Consumer Offset 관리 | 메시지 처리가 성공한 후에만 커밋 |
Kafka Exactly-once 구현 흐름:
(Java/Python 기준)
| |
Kafka Streams 기반 Exactly-once:
- Kafka Streams API 는 내부적으로 Exactly-once 지원을 내장하고 있다.
- Exactly-once V2는 Kafka 2.5+ 이상에서 사용 가능
- 내부적으로 transactional write 및 state management 연동
주요 고려사항 및 권장 설정
| 고려 요소 | 설명 | 권장값 |
|---|---|---|
| Producer 설정 | enable.idempotence | true |
| Kafka Streams | processing.guarantee | exactly_once_v2 |
| Offset commit | 수동 commit 사용 | Consumer.commitSync() |
| 메시지 중복 방지 | Consumer 측에서 DB idempotency 구현 | 예: unique key 기반 INSERT IGNORE |
메시지 중복 방지 전략
| 전략 | 설명 |
|---|---|
| DB unique constraint | 동일 메시지 중복 방지 |
| Redis dedup key | 메시지 hash 기반 중복 필터링 |
| UUID 기반 트랜잭션 ID | 메시지 고유 식별자 사용 |
| Application-level deduplication | 자체 메시지 처리 테이블 관리 |
최적화하기 위한 고려사항 및 주의할 점
| 최적화 영역 | 고려사항 | 설명 | 권장사항 |
|---|---|---|---|
| 메시지 처리 | 배치 처리 | 개별 처리보다 효율적인 처리량 확보 가능 | 배치 크기 (100~1000), 최대 대기 시간 (~100ms) 조절 |
| 비동기 처리 | 동기식은 병목 발생, 소비자/생산자 모두 병렬 처리로 처리량 향상 가능 | Async 클라이언트, ThreadPool/WorkerPool 기반 처리 적용 | |
| 메시지 크기 관리 | 과도한 메시지 크기는 전송 지연 및 장애 유발 가능 | 메시지 분할 (Chunking), 10MB 이하 권장, 대용량은 Blob 으로 분리 저장 | |
| 순서 보장 | 소비자 처리 순서가 중요 시 순서 유지 필요 | FIFO Queue 또는 Partition Key 기반 설계 | |
| 리소스 및 저장소 | 메모리 관리 | GC 지연 또는 메모리 누수로 인한 성능 저하 | Heap 크기 제한, GC 튜닝, JVM 설정 최적화 |
| 디스크 I/O 최적화 | 로그 기반 브로커는 디스크 성능이 병목 요소가 될 수 있음 | SSD 사용, RAID 구성, 로그 분리 디스크 적용 | |
| 저장소 압축 및 효율화 | 저장소 낭비 및 네트워크 대역폭 감소 목적 | Snappy/LZ4 압축 사용, 직렬화 포맷 (Avro, Protobuf) 활용 | |
| 네트워크 | 네트워크 대역폭/버퍼 최적화 | 전송 병목 방지 및 자원 낭비 방지를 위한 네트워크 구성 | OS/Socket 버퍼 튜닝, 압축 전송 활성화, 지역 분산 구성 |
| 네트워크 병목 최소화 | 병목 지점 없이 지연시간 최소화 | 로컬 브로커 배치, 고속 네트워크 환경 구성 (10G 이상 NIC 등) | |
| 컨슈머 구조 | 컨슈머 그룹 최적화 | 파티션 수와 불일치하거나 그룹 불균형 시 처리 지연 발생 | 파티션 수 = 소비자 수, 그룹 재조정 최소화 |
| Consumer Lag 대응 | 소비자 지연 발생 시 대기 증가 → 처리량 저하 | 소비자 수 증설, Lag 모니터링 및 지표 기반 알림 설정 | |
| Queue 크기 및 적체 방지 | 큐 오버플로우 방지는 필수 장애 대응 요소 | Max Length 제한, 알림 설정, Rate Limiting, Circuit Breaker 적용 | |
| 운영 자동화 | 모니터링 및 알림 구성 | 지연, 병목, 장애를 실시간으로 탐지 및 대응 | 처리량, Lag, Queue Depth, 에러율 등 지표 수집 및 경고 임계값 설정 |
| 클러스터 토폴로지 구성 | 브로커의 지역적 분산 및 트래픽 분산 전략 필요 | 멀티 노드 구성, AZ 분산, Leader 균등 분배 | |
| 자동화 및 스케일링 정책 | 처리량 증가/감소에 따라 리소스 동적 할당 필요 | HPA, Kafka Cruise Control, 오토스케일링 도입 | |
| 장애 대응 | 백프레셔 및 흐름 제어 | 생산량 > 소비량일 경우 시스템 오버로드 발생 가능 | Consumer 제한, 큐 임계 도달 시 Circuit Breaker, Rate Limiter 도입 |
| 재처리 및 실패 대응 | 장애 발생 시 재처리 가능한 구조 필요 | DLQ 구성, Retry 정책 (지수 백오프), 메시지 상태 추적 IDempotency 적용 | |
| 설계 및 구조 | 파티션 전략 | 파티션 설계가 병렬성과 순서 보장에 직접 영향 | 주제별 분리 설계, Partition Key 활용, 파티션 수 테스트 기반 설정 |
| 메시지 보존 정책 관리 | 오래된 메시지 보존 시 저장소 압박 발생 | TTL 설정, Retention Period 관리, Cleanup Policy 적용 (Kafka: log.compaction 등) |
실무 사용 예시
| 주요 활용 분야 | 사용 사례 | 연계 기술/브로커 | 목적 및 효과 |
|---|---|---|---|
| 1. 마이크로서비스 통합 | 서비스 간 비동기 통신 | RabbitMQ, Kafka, Spring Boot, Docker, K8s | 시스템 간 결합도 감소, 장애 전파 차단, 느슨한 연동 및 서비스 확장성 확보 |
| 요청 - 응답 API 메시징 | RabbitMQ (Request/Reply), gRPC over MQ | 서비스 간 RPC-like 구조 구현, 응답 보장 가능 | |
| 내부 로직 분리 및 확장 | Kafka + CQRS, Event Sourcing | 비즈니스 로직 분리, 상태 관리 분산, 감사 추적 가능 | |
| 2. 실시간 처리 및 분석 | 로그 수집 및 모니터링 파이프라인 구성 | Kafka, Elasticsearch, Fluent Bit, Grafana | 실시간 로그 분석 및 모니터링 대시보드 구성 (ELK, EFK) |
| 사용자 행동 분석 | Kafka Streams, Redis Streams | 클릭스트림 수집, 실시간 필터링/세분화 처리 | |
| 미디어 스트리밍 작업 분산 처리 | Kafka, Redis Pub/Sub | 비디오 인코딩, 트랜스코딩 병렬 처리 | |
| 3. 알림 및 사용자 피드백 | 실시간 알림 시스템 | SQS, Firebase, WebSocket + MQ | 댓글/이벤트 발생 시 다수 사용자에게 동시에 알림 전송 |
| 사용자 피드 및 메시지 전파 | Kafka, Redis Streams | SNS 피드 전파, 사용자 타임라인 동기화 | |
| 이메일/SMS 비동기 발송 | RabbitMQ, SQS, SMTP Relay Worker | 응답 지연 없는 이메일/SMS 대량 발송 구현 | |
| 4. IoT 및 엣지 컴퓨팅 | IoT 센서 데이터 실시간 수집 | MQTT, Google Pub/Sub, Azure IoT Hub | 저지연 경량 메시징 프로토콜 기반으로 센서와 중앙 시스템 간 통신 처리 |
| 차량/물류 위치 추적 | Kafka, NATS, GPS 트래커 | 실시간 위치 데이터 수신 및 경로 최적화 처리 | |
| 스마트홈 자동화 시스템 구성 | MQTT + Node-RED | 이벤트 기반 자동화 및 상태 알림 처리 | |
| 5. 백그라운드 및 배치 작업 | 백그라운드 이미지 리사이징 | AWS SQS + Lambda, RabbitMQ + Worker Pool | 고부하 작업을 메인 서비스와 분리, 병렬 처리로 성능 개선 |
| 예약 작업/스케줄러 | Cron + MQ, Airflow + Kafka | 시간 기반 태스크 트리거, 작업 분리 처리 | |
| 비동기 데이터 수집/적재 | Kafka Connect + DB Sink | 백오피스/타 시스템에서 수집한 데이터 적재 자동화 | |
| 6. 산업별 특화 사용 | 금융: 결제/트랜잭션 큐 | IBM MQ, Kafka | 트랜잭션 정합성 확보, 고신뢰성 처리, 규제 대응 |
| 헬스케어: 환자 모니터링/알림 처리 | MQTT, RabbitMQ | 실시간 상태 알림, 민감 정보 보호, 인증 통신 필요 | |
| 전자상거래: 주문 워크플로우 관리 | RabbitMQ, Kafka, AWS SQS | 주문 → 결제 → 배송의 비동기 이벤트 분리, 리소스 최적화 | |
| 텔레콤: 통화 기록 및 청구 처리 | Kafka, Pulsar | 대용량 기록 스트리밍, 지연 최소화, 고가용성 구성 | |
| AI/ML: 추론 트리거 및 파이프라인 자동화 | Kafka, SQS + Lambda, Pub/Sub + Vertex AI | 메시지 기반 모델 실행 트리거, 데이터 파이프라인 자동화 |
활용 사례
사례 1: 주문 처리 시스템에서의 메시지 브로커
구성
flowchart LR User(고객) --> API[웹 API 서버] API --> Broker[메시지 브로커] Broker --> Queue[OrderQueue] Queue --> Worker1[Order Worker 1] Queue --> Worker2[Order Worker 2] Worker1 --> DB[주문 DB] Worker2 --> DB Broker --> DLQ
Workflow 설명
- 고객이 주문 요청 → API 서버를 통해 브로커로 메시지 발송
- 브로커가 주문 큐 (OrderQueue) 에 메시지 적재
- 두 개 이상의 워커가 큐에서 메시지 받아 병렬 주문 처리
- 장애/실패 메시지는 DLQ(Dead Letter Queue) 로 별도 관리
주제 유무 차이점:
- 브로커 사용 → 주문의 신뢰성, 확장성, 장애 복원력 보장
- 브로커 없음 → 동시성, 중복/누락, 장애에 취약 및 시스템 간 결합 심화
구현 예시:
| |
- Producer 가 메시지 저장, Consumer 가 ack 기반 처리. 장애 시 메시지는 큐에 남아 재처리 가능.
사례 2: 이메일 발송 자동화 시스템 (RabbitMQ 기반)
시스템 구성:
- Producer: 사용자 등록 서비스
- Broker: RabbitMQ (Direct Exchange 사용)
- Queue:
email.send.queue - Consumer: 이메일 발송 Worker(Node.js 또는 Python)
flowchart TD
A[User Registration Service] --> B["Exchange (email.direct)"]
B --> C[Queue: email.send.queue]
C --> D[Consumer: Email Worker]
Workflow:
- 신규 가입 시 Producer 가 “email.send” 메시지를 발행
- Exchange 가 라우팅 키 기반으로 해당 큐로 전달
- Worker 가 메시지를 처리해 이메일 전송
효과:
| 항목 | 브로커 사용 시 | 미사용 시 |
|---|---|---|
| 처리 방식 | 비동기 | 동기 (응답 지연) |
| 실패 대응 | DLQ 처리 가능 | 실패 시 사용자에게 오류 반환 |
| 확장성 | Worker 수 증가만으로 확장 | 코드 수정 필요 |
구현 예시:
Producer 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23# 메시지 브로커에 이메일 발송 요청 메시지 전송 import pika import json connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='email.send.queue') message = { 'to': 'user@example.com', 'subject': 'Welcome!', 'body': '감사합니다. 회원가입이 완료되었습니다.' } channel.basic_publish( exchange='', routing_key='email.send.queue', body=json.dumps(message) ) print("✅ 이메일 발송 메시지 전송 완료") connection.close()Consumer 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# 메시지 큐에서 메시지를 소비하고 실제 이메일 전송 처리 import pika import json def callback(ch, method, properties, body): data = json.loads(body) print(f"📧 이메일 전송 대상: {data['to']} / 제목: {data['subject']}") # 실제 메일 발송 로직 (SMTP 등) connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='email.send.queue') channel.basic_consume(queue='email.send.queue', on_message_callback=callback, auto_ack=True) print("📬 이메일 Consumer 시작됨") channel.start_consuming()
사례 3: 전자상거래 주문 처리 시스템
시스템 구성:
graph TB
subgraph "Frontend"
UI[Web/Mobile UI]
end
subgraph "API Gateway"
GW[API Gateway]
end
subgraph "Microservices"
OS[Order Service]
PS[Payment Service]
IS[Inventory Service]
NS[Notification Service]
end
subgraph "Message Broker"
MB[Apache Kafka]
T1[order-events]
T2[payment-events]
T3[inventory-events]
end
subgraph "External Systems"
PG[Payment Gateway]
WMS[Warehouse Management]
EMAIL[Email Service]
end
UI --> GW
GW --> OS
OS --> MB
MB --> PS
MB --> IS
MB --> NS
PS --> PG
IS --> WMS
NS --> EMAIL
워크플로우:
- 사용자 주문 생성 → Order Service
- Order Service → order-created 이벤트 발행
- Message Broker → 이벤트 라우팅
- Payment Service → 결제 처리
- Inventory Service → 재고 차감
- Notification Service → 알림 발송
Message Broker 의 역할:
- 서비스 간 비동기 통신 중개
- 이벤트 순서 보장
- 장애 시 메시지 재처리
- 서비스 부하 분산
Message Broker 유무에 따른 차이점:
| 구분 | Message Broker 사용 | Message Broker 미사용 |
|---|---|---|
| 결합도 | 낮음 (느슨한 결합) | 높음 (강한 결합) |
| 장애 전파 | 격리됨 | 연쇄 장애 발생 |
| 확장성 | 독립적 확장 가능 | 전체 시스템 확장 필요 |
| 성능 | 비동기 처리로 빠른 응답 | 동기 처리로 느린 응답 |
| 복잡성 | 메시징 계층 추가 | 단순한 직접 호출 |
구현 예시:
| |
이 구현 예시는 Message Broker (Apache Kafka) 를 활용한 주문 처리 시스템으로, 다음과 같은 핵심 기능을 보여준다:
- 비동기 메시지 처리: 주문 생성과 결제 처리가 독립적으로 실행
- 이벤트 드리븐 아키텍처: 이벤트 기반 서비스 간 통신
- 메시지 순서 보장: 파티션 키를 사용한 순서 보장
- 장애 처리: 결제 실패 시 별도 이벤트 발행
- 확장성: 컨슈머 그룹을 통한 수평적 확장 가능
주목할 내용
| 카테고리 | 주제 | 핵심 항목 | 설명 |
|---|---|---|---|
| 1. 메시징 구조 및 패턴 | 큐 & 토픽 구조 | 1:1, 1:N, Pub/Sub | 메시지 송수신 방식의 유연성 확보. 시스템 decoupling 에 핵심. |
| 하이브리드 모델 | Queue + Topic 혼합 | 작업 큐와 이벤트 브로드캐스트를 동시에 구성하는 복합 구조. | |
| 메시징 패턴 | CQRS, Event Sourcing, Work Queue | 아키텍처 기반 설계 패턴으로서 다양한 분산 처리 구조를 구현. | |
| 메시지 라우팅 | Exchange, Routing Key | 메시지를 조건에 따라 분기 처리. Direct/Fanout/Topic/Headers 등 라우팅 전략. | |
| 2. 신뢰성 및 복원력 | 장애 대응 메커니즘 | DLQ, Retry Policy, ACK, TTL | 메시지 유실 방지와 재처리를 위한 장애 복원 구조. |
| 멱등성 보장 | Idempotency Key, Exactly-once | 중복 메시지 처리 시 동일 결과 보장. 트랜잭션 무결성 유지. | |
| 지속성 | Persistent Storage | 메시지 영속성 확보. 디스크 기반 저장으로 장애 복구 가능. | |
| 3. 성능 및 확장성 | 병렬 소비 구조 | Consumer Group, 파티셔닝 | 수평 확장을 통한 대규모 트래픽 분산 처리. |
| 스트리밍 처리 통합 | Kafka Streams, Pulsar Functions | 브로커와 실시간 처리 엔진 간 경계가 사라지고 통합 처리 플랫폼으로 진화. | |
| 글로벌 메시징 | Global Data Mesh | 멀티리전 환경에서 지연 최소화를 위한 분산 메시지 라우팅 기술. | |
| 오토스케일링 | Auto Scaling, Worker Pool Sizing | 트래픽 변화에 따른 자동 확장 구성. | |
| 4. 운영/관측/자동화 | 분산 모니터링 | Prometheus, Grafana, Micrometer | 브로커 메트릭 수집 및 시각화. 처리 지연, 실패율, 처리량 추적. |
| 분산 추적 | OpenTelemetry, Zipkin, Jaeger | 메시지 흐름 추적 및 병목 탐지. 서비스 간 연쇄 추적에 필수. | |
| 자가 치유 메커니즘 | AI 기반 운영 자동화, Auto Recovery | 장애 자동 감지 및 복구로 운영 부담 최소화. | |
| 5. 보안 및 컴플라이언스 | 메시지 수준 보안 | TLS, mTLS, SASL, E2E Encryption | 데이터 전송 보안 및 상호 인증 강화. |
| 세분화된 접근 제어 | IAM, Role-based Access Control | 메시지 주제 또는 큐 단위의 권한 제어를 통한 멀티테넌시 지원. | |
| 데이터 수명 정책 | TTL, GDPR-compliant retention policy | 데이터 보관 기한 및 삭제 정책을 통한 컴플라이언스 대응. | |
| 6. 표준 및 상호운용성 | 이벤트 표준화 | CloudEvents, AsyncAPI | 이벤트 포맷, 정의, 문서화 통일로 시스템 간 통합 용이. |
| 메시징 프로토콜 | AMQP 1.0, MQTT, STOMP | 다양한 환경에서 상호운용 가능한 표준 메시징 프로토콜 적용. | |
| 7. 설계 트렌드 및 패러다임 | 이벤트 중심 설계 | Event-driven Microservices | 비동기 이벤트 기반 아키텍처로 설계되는 마이크로서비스 구조. |
| 서버리스 메시징 | AWS EventBridge, Azure Event Grid | 브로커를 서버리스로 운영하여 유연한 이벤트 흐름 구성. | |
| 커널 수준 최적화 | eBPF 기반 메시징 | 초저지연 메시징을 위한 리눅스 커널 내 네트워크 필터 및 처리 기술. |
반드시 학습해야 할 내용
| 카테고리 | 주제 | 세부 항목 | 설명 |
|---|---|---|---|
| 개념 및 프로토콜 | 메시징 패턴 | Queue, Topic, Pub/Sub, P2P, Request-Reply | 기본 통신 모델의 구조와 사용 시나리오를 이해 |
| 메시지 형식 및 직렬화 | JSON, Avro, Protocol Buffers | 메시지 포맷에 따른 용량, 속도, 스키마 관리 이슈 이해 | |
| 메시징 프로토콜 | AMQP, MQTT, STOMP, JMS | 전송 보장, QoS, 경량화 등 프로토콜별 차이 분석 | |
| 설계 및 아키텍처 | 분산 메시징 아키텍처 | 브로커 클러스터링, 파티셔닝, 샤딩, 글로벌 분산 | 고가용성 및 대규모 확장을 위한 분산 설계 구조 |
| 이벤트 기반 설계 패턴 | Event Sourcing, CQRS, Saga | 메시지 브로커 기반의 도메인 주도 분산 아키텍처 패턴 활용법 | |
| 멱등성과 순서 보장 | Idempotency, Ordering Key, Partitioning | 중복 방지와 처리 순서 보장을 위한 핵심 설계 전략 | |
| 메시지 일관성 모델 | Strong/Eventually Consistent | 분산 환경에서의 데이터 일관성 수준 정의 및 메시지 전파 전략 | |
| 신뢰성 및 복구 | 메시지 전달 보장 | At-Least-Once, Exactly-Once, At-Most-Once | 재시도, 중복 제거, ACK 메커니즘 설계 |
| 장애 복구 및 실패 처리 | Retry, DLQ(Dead Letter Queue), Replication, Failover | 메시지 손실 방지 및 복구를 위한 복제·재처리 구조 | |
| 메시지 보존 및 수명 | TTL, Retention Policy, Offset Management | 메시지의 저장 기간과 소비 상태 관리 | |
| 성능 및 최적화 | 성능 튜닝 | Batch, Compression, Acknowledgment 전략 | Throughput 과 Latency 를 개선하기 위한 기법 |
| Consumer Lag 최적화 | 병렬 소비자 구성, Lag 측정 지표 | 소비자 지연을 실시간으로 측정하고 대응 | |
| 벤치마킹 | 성능 비교 기준, 테스트 환경 구성 | 브로커 간 성능 측정을 위한 표준 시나리오 설계 | |
| 보안 및 규제 | 통신 보안 | TLS, Message Encryption | 데이터 전송 시 보안 확보 |
| 인증 및 접근 제어 | SASL, OAuth, RBAC, ACL | 사용자 및 서비스 간 인증/인가 정책 설계 | |
| 규제 준수 | GDPR, HIPAA, 금융보안 | 민감 정보 처리 시 보안/로깅 정책 적용 | |
| 통합 및 배포 | API 게이트웨이 연계 | RESTful API ↔ 메시지 브로커 | 요청 - 응답 + 이벤트 기반 혼합 아키텍처 구현 |
| 서버리스 아키텍처 통합 | Lambda, EventBridge, Pub/Sub | 이벤트 트리거 기반 무상태 처리 구조 | |
| DevOps 및 자동화 | CI/CD, Helm, Terraform, Ansible | 브로커 인프라의 코드 기반 배포/운영 자동화 | |
| 관측성 및 운영 | 로깅, 메트릭, 분산 트레이싱 | OpenTelemetry, Prometheus, Grafana, Jaeger | 메시지 흐름 추적 및 장애 원인 분석 |
| 알림 시스템 구성 | AlertManager, Slack Webhook, PagerDuty | 장애 발생 시 실시간 알림 구조 설계 | |
| 운영 자동화 및 스케일링 | Auto-scaling, Lifecycle Management | 워크로드에 따른 자동 조정 및 자원 관리 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 기본 구조 | Queue (큐) | FIFO 원칙의 메시지 저장소. 1:1 메시징에 적합하며, 작업 분산 (Task Queue) 등에 사용됨 |
| Topic (토픽) | Pub/Sub 모델에서 사용되는 논리적 채널. 여러 소비자가 동일 메시지를 구독 가능 | |
| Partition (파티션) | 하나의 토픽을 병렬 처리 가능한 세그먼트로 나눈 단위. 처리량 확장과 순서 보장을 위해 사용됨 | |
| Offset (오프셋) | 파티션 내 각 메시지의 고유 순서 번호. 메시지 소비 상태를 추적하는 데 사용됨 | |
| Exchange (교환기) | (RabbitMQ 등에서) 메시지를 라우팅하는 컴포넌트. Direct, Topic, Fanout, Headers 타입이 존재 | |
| 프로토콜/표준 | AMQP | RabbitMQ 등에서 사용하는 고신뢰 메시징 프로토콜. 표준 기반으로 상호운용성 보장 |
| MQTT | IoT 환경에서 널리 사용되는 경량 메시징 프로토콜. 낮은 대역폭과 저전력 환경에 적합 | |
| STOMP | 텍스트 기반 단순 메시징 프로토콜. 다양한 클라이언트 라이브러리와 언어 지원 | |
| 메시지 처리 | Producer (프로듀서) | 메시지를 생성하고 브로커에 발행하는 클라이언트 혹은 애플리케이션 |
| Consumer (컨슈머) | 메시지를 브로커로부터 구독하고 처리하는 클라이언트 | |
| Consumer Group | 하나의 토픽을 병렬로 처리하는 컨슈머 집합. Kafka 등에서 메시지를 분산 소비하기 위해 사용됨 | |
| Ack (ACK, 확인신호) | 메시지를 정상적으로 처리했음을 브로커에 알리는 신호. 재전송 정책과 함께 신뢰성 보장에 사용됨 | |
| Dead Letter Queue (DLQ) | 처리 실패한 메시지를 저장하는 특수 큐. 장애 대응, 모니터링, 재처리 등에 활용됨 | |
| TTL (Time To Live) | 메시지의 유효 시간. 만료되면 삭제됨. 캐시, 지연 큐 등에서 주로 사용됨 | |
| QoS (Quality of Service) | 메시지 전달 보장 수준: At-most-once, At-least-once, Exactly-once | |
| 운영/신뢰성 | Persistent Storage | 메시지를 디스크에 저장하여 시스템 장애 후에도 복구 가능 |
| Idempotency (멱등성) | 같은 메시지가 여러 번 처리되어도 결과가 동일함을 보장하는 처리 특성 | |
| Backpressure (백프레셔) | 소비자의 처리 속도보다 메시지 유입이 많을 때, 흐름을 제어하여 시스템 과부하를 방지 | |
| Message Replay | 과거 메시지를 다시 처리하는 기능. 장애 복구, 재처리, 모델 재학습 등에 유용 | |
| 패턴/아키텍처 | Routing | 메시지를 조건/키 기반으로 큐나 파티션에 분배하는 방식. Direct, Topic, Header 기반 등 존재 |
| Saga Pattern | 메시지 브로커 기반의 분산 트랜잭션 처리 패턴. 로컬 트랜잭션 + 보상 트랜잭션 구성 | |
| CQRS | Command 와 Query 를 분리하는 아키텍처. 이벤트 소싱 및 메시징과 함께 활용 가능 | |
| Sharding (샤딩) | 데이터를 노드별로 분산 저장하여 확장성과 처리량 향상 | |
| Replication (복제) | 메시지나 로그를 여러 노드에 복사하여 내결함성과 고가용성 보장 | |
| Load Balancing (로드밸런싱) | 메시지 처리 부하를 여러 노드나 소비자에게 분산 | |
| Autoscaling (오토스케일링) | 메시지 수요에 따라 컨슈머/노드 수를 자동 조정 | |
| Schema Registry (스키마 레지스트리) | 메시지 구조를 관리하고 호환성을 검증. Avro, Protobuf, JSON Schema 등과 함께 사용 |
참고 및 출처
공식 문서 및 스펙
- RabbitMQ 공식 문서
- Apache Kafka 공식 문서
- Apache Pulsar 문서
- Apache ActiveMQ GitHub
- AMQP 1.0 스펙 문서
- CloudEvents Specification
- AWS SQS 개발자 가이드
- AWS MQ 제품 설명
- Azure Service Bus Messaging Overview
- Google Cloud Pub/Sub Overview
- NATS 공식 문서
- MQTT 공식 문서
기술 개념 및 가이드
- RedHat - What is a Message Broker?
- CloudAMQP - 메시지 브로커 개념 비교
- Confluent - What is a Message Broker?
- Estafet - Simple Guide to Message Brokers
- HevoData - Message Brokers: Key Models & Use Cases
- Tsh.io - Message Broker의 원리와 장단점
- LinkedIn - Understanding Message Brokers
- IBM - Message Broker 설명
- Hostman - Microservices Architecture에서의 Message Brokers
- CloudAMQP - 메시지 브로커란?
아키텍처 및 디자인 패턴
- Martin Fowler - Enterprise Messaging Patterns
- Enterprise Integration Patterns
- AsyncAPI 공식 웹사이트
- O’Reilly - Software Architecture Patterns: Queue-based Load Leveling
- Microsoft Docs - Messaging Patterns
- Building Event-Driven Microservices (O’Reilly)
- Kafka: The Definitive Guide (O’Reilly)