Space-Based Architecture
Space-Based Architecture(스페이스 기반 아키텍처) 는 대량의 동시 트랜잭션과 데이터 처리가 필요한 환경에서 병목 현상 없이 확장성과 장애 격리를 실현하기 위해 고안된 분산 아키텍처 스타일이다. 시스템을 여러 공간 (Space) 으로 분할하고, 각 공간은 자체적으로 데이터와 프로세스를 관리하며, 중앙 데이터베이스 의존도를 줄여 확장성과 가용성을 극대화한다. 실시간 빅데이터 처리, 금융 시스템, 대규모 전자상거래 등에서 널리 활용된다.
배경
Space‑Based Architecture 는 1997–98 년 마이크로소프트 내부의 Youkon Distributed Caching 플랫폼에서 최초 개발되어 MSN Live Search 등 대용량 서비스에서 사용된 고성능 분산 패턴으로, 이후 금융 및 대규모 웹 서비스에 채택되었다.
전통적 Tier 기반 아키텍처에서 DB 계층이 증가하는 로드와 확장성 한계의 병목이 되자, 이를 해결하기 위해 인메모리 데이터 그리드 (IMDG) 와 스케일링 가능한 처리 단위 (PU) 를 이용한 분산 구조가 등장했다.
목적 및 필요성
주요 목적
- 선형적 확장성 달성: 노드 추가에 비례한 성능 향상
- 초저지연 데이터 액세스: 마이크로초 단위의 응답시간 제공
- 고가용성 보장: 장애 상황에서도 서비스 연속성 유지
- 복잡성 최소화: 확장 시 아키텍처 복잡성 증가 방지
필요성
- 실시간 금융 거래 시스템의 요구사항 증가
- IoT 및 빅데이터 환경에서의 대용량 데이터 처리 필요
- 클라우드 네이티브 환경에서의 탄력적 확장 요구
- 마이크로서비스 아키텍처와의 시너지 효과 창출
핵심 개념
기본 개념
Tuple Space (튜플 스페이스)
- 분산 공유 메모리의 한 형태로, 데이터가 튜플 형태로 저장되는 가상적인 공간
- 프로세스들이 콘텐츠 기반 주소 지정을 통해 데이터를 읽고 쓸 수 있는 저장소
- Linda 코디네이션 모델에서 시작된 개념으로, 시간적, 공간적, 흐름적 디커플링을 제공
Processing Unit (처리 단위)
- SBA 의 기본 빌딩 블록으로, 애플리케이션 컴포넌트와 데이터를 포함하는 자율적인 실행 단위
- 웹 컴포넌트, 비즈니스 로직, 인메모리 데이터 그리드를 포함
- 독립적으로 배포, 확장, 관리가 가능한 단위
In-Memory Data Grid (인메모리 데이터 그리드)
- 메모리 내에서 데이터를 저장하고 처리하는 분산 캐싱 시스템
- 디스크 I/O 없이 데이터 액세스를 제공하여 초저지연 달성
- 데이터 파티셔닝과 복제를 통한 고가용성 보장
실무 구현 연관성
확장성 (Scalability) 측면
- 수평적 확장을 통한 선형적 성능 향상
- 데이터베이스 병목 현상 제거로 인한 무제한 확장 가능성
- 동적 Processing Unit 추가/제거를 통한 탄력적 확장
성능 (Performance) 측면
- 메모리 기반 데이터 액세스로 마이크로초 단위 지연시간 달성
- 데이터 지역성 (Data Locality) 활용으로 네트워크 오버헤드 최소화
- 병렬 처리를 통한 높은 처리량 제공
안정성 (Reliability) 측면
- 데이터 복제를 통한 장애 복구 능력
- 무중단 서비스를 위한 자동 페일오버 메커니즘
- 분산 환경에서의 데이터 일관성 보장
주요 기능 및 역할
데이터 관리 기능
- 분산 데이터 저장 및 복제
- 자동 데이터 파티셔닝
- 트랜잭션 처리 및 일관성 보장
- 데이터 지역성 최적화
처리 기능
- 이벤트 기반 처리
- 맵리듀스 패턴 지원
- 비동기 처리 지원
- 실시간 스트림 처리
관리 기능
- 자동 로드 밸런싱
- 장애 감지 및 복구
- 동적 확장 및 축소
- 모니터링 및 관리
특징
아키텍처 특징
- 공유 없음 (Shared Nothing): 각 노드가 독립적으로 동작
- 수평적 확장: 노드 추가를 통한 확장
- 데이터 지역성: 데이터와 처리 로직의 동일 위치 배치
- 이벤트 기반: 비동기 메시징을 통한 컴포넌트 간 통신
성능 특징
- 초저지연: 마이크로초 단위 응답시간
- 고처리량: 초당 수백만 건의 트랜잭션 처리
- 선형적 성능: 노드 수에 비례한 성능 향상
- 메모리 기반: 디스크 I/O 최소화
핵심 원칙
- 분산 처리: 데이터와 처리 로직을 여러 노드에 분산
- 메모리 우선: 모든 데이터를 메모리에 저장
- 비동기 통신: 컴포넌트 간 비동기 메시징 활용
- 자율성: 각 Processing Unit 의 독립적 동작
- 탄력성: 동적 확장 및 장애 복구 능력
주요 원리
튜플 스페이스 원리
데이터 분산 원리
- 일관성 해싱을 통한 데이터 파티셔닝
- 복제를 통한 고가용성 보장
- 로드 밸런싱을 통한 균등한 부하 분산
처리 원리
- 이벤트 기반 처리 모델
- 맵리듀스 패턴을 통한 분산 처리
- 비동기 처리를 통한 높은 처리량
작동 원리 및 방식
graph TD
A[Client Request] --> B[Message Grid]
B --> C[Processing Grid]
C --> D[Processing Unit 1]
C --> E[Processing Unit 2]
C --> F[Processing Unit N]
D --> G[In-Memory Data Grid 1]
E --> H[In-Memory Data Grid 2]
F --> I[In-Memory Data Grid N]
G --> J[Data Grid]
H --> J
I --> J
J --> K[Deployment Manager]
K --> L[Virtualized Middleware]
style A fill:#e1f5fe
style B fill:#f3e5f5
style C fill:#e8f5e8
style D fill:#fff3e0
style E fill:#fff3e0
style F fill:#fff3e0
style G fill:#fce4ec
style H fill:#fce4ec
style I fill:#fce4ec
style J fill:#e0f2f1
style K fill:#f1f8e9
style L fill:#fafafa
작동 단계:
- 클라이언트 요청이 메시지 그리드에 도달
- 처리 그리드가 적절한 Processing Unit 선택
- 선택된 Processing Unit 에서 비즈니스 로직 실행
- 인메모리 데이터 그리드에서 데이터 액세스
- 결과를 클라이언트에게 반환
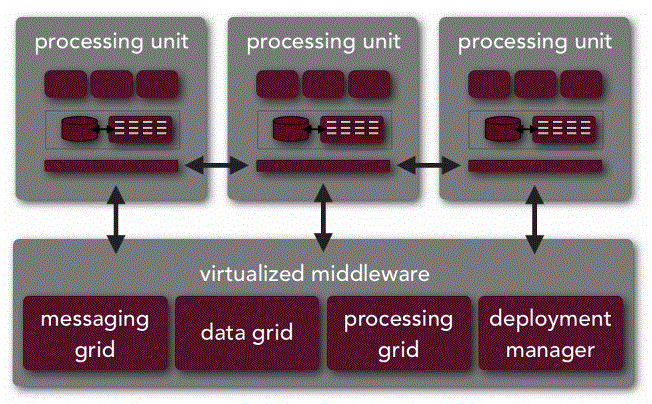
구조 및 아키텍처
전체 아키텍처 구조
graph TB
subgraph "Virtualized Middleware"
MG[Message Grid]
PG[Processing Grid]
DG[Data Grid]
DM[Deployment Manager]
end
subgraph "Processing Units"
PU1[Processing Unit 1]
PU2[Processing Unit 2]
PU3[Processing Unit N]
end
subgraph "Each Processing Unit"
APP[Application Modules]
IMDG[In-Memory Data Grid]
APS[Async Persistent Store]
DRE[Data Replication Engine]
end
MG --> PU1
MG --> PU2
MG --> PU3
PG --> PU1
PG --> PU2
PG --> PU3
DG --> PU1
DG --> PU2
DG --> PU3
DM --> PU1
DM --> PU2
DM --> PU3
PU1 --> APP
PU1 --> IMDG
PU1 --> APS
PU1 --> DRE
style MG fill:#e3f2fd
style PG fill:#e8f5e8
style DG fill:#fce4ec
style DM fill:#fff3e0
style PU1 fill:#f3e5f5
style PU2 fill:#f3e5f5
style PU3 fill:#f3e5f5
style APP fill:#e1f5fe
style IMDG fill:#e0f2f1
style APS fill:#fff8e1
style DRE fill:#fafafa
구성요소
| 구분 | 구성요소 | 기능 | 역할 | 특징 |
|---|---|---|---|---|
| 필수 | Processing Unit | 독립적 실행 단위 | 애플리케이션 로직과 데이터 호스팅 | 자율적, 확장 가능 |
| In-Memory Data Grid | 메모리 내 데이터 저장 | 초저지연 데이터 액세스 제공 | 분산, 복제 지원 | |
| Message Grid | 요청 라우팅 | 클라이언트 요청을 적절한 PU 로 전달 | 로드 밸런싱 | |
| Data Grid | 데이터 관리 | 분산 데이터 동기화 및 복제 | 일관성 보장 | |
| Processing Grid | 처리 조정 | 분산 처리 및 맵리듀스 조정 | 병렬 처리 지원 | |
| 선택 | Async Persistent Store | 비동기 영속화 | 장애 복구를 위한 데이터 백업 | 선택적 영속성 |
| Data Replication Engine | 데이터 복제 | PU 간 데이터 동기화 | 고가용성 향상 | |
| Deployment Manager | 배포 관리 | 동적 PU 배포 및 관리 | 운영 효율성 | |
| Monitoring System | 모니터링 | 시스템 상태 및 성능 모니터링 | 운영 가시성 |
Cell vs. Processing Unit 비교
| 항목 | Cell (Cell-based Architecture) | Processing Unit (Space-based Architecture) |
|---|---|---|
| 정의 | 독립적인 마이크로서비스 환경을 포함한 자율 실행 단위 | 메모리 - 기반 분산 환경에서 데이터를 처리하는 단위 컴포넌트 |
| 구성 요소 | API 서버, DB, 캐시, 큐, 메시지 브로커 등 전체 서비스 스택 포함 | PU + In-Memory Data Grid (IMDG) + Messaging + SLA 관리 |
| 설계 목적 | 장애 격리와 스케일아웃을 위한 단위화 (셀 간 고립) | 대규모 동시성 처리와 성능 최적화, 메모리 기반 처리 |
| 라우팅 방식 | 요청 Partition Key 기반 라우팅 (예: UserID → 특정 Cell 로) | 데이터 중심 접근 방식 (Data Affinity, Collocation 기반 라우팅) |
| 상태 저장 | 일반적으로 상태 저장 서비스 포함 (DB, Redis 등) | 상태 비저장 또는 IMDG 내 상태 유지 |
| 스케일 아웃 방식 | Cell 단위로 수평 확장 가능 (Cell A, Cell B 등 독립 복제) | PU 수 증가로 자동 수평 확장, 클러스터 내 동적 할당 |
| 고가용성 및 장애 격리 | 한 Cell 장애 시 다른 Cell 에 영향 없음 (Cell Router 가 fallback 가능) | PU 장애 시 다른 PU 가 작업을 takeover 함 (Eventual Recovery) |
| 장애 복구 전략 | Control Plane 이 감지 후 다른 Cell 로 트래픽 라우팅하거나 Cell 재생성 | SLA 위반 시 자동으로 PU 를 재시작하거나 백업 PU 활성화 |
| 데이터 접근 방식 | 각 Cell 내부 DB 또는 스토리지를 통해 접근 | 중앙 저장소 없이 In-Memory Grid 에서 직접 데이터 조회 |
| 사용 시나리오 | 다중 리전 기반 SaaS, 멀티테넌시, 사용자 격리 목적 서비스 | 초고속 트랜잭션 처리, 실시간 이벤트 분석, 트레이딩 시스템, IoT 처리 등 |
| 주요 기술 예시 | AWS Cell-based Design, Netflix Cell Architecture | GigaSpaces XAP, Hazelcast Jet, Apache Ignite, Oracle Coherence |
구현 기법
| 카테고리 | 기법 | 정의 및 목적 | 주요 구성 요소 | 대표 기술/예시 |
|---|---|---|---|---|
| 데이터 저장 및 공유 | 튜플 스페이스 (Tuple Space) | 분산 공유 메모리 모델 기반 비동기적 데이터 공유 및 통신 제공 | 튜플 저장소, 패턴 매칭 엔진, 동기화 락 | JavaSpaces, Linda, 직접 구현 예시 (Python) |
| 데이터 분산 | 데이터 파티셔닝 (Data Partitioning) | 해시 또는 범위 기반으로 데이터를 다수 노드에 분산 저장하여 확장성과 부하 분산 제공 | 해시 함수, 파티션 맵, 분할 알고리즘 | Consistent Hashing, Range Partitioning |
| 이벤트 처리 | 이벤트 기반 처리 (Event-Driven Processing) | 이벤트 발생 시 비동기 로직 실행으로 컴포넌트 간 느슨한 결합 유지 | 이벤트 큐, 발행자/구독자, 이벤트 핸들러 | Queue, Pub/Sub, Python 기반 이벤트 핸들러 |
| 데이터 복제 및 가용성 | 분산 캐싱 / 미러링 | 여러 노드에 캐시 및 복제 저장소 구성으로 데이터 접근 지연 최소화 및 장애 복구 대비 | 캐시 노드, 캐시 관리자, 복제 컨트롤러, 일관성 전략 | Hazelcast, Apache Ignite, 복제 기반 캐시 시스템 |
| 실행 단위 관리 | Processing Unit 설계 | 독립적인 비즈니스 로직 및 메모리 공간으로 구성된 단위 실행 체계 | PU (로직 + 메모리), 복제 엔진, 라우터 | GigaSpaces, SATS, 커스텀 PU 컨테이너 |
| 미들웨어 구성 | 가상 미들웨어 (Virtual Middleware) | 메시지 라우팅, 데이터 분산, 이벤트 오케스트레이션 기능 제공 | 메시지 큐, 처리 그리드, 라우터, 오케스트레이터 | Jini, GigaSpaces Message Grid |
| 확장성 관리 | 오토스케일링 및 SLA 기반 제어 | 부하에 따라 PU 를 자동으로 배치하거나 제거하며 SLA 충족 유지 | SLA 모니터링, Deployment Manager, 자원 스케줄러 | Kubernetes, GigaSpaces SLA Manager |
- 데이터 공유 계층: Tuple Space, IMDG 와 같은 메모리 기반 공유 저장소 중심
- 처리/이벤트 계층: 이벤트 루프 기반 처리, 메시지 기반 오케스트레이션
- 확장/복제 계층: 고가용성 및 부하 분산을 위한 캐시, 미러링, 오토스케일링 등
- 운영/제어 계층: SLA 기반 처리 및 PU 관리 자동화, 배치 제어
튜플 스페이스 구현
정의: 분산 공유 메모리를 통한 데이터 저장 및 액세스 메커니즘
구성:
- 튜플 저장소 (Tuple Repository)
- 패턴 매칭 엔진 (Pattern Matching Engine)
- 동기화 메커니즘 (Synchronization Mechanism)
목적: 프로세스 간 비동기적, 익명적 통신 제공
실제 예시:
| |
데이터 파티셔닝 구현
정의: 데이터를 여러 노드에 분산하여 저장하는 기법
구성:
- 해시 기반 파티셔닝
- 레인지 기반 파티셔닝
- 컨시스턴트 해싱
목적: 부하 분산 및 확장성 향상
실제 예시:
| |
이벤트 기반 처리 구현
정의: 이벤트 발생에 따른 비동기 처리 메커니즘
구성:
- 이벤트 발행자 (Event Publisher)
- 이벤트 구독자 (Event Subscriber)
- 이벤트 큐 (Event Queue)
목적: 컴포넌트 간 느슨한 결합 및 비동기 처리
실제 예시:
| |
분산 캐싱 구현
정의: 여러 노드에 걸쳐 데이터를 캐싱하는 기법
구성:
- 캐시 노드 (Cache Node)
- 캐시 매니저 (Cache Manager)
- 일관성 관리자 (Consistency Manager)
목적: 데이터 액세스 성능 향상 및 확장성 제공
실제 예시:
| |
장점
| 카테고리 | 항목 | 설명 |
|---|---|---|
| 성능 (Performance) | 초저지연 처리 (Low Latency) | 모든 데이터를 메모리에 저장하고 디스크 I/O 를 제거하여 마이크로초 단위의 응답시간을 보장함 |
| 고성능 트랜잭션 처리 | 인메모리 데이터 그리드 구조와 네트워크 최소화 설계로 고속 처리 가능 | |
| 데이터 지역성 최적화 | 데이터와 연산이 같은 PU 에 위치하여 네트워크 지연을 최소화함 | |
| 확장성 (Scalability) | 선형 확장성 (Linear Scalability) | PU 를 수평으로 추가함으로써 처리 성능이 선형적으로 증가함 |
| 탄력적 확장 (Elastic Scaling) | 부하 증가 시 PU 를 동적으로 추가하고, 부하 감소 시 제거 가능 | |
| 단순한 확장 구조 | 중앙 집중형 DB 를 제거함으로써 아키텍처 복잡성 없이 수평 확장이 용이함 | |
| 가용성 & 복원력 (Availability & Resilience) | 고가용성 (High Availability) | 데이터 복제 및 페일오버 메커니즘으로 단일 장애 지점 제거 |
| 장애 격리 (Fault Isolation) | 각 PU 는 독립적으로 운영되어 장애가 전체 시스템에 미치는 영향을 최소화함 | |
| 아키텍처 유연성 (Modularity & Flexibility) | 자율성 및 격리성 (Autonomy & Isolation) | 각 PU 는 독립적으로 개발·테스트·배포 가능하여 CI/CD 및 마이크로서비스 스타일에 적합함 |
| 유연한 비즈니스 대응 | 로직과 데이터를 느슨하게 결합하여 다양한 요구사항에 대응 가능 | |
| 이벤트 기반 처리 (Event-Driven Architecture) | 비동기 이벤트 기반 처리 | 튜플 스페이스 기반의 메시지 패싱 구조로 느슨한 결합과 비동기 처리가 가능함 |
| 장애 회복 (Resilience) | 자동 복구 및 페일오버 지원 | 장애 발생 시 자동으로 다른 PU 로 트래픽 분산 또는 재시작 가능 |
단점과 문제점 그리고 해결방안
단점
| 항목 | 설명 | 해결 방안 전략 |
|---|---|---|
| 메모리 비용 부담 | 모든 데이터를 인메모리에 유지하므로 하드웨어 요구량이 높고 비용 증가 | 티어링 저장소 도입, 핫 데이터 위주 캐싱, Hybrid 구조 도입 |
| 데이터 일관성 확보 어려움 | 분산된 공간 간 동기화 지연 및 충돌 가능성 존재 | Eventual Consistency 전략, CQRS, 이벤트 소싱 |
| 구현 및 운영 복잡성 | PU, 미러링, 라우팅 등 설계 복잡도와 유지 보수 난이도 상승 | GigaSpaces, Hazelcast 등 검증된 플랫폼 활용, 설정 자동화 |
| 리소스 중복 | 공간 간 독립성이 강해 동일 데이터나 기능을 중복 배치하게 됨 | 공통 컴포넌트 리팩토링, 공유 인프라 구성, 멀티테넌시 최적화 |
| 분석 연산의 어려움 | 데이터가 분산되어 있어 전체 집계나 분석에 비효율 발생 | MapReduce, 분산 쿼리 엔진 (Presto, Spark SQL 등) 활용 |
| 네트워크 의존성 | PU 간 통신이 잦아 네트워크 장애 발생 시 성능 급락 가능 | 로컬 캐싱, 중복 경로 구성, 네트워크 장애 탐지 및 회복 전략 도입 |
문제점
| 항목 | 원인/상황 | 영향 | 탐지/진단 방법 | 예방/대응 전략 |
|---|---|---|---|---|
| 메모리 누수 | GC 최적화 부족, 튜플 잔존 | 시스템 성능 저하, Crash 위험 | Heap Dump, 프로파일링 도구 | 정기적인 GC 튜닝, GC 알고리즘 선택 (G1GC 등) |
| 데이터 불일치 | 복제/동기화 지연, 네트워크 파티션 | 무결성 저하, 처리 오류 유발 | 벡터 클록, 일관성 체크도구 | Conflict Resolver, 동기화 주기 최적화 |
| 핫스팟 발생 | 특정 키 또는 노드에 트래픽 집중 | 성능 저하, 특정 PU 과부하 | 트래픽 분석, 노드 로드 모니터링 | Consistent Hashing, 가상 노드 (Virtual Nodes) |
| 스플릿 브레인 현상 | 네트워크 분리 시 다중 마스터 발생 | 데이터 충돌, 시스템 안정성 저하 | Quorum 모니터링 | Paxos, Raft, 리더 선출 알고리즘 적용 |
| 캐시 미스 급증 | 예기치 못한 부하 상승, TTL 만료 등 | 응답 시간 증가, 사용자 체감 속도 저하 | Cache Hit Ratio 분석 | 예측 기반 캐싱, 캐시 워밍업, 적응형 캐싱 (Adaptive Caching) |
| 장애 감지 지연 | 모니터링 부족, 헬스체크 실패 무시 | 복구 지연, 서비스 중단 시간 증가 | 실시간 헬스체크, 트레이싱 | 자동화된 장애 감지 및 Failover 시스템 |
| 디버깅 난이도 | 분산 환경에서 동시성 문제 발생 | 테스트 및 문제 추적 어려움 | 분산 트레이싱 도구 (Zipkin, Jaeger) | 트랜잭션 로그, 추적 ID 기반 전파 |
| 데이터 손실 위험 | IMDG 의 비영속 특성, 장애 발생 시 복구 어려움 | 영구 데이터 소실, 비즈니스 로직 장애 | Write-Ahead Logging, Snapshot 관리 | 지속적 체크포인트, 디스크 기반 백업 + WAL 적용 |
도전 과제
| 카테고리 | 과제 | 원인 / 영향 | 해결 방향 (분석 기반 보완) |
|---|---|---|---|
| 확장성 & 네트워크 | 네트워크 오버헤드 | 노드 증가 시 데이터 분산으로 인한 트래픽 폭증→ 성능 저하 발생 가능 | 데이터 로컬리티 보장, 엣지 컴퓨팅 도입, 네트워크 토폴로지 최적화 |
| PU 오토스케일링 정책의 정밀성 부족 | SLA 기반 PU 스케일링이 비효율적일 경우 비용 과잉 또는 자원 부족 초래 | 예측 기반 오토스케일링 알고리즘, SLA-Event 동기화 정책 | |
| 데이터 일관성 | 실시간 데이터 복제 지연 | 분산된 PU 간 복제 타이밍 불일치→ 데이터 불일치 발생 가능 | 최종 일관성 모델 + 이벤트 소싱, Pub/Sub 기반 CQRS |
| 강한 일관성 보장 어려움 | CAP 정리상 가용성과의 트레이드오프 존재→ 금융/정합성 요구 시스템에서 제약 | 분산 트랜잭션 (2PC 개선), CRDT, 시계 동기화 전략 강화 | |
| 운영 복잡성 | 분산 노드 운영 및 장애 대응 어려움 | PU 수 증가에 따른 로그, 트레이스, 상태 추적 복잡도 증가 | 관찰성 도구 통합 (OTel, Grafana), 자동 Healing 및 상태 기반 경고 체계 |
| 테스트 및 디버깅 난이도 | 재현 환경 구성의 어려움 및 E2E 테스트 자동화 부재 | Chaos Engineering 기법, 시뮬레이션 테스트 인프라 | |
| 비용 및 자원 최적화 | 메모리 자원 낭비 | 복제 구조로 인한 중복 저장 → 메모리 사용률 증가 | Hybrid Memory-Disk 구조, LRU 기반 캐시 정책 |
| 인프라 사용률 불균형 | PU 간 자원 부하 편중 → 특정 노드 과부하 또는 유휴 노드 발생 | 자원 사용률 기반 로드 밸런싱, Auto-Rebalancing | |
| 보안 및 격리성 | 접근 제어 및 데이터 격리 미흡 | 인메모리 기반 공유 구조에서 인증·인가 정책 미비 시 보안 위협 발생 가능 | PU 별 접근 제어 정책, TLS 통신 암호화, 인증 토큰 활용 |
| 운영 도구 부족 | SBA 특화된 관찰성 도구 미비 | Zipkin, Jaeger 등 외부 도구 의존도 높음→ 분산 환경 통합 가시성 부족 | SBA 전용 대시보드/분산 로그 수집 플랫폼 개발 |
분류 기준에 따른 종류 및 유형
| 분류 기준 | 유형 | 설명 | 특징/선택 기준 |
|---|---|---|---|
| 데이터 저장 및 분산 | Partitioned Space | 데이터를 키/범위 기반으로 분할하여 PU 에 수평 분산 저장 | 확장성 중심, 부하 분산 우수 |
| Replicated Space | 모든 PU 에 동일한 데이터를 복제 저장 | 고가용성 중심, 읽기 부하 분산, 쓰기 비용 증가 가능 | |
| 파티셔닝 전략 | 해시 기반 분할 | 키 해시값 기반으로 데이터 위치 결정 | 균등 분산에 유리, 범위 쿼리 어려움 |
| 범위 기반 분할 | 특정 범위 (날짜, ID 등) 에 따라 파티션 분할 | 범위 쿼리에 적합, 불균형 가능성 있음 | |
| 수직 분할 (기능별) | 데이터 속성을 기능 도메인별로 분리 | 도메인 중심 최적화, 서비스 독립성 확보 | |
| 데이터 일관성 모델 | Strong Consistency | 모든 노드가 동일한 데이터를 즉시 유지 | 정합성 중요 시스템 적합, 쓰기 성능 저하 가능 |
| Eventual Consistency | 시간이 지남에 따라 일관된 상태에 도달 | 높은 처리량, 임시 불일치 허용, 분산 환경 최적화 | |
| 복제 방식 | Single Mirror | 한 개의 백업 노드 (PU) 에만 데이터 복제 | 단순 구조, 리스크 존재 |
| Multi Mirror | 여러 PU 에 다중 복제 저장 | 고가용성 보장, 리소스 비용 증가 가능 | |
| 장애 복구 전략 | Active-Passive | Primary PU + Backup PU 구성, 장애 시 페일오버 수행 | 안정적 복구 구조, 자원 비효율 가능 |
| Active-Active | 모든 PU 가 동시에 동작하며 Failover 없음 | 성능 균형, 충돌 해결 로직 필요 | |
| 처리 모델 | Synchronous | 요청/응답 기반의 동기 통신 | 일관성 및 직관적인 흐름 보장, 지연 발생 |
| Asynchronous (Event-driven) | 이벤트 기반 메시지 처리, 비동기 응답 | 높은 처리량, 복잡한 상태/에러 관리 필요 | |
| 노드 확장 방식 | Static Cluster | 수동으로 노드 및 PU 구성 | 제어 용이, 운영 비용 증가 가능 |
| Dynamic Cluster | SLA 기준으로 PU 자동 확장/축소 | 자원 최적화, 운영 자동화 가능 | |
| 배포 모델 | On-Premise | 자체 데이터 센터에 배포 | 높은 제어권, 고비용 |
| Cloud-Native | 클라우드 환경에 완전 배포 | 탄력적 확장, 플랫폼 종속성 가능 | |
| Hybrid Deployment | 클라우드와 온프레미스 혼합 배포 | 유연성 확보, 네트워크/운영 복잡성 증가 |
실무 사용 예시
| 분야 | 사용 목적 | 기술/환경 | 달성 효과 |
|---|---|---|---|
| 금융 거래 시스템 | 고속 트랜잭션 처리, 무중단 운영 | GigaSpaces XAP, Event Sourcing, IMDG (In-Memory Data Grid) | 마이크로초 단위 응답, 고가용성, 장애 격리 |
| 전자상거래 | 대규모 주문 및 결제 처리 | Spring PU Framework, Apache Ignite, CQRS, Event Queue | 병목 없는 트랜잭션 흐름, 실시간 재고/결제 처리 |
| 실시간 추천 시스템 | 사용자 행동 기반 실시간 개인화 추천 | Machine Learning 모델, PU 기반 인메모리 분석 | 추천 속도 향상, 사용자 이탈률 감소 |
| IoT/센서 처리 | 실시간 센서 이벤트 수집 및 분석 | Hazelcast, Apache Ignite, Stream Processing + PU | 병렬 처리 및 지연 최소화, 수평 확장 용이 |
| 소셜 플랫폼 | 수백만 세션 관리, 대규모 사용자 활동 처리 | PU 기반 세션 클러스터링, WebSocket, Redis | 세션 안정성 확보, 수평 확장에 유리, 빠른 실시간 반응성 |
| 게임 서버 백엔드 | 상태 동기화 및 초저지연 인터랙션 관리 | Redis Cluster + Lua, GigaSpaces 기반 실시간 메모리 처리 | 게임 상태 공유 최적화, 부하 분산, 지연 최소화 |
| 사기 탐지/보안 | 실시간 거래 이상 징후 탐지 | Rule Engine + PU, ML Model, Streaming Engine | 실시간 탐지 및 차단, 위협 최소화 |
| 캐시 중심 웹 서비스 | DB 의존도 감소 및 빠른 응답 제공 | Apache Ignite + Space 기반 캐시 처리 구조 | DB 부하 완화, 페이지 렌더링 속도 향상 |
활용 사례
사례 1: 전자상거래 대규모 주문 처리 시스템
시스템 구성: 여러 공간 (Space) 에 주문 데이터 파티셔닝, 각 공간에 프로세싱 유닛 배치
graph TD
User(사용자) --> LB(로드 밸런서)
LB --> PU1(프로세싱 유닛 1)
LB --> PU2(프로세싱 유닛 2)
PU1 --> Space1(공간 1)
PU2 --> Space2(공간 2)
Space1 -- 미러링 --> Space2
워크플로우: 주문 요청 → 로드 밸런서 → 적절한 공간 → 프로세싱 유닛에서 처리 → 데이터 미러링
역할: 장애 발생 시 해당 공간만 격리, 전체 서비스는 정상 운영
차이점: 미적용 시 주문 폭주로 중앙 DB 병목, 적용 시 공간별로 병렬 처리 및 장애 격리
구현 예시:
| |
- 위 코드는 주문 요청을 Space-Based Architecture 에서 특정 공간으로 라우팅하는 원리를 보여준다.
사례 2: 금융 실시간 결제 시스템
시스템 구성
flowchart TD Client --> Router Router --> PU1["PU1 (Primary)"] Router --> PU2["PU2 (Primary)"] PU1 --> SpaceP1[(Tuple Space Partition)] PU2 --> SpaceP2[(Tuple Space Partition)] PU1 <--> Backup1[PU1 Backup] PU2 <--> Backup2[PU2 Backup]
Workflow:
- 고객 결제 요청 → Router → 특정 PU
- PU 에서 Tuple 로 insert → Backup 으로 복제
- Polling Container 가 튜플 꺼내며 비즈니스 로직 처리
- 결제 결과 튜플 등록 및 응답
- PU 장애 시 Backup 이 자동 사용
SBA 도입 전/후 비교:
| 항목 | SBA 적용 전 | SBA 적용 후 |
|---|---|---|
| 처리속도 | 중앙 DB 병목, 지연 발생 | 메모리 공간 기반 병목 해소, 지연 감소 |
| 장애 대처 시간 | 장애 시 서비스 전체 중단 | PU 단위 장애 격리, 자동 복구 |
| 확장성 | 수직 확장 및 복잡한 샤딩 | 노드 증설만으로 간편한 수평 확장 |
사례 2: 고빈도 거래 (HFT) 시스템 사례
시스템 구성:
- 다수의 Processing Unit 이 각각 특정 금융 상품 데이터를 담당
- 실시간 시장 데이터 피드를 이벤트 스트림으로 처리
- 거래 결정 로직과 포지션 데이터를 동일한 메모리 공간에 배치
시스템 구성 다이어그램:
graph TB
subgraph "Market Data Sources"
MDS1[Exchange A]
MDS2[Exchange B]
MDS3[News Feed]
end
subgraph "Space-Based Trading System"
MG[Message Grid]
subgraph "Processing Units"
PU1[Equity Trading PU]
PU2[FX Trading PU]
PU3[Options Trading PU]
end
subgraph "Data Grids"
DG1[Market Data Grid]
DG2[Position Data Grid]
DG3[Risk Data Grid]
end
end
subgraph "External Systems"
OMS[Order Management]
RISK[Risk Management]
SETTLE[Settlement]
end
MDS1 --> MG
MDS2 --> MG
MDS3 --> MG
MG --> PU1
MG --> PU2
MG --> PU3
PU1 --> DG1
PU1 --> DG2
PU2 --> DG1
PU2 --> DG2
PU3 --> DG1
PU3 --> DG2
DG3 --> RISK
PU1 --> OMS
PU2 --> OMS
PU3 --> OMS
OMS --> SETTLE
style MG fill:#e3f2fd
style PU1 fill:#e8f5e8
style PU2 fill:#e8f5e8
style PU3 fill:#e8f5e8
style DG1 fill:#fce4ec
style DG2 fill:#fce4ec
style DG3 fill:#fce4ec
Workflow:
- 시장 데이터 수신 및 Message Grid 를 통한 라우팅
- 해당 상품 담당 Processing Unit 에서 데이터 처리
- 인메모리 데이터 그리드에서 포지션 및 리스크 데이터 조회
- 거래 알고리즘 실행 및 주문 결정
- 주문 관리 시스템으로 주문 전송
- 실시간 포지션 및 리스크 업데이트
Space-Based Architecture 의 역할:
- 시장 데이터와 거래 로직을 동일한 메모리 공간에 배치하여 지연시간 최소화
- 각 상품별 Processing Unit 분리로 병렬 처리 및 확장성 제공
- 인메모리 데이터 그리드를 통한 초고속 포지션 계산
구현 예시
| |
구현 특징:
- Processing Unit 분리: 각 거래 심볼별로 독립적인 처리 단위
- 인메모리 데이터 그리드: 모든 데이터를 메모리에 저장하여 초저지연 달성
- 이벤트 기반 처리: 시장 데이터 변경 시 자동으로 처리 로직 실행
- 메시지 그리드: 데이터 라우팅 및 처리 단위 간 조정
- 확장성: 새로운 심볼 추가 시 독립적인 Processing Unit 생성
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 카테고리 | 고려 항목 | 설명 | 권장 방식 / 최적화 전략 |
|---|---|---|---|
| 설계 전략 | PU 구성 전략 | 기능 또는 데이터 파티션 단위로 PU 분리 설계→ 독립성 및 장애 격리 가능 | 도메인 기반 설계, ID 기반 수평 분산 |
| 파티셔닝 전략 | 트래픽/데이터 특성 기반 분할 방식 선택→ 핫스팟/불균형 방지 | 일관 해싱, 범위 기반 파티셔닝, 동적 리밸런싱 | |
| 데이터 모델링 | 객체지향 + 문서 기반 데이터 모델링 병행 | Domain 중심 스키마 설계, Query 최적화 고려 | |
| 확장성 & 자동화 | PU 오토스케일링 | SLA 기반 자동 확장 정책 수립 | CPU/Memory/Latency 기반 HPA or KEDA 활용 |
| 배포 전략 | 클러스터 기반 롤링 배포 또는 Blue/Green 배포 | Canary 또는 무중단 롤링 배포 전략 적용 | |
| 운영 자동화 | 배포, 테스트, 확장 등 반복 작업 자동화 | CI/CD + IaC(Terraform, ArgoCD 등) | |
| 데이터 & 일관성 | 영속성 확보 | IMDG 기반 데이터 휘발성 이슈 대응 | WAL, Snapshot, SSD 기반 백업 구조 구성 |
| 분산 일관성 | 실시간 동기화 어려움 해결 | 최종 일관성, 이벤트 소싱, CDC, Conflict Resolver 전략 활용 | |
| 복제 전략 | 싱글/멀티 미러 구성 시 자원 비용 vs 가용성 고려 | 리드 중심 멀티 복제, 쓰기 PU 제한 또는 Write-Master 모델 적용 | |
| 관찰성 & 운영 관리 | 모니터링 체계 | PU 및 클러스터 상태 실시간 추적 필요 | Prometheus + Grafana + Alertmanager 통합 |
| 분산 트레이싱 | 비동기 이벤트 흐름 가시화 및 디버깅 | OpenTelemetry, Zipkin, Jaeger 연동 | |
| 로그 집계 및 분석 | 장애 추적 및 감사 로그 분석 | Loki, Fluent Bit, EFK/ELK Stack | |
| 성능 최적화 | 네트워크 최적화 | PU 간 통신 비용 절감, 데이터 지역성 강화 | gRPC, 이중 NIC 구성, 데이터 - 연산 PU 병렬 배치 |
| 메모리 관리 | 대용량 데이터 처리 시 GC 및 압축 필요 | LRU 캐시 정책, 데이터 티어링, 압축 엔진 사용 | |
| 장애 대응 & 복구 | 장애 감지 및 전환 | PU 장애 시 자동 전환과 상태 복구 필요 | 헬스체크 기반 Failover, Leader Election, Retry/Timeout 구성 |
| 백업 및 복구 | 복구 시점 제어 및 데이터 손실 최소화 필요 | 증분 백업, Async Snapshot, 스케줄 기반 WAL 아카이브 적용 | |
| 보안 | 메모리 & 네트워크 보안 | PU 간 통신 및 IMDG 접근 보안 | mTLS, VPN, TLS 적용, In-Memory 암호화 사용 |
| 인증 및 권한 관리 | PU 별 접근 제어 및 중앙화된 인증 체계 필요 | OAuth2, RBAC, API Key, Token 기반 인증 |
최적화하기 위한 고려사항 및 주의할 점
| 카테고리 | 최적화 요소 | 설명 | 권장사항 |
|---|---|---|---|
| 메모리 최적화 | 데이터 압축 | 메모리 사용량을 줄이기 위한 실시간 압축 처리 | LZ4, Snappy 등 경량 압축 알고리즘 적용 |
| 가비지 컬렉션 | GC 지연 최소화를 통한 처리 성능 향상 | G1GC, ZGC, 정기적 튜닝 및 메모리 프로파일링 | |
| 복제 전략 | 전체 데이터 복제 대신 Hot 영역 중심 복제 | Hot/Cold Tier 적용, 세분화된 파티셔닝 | |
| 네트워크 최적화 | 배치 처리 | 빈번한 네트워크 호출을 줄이기 위한 묶음 처리 | 마이크로배치 + 파이프라이닝 구조 |
| 프로토콜 최적화 | 직렬화/역직렬화 효율성 향상 | Protocol Buffers, Avro 사용 | |
| 로컬 우선 처리 | PU 간 통신을 최소화하여 네트워크 부하를 줄임 | 로컬 튜플 우선 처리 로직 적용 | |
| 네트워크 병목 방지 | 공간 간 네트워크 부하 최소화 | 네트워크 구조 개선, QoS 적용, CDN 연계 | |
| 처리 최적화 | 병렬 처리 | 멀티코어 활용 극대화 및 지연 최소화 | 워크 스틸링, async/task 기반 비동기 구조 |
| 캐시 친화 구조 | CPU 캐시 활용 극대화를 위한 데이터 구조 최적화 | 캐시 라인 정렬, Prefetching 적용 | |
| 상태 추적 | 메시지 처리 상태 관리로 장애 감지 및 복구 용이 | Distributed Tracing (e.g. Jaeger, Zipkin) 도입 | |
| 저장소 최적화 | 티어링 전략 | 자주 사용되는 데이터만 고속 메모리에 저장 | 자동화된 Hot/Cold 분류 및 정책 기반 이동 |
| 인덱싱 | 빠른 검색을 위한 인메모리 색인 구조 | 블룸 필터, 계층 인덱스, 인메모리 B+ Tree | |
| 확장성 최적화 | 자동 스케일링 | 부하에 따라 PU 수를 동적으로 조절 | SLA 기반 Auto-scaler, 예측 기반 리소스 관리 |
| 로드 밸런싱 | 요청을 고르게 분산시켜 특정 PU 과부하 방지 | 가중치 기반 라우팅, Health Check 기반 우선순위 분산 | |
| 자원 효율화 | 공간 단위 리소스 낭비 방지 | 공통 인프라 재사용, 리소스 사용률 모니터링 | |
| 정합성/일관성 최적화 | 데이터 정합성 유지 | 분산 환경에서 일관성 보장 | CDC 기반 정합성 보정, 버전 태깅, 벡터 클록 적용 |
| Eventually Consistent 접근 | 강한 일관성 대신 지연된 동기화 허용 | CQRS, Event Sourcing 기반 처리 모델 적용 |
주제와 관련하여 주목할 내용
| 카테고리 | 세부 주제 | 핵심 항목 | 설명 및 중요도 |
|---|---|---|---|
| 1. 아키텍처 구조 | 장애 격리 구조 | 공간 기반 격리 아키텍처 | PU 간 독립성 확보로 전체 장애 전파 방지 및 빠른 복구 가능 |
| 데이터 파티셔닝 | 해시/범위 기반 분산 전략 | 병목 없이 균등한 부하 분산과 수평적 확장성 확보 | |
| 오토스케일링 구조 | SLA 기반 PU 자동 조정 | 실시간 부하 기반 탄력적 확장 및 자원 효율화 | |
| 복제 전략 | Master-Slave 또는 Multi-Replica | 고가용성 및 데이터 신뢰성 확보 | |
| 2. 성능 최적화 | 메모리 최적화 | JVM 튜닝 / GC 최적화 | 짧은 응답시간 유지 및 GC Pause 방지 |
| 네트워크 처리 최적화 | 직렬화/역직렬화 방식 개선 | 메시지 크기 최소화 및 전송 효율 향상 (예: Protobuf, Avro) | |
| 캐싱 계층 활용 | 인메모리 다층 캐싱 전략 | DB I/O 최소화 및 응답 속도 개선 | |
| 3. 데이터 일관성 | 일관성 모델 | 최종 일관성 or 강한 일관성 선택 | CAP 정리에 따라 시스템 요구사항에 맞는 일관성 모델 선택 필요 |
| 동기화 기법 | 벡터 클록, 타임스탬프 기반 동기화 | 데이터 충돌 감지 및 순서 보장 | |
| 충돌 해결 | CRDT 적용 등 Conflict-Free 구조 | 분산 환경에서도 일관성 있는 데이터 병합 가능 | |
| 4. 가용성 및 복구 | 장애 복구 메커니즘 | 자동 Failover 및 Health Check | PU 상태 기반 전환으로 무중단 운영 가능 |
| 백업 및 영속성 확보 | Snapshot, Checkpoint, WAL | IMDG 기반 휘발성 데이터에 대한 내구성 확보 | |
| 5. 운영 및 모니터링 | 모니터링 지표 수집 | Prometheus, Grafana 기반 메트릭 수집 | 성능 모니터링, 용량 예측, SLA 추적 가능 |
| 분산 추적 | OpenTelemetry, Zipkin 연동 | 이벤트 흐름과 병목 구간 시각화 및 추적 | |
| 장애 탐지 자동화 | Alert Rule 기반 자동화 체계 | 운영 효율성과 빠른 대응 시간 확보 | |
| 6. 보안 | 암호화 및 보호 | 메모리 내 암호화 / 전송 중 암호화 | TLS/mTLS, at-rest/in-transit 보안 강화 |
| 접근 제어 | RBAC 및 토큰 기반 인증 | PU 및 관리 인터페이스에 대한 정교한 권한 제어 필요 |
반드시 학습해야할 내용
| 카테고리 | 주제 | 핵심 항목 | 설명 및 학습 포인트 |
|---|---|---|---|
| 기초 이론 | 분산 시스템 설계 원칙 | CAP 정리, 합의 알고리즘 (Raft, PBFT 등) | SBA 는 분산된 공간 간 강한 일관성이 어려우므로 일관성 - 가용성 트레이드오프 이해 필수 |
| 분산 해시 및 노드 배치 | Consistent Hashing | PU 간 데이터 파티셔닝과 핫스팟 방지의 핵심 전략 | |
| 동시성 제어 | Lock-free 알고리즘, 메시지 기반 동기화 | SBA 는 공유 상태보다 메시지 기반 비동기 처리에 최적화된 모델을 지향 | |
| 데이터 구조/공간 개념 | Tuple Space, Linda 모델 | 공간 기반의 분산 메시징 구조에 대한 이론적 기반 | |
| 아키텍처 및 구현 기술 | 이벤트 기반 처리 | Event-Driven Architecture, 비동기 Queue | SBA 의 PU 간 통신 및 트리거 기반 처리 구조의 핵심 |
| 인메모리 데이터 관리 | IMDG (Hazelcast, Ignite, XAP 등) | SBA 의 핵심 저장소로 고속 처리와 복제 구조 학습 필수 | |
| 데이터 파티셔닝 및 복제 전략 | 해시 파티셔닝, 범위 파티셔닝, 미러링 | 고가용성과 확장성을 위한 PU 간 데이터 분산 및 복제 로직 학습 | |
| 비동기 I/O & 직렬화 | Netty, Protocol Buffers, Avro 등 | 고성능 메시징 구현을 위한 필수 구성 요소 | |
| GC 및 메모리 최적화 | G1GC, ZGC, Memory Tiering | 인메모리 기반 아키텍처의 성능을 결정짓는 핵심 기술 요소 | |
| 플랫폼 및 운영 기술 | 클라우드 네이티브 인프라 | Kubernetes, Docker | SBA 는 PU 를 컨테이너 단위로 배포 및 확장하므로 클라우드 오케스트레이션 기술이 필수 |
| 서비스 메시 및 네트워크 정책 | Istio, Linkerd | PU 간 통신을 제어하기 위한 서비스 메시 + 정책 기반 라우팅 구성 | |
| SLA 기반 오토스케일링 | HPA, Custom Autoscaler | PU 의 부하, 지연 시간, 메시지 큐 상태 기반으로 자동 스케일링 적용 | |
| 운영 자동화 및 배포 전략 | CI/CD, GitOps | SBA 기반 시스템은 지속적인 롤아웃 및 리소스 자동 복구를 요구함 | |
| 관찰성 및 추적 도구 | Prometheus, Grafana, Jaeger, OTel | PU 간 흐름, 이벤트 추적, 장애 진단을 위한 분산 트레이싱 및 메트릭 기반 모니터링 체계 구축 필요 | |
| 보안 아키텍처 | Zero Trust, TLS, 네트워크 분할 | SBA 는 노드 간 직접 통신이 많아 전송 계층 보안 및 인증 정책 적용 필수 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 아키텍처 | 공간 (Space) | 데이터와 프로세스를 저장·관리하는 분산 메모리 그리드 |
| 아키텍처 | 프로세싱 유닛 (Processing Unit) | 공간 내에서 비즈니스 로직을 실행하는 독립적 실행 환경 |
| 네트워크 | 로드 밸런서 (Load Balancer) | 요청을 여러 공간/프로세싱 유닛으로 분산하는 장치 |
| 데이터 | 파티셔닝 (Partitioning) | 데이터를 여러 공간에 분산 저장하는 전략 |
| 데이터 | 미러링 (Mirroring) | 장애 대비를 위한 공간 간 데이터 복제 |
| 운영 | 관리 콘솔 (Admin Console) | 시스템 모니터링 및 관리 도구 |
📌 용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 아키텍처 | Tuple Space | 데이터를 공유하는 메모리 공간, SBA 의 핵심 구성 |
| 시스템 구성 | Processing Unit (PU) | 로직, 메모리, 복제가 통합된 실행 단위 |
| 데이터 관리 | Partitioning | 데이터 분할 저장 전략 |
| 데이터 관리 | Replication | 데이터 복제 전략으로 내결함성 확보 |
| 메시징/이벤트 | Event-Driven | 이벤트 기반 비동기 처리 모델 |
| 장애 복구 | Active-Passive | 장애 시 백업 노드가 Primary 로 승격 |
| 운영 | SLA (Service Level Agreement) | 처리 속도, 용량 기준의 서비스 품질 보장 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 아키텍처 | Tuple Space | 분산 시스템에서 프로세스 간 통신을 위한 공유 메모리 공간으로, 데이터를 튜플 형태로 저장하고 패턴 매칭을 통해 접근 |
| 아키텍처 | Processing Unit | SBA 의 기본 실행 단위로, 애플리케이션 로직과 데이터를 포함하여 독립적으로 확장 가능한 컴포넌트 |
| 아키텍처 | Virtualized Middleware | 메시지 그리드, 데이터 그리드, 처리 그리드 등을 포함하는 가상화된 미들웨어 계층 |
| 데이터 | In-Memory Data Grid | 메모리 내에서 데이터를 저장하고 처리하는 분산 캐싱 시스템으로, 초저지연 데이터 액세스 제공 |
| 데이터 | Data Locality | 데이터와 처리 로직을 동일한 노드에 배치하여 네트워크 지연시간을 최소화하는 기법 |
| 데이터 | Consistent Hashing | 분산 해시 테이블에서 노드 추가/제거 시 데이터 재배치를 최소화하는 해싱 기법 |
| 성능 | Linear Scalability | 노드 수 증가에 비례하여 성능이 향상되는 확장성 특성 |
| 성능 | Microsecond Latency | 마이크로초 단위의 매우 낮은 응답 지연시간 |
| 성능 | Horizontal Scaling | 서버 수를 늘려서 성능을 향상시키는 수평적 확장 방식 |
| 처리 | Event-Driven Processing | 이벤트 발생에 기반하여 비동기적으로 처리하는 프로그래밍 모델 |
| 처리 | MapReduce Pattern | 대용량 데이터를 여러 노드에서 병렬로 처리하는 분산 처리 패턴 |
| 처리 | Asynchronous Replication | 데이터 복제를 비동기적으로 수행하여 성능을 향상시키는 기법 |
| 보안 | Zero Trust Network | 네트워크 내부의 모든 트래픽을 신뢰하지 않고 검증하는 보안 모델 |
| 보안 | RBAC (Role-Based Access Control) | 역할 기반 접근 제어 시스템으로, 사용자의 역할에 따라 권한을 부여 |
| 운영 | Observability | 시스템의 내부 상태를 외부에서 관찰할 수 있는 능력으로, 메트릭, 로그, 트레이스 포함 |
| 운영 | Service Mesh | 마이크로서비스 간 통신을 관리하는 인프라스트럭처 계층 |
| 운영 | Circuit Breaker | 장애가 발생한 서비스에 대한 호출을 차단하여 시스템 안정성을 보장하는 패턴 |
| 클라우드 | Container Orchestration | 컨테이너의 배포, 관리, 확장을 자동화하는 시스템 |
| 클라우드 | Auto Scaling | 시스템 부하에 따라 자동으로 리소스를 조정하는 기능 |
| 클라우드 | Infrastructure as Code | 인프라스트럭처를 코드로 정의하고 관리하는 방법론 |
참고 및 출처
- Software Architecture Patterns by Mark Richards - O’Reilly
- Space-Based Architecture Pattern - GigaSpaces
- GigaSpaces XAP Documentation
- Space-based architecture - Wikipedia
- Linda coordination language - Wikipedia
- Tuple space - Wikipedia
- JavaSpaces Service Specification
- Understanding Space-Based Architecture - Medium
- Space-Based Architecture vs Tier-Based Implementation - GigaSpaces
- Tuple spaces implementations and their efficiency - SpringerLink
🔗 참고 및 출처
- GigaSpaces 공식 문서 – Space-Based Architecture
- Wikipedia – Space-Based Architecture
- Medium – Understanding Space-Based Architecture
- TechTarget – Harnessing SBA for Performance
- Rajat Nigam – Space-Based Architecture Deep Dive
참고 및 출처
🔗 참고 및 출처
- GigaSpaces 공식 문서 – Space-Based Architecture
- Akka Documentation
- Microsoft Docs – Actor Model
- InfoQ – Actor Model vs Microservices
- Medium – Space-Based Architecture vs Actor