Latency vs. Throughput
Latency 와 Throughput 은 시스템 성능 평가의 양대 축으로 상호 보완적인 지표이다. Latency는 데이터 전송 지연 시간 (밀리초 단위) 으로, 실시간 화상 회의나 온라인 게임에서 사용자 경험에 직접적 영향을 미친다. Throughput은 초당 처리 가능한 데이터량 (MBps) 으로 대용량 트래픽 처리 능력을 결정한다. 시스템 설계자는 대역폭, 병목 현상, 하드웨어 자원 등 다양한 요소를 고려하여 균형점을 찾아야 한다. 이를 통해 실시간 시스템, 대용량 데이터 처리 등 다양한 응용 분야에서 최적의 성능을 달성할 수 있다.
핵심 개념
지연시간 (Latency)
지연시간은 데이터가 한 지점에서 다른 지점으로 이동하는 데 걸리는 시간이다. 시스템에서 요청이 시작된 시점부터 응답을 받는 시점까지의 지연을 의미합니다. 주로 밀리초 (ms), 마이크로초 (μs) 또는 나노초 (ns) 단위로 측정됩니다. 낮은 지연시간은 시스템의 응답성이 좋다는 것을 의미하며, 실시간 상호작용이 중요한 애플리케이션에서 특히 중요합니다.처리량 (Throughput)
처리량은 시스템이 단위 시간당 처리할 수 있는 작업량을 나타낸다. 네트워크에서는 초당 비트 수 (bps), 초당 요청 수 (RPS), 또는 초당 트랜잭션 수 (TPS) 등으로 측정된다. 높은 처리량은 시스템이 효율적으로 많은 작업을 처리할 수 있음을 의미하며, 대용량 데이터 처리가 필요한 시스템에서 중요한다.대역폭 (Bandwidth)
대역폭은 통신 채널의 최대 이론적 처리량을 나타낸다. 네트워크 케이블이나 연결이 처리할 수 있는 최대 데이터 양을 의미하며, 일반적으로 초당 비트 수 (bps) 로 표시된다. 대역폭은 처리량의 상한선을 설정하며, 실제 처리량은 대역폭보다 낮다.상충관계 (Trade-off)
지연시간과 처리량 사이에는 상충관계가 존재한다. 처리량을 높이기 위해 배치 처리, 병렬 처리 등의 기법을 사용하면 개별 요청의 지연시간이 증가할 수 있다. 반대로 지연시간을 최소화하기 위해 자원을 최적화하면 전체 처리량이 감소할 수 있다. 시스템 설계자는 애플리케이션의 요구사항에 따라 적절한 균형점을 찾아야 한다.병목 현상 (Bottlenecks)
시스템 내에서 전체 성능을 제한하는 요소를 병목 현상이라고 한다. 네트워크 대역폭, CPU 처리 능력, 메모리 접근 속도, 디스크 I/O 등 다양한 요소가 병목 현상을 일으킬 수 있으며, 이는 지연시간 증가와 처리량 감소로 이어진다. 효율적인 시스템 설계를 위해서는 병목 현상을 식별하고 해결하는 것이 중요하다.확장성 (Scalability)
시스템이 증가하는 부하를 처리하기 위해 자원을 효율적으로 추가할 수 있는 능력을 의미한다. 수평적 확장 (더 많은 서버 추가) 과 수직적 확장 (더 강력한 서버로 업그레이드) 을 통해 처리량을 증가시킬 수 있다. 그러나 확장 시 지연시간에 미치는 영향도 고려해야 한다.응답 시간 (Response Time)
응답 시간은 사용자가 요청을 보내고 완전한 응답을 받는 데 걸리는 총 시간을 의미한다. 지연시간과 관련이 있지만, 응답 시간에는 처리 시간과 대기 시간도 포함된다. 사용자 경험에 직접적인 영향을 미치는 중요한 지표이다.큐잉 이론 (Queueing Theory)
큐잉 이론은 대기열 (큐) 의 동작을 수학적으로 연구하는 분야로, 지연시간과 처리량의 관계를 이해하는 데 중요한 이론적 기반을 제공한다. Little 의 법칙 (L = λW) 과 같은 원리를 통해 시스템의 성능을 예측하고 최적화할 수 있다.
지연 시간 (Latency) vs. 처리량 (Throughput) 비교
사용자 경험 향상, 자원 활용 효율성 증대, 성능 병목 현상 파악, 확장성 계획 수립 등 다양한 목적을 위해 이 두 지표의 이해와 관리가 필요하다.
| 항목 | 지연 시간 (Latency) | 처리량 (Throughput) |
|---|---|---|
| 정의 | 요청이 시작되어 응답을 받기까지의 시간 | 단위 시간당 처리 가능한 작업의 양 |
| 측정 단위 | 밀리초 (ms), 마이크로초 (μs) 등 | 초당 요청 수 (RPS), Mbps 등 |
| 중요성 | 실시간 응답이 필요한 시스템에서 중요 | 대량의 데이터 처리 시스템에서 중요 |
| 영향 요소 | 네트워크 지연, 처리 시간, 큐 대기 시간 등 | 시스템 자원, 네트워크 대역폭 등 |
| 최적화 목표 | 최소화 (낮을수록 좋음) | 최대화 (높을수록 좋음) |
| 최적화 방법 | 캐싱, 로드 밸런싱, 경량화 등 | 병렬 처리, 리소스 확장 등 |
| 중요 응용 분야 | 실시간 시스템, 온라인 게임, 금융 거래 시스템 | 대용량 데이터 처리, 백업 시스템, 데이터 마이그레이션 |
주요 기능 및 역할
지연시간과 처리량은 시스템 성능을 다각도로 평가하고 최적화하는 데 핵심적인 역할을 한다.
| 항목 | 지연시간 (Latency) | 처리량 (Throughput) |
|---|---|---|
| 주요 역할 | 시스템 응답성 평가, 실시간성 보장, 사용자 경험 향상 | 시스템 효율성 평가, 자원 활용도 측정, 확장성 계획 |
| 성능 지표로서의 활용 | 애플리케이션의 응답 시간과 직접 연관, P99 지연시간 등 SLA 정의에 활용 | 시스템의 최대 처리 능력 정의, 용량 계획 수립에 활용 |
| 병목 현상 식별 | 높은 지연시간은 네트워크, CPU, 메모리 등의 병목 현상 식별에 도움 | 예상보다 낮은 처리량은 시스템 내 병목 현상 식별에 도움 |
| 시스템 설계 영향 | 낮은 지연시간을 위한 설계는 캐싱, 지역성, 효율적인 알고리즘 등에 초점 | 높은 처리량을 위한 설계는 병렬 처리, 배치 처리, 자원 효율성 등에 초점 |
특징
지연시간과 처리량은 다양한 요소에 의해 영향을 받으며, 각기 다른 특성을 가지고 있다.
| 항목 | 지연시간 (Latency) | 처리량 (Throughput) |
|---|---|---|
| 변동성 | 네트워크 혼잡, 부하 변동 등에 따라 크게 변할 수 있음 | 시스템 자원 한계에 도달하기 전까지는 비교적 안정적 |
| 사용자 경험 영향 | 직접적인 영향 (느린 응답 = 나쁜 경험) | 간접적인 영향 (처리량 한계 도달 시 지연시간 증가로 이어짐) |
| 분포 특성 | 꼬리가 긴 (long-tailed) 분포를 보이는 경우가 많음 (P99, P999 지연시간 중요) | 일반적으로 평균값이 의미 있는 정규 분포에 가까움 |
| 최적화 접근법 | 병렬 처리보다 직렬 처리가 유리할 수 있음 | 병렬 처리, 배치 처리가 유리함 |
핵심 원칙
지연시간과 처리량을 최적화하기 위한 핵심 원칙.
| 원칙 | 설명 |
|---|---|
| 균형 찾기 | 애플리케이션 요구사항에 맞게 지연시간과 처리량 사이의 적절한 균형점 찾기 |
| 병목 현상 제거 | 시스템 내 병목 현상을 식별하고 제거하여 전체 성능 향상 |
| 적절한 측정 | 정확한 지연시간과 처리량 측정을 통해 성능 문제 식별 및 개선 |
| 확장성 고려 | 부하 증가에 따른 지연시간과 처리량의 변화를 고려한 확장 계획 수립 |
| 실제 사용자 경험 우선 | 평균값보다 P95, P99 등 실제 사용자가 경험하는 성능 지표에 초점 |
주요 원리 및 작동 원리
지연시간과 처리량의 관계는 다양한 이론과 원리로 설명될 수 있다.
큐잉 이론과 Little 의 법칙
큐잉 이론은 지연시간과 처리량 사이의 관계를 수학적으로 설명한다. Little 의 법칙 (L = λW) 은 시스템 내 평균 요청 수 (L) 가 도착률 (λ) 과 평균 대기 시간 (W) 의 곱과 같다는 원리를 설명한다. 이는 처리량 (λ) 과 지연시간 (W) 사이의 근본적인 관계를 보여준다.
지연시간 - 처리량 곡선
아래의 이미지는 분산 네트워크 성능 분석을 위한 **지연시간 - 처리량 곡선 (Latency-Throughput Curve)**을 보여주며, 다음과 같은 핵심 요소를 포함한다.
X 축 (Injection Rate)
- 트래픽 주입률: 네트워크에 초당 주입되는 데이터 양 (단위: flits/cycle).
- **0 부터 포화점 (Saturation Point)**까지 증가하며, 네트워크 부하를 점진적으로 높임.
Y 축 (Latency)
- 패킷 지연시간: 데이터가 네트워크를 통과하는 데 걸리는 시간 (단위: cycles).
- 초기에는 낮은 값 유지 → 트래픽 증가 시 급격히 상승.
곡선 형태
- 선형 구간 (Linear Region): 낮은 주입률에서 처리량 증가 ↔ 지연시간 완만 상승.
- 포화 구간 (Saturation Region): 주입률 증가해도 처리량 정체 ↔ 지연시간 급증.
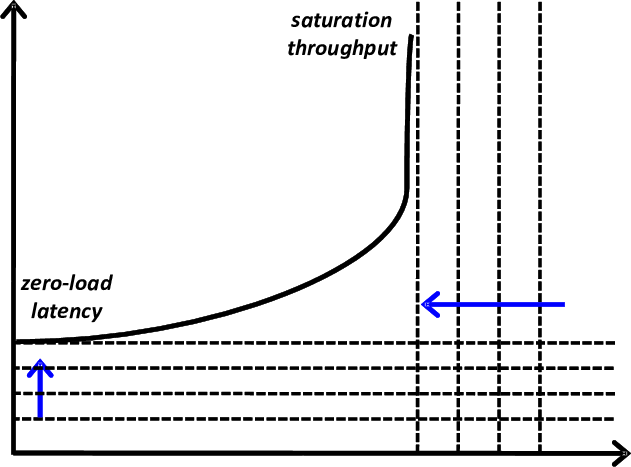
곡선 해석 및 성능 지표
| 구분 | 설명 | 기술적 의미 |
|---|---|---|
| Zero-Load Latency | 트래픽이 0 일 때의 지연시간 | 네트워크 기본 성능 (토폴로지, 라우팅 알고리즘 영향) |
| Saturation Throughput | 네트워크가 처리할 수 있는 최대 처리량 | 플로우 컨트롤 및 버퍼 관리 효율성 결정 |
| Latency Slope | 지연시간 증가 기울기 | 네트워크 혼잡도 및 리소스 경쟁 정도 반영 |
성능 영향 요소
토폴로지 (Topology)
- 예시: 메시 (Mesh), 토러스 (Torus) → Bisection Bandwidth가 처리량 상한 결정.
- 영향: 높은 대역폭 → 포화점 지연.
라우팅 알고리즘 (Routing)
- Minimal vs. Non-Minimal: 비최소 라우팅은 지연시간 증가 대신 포화 처리량 향상.
- Adaptive Routing: 트래픽 부하에 따라 경로 동적 조정 → 곡선 형태 최적화.
플로우 컨트롤 (Flow Control)
- Virtual Channel 사용: 버퍼 경쟁 감소 → 포화 처리량 40% 향상 가능.
- Credit-Based vs. On/Off: 신호 오버헤드 차이로 지연시간 변동.
처리량 제한 요소
처리량은 다양한 요소에 의해 제한될 수 있다:
- 하드웨어 제한: CPU, 메모리, 디스크 I/O 등
- 네트워크 제한: 대역폭, 패킷 손실, 혼잡 제어
- 소프트웨어 제한: 비효율적인 알고리즘, 동기화 오버헤드
지연시간 구성 요소
지연시간은 여러 구성 요소로 이루어져 있다:
- 전파 지연 (Propagation Delay): 데이터가 물리적 거리를 이동하는 데 걸리는 시간
- 전송 지연 (Transmission Delay): 데이터를 매체에 전송하는 데 걸리는 시간
- 처리 지연 (Processing Delay): 데이터를 처리하는 데 걸리는 시간
- 대기열 지연 (Queuing Delay): 처리를 기다리는 동안 발생하는 지연
지연시간과 처리량의 관계
구조 및 아키텍처
지연 시간 최적화 아키텍처
지연 시간을 최소화하기 위해, 클라이언트와 서버 간의 거리를 줄이고, 데이터 처리 경로를 최적화하는 구조를 채택한다.
요청 처리 경로를 최소화하고, 캐싱과 지역성을 활용하여 빠른 응답 시간을 제공한다. 예를 들어, CDN(Content Delivery Network) 을 활용하여 사용자와 가까운 위치에서 콘텐츠를 제공함으로써 지연 시간을 줄일 수 있다. 실시간 시스템, 온라인 게임, 고주파 거래 시스템 등에 적합하다.
주요 특징:
- 요청 경로 최소화 (홉 수 줄이기)
- 엣지 컴퓨팅 활용
- 캐싱 최적화
- 비동기 처리 대신 동기 처리 활용
- 지역성 (Locality) 최적화
처리량 최적화 아키텍처
처리량을 극대화하기 위해, 시스템은 병렬 처리, 배치 처리, 큐 시스템와 리소스 확장을 활용하여 높은 처리량을 제공한다. 예를 들어, 마이크로서비스 아키텍처를 도입하여 각 서비스가 독립적으로 확장 가능하게 설계함으로써 전체 시스템의 처리량을 향상시킬 수 있다. 이는 대용량 데이터 처리, 분석 시스템, 백업 시스템 등에 적합하다.
주요 특징:
- 병렬 처리 극대화
- 배치 처리 활용
- 큐 시스템 구현
- 비동기 처리 활용
- 수평적 확장성 설계
균형 잡힌 아키텍처
대부분의 실제 시스템은 지연시간과 처리량 사이의 균형을 맞추어야 한다. 이를 위해 다양한 기법을 조합하여 사용한다.
주요 특징:
- 마이크로서비스 아키텍처
- 캐싱과 큐 시스템의 조합
- 적응형 배치 처리
- 우선순위 기반 스케줄링
- 지능형 부하 분산
구성 요소
| 구성 요소 | 기능 및 역할 | 종류 | 작동 방식 | 지연시간 최적화 기여 | 처리량 최적화 기여 |
|---|---|---|---|---|---|
| 캐싱 시스템 | 자주 접근하는 데이터를 메모리에 저장하여 빠른 응답 제공 | 메모리 내 캐시, 분산 캐시 (Redis, Memcached), CDN, 브라우저 캐시 | 캐시 적중 시 원본 접근 없이 빠르게 데이터 제공 | 데이터 접근 속도를 메모리 수준으로 줄여 응답 시간 단축 | 원본 시스템의 부하 감소로 더 많은 요청을 처리 가능 |
| 로드 밸런서 | 요청을 여러 서버에 분산시켜 부하를 균등하게 처리 | L4, L7, 글로벌 로드 밸런서 | 라운드 로빈, 최소 연결, 최소 지연시간 등 알고리즘으로 분산 | 가장 응답 속도가 빠른 서버로 분산하여 응답 지연 최소화 | 서버 간 부하 분산으로 동시 요청 처리량 증가 |
| 메시지 큐 | 비동기 처리로 병렬 처리 및 시스템 독립성 확보 | Kafka, RabbitMQ, SQS, Pub/Sub | 생산자가 메시지를 큐에 넣고 소비자가 비동기적으로 처리 | 요청 즉시 처리하지 않고 큐에 저장하여 시스템 병목 완화 | 소비자가 독립적으로 처리하므로 고속의 비동기 처리 가능 |
| 데이터베이스 | 데이터 저장, 쿼리 처리 및 트랜잭션 관리 | RDBMS, NoSQL, 시계열 DB, 그래프 DB | 인덱싱, 샤딩, 복제 등으로 성능 향상 | 인덱싱으로 검색 속도 향상, 캐싱으로 반복 조회 시간 절감 | 샤딩/복제로 수평 확장하여 높은 처리량 확보 |
| 네트워크 구성 요소 | 패킷 전송, 라우팅, 트래픽 제어 및 보안 | 라우터, 스위치, 프록시, 방화벽, CDN | 패킷 포워딩, 큐잉, 우선순위 지정 등 네트워크 최적화 | CDN, QoS 로 요청을 사용자 가까운 위치에서 처리해 지연 최소화 | 대역폭 제어, 트래픽 분산으로 동시 요청 수용 능력 증가 |
장점과 단점
| 접근 방식 | 장점 | 단점 |
|---|---|---|
| 지연시간 우선 최적화 | - 사용자 경험 향상 - 실시간 상호작용 개선 - 빠른 응답성으로 사용자 만족도 증가 | - 자원 활용도 감소 가능 - 처리량 제한 가능 - 구현 및 유지보수 비용 증가 |
| 처리량 우선 최적화 | - 효율적인 자원 활용 - 높은 데이터 처리 용량 - 비용 효율적인 처리 | - 개별 요청의 지연시간 증가 - 실시간성 저하 - 복잡한 비동기 처리 로직 필요 |
| 균형 잡힌 접근법 | - 다양한 워크로드 지원 - 확장성 향상 - 사용자 경험과 효율성 모두 고려 | - 구현 복잡도 증가 - 더 많은 설계 노력 필요 - 다양한 기술 스택 필요 |
지연시간과 처리량 최적화의 장단점과 운영 기준.
| 측면 | 지연시간 최적화 장단점 | 처리량 최적화 장단점 | 운영 기준 |
|---|---|---|---|
| 인프라 비용 | - 장점: 일부 영역만 고사양 장비 필요 - 단점: 지리적 분산으로 인한 추가 비용 | - 장점: 규모의 경제로 비용 효율성 - 단점: 대규모 처리 인프라 필요 | - 트래픽 패턴 분석 ROI 기반 인프라 투자 - 클라우드 vs 온프레미스 결정 |
| 개발 복잡성 | - 장점: 동기식 처리로 간단한 디버깅 - 단점: 캐싱, 무효화 등 복잡한 로직 필요 | - 장점: 표준화된 배치 처리 패턴 - 단점: 비동기 처리의 복잡성, 재시도 로직 | - 개발자 경험 고려 - 적절한 추상화 레벨 설정 - 자동화된 테스트 중요 |
| 확장성 | - 장점: 수직적 확장으로 단순함 - 단점: 물리적 한계 존재 | - 장점: 수평적 확장으로 거의 무제한 - 단점: 분산 시스템 복잡성 | - 미래 성장 예측 - 점진적 확장 계획 - 확장성 병목 지속 모니터링 |
| 사용자 경험 | - 장점: 즉각적 반응으로 좋은 UX - 단점: 부하 증가 시 성능 저하 가능성 | - 장점: 안정적인 대량 데이터 처리 - 단점: 개별 요청 지연 가능성 | - 사용자 만족도 측정 - 업계 벤치마크 대비 성능 A/B 테스트를 통한 개선 |
| 유지보수 | - 장점: 간단한 아키텍처 가능 - 단점: 성능 튜닝의 지속적 필요성 | - 장점: 모듈화된 컴포넌트 - 단점: 분산 시스템 디버깅 어려움 | - 모니터링 및 알림 체계 - 성능 회귀 테스트 - 정기적인 성능 검토 |
실무 적용 예시
| 사례 | 적용 방식 | 설명 |
|---|---|---|
| 온라인 게임 | 지연 시간 최적화 | 실시간 반응이 중요하므로 지연 시간을 최소화하여 사용자 경험 향상 |
| 데이터 분석 시스템 | 처리량 최적화 | 대량의 데이터를 효율적으로 처리하기 위해 시스템의 처리량을 극대화 |
| 스트리밍 서비스 | 지연 시간 및 처리량 최적화 | 빠른 응답과 안정적인 데이터 전송을 위해 지연 시간과 처리량을 동시에 최적화 |
활용 사례
시나리오: 대규모 E- 커머스 플랫폼의 성능 최적화
상황: 대규모 온라인 쇼핑몰이 블랙프라이데이와 같은 특별 할인 기간 동안 트래픽이 평소의 10 배 이상 증가하는 문제에 직면했습니다. 사이트 로딩 시간이 길어지고, 결제 프로세스가 지연되며, 일부 사용자는 서비스를 이용할 수 없는 상황이 발생했습니다.
목표:
- 사이트 로딩 시간을 2 초 이내로 유지
- 장바구니 추가 및 결제 프로세스 응답 시간을 500ms 이내로 유지
- 초당 최소 5,000 건의 트랜잭션 처리 가능
- 99.99% 서비스 가용성 확보
E- 커머스 플랫폼 지연시간/처리량 최적화 다이어그램
| |
최적화 전략 (지연시간 vs. 처리량)
| 구분 | 지연시간 최적화 전략 | 처리량 최적화 전략 |
|---|---|---|
| 핵심 기술 | - CDN 엣지 캐싱 - 인메모리 데이터베이스 - Lazy Loading | - Auto Scaling - DB 샤딩 - 비동기 큐 |
| 주요 서비스 | CloudFront, Redis, DAX | ECS Fargate, Aurora Global, SQS |
| 최적화 대상 | 사용자 체감 성능 (FCP, TTI) | 시스템 처리 용량 (RPS, TPS) |
| 모니터링 지표 | - Time to First Byte (TTFB) - DOM Load | - CPU/Memory Utilization - Queue Depth |
| 트레이드오프 | 높은 인프라 비용 | 데이터 일관성 지연 가능성 |
| 적용 사례 | 제품 페이지 로딩, 검색 결과 | 주문 처리, 재고 관리, 배치 작업 |
계층별 최적화
프론트엔드 계층 (지연시간 <1s)
- 점진적 정적 재생성 (ISR): Next.js 15+ 의 On-demand ISR 로 실시간 콘텐츠 갱신
- WebAssembly 최적화: 이미지 리사이징을 WASM 으로 엣지 처리
- HTTP/3 + QUIC: 멀티플렉싱으로 연결 지연시간 40% 감소
API 계층 (지연시간 <300ms)
계층적 캐싱 전략:
graph LR A[User] --> B[Edge API Cache - 50ms] B --> C{Cache Hit?} C -->|Yes| D[Return Response] C -->|No| E[Region API Cache - 100ms] E --> F{Cache Hit?} F -->|Yes| G[Return Response] F -->|No| H[Origin Server - 300ms]GraphQL 지연 로딩:
@defer지시어 활용해 부분 응답 스트리밍
데이터 계층 (처리량 >10k TPS)
AI 기반 샤딩:
벡터화 쿼리 처리: PostgreSQL pgvector 확장으로 유사도 검색 가속화
배치 처리 계층
- 서버리스 스팟 인스턴스: AWS Lambda + EC2 Spot 혼합 배치로 비용 70% 절감
- 예측 확장: Prophet 모델 기반 트래픽 예측 → 리소스 사전 할당
핵심 설계 원칙
지연시간 민감도 계층화:
비용 - 성능 최적화 곡선:
장애 전파 차단:
Google, Meta 사례 기반 구조 선택 전략
Google 과 Meta(Facebook) 는 각자의 서비스 특성에 맞는 지연시간과 처리량 최적화 전략을 구현했다.
Google 의 접근법
Google 은 다양한 서비스에 따라 다른 최적화 전략을 적용한다:
- 검색 엔진: 낮은 지연시간을 위해 글로벌 분산 아키텍처와 인메모리 캐싱을 활용한다. Google 의 검색은 사용자 쿼리를 즉각 처리하기 위해 처리량보다 지연시간을 우선시한다.
- BigTable/Spanner: 분산 데이터베이스 시스템으로, 지연시간과 처리량의 균형을 맞추기 위해 설계되었다. Google 의 SRE(Site Reliability Engineering) 책에서는 BigTable 에 대해 " 지연 시간이 낮은 사용자는 시스템이 도착하는 각 요청을 즉시 처리할 수 있도록 큐가 (거의 항상) 비어 있기를 원하지만, 오프라인 분석에 관심이 있는 사용자는 처리량에 더 관심이 있습니다 " 라고 설명한다.
- Google 클라우드 네트워크: 프리미엄 티어에서는 자체 글로벌 백본 네트워크를 활용하여 지연시간을 최소화하고, 표준 티어에서는 인터넷을 통한 라우팅으로 비용 대비 처리량을 최적화한다.
Meta(Facebook) 의 접근법
Meta 는 소셜 네트워크 특성에 맞게 다음과 같은 최적화 전략을 사용한다:
- TAO(The Associations and Objects): Facebook’s 소셜 그래프를 저장하는 분산 데이터 저장소로, 읽기 중심 워크로드에 최적화되어 있다. 다중 레이어 캐싱으로 지연시간을 최소화한다.
- Proxygen: Facebook 의 HTTP 서버 프레임워크로, 처리량 최적화를 위한 멀티스레딩과 지연시간 최적화를 위한 비동기 I/O 를 모두 활용한다.
- TCP BBR(Bottleneck Bandwidth and Round-trip propagation time): Google 이 개발하고 Meta 도 채택한 TCP 혼잡 제어 알고리즘으로, 네트워크 지연시간과 처리량을 모두 개선한다.
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 고려사항 | 설명 |
|---|---|
| 사용자 경험 우선 | 사용자와 직접 상호작용하는 기능은 지연시간 최적화에, 백그라운드 처리는 처리량 최적화에 중점을 둡니다. |
| 측정 기반 접근 | 실제 측정을 통해 병목 현상을 식별하고, 최적화 전략을 수립합니다. 가정이 아닌 데이터에 기반한 의사결정이 중요합니다. |
| 점진적 개선 | 한 번에 모든 것을 최적화하려 하지 말고, 가장 큰 영향을 미치는 부분부터 점진적으로 개선합니다. |
| 캐싱 전략 | 캐싱은 지연시간을 크게 줄일 수 있지만, 캐시 무효화와 일관성 문제에 주의해야 합니다. |
| 비동기 처리 | 비동기 처리로 처리량을 높일 수 있지만, 복잡성이 증가하고 디버깅이 어려워질 수 있습니다. |
| 확장성 설계 | 초기부터 확장성을 고려한 설계로 나중에 대규모 재작업을 방지합니다. |
| 모니터링과 알림 | 지연시간과 처리량을 지속적으로 모니터링하고, 이상 징후 발생 시 즉시 알림을 받을 수 있는 시스템을 구축합니다. |
최적화하기 위한 고려사항 및 주의할 점
| 고려사항 | 지연시간 최적화 | 처리량 최적화 |
|---|---|---|
| 하드웨어 최적화 | - 더 빠른 CPU 와 메모리 SSD 스토리지 - 네트워크 하드웨어 업그레이드 | - 더 많은 코어와 스레드 - 대용량 메모리 - 빠른 대용량 스토리지 |
| 소프트웨어 최적화 | - 알고리즘 효율성 개선 I/O 최소화 - 동기화 병목 제거 | - 병렬 처리 최적화 - 배치 처리 효율화 - 리소스 활용 극대화 |
| 네트워크 최적화 | TCP 최적화 (BBR 같은 혼잡 제어) - 연결 재사용 - 지역성 최적화 | - 대역폭 확장 - 프로토콜 최적화 - 로드 밸런싱 |
| 데이터베이스 최적화 | - 인덱싱 최적화 - 쿼리 최적화 - 캐싱 적용 | - 파티셔닝/샤딩 - 벌크 작업 최적화 - 읽기/쓰기 분리 |
| 애플리케이션 설계 | - 비동기 I/O - 마이크로서비스 아키텍처 - 이벤트 기반 아키텍처 | - 워커 풀 최적화 - 작업 스케줄링 - 큐 기반 처리 |
주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 네트워킹 | TCP BBR | Google 의 TCP BBR(Bottleneck Bandwidth and RTT) 혼잡 제어 알고리즘이 지연시간과 처리량을 동시에 최적화하는 접근법으로 주목받고 있습니다. |
| 분산 시스템 | 서킷 브레이커 | 서킷 브레이커 패턴이 분산 시스템에서 장애 전파를 방지하고 지연시간 최소화와 처리량 유지에 기여하고 있습니다. |
| 컨테이너 기술 | Service Mesh | Istio, Linkerd 등의 서비스 메시가 마이크로서비스 간 통신 최적화와 지연시간 모니터링을 제공합니다. |
| 측정 방법론 | 테일 지연시간 | 평균 지연시간보다 P95, P99 등 테일 지연시간 (극단값) 에 초점을 맞춘 측정과 최적화가 중요해지고 있습니다. |
| AI/ML | 자율 최적화 | AI/ML 을 활용한 자율적 성능 최적화 시스템이 지연시간과 처리량의 동적 균형을 찾는 방향으로 발전하고 있습니다. |
| 모니터링 | 분산 추적 | OpenTelemetry 와 같은 분산 추적 시스템이 복잡한 시스템에서 지연시간 문제 원인 파악에 필수적인 도구로 자리 잡고 있습니다. |
최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 엣지 컴퓨팅 | 로컬 처리 | 사용자와 가까운 위치에서 데이터를 처리하여 지연시간을 크게 줄이는 엣지 컴퓨팅 기술이 확산되고 있습니다. 5G 와 결합하여 실시간 응용 프로그램에 혁신을 가져오고 있습니다. |
| 프로토콜 최적화 | QUIC 프로토콜 | Google 이 개발한 QUIC 프로토콜이 HTTP/3 의 기반으로 자리 잡아, 연결 설정 지연시간을 33% 줄이고 멀티플렉싱을 통한 처리량 개선에 기여하고 있습니다. |
| 하드웨어 가속 | 전용 가속기 | AI 추론, 네트워크 패킷 처리 등을 위한 전용 하드웨어 가속기가 지연시간을 줄이고 처리량을 높이는 방향으로 발전하고 있습니다. |
| 서버리스 컴퓨팅 | 자동 확장 | 서버리스 아키텍처가 자동 확장을 통해 변동하는 부하에 효율적으로 대응하여 처리량 최적화에 기여하고 있습니다. |
| 분산 데이터베이스 | 글로벌 분산 | CockroachDB, YugabyteDB 등 글로벌 분산 데이터베이스가 지연시간과 처리량의 균형을 목표로 발전하고 있습니다. |
| 메시지 브로커 | 스트리밍 플랫폼 | Kafka, Pulsar 등의 고성능 메시지 브로커가 실시간 데이터 스트리밍과 처리량 최적화를 위한 핵심 인프라로 자리 잡고 있습니다. |
앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 양자 컴퓨팅 | 양자 통신 | 양자 컴퓨팅과 양자 통신이 특정 영역에서 지연시간과 처리량의 한계를 극복할 잠재력을 가지고 있습니다. |
| 네트워크 혁신 | 6G 네트워크 | 개발 중인 6G 네트워크는 초저지연 (sub-millisecond), 초고속 (테라비트급) 통신으로 새로운 응용 프로그램 가능성을 열 것입니다. |
| 분산 시스템 | 엣지 - 클라우드 통합 | 엣지 컴퓨팅과 클라우드의 긴밀한 통합이 지연시간과 처리량의 최적화된 조합을 제공할 것입니다. |
| 메모리 기술 | 비휘발성 메모리 | 차세대 비휘발성 메모리 기술이 지연시간과 처리량의 새로운 균형점을 제시할 것입니다. |
| AI 인프라 | AI 전용 데이터센터 | AI 워크로드에 최적화된 데이터센터 아키텍처가 추론과 학습의 지연시간과 처리량을 획기적으로 개선할 것입니다. |
| 지속가능성 | 에너지 효율 최적화 | 지연시간과 처리량뿐만 아니라 에너지 효율성까지 고려한 다차원적 최적화가 중요해질 것입니다. |
| 처리량 | 멀티코어/다중 노드 기반 병렬 처리 | CPU, GPU, TPU 의 코어 수 증가와 분산 시스템 확장을 통해 초고처리량 처리 환경 보편화 |
추가로 학습해야할 내용
| 주제 | 카테고리 | 설명 |
|---|---|---|
| 큐잉 이론 | 이론 | 지연시간과 처리량의 수학적 모델링, Little 의 법칙, M/M/1 큐 등 큐잉 이론의 기초와 응용 |
| 네트워크 프로토콜 | 네트워킹 | TCP, UDP, QUIC 등 다양한 네트워크 프로토콜의 지연시간과 처리량 특성 이해 |
| 분산 시스템 설계 | 아키텍처 | CAP 이론, 데이터 복제, 샤딩 등 분산 시스템에서 지연시간과 처리량 최적화 기법 |
| 하드웨어 아키텍처 | 하드웨어 | CPU 캐시, NUMA 아키텍처, DMA 등 하드웨어 수준의 지연시간과 처리량 최적화 |
| 성능 측정 방법론 | 측정/분석 | 지연시간과 처리량 측정 도구, 통계적 분석 방법, 벤치마킹 기법 |
| 캐싱 전략 | 최적화 | 다양한 캐싱 전략, 캐시 일관성 프로토콜, 최적의 캐시 사이즈 결정 방법 |
| 로드 밸런싱 알고리즘 | 분산 컴퓨팅 | 라운드 로빈, 최소 연결, 해시 기반 등 다양한 로드 밸런싱 알고리즘의 장단점 |
| 데이터베이스 최적화 | 데이터 | 인덱싱, 쿼리 최적화, 트랜잭션 처리 등 데이터베이스 성능 향상 기법 |
| 실시간 시스템 | 특수 도메인 | 실시간 시스템의 요구사항과 지연시간 보장 메커니즘 |
| 클라우드 성능 최적화 | 클라우드 | 클라우드 환경에서의 지연시간과 처리량 최적화 전략, 자동 확장 정책 |
학습 주제 정리
| 카테고리 | 주제 | 설명 |
|---|---|---|
| System Performance | QoS (Quality of Service) | 시스템에서 서비스 품질 보장을 위한 다양한 지표와 정책을 학습 |
| Distributed Systems | 분산 큐 시스템 (Kafka, RabbitMQ 등) | 고처리량 시스템을 위한 메시지 기반 아키텍처 이해 |
| Networking | TCP/IP 지연 및 처리량 제어 | 전송 계층에서 성능을 제한하는 요소와 최적화 기법 학습 |
| Cloud Computing | Auto Scaling 및 Load Balancing | 클라우드 기반에서 처리량과 응답 속도를 동적으로 조절하는 구조 이해 |
| DevOps | Performance Monitoring Tools | Prometheus, Grafana, Datadog 등을 통한 실시간 모니터링과 튜닝 실습 |
용어 정리
| 용어 | 설명 |
|---|---|
| 지연시간 (Latency) | 데이터가 한 지점에서 다른 지점으로 이동하는 데 걸리는 시간. 일반적으로 밀리초 (ms) 나 마이크로초 (μs) 단위로 측정됨 |
| 처리량 (Throughput) | 단위 시간당 처리할 수 있는 작업량. 초당 비트 수 (bps), 초당 요청 수 (RPS) 등으로 측정됨 |
| 대역폭 (Bandwidth) | 통신 채널의 최대 이론적 처리 용량. 처리량의 상한선을 결정함 |
| 응답 시간 (Response Time) | 요청을 보내고 완전한 응답을 받을 때까지의 총 시간. 지연시간 + 처리 시간 + 대기 시간 |
| P95/P99 지연시간 | 모든 요청 중 95%/99% 의 요청이 이 시간 이내에 처리됨을 나타내는 백분위 지연시간 |
| 테일 지연시간 (Tail Latency) | 가장 느린 요청들 (일반적으로 상위 5% 또는 1%) 의 응답 시간 |
| 캐싱 (Caching) | 자주 접근하는 데이터를 빠르게 접근할 수 있는 위치에 저장하여 지연시간을 줄이는 기법 |
| 큐잉 지연 (Queuing Delay) | 처리를 기다리는 동안 요청이 큐에서 대기하는 시간 |
| 로드 밸런싱 (Load Balancing) | 여러 서버나 자원에 작업을 분산하여 처리량을 높이는 기법 |
| 병목 현상 (Bottleneck) | 시스템 성능을 제한하는 구성 요소나 프로세스 |
| CDN(Content Delivery Network) | 사용자와 가까운 위치에 콘텐츠를 캐싱하여 지연시간을 줄이는 분산 서버 네트워크 |
| 비동기 처리 (Asynchronous Processing) | 요청을 즉시 응답하지 않고 백그라운드에서 처리하여 처리량을 높이는 기법 |
| 샤딩 (Sharding) | 데이터베이스를 여러 파티션으로 분할하여 처리량을 높이는 기법 |
| 리틀의 법칙 (Little’s Law) | L = λW: 평균 시스템 내 항목 수 (L) 는 평균 도착률 (λ) 과 평균 대기 시간 (W) 의 곱과 같다는 원리 |
| TCP/IP | 인터넷의 기본 통신 프로토콜. 신뢰성과 순서 보장에 중점을 두어 지연시간과 처리량에 영향을 미침 |
| QUIC | Google 이 개발한 UDP 기반 전송 프로토콜. 연결 설정 시간을 줄이고 멀티플렉싱을 지원하여 지연시간과 처리량 개선 |
| 엣지 컴퓨팅 (Edge Computing) | 데이터 소스와 가까운 위치에서 처리하여 지연시간을 줄이는 분산 컴퓨팅 패러다임 |
| 모노레포 (Monorepo) | 여러 프로젝트를 하나의 저장소에서 관리하는 방식. 빌드 최적화와 의존성 관리에 영향을 미침 |
| 폴리레포 (Polyrepo) | 각 프로젝트를 별도의 저장소에서 관리하는 방식. 독립적인 개발과 배포에 유리함 |
| QKD | 양자 키 분배 보안 기술 |
| MEC | Mobile Edge Computing |
| QoS (Quality of Service) | 시스템이 일정 수준 이상의 서비스 품질을 보장하도록 관리하는 기술 |
| RPC (Remote Procedure Call) | 네트워크 상의 다른 서버에 있는 함수나 메서드를 호출하는 통신 기법 |
| SLA (Service Level Agreement) | 고객과 서비스 제공자 간의 서비스 품질, 성능 보장 등의 계약 |
참고 및 출처
Latency & Throughput 관련
- Latency and Throughput in System Design | GeeksforGeeks
- System Design: Latency vs Throughput - cs.fyi
- Latency, throughput, and availability: system design interview concepts - IGotAnOffer
- Latency and Throughput for Systems Design Interview - Java Challengers
- Throughput vs Latency - AWS 비교 문서
- Latency, Bandwidth, Throughput and Response Time | PerfMatrix
- Optimizing web servers for high throughput and low latency - Dropbox
- The Latency/Throughput Tradeoff - Dan Slimmon
모놀리포 Vs 폴리레포 (참고 추가)
최신 기술 동향 및 성능 최적화 사례
- Google Cloud Rapid Storage - InfoQ
- Meta RTC Optimization - Facebook Engineering
- Meta ServiceRouter at Scale - CACM
성능 인프라 관련 도구 및 문서
- Cloudflare CDN Documentation
- AWS Auto Scaling
- Prometheus Official Docs
- Kubernetes Horizontal Pod Autoscaler