Database per Service Pattern
“Database per Service Pattern"은 마이크로서비스 아키텍처에서 중요한 디자인 패턴 중 하나이다.
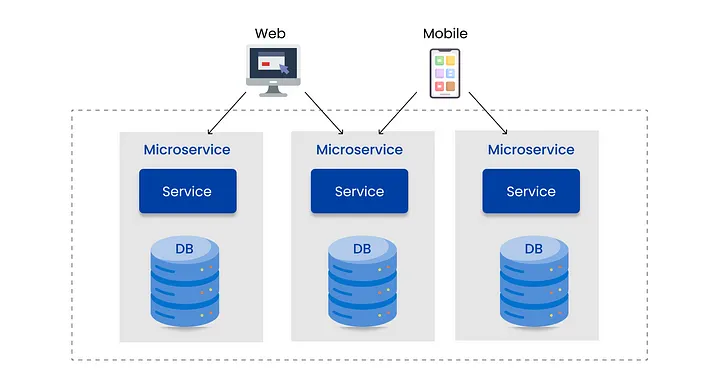
Database per Service Pattern은 각 마이크로서비스가 자체적인 독립된 데이터베이스를 가지는 구조를 말한다.
이는 서비스 간의 느슨한 결합을 촉진하고, 각 서비스의 자율성을 높이는 것을 목표로 한다.
주요 특징:
- 각 서비스는 자신만의 전용 데이터베이스를 가짐
- 서비스 간 데이터 접근은 API를 통해서만 가능
- 각 서비스는 자신의 요구사항에 가장 적합한 데이터베이스 기술을 선택할 수 있음
Database per Service Pattern은 마이크로서비스 아키텍처에서 서비스 간 독립성과 확장성을 높인다.
하지만 이를 효과적으로 구현하기 위해서는 신중한 설계와 다양한 기술적 도전을 해결해야 한다.
각 서비스의 특성과 전체 시스템의 요구사항을 고려하여 이 패턴의 적용 여부를 결정해야 하며, 필요에 따라 다른 패턴들과 조합하여 사용하는 것이 좋다.
구현 방법
서비스 경계 설계:
- 비즈니스 도메인을 분석하여 각 마이크로서비스의 책임 영역을 명확히 정의
- 서비스 간 상호작용을 위한 API 설계
데이터베이스 선택:
- 각 서비스의 특성에 맞는 데이터베이스 기술 선택 (예: SQL, NoSQL)
- 데이터 볼륨, 트랜잭션 요구사항, 쿼리 복잡성 등을 고려
데이터 소유권 및 스키마 설계:
- 각 서비스의 데이터 모델 설계
- 데이터 중복을 최소화하면서 서비스 독립성 유지
데이터 일관성 관리:
- 분산 트랜잭션 대신 보상 트랜잭션 또는 이벤트 기반 아키텍처 활용
- 최종 일관성(Eventual Consistency) 모델 적용
쿼리 및 데이터 동기화:
- API Composition 패턴이나 CQRS 패턴을 활용하여 여러 서비스에 걸친 쿼리 구현
- 필요한 경우 이벤트 기반 아키텍처를 통한 데이터 동기화
장점
서비스 독립성 향상:
- 각 서비스는 자체 데이터베이스를 가져 독립적으로 진화 가능
- 한 서비스의 데이터베이스 변경이 다른 서비스에 영향을 주지 않음
확장성 개선:
- 각 서비스와 데이터베이스를 독립적으로 스케일링 가능
- 서비스별 부하에 따른 최적화 용이
기술 다양성:
- 각 서비스에 최적화된 데이터베이스 기술 선택 가능
- 예: 텍스트 검색에는 Elasticsearch, 그래프 데이터에는 Neo4j 등
장애 격리:
- 한 서비스의 데이터베이스 문제가 전체 시스템에 미치는 영향 최소화
- 시스템 전반의 복원력 향상
단점
데이터 일관성 관리의 복잡성:
- 분산 트랜잭션 구현의 어려움
- 여러 서비스에 걸친 데이터 일관성 유지가 복잡해짐
쿼리 복잡성 증가:
- 여러 서비스의 데이터를 조인하는 쿼리 구현이 어려워짐
- API Composition이나 CQRS 패턴 적용 필요
운영 복잡성:
- 여러 데이터베이스 관리에 따른 운영 부담 증가
- 다양한 데이터베이스 기술에 대한 전문성 요구
데이터 중복:
- 서비스 간 데이터 중복이 발생할 수 있음
- 중복 데이터의 동기화 메커니즘 필요
사용 시 고려사항
서비스 경계 설정:
- 비즈니스 도메인을 정확히 이해하고 서비스 경계를 명확히 정의해야 함
- 과도한 세분화는 복잡성을 증가시킬 수 있음
데이터 일관성 전략:
- 강한 일관성이 필요한 경우와 최종 일관성으로 충분한 경우를 구분
- 이벤트 기반 아키텍처 등을 활용한 데이터 동기화 메커니즘 구현
쿼리 성능:
- 여러 서비스에 걸친 복잡한 쿼리의 성능 최적화 방안 고려
- 필요한 경우 데이터 복제나 캐싱 전략 수립
모니터링 및 관리:
- 분산된 데이터베이스들의 효과적인 모니터링 및 관리 방안 수립
- 장애 상황에 대한 대응 전략 마련