Bulkhead
아래는 “Bulkhead Pattern(벌크헤드 패턴)”에 대한 체계적이고 심층적인 조사, 분석, 정리입니다.
1. 태그 (Tag)
- Resilience-Pattern
- Fault-Tolerance
- Resource-Isolation
- Distributed-Systems
2. 분류 구조 적합성 분석
현재 분류 구조
분석 및 근거
Bulkhead Pattern은 시스템의 내결함성(Resilience)과 신뢰성을 높이기 위해, 자원(스레드, 메모리, 연결 등)을 논리적 또는 물리적으로 격리하여 장애 전파를 방지하는 설계 패턴입니다.
이 패턴은 “Architecture Patterns > Resilience Patterns”에 포함되어야 하며, “Software Engineering > Design and Architecture” 계층 아래에 위치하는 것이 적절합니다.
따라서, 현재 분류 구조는 주제의 특성과 실무적 중요성 모두를 반영하고 있습니다.
3. 요약(200자 내외)
Bulkhead Pattern은 시스템 자원(스레드, 메모리 등)을 논리적 또는 물리적으로 격리하여, 일부 서비스 장애가 전체 시스템에 전파되는 것을 방지하는 내결함성 설계 패턴입니다.
4. 개요(250자 내외)
Bulkhead Pattern은 시스템의 자원(스레드, 메모리, 연결 등)을 여러 개의 격리된 그룹으로 분리하여, 특정 서비스나 작업의 장애가 다른 서비스나 작업에 영향을 주지 않도록 방지하는 내결함성 및 신뢰성 향상 패턴입니다.
주로 분산 시스템, 마이크로서비스 환경에서 사용됩니다.
5. 핵심 개념
- 정의 및 목적
- Bulkhead Pattern은 시스템의 자원(스레드, 메모리, 연결 등)을 여러 개의 격리된 그룹으로 분리하여, 장애가 발생해도 전체 시스템에 전파되지 않도록 하는 패턴입니다.
- 목적은 장애 전파 방지, 자원 효율성, 신뢰성 및 내결함성 향상입니다.
- 실무 연관성
- 실무에서는 외부 API 호출, 데이터베이스 쿼리, 분산 시스템 간 통신 등 다양한 작업에 적용됩니다.
- 내결함성, 신뢰성, 서비스 품질 향상에 필수적인 요소로 작용합니다.
6. 세부 조사 내용
배경
- 분산 시스템의 복잡성 증가
- 여러 서비스가 상호작용하는 환경에서 장애가 연쇄적으로 전파될 위험이 높아졌습니다.
- 자원 경쟁 및 장애 전파
- 특정 서비스의 과부하나 장애가 전체 시스템의 자원을 고갈시키고, 장애를 전파할 수 있습니다.
목적 및 필요성
- 장애 전파 방지
- 장애가 연쇄적으로 전파되는 것을 방지하여 시스템 전체의 안정성을 높입니다.
- 자원 효율성
- 불필요한 자원 소모를 줄여 시스템의 효율성을 높입니다.
- 신뢰성 및 내결함성
- 시스템의 신뢰성과 내결함성을 높여 사용자 경험을 개선합니다.
주요 기능 및 역할
- 자원 격리
- 스레드, 메모리, 연결 등 자원을 여러 그룹으로 분리하여 각 그룹이 독립적으로 동작하도록 합니다.
- 장애 전파 방지
- 한 그룹의 장애가 다른 그룹에 영향을 주지 않도록 방지합니다.
- 자동화
- 자원 할당, 관리, 장애 감지 등이 자동으로 이루어집니다.
특징
- 격리(Isolation)
- 자원을 논리적 또는 물리적으로 격리하여 장애 전파를 방지합니다.
- 확장성(Scalability)
- 각 그룹이 독립적으로 확장될 수 있습니다.
- Low-risk(저위험)
- 장애가 전체 시스템에 미치는 영향을 최소화합니다.
핵심 원칙
- Isolation(격리)
- 자원을 격리하여 장애 전파를 방지합니다.
- Graceful Degradation(우아한 성능 저하)
- 장애 발생 시 핵심 기능은 유지하면서 일부 기능만 저하시키는 방식으로 동작합니다.
- Resource Management(자원 관리)
- 자원을 효율적으로 관리하여 시스템의 확장성과 안정성을 높입니다.
주요 원리 및 작동 원리
다이어그램 (Text)
| |
설명
클라이언트가 요청을 보내면, 각 요청은 별도의 Bulkhead Group(스레드 풀 등)으로 분리되어 처리됩니다.
한 그룹의 장애가 다른 그룹에 영향을 주지 않습니다.
구조 및 아키텍처
구성 요소
| 항목 | 기능 및 역할 |
|---|---|
| Client | 요청을 시작하고, 결과 또는 실패를 처리하는 주체 |
| Bulkhead Group | 스레드, 메모리, 연결 등 자원을 격리하여 관리하는 그룹 |
| Service | 실제로 요청을 처리하는 서비스(또는 인스턴스) |
필수 구성요소
- Client: 요청을 시작하고 결과를 처리
- Bulkhead Group: 자원을 격리하여 관리
- Service: 실제 작업 수행
선택 구성요소
- Fallback Handler: 장애 발생 시 대체 동작을 수행하는 핸들러
- Logging Module: 장애, 자원 고갈 등 이벤트 로그 기록
구조 다이어그램 (Text)
| |
7. 구현 기법
| 기법 | 정의 및 목적 | 예시(시스템 구성, 시나리오) |
|---|---|---|
| 스레드 풀 | 각 서비스별로 별도의 스레드 풀을 구성하여 자원을 격리 | 외부 API 호출 시 별도의 스레드 풀 사용 |
| 연결 풀 | 데이터베이스 연결 등도 별도의 풀로 분리하여 격리 | 데이터베이스 쿼리 시 별도의 연결 풀 사용 |
| 메모리 격리 | 메모리 할당도 그룹별로 분리하여 장애 전파 방지 | 메모리 집약적 작업 시 별도의 메모리 풀 사용 |
| Polly 라이브러리 | .NET 환경에서 Bulkhead를 쉽게 구현할 수 있는 라이브러리 | Polly의 AddBulkhead 사용 |
8. 장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 장애 전파 방지 | 장애가 연쇄적으로 전파되는 것을 방지하여 시스템 전체의 안정성 향상 |
| 자원 효율성 | 불필요한 자원 소모를 줄여 시스템의 효율성 향상 | |
| 신뢰성 및 내결함성 | 시스템의 신뢰성과 내결함성을 높여 사용자 경험 개선 | |
| 확장성 | 각 그룹이 독립적으로 확장될 수 있어 시스템의 확장성 향상 |
9. 단점과 문제점 그리고 해결방안
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 복잡성 증가 | 자원 격리로 인해 시스템 구성이 복잡해질 수 있음 | 표준화된 라이브러리(예: Polly) 사용 |
| 자원 낭비 가능 | 각 그룹별로 자원을 할당하므로 전체 자원 사용량이 늘어날 수 있음 | 동적 자원 할당 및 관리 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 자원 할당 부족 | 그룹별 자원 할당이 부족 | 서비스 품질 저하 | 모니터링, 로그 | 동적 자원 할당 | 동적 자원 할당 알고리즘 |
| 장애 탐지 지연 | 장애 탐지가 늦을 경우 | 장애 전파 가능성 | 모니터링, 로그 | 실시간 모니터링 | 자동 장애 감지 및 복구 |
10. 도전 과제
| 과제 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|
| 동적 자원 할당 | 시스템 환경 변화 | 자원 낭비 또는 부족 | 모니터링, 로그 | 동적 자원 할당 | 머신러닝, 통계 기반 적용 |
| 장애 탐지 및 복구 | 장애 유형 다양 | 장애 전파 가능성 | 실시간 모니터링 | 자동 장애 감지 및 복구 | 자동화된 복구 메커니즘 |
11. 분류 기준에 따른 종류 및 유형
| 기준 | 유형 | 설명 |
|---|---|---|
| 적용 대상 | 스레드 | 스레드 풀을 그룹별로 분리 |
| 연결 | 데이터베이스 연결 등도 별도의 풀로 분리 | |
| 메모리 | 메모리 할당도 그룹별로 분리 | |
| 구현 방식 | 논리적 격리 | 논리적으로 자원을 그룹화하여 격리 |
| 물리적 격리 | 물리적으로 자원을 분리(예: 별도의 서버, 컨테이너 등) |
12. 실무 사용 예시
| 사용 예시 | 목적 | 효과 |
|---|---|---|
| 외부 API 호출 | 장애 전파 방지 | 서비스 신뢰성 향상 |
| 데이터베이스 쿼리 | 자원 효율성 | 데이터 가용성 향상 |
| 파일 I/O | 장애 전파 방지 | 파일 접근성 향상 |
13. 활용 사례
사례: 온라인 쇼핑몰 결제 서비스
- 시스템 구성
- 결제 서비스 → 외부 결제 게이트웨이 호출, 재고 서비스 → 데이터베이스 쿼리
- Workflow
- 결제 요청 발생
- 결제 서비스는 별도의 스레드 풀(Bulkhead Group A)에서 외부 결제 게이트웨이 호출
- 재고 서비스는 별도의 스레드 풀(Bulkhead Group B)에서 데이터베이스 쿼리
- 한 그룹의 장애가 다른 그룹에 영향을 주지 않음
- Bulkhead Pattern의 역할
- 결제 게이트웨이 장애 시 결제 서비스만 영향을 받고, 재고 서비스는 정상 동작
- 결제 서비스의 신뢰성 및 사용자 경험 향상
- 유무에 따른 차이
- Bulkhead Pattern 미적용 시: 결제 서비스 장애가 재고 서비스까지 전파되어 전체 시스템 장애 가능
- Bulkhead Pattern 적용 시: 장애 전파 방지 및 시스템 신뢰성 향상
14. 구현 예시
| |
실제 서비스에서는 스레드 풀, 연결 풀 등으로 구현하며, 위 예시는 개념적 예시입니다.
15. 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 자원 할당 기준 | 환경, 서비스 중요도에 맞는 자원 할당 기준 설정 | 모니터링, 튜닝 |
| 장애 감지 및 복구 | 실시간 모니터링 및 자동 복구 메커니즘 구현 | 자동화된 복구 메커니즘 |
| 로깅 및 모니터링 | 장애, 자원 고갈 등 이벤트 로그, 메트릭 수집 | 로그, 메트릭 수집 |
16. 최적화하기 위한 고려사항 및 주의할 점
| 항목 | 설명 | 권장사항 |
|---|---|---|
| 동적 자원 할당 | 시스템 상태, 서비스 부하에 따라 자원 할당 자동 조정 | 동적 자원 할당 알고리즘 |
| 자원 낭비 최소화 | 불필요한 자원 할당을 최소화하여 효율성 극대화 | 자원 사용량 모니터링 |
| 장애 탐지 및 복구 | 실시간 장애 탐지 및 빠른 복구로 서비스 품질 유지 | 자동화된 복구 메커니즘 |
17. 주제와 관련하여 주목할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 내결함성 | Resilience | Bulkhead Pattern | 장애 전파 방지 및 신뢰성 향상 |
| 분산 시스템 | Microservices | Fault Tolerance | 서비스 간 통신 시 장애 대응 및 회복력 강화 |
| 자원 관리 | Resource Isolation | 스레드/연결 풀 | 자원을 격리하여 장애 전파 방지 |
| 실무 적용 | 실무 예시 | 결제 서비스 | 외부 API 호출 시 Bulkhead 적용으로 장애 전파 방지 |
18. 반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 내결함성 | Resilience Pattern | Circuit Breaker | Bulkhead와 함께 사용되는 내결함성 패턴 |
| 분산 시스템 | Microservices | Timeout Pattern | Bulkhead와 함께 사용되는 타임아웃 패턴 |
| 자원 관리 | Resource Management | 스레드/연결 풀 | 자원을 효율적으로 관리하는 방법 |
| 실무 적용 | 실무 예시 | Fallback Pattern | Bulkhead 후에도 실패 시 대체 동작 구현 방법 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 내결함성 | Resilience | 시스템이 장애 상황에서도 정상적으로 동작하는 능력 |
| 분산 시스템 | Microservices | 여러 서비스가 네트워크를 통해 상호작용하는 시스템 구조 |
| 자원 격리 | Resource Isolation | 자원(스레드, 메모리, 연결 등)을 논리적 또는 물리적으로 격리 |
| 실무 적용 | Bulkhead | 장애 전파 방지를 위한 자원 격리 패턴 |
참고 및 출처
- Bulkhead Pattern (Microsoft Docs)
- Bulkhead Pattern (Martin Fowler)
- Bulkhead Pattern (Patterns for Resilient Architecture)
- Bulkhead Pattern in Microservices (dev.to)
- Polly Bulkhead Documentation
아래는 Bulkhead Pattern에 대한 1–5단계 정리입니다. 이어서 자세한 항목들을 순차적으로 작성 가능합니다.
1. 태그 (Tags)
Bulkhead-Pattern Resilience-Patterns Fault-Isolation Resource-Partitioning
2. 분류 구조 적절성 검토
“Bulkhead Pattern”은 Software Engineering > Design and Architecture > Architecture Patterns > Resilience Patterns 아래에 적절한 패턴입니다.
- 근거: 마이크로서비스나 분산 시스템에서 하나의 구성 요소 실패가 전체 서비스에 전파되는 것을 방지하기 위해, 자원(스레드풀, 커넥션 등)을 격리해 장애 범위를 축소하는 핵심 탄력성 전략입니다 (geeksforgeeks.org).
3. 요약 (200자 내외)
Bulkhead Pattern은 시스템을 격리된 자원 풀(스레드풀, 커넥션 등)으로 나누어, 하나의 구성 요소가 과부하 또는 오류가 발생해도 나머지 기능은 정상 동작하도록 설계하는 탄력성 패턴입니다. 이를 통해 장애 확산을 방지하고 높은 가용성과 안정성을 유지할 수 있습니다 .
4. 개요 (250자 내외)
Bulkhead Pattern은 선박의 격벽(bulkhead)에서 영감을 받아 시스템 내 각 기능 또는 서비스에 독립된 자원(pool)으로 홀을 만들고, 특정 영역의 과부하나 오류가 다른 영역에 영향을 미치지 않도록 설계하는 패턴입니다. 이는 스레드풀, 커넥션 풀, 컨테이너, 큐 등 여러 레벨에서 적용되며, 장애 범위 축소와 자원 통제, 안정적인 사용자 경험 확보를 위해 마이크로서비스 구조에서 널리 사용됩니다 (numberanalytics.com).
5. 핵심 개념 (Core Concepts)
- 격리된 자원 풀(Isolated Resource Pool): 스레드, 커넥션, 큐 등을 기능 단위로 분리하여 풀 구성
- Fault Containment: 장애 발생 시 영향을 해당 풀에만 국한하여 서비스 확산 방지 (geeksforgeeks.org)
- 자원 제한(Resource Quotas): 각 격벽의 자원 사용 상한 설정으로 리소스 고갈 방지
- 컴포넌트 기반 분리(Component Isolation): 마이크로서비스, 데이터베이스, 큐 등 서로 다른 자원 단위로 나누어 설계 (numberanalytics.com, codeopinion.com)
- 모니터링 기반 관리: 각 풀의 사용 현황, 실패율 등을 모니터링해 적절한 규모 및 격벽 수 설정
5.1 실무 연관성
- Thread Pool Bulkhead: Java/Spring, .NET Polly 등에서 thread/semaphore 기반 구현
- Connection Pool Bulkhead: DB별 전용 커넥션 풀로 무관한 작업 보호
- Service Mesh Bulkhead: Istio, AWS App Mesh 등에서 인프라 레벨 자원 격리 (numberanalytics.com, aws.amazon.com)
- Queue Bulkhead: 우선순위별 큐 분리 → 작업 욕구 분리 및 안정성 강화 (learn.microsoft.com)
다음 단계—배경·목적·특징, 작동 원리 다이어그램, 구조 및 구성요소, 구현 기법, 장단점·해결 방안, 도전 과제—중 어떤 항목부터 상세하게 이어서 작성할까요? 원하시는 순서 말씀해 주세요!
이어서 Bulkhead Pattern의 주요 항목들을 심층적으로 정리했습니다.
6. 배경·목적·특징
배경: 마이크로서비스, 공유자원 환경에서 특정 서비스의 과부하나 장애가 전체 시스템 장애로 확산(cascading failure)되는 경향이 있음 (learn.microsoft.com)
목적:
- 서비스 간 장애 전이 방지
- 시스템 가용성 및 자원 격리 강화
- 핵심 기능이 일부 장애에도 계속 동작하도록 보장
특징:
- 자원(스레드/커넥션/큐) 분리 및 제한
- Pool 단위 격리 설계
- 구성 복잡도 증가하나 장애 격리를 통한 안정성 보장
7. 작동 원리 (동작 다이어그램)
flowchart TB
A[Service Entry Point] --> B{Select Bulkhead}
B --> C1[Bulkhead-Pool-A]
B --> C2[Bulkhead-Pool-B]
C1 --> D1[Process via pool A resources]
C2 --> D2[Process via pool B resources]
D1 -->|Overflow or Timeout| E1[Reject/Queue or Fallback]
D2 -->|Overflow or Timeout| E2[Reject/Queue or Fallback]
각 Bulkhead Pool은 최대 동시 요청 수를 제한하고, 풀 포화 시 요청을 차단하거나 폴백/대기 처리합니다.
8. 구조 및 구성요소
| 구성 요소 | 유형 | 역할 |
|---|---|---|
| Bulkhead Pool | 필수 | 스레드, 커넥션 등 자원 풀로 기능마다 분리 |
| Semaphore/Queue | 필수 | 동시성 제한, 대기 처리 |
| Fallback Handler | 선택 | Pool 포화 시 안전 응답 제공 |
| Metrics Collector | 선택 | Pool 상태, 사용률 관찰 |
| Admin/Monitor UI | 선택 | Pool 상태 조정 및 모니터링 |
9. 구현 기법
Resilience4j Thread-Semaphore Bulkhead (Java):
@Bulkhead로 메서드에 적용 (badia-kharroubi.gitbooks.io, splunk.com, medium.com)
Polly Bulkhead (.NET):
1BulkheadPolicy policy = Policy.BulkheadAsync(10, 2);Service Mesh (AWS App Mesh, Istio): 라우팅 규칙으로 트래픽 분리, 컨테이너별 자원 제한으로 구성 (aws.amazon.com)
Queue 기반 Bulkhead: 우선순위 또는 기능별로 큐 분리 → 해당 큐 consumer pool에게 작업 할당
10. 장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 장애 확산 방지 | 특정 기능 장애 시 시스템의 나머지 부분은 영향 받지 않음 |
| 자원 고갈 방지 | pool 포화 시 초과 요청 차단 | |
| 서비스 가용성 유지 | 일부 Pool 장애에도 핵심 기능 지속 | |
| 성능 최적화 가능 | 기능별 자원 크기 조절 가능 |
11. 단점·문제점 및 해결방안
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 구성 및 운영 복잡 | 많은 분리 Pool 관리 필요 | 자동화 도구 및 글로벌 설정 |
| 리소스 낭비 | 풀 미사용 시 자원 유휴 상태 | 동적 풀 크기 조정 | |
| 오버 프로비저닝 | 예측 실패 시 불필요한 자원 차지 | 실사용 기반 조정 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지/진단 | 예방 | 해결 기법 |
|---|---|---|---|---|---|---|
| 문제점 | Pool 경합 | 동시 요청 집중 | 일부 기능 차단 | Metrics 이상 탐지 | 동적 pool 재조정 | 오토스케일링, rate limiting |
| 시간 지연 발생 | Wait 시간 긴 대기 | 응답 지연 | Response time 모니터링 | timeout 설정 | fallback 로직 구성 |
12. 도전 과제
- Pool 크기 동적 조정: 트래픽 패턴 변화에 따라 실시간 조정 필요
- 분산 환경 동기화: 여러 인스턴스 Pool 설정 일관성 확보
- 관측성과 알람: Pool 사용량, 포화 이벤트 모니터링 경보 체계
더 상세한 항목들—실무 예시, 활용 사례와 워크플로우, 코드 구현 (Python/JS), 최적화 고려사항, 용어 정리 및 참고/출처—작성 가능합니다. 어떤 항목부터 더 진행할까요?
이어서 Bulkhead Pattern의 나머지 주요 항목들—실무 예시, 활용 사례 워크플로우, 코드 구현(Python/JS), 최적화 고려사항, 용어 정리 및 참고까지 정리했습니다.
13. 실무 사용 예시
| 주체 | 목적 | 구현 방식 | 효과 |
|---|---|---|---|
| Spring Boot + Resilience4j | 외부 프로모션/결제 지연 격리 | @Bulkhead (Semaphore/ThreadPool) | 특정 요청이 포화시에도 다른 요청 정상 처리 (medium.com, resilience4j.readme.io, blog.nashtechglobal.com) |
| .NET Polly | 내부 큐/알림 작업 격리 | Policy.BulkheadAsync(...) | 큐 과부하 시도 중 격리 및 안정 |
| Istio/AWS App Mesh | 인프라 레벨 API 호출 자원 분리 | VirtualService 리소스 별 할당 | 장애 서비스 격리 및 구성 유연성 |
| Web 애플리케이션 (GeeksforGeeks 예시) | UI/배치 작업 분리 | HTTP 요청과 백그라운드 큐 분리 | UI 응답 지연 없이 독립 처리 |
14. 활용 사례 워크플로우
A. 프로모션 vs 주문 기능 분리
sequenceDiagram
participant UI
participant API Gateway
participant PH as Payment Bulkhead
participant PR as Promotion Bulkhead
participant OrderService
UI->>API Gateway: Place order
API Gateway->>PR: checkPromotion() (Bulkhead A)
alt PR Pool Busy
PR-->>API Gateway: fallbackPromotion()
else
PR-->>API Gateway: promo OK
end
API Gateway->>PH: processPayment() (Bulkhead B)
alt PH Pool Busy
PH-->>API Gateway: paymentDeferred()
else
PH-->>API Gateway: payment OK
end
API Gateway->>OrderService: finalizeOrder()
- 🎯 기능 분리로 프로모션 지연 시 주문은 지속 가능
15. 코드 구현 예시
Python (requests + Semaphore)
JavaScript (Node.js + async-sema)
| |
16. 최적화 고려사항 및 권장사항
| 항목 | 고려 사항 | 권장 해법 및 권장사항 |
|---|---|---|
| Pool 사이즈 설정 | 트래픽 기반 동시성 요구치 파악 어려움 | 모니터링 기반 자동 조정 |
| Wait/Queue 규칙 | 과도한 대기 → 응답 지연으로 이어짐 | timeout 설정 및 큐 용량 조정 |
| 분산 동기화 | 인스턴스 간 체계적 Pool 일관성 유지 필요 | 중앙 구성 관리 및 공유 registry |
| 이벤트 모니터링 | Pool 포화 이벤트용 알람 필요 | BulkheadFull 이벤트에 alert 설정 |
| 패턴 조합 | Retry/Fallback과 조합 시 효과 상호 연관성 있음 | Bulkhead→Circuit Breaker→Retry 순서 구성 |
17. 용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| Resilience | Bulkhead | 자원 격리를 위한 격벽 패턴 |
| Resilience | SemaphoreBulkhead | 세마포어 기반 동시성 제한 bulkhead |
| Resilience | ThreadPoolBulkhead | 스레드풀 + 큐 기반 bulkhead |
| Error Handling | BulkheadFullException | Pool이 포화됐을 때 발생하는 예외 |
| Monitoring | Bulkhead Metrics | 사용률, 거부 횟수, 대기시간 등을 지표화 |
18. 참고 및 출처
- Medium: Bulkhead pattern in Microservices: Spring Boot example (medium.com, blog.nashtechglobal.com)
- Resilience4j 공식 문서: Bulkhead(Semaphore/ThreadPool) (resilience4j.readme.io)
- Microsoft Azure Docs: Bulkhead Pattern 설명 (learn.microsoft.com)
- DZone: Resilient Microservice Design – Bulkhead Pattern (dzone.com)
- GeeksforGeeks: Bulkhead Implementation 예시 (geeksforgeeks.org)
- Reflectoring: Implementing Bulkhead with Resilience4j (reflectoring.io)
🎯 다음에 처리할 항목:
- ✅ 실시간 자동 조정 로직
- ✅ Dashboard/모니터링 설계
- ✅ 언어별 고급 예시 (Go, Java 등)
- ✅ Bulkhead + Circuit Breaker/Retry 조합 사례
필요하시면 말씀만 주세요!
다음은 Bulkhead Pattern의 남은 항목들을 심화 정리한 내용입니다.
🔧 18. 실시간 자동 조정 로직 (Adaptive Bulkhead)
Adaptive Bulkhead: Resilience4j에서 작성 중인 기능으로, TCP congestion control처럼 AIMD(additive increase/multiplicative decrease) 알고리즘을 기반으로 동적으로 동시성 제한을 조정합니다 (stackoverflow.com).
사용 전략:
- 초기 동시성(pool size)을 낮게 잡고, 정상 구간에서 서서히 확장.
- 풀 경합 시에만 감소시켜 안정 상태 유지.
효과: 트래픽 패턴 변화에 따라 효과적 자원 자동 조절 가능.
📊 19. 대시보드 & 모니터링 설계
추천 지표(Metrics):
- Pool 사용률(concurrency usage)
- Queue reject/timeout 횟수
- 평균/95% 응답 대기 시간
- BulkheadFull 이벤트 수
대시보드 구성 요소:
- 시간 기반 Pool 사용률 시계열
- 이벤트 알림(예: Pool 포화 시)
- Adaptive 동적 tuning 상태 표시
- SLA 대비 성능 수치 시각화
도구 예시: Prometheus + Grafana, ELK, New Relic, Azure Monitor
🔄 20. Bulkhead + Circuit Breaker/Retry 조합 활용
| 순서 | 패턴 | 역할 |
|---|---|---|
| 1 | Bulkhead | 자원 격리 (동시성 제한) |
| 2 | Circuit Breaker | 장애 확산 방지 (실패 시 상태 관리) |
| 3 | Retry | 일시적 오류 자동 복구 |
| 4 | Fallback | 최종 대체 로직 제공 |
설명: Bulkhead로 리소스 과부하를 방지하고, CB가 장애 시도를 차단→Retry 처리하고, 마지막으로 Fallback 제공하는 구조로 안정성 확보 (learn.microsoft.com).
⚙️ 21. 언어별 고급 코드 예시
Java (Resilience4j + AdaptiveBulkhead 화이트보드 스타일)
Go (Semaphore 기반 Bulkhead)
| |
🎯 22. 용어 정리 (Glossary)
| 카테고리 | 용어 | 설명 |
|---|---|---|
| Resilience | Adaptive Bulkhead | AIMD 기반 동시성 풀 조정 메커니즘 |
| Resilience | BulkheadFull 이벤트 | Pool 포화 발생 시 이벤트 |
| Monitoring | Pool Usage | 동시 실행 중인 요청 수 |
| Monitoring | Wait Duration | 요청이 대기하는 최대 시간 |
| Automation | AIMD (Additive Increase/ Mult Decrease) | 동시성 증가/감소에 사용되는 알고리즘 |
📚 23. 참고 및 출처
- GeeksforGeeks: Circuit Breaker + Bulkhead 소개 (stackoverflow.com, geeksforgeeks.org)
- Resilience4j 이슈: AdaptiveBulkhead 소개 (github.com)
- Azure 아키텍처 센터: Bulkhead + 다른 패턴 조합 가이드 (blog.stackademic.com)
- Stackademic 블로그: Microservices Bulkhead 설명 (blog.stackademic.com)
- Reflectoring: Resilience4j Bulkhead 구현 (reflectoring.io)
- Number Analytics: Bulkhead 종합 가이드 (numberanalytics.com)
이로써 Bulkhead Pattern의 핵심 구성부터 자동 튜닝, 운영 모니터링, 조합 적용, 언어별 고급 구현까지 전반적인 내용을 완성했습니다. ✅ 추가로 요청하실 주제가 있다면 바로 이어서 도와드릴게요!
안녕하세요! Bulkhead Pattern에 대한 상세한 조사와 분석을 시작하겠습니다. 먼저 최신 정보를 수집하여 체계적으로 정리해드리겠습니다.
Bulkhead Pattern 조사 및 분석 보고서
1. 태그
Bulkhead-PatternFault-ToleranceResilience-ArchitectureResource-Isolation
2. 분류 구조 검토
현재 분류: Computer Science and Engineering > Software Engineering > Design and Architecture > Architecture Patterns > Resilience Patterns
검토 결과: 적절한 분류입니다.
근거:
- Bulkhead Pattern은 소프트웨어 아키텍처 설계 패턴의 일종입니다
- 시스템의 복원력(Resilience)과 내결함성(Fault Tolerance)을 향상시키는 목적으로 사용됩니다
- 마이크로서비스 아키텍처와 분산 시스템에서 중요한 패턴으로 분류됩니다
- 회로 차단기(Circuit Breaker), 재시도(Retry) 패턴과 함께 복원력 패턴 범주에 속합니다
3. 주제 요약 설명 (200자 내외)
Bulkhead Pattern은 선박의 격벽에서 영감을 얻은 소프트웨어 아키텍처 패턴으로, 시스템의 구성 요소나 리소스를 격리된 구획으로 분할하여 한 부분의 장애가 전체 시스템에 전파되는 것을 방지합니다. 이를 통해 시스템의 복원력과 내결함성을 향상시킵니다.
4. 개요 (250자 내외)
Bulkhead Pattern은 분산 시스템과 마이크로서비스 아키텍처에서 장애 격리를 위해 사용되는 중요한 설계 패턴입니다. 스레드 풀, 프로세스, 네트워크 연결 등의 리소스를 독립적인 구획으로 분리하여 하나의 구성 요소 장애가 다른 구성 요소에 영향을 미치지 않도록 합니다. 세마포어 기반과 스레드 풀 기반의 구현 방식을 제공하며, 시스템의 가용성과 성능을 보장합니다.
5. 핵심 개념
5.1 기본 개념
**Bulkhead Pattern (벌크헤드 패턴)**은 선박의 격벽(Bulkhead)에서 유래된 소프트웨어 아키텍처 패턴입니다. 선박에서 격벽이 물의 침입을 특정 구획에 한정시켜 전체 선박의 침몰을 방지하는 것처럼, 소프트웨어에서도 리소스를 격리된 구획으로 분할하여 장애의 전파를 차단합니다.
5.2 이론적 기반
격리 원칙 (Isolation Principle)
- 시스템 구성 요소를 독립적인 구획으로 분리
- 각 구획은 자체 리소스 풀을 보유
- 구획 간 상호 의존성 최소화
장애 봉쇄 (Fault Containment)
- 장애가 발생한 구획에 오류를 국한
- 연쇄 장애(Cascading Failure) 방지
- 부분적 기능 유지를 통한 시스템 가용성 확보
5.3 실무 구현 측면
리소스 관리 연관성
- 스레드 풀 격리: 서로 다른 서비스별로 독립된 스레드 풀 할당
- 연결 풀 분리: 데이터베이스 연결, HTTP 연결 등을 서비스별로 분리
- 메모리 할당: 각 구획에 전용 메모리 영역 할당
- 네트워크 대역폭: 서비스별 네트워크 리소스 제한
동시성 제어 연관성
- 세마포어 기반 제어: 동시 실행 요청 수 제한
- 큐 용량 관리: 대기 요청의 최대 수 설정
- 타임아웃 설정: 장시간 대기 방지를 위한 시간 제한
6. 배경
6.1 등장 배경
분산 시스템과 마이크로서비스 아키텍처의 확산과 함께 시스템 복잡성이 증가하면서, 단일 장애점(Single Point of Failure)으로 인한 전체 시스템 다운 문제가 빈번하게 발생했습니다. 특히 하나의 서비스나 구성 요소의 성능 저하나 장애가 다른 건전한 서비스에까지 영향을 미치는 연쇄 장애 현상이 주요 문제로 대두되었습니다.
6.2 기술적 배경
리소스 경합 문제
- 여러 서비스가 동일한 스레드 풀을 공유할 때 발생하는 리소스 고갈
- 느린 응답을 보이는 서비스가 전체 스레드 풀을 점유하는 현상
- 메모리, CPU, 네트워크 대역폭 등의 시스템 리소스 경합
마이크로서비스 특성
- 서비스 간 강한 결합도로 인한 장애 전파
- 네트워크 호출의 불안정성
- 서비스 간 의존성 복잡성 증가
7. 목적 및 필요성
7.1 주요 목적
장애 격리 (Fault Isolation)
- 특정 구성 요소의 장애를 해당 구획에 국한
- 전체 시스템의 가용성 유지
- 장애 영향 범위 최소화
리소스 보호 (Resource Protection)
- 중요 서비스의 리소스 보장
- 비정상적인 리소스 소비 방지
- 시스템 안정성 확보
성능 최적화 (Performance Optimization)
- 서비스별 독립적인 확장성 제공
- 우선순위가 높은 서비스의 성능 보장
- 전체적인 응답 시간 개선
7.2 필요성
분산 시스템의 복잡성
- 수많은 네트워크 호출과 서비스 간 의존성
- 예측하기 어려운 장애 시나리오
- 부분적 장애에 대한 대응 필요성
비즈니스 연속성
- 24/7 서비스 가용성 요구
- 부분적 기능이라도 지속적인 서비스 제공 필요
- 장애 복구 시간 최소화
8. 주요 기능 및 역할
8.1 핵심 기능
동시성 제어 (Concurrency Control)
- 각 구획별 최대 동시 실행 요청 수 제한
- 대기 시간 설정을 통한 무한 대기 방지
- 공정한 리소스 배분
장애 감지 및 대응 (Fault Detection and Response)
- 구획별 상태 모니터링
- 장애 발생 시 해당 구획 격리
- 폴백(Fallback) 메커니즘 제공
리소스 할당 및 관리 (Resource Allocation and Management)
- 구획별 전용 리소스 풀 할당
- 동적 리소스 조정
- 리소스 사용량 모니터링
8.2 시스템에서의 역할
안전망 역할 (Safety Net)
- 예상치 못한 트래픽 급증 대응
- 서비스 간 상호 영향 차단
- 시스템 전체 안정성 보장
성능 조절기 역할 (Performance Regulator)
- 각 서비스별 성능 특성에 맞는 리소스 할당
- 중요도에 따른 우선순위 관리
- 전체 시스템 처리량 최적화
9. 특징
9.1 기본 특징
격리성 (Isolation)
- 물리적 또는 논리적 리소스 분리
- 구획 간 독립적 운영
- 장애 전파 차단
투명성 (Transparency)
- 애플리케이션 로직에 최소한의 영향
- 기존 코드 변경 최소화
- 런타임 동작 투명성
설정 가능성 (Configurability)
- 구획별 리소스 할당 조정 가능
- 동적 설정 변경 지원
- 모니터링 메트릭 제공
9.2 운영 특징
탄력성 (Elasticity)
- 부하에 따른 동적 리소스 조정
- 구획별 독립적 확장
- 성능 요구사항 변화 대응
관찰 가능성 (Observability)
- 구획별 성능 메트릭 제공
- 장애 발생 시점과 원인 추적 가능
- 실시간 상태 모니터링
10. 핵심 원칙
10.1 설계 원칙
단일 책임 원칙 적용
- 각 구획은 특정 서비스나 기능에 전담
- 명확한 경계와 책임 정의
- 구획 간 최소한의 결합도 유지
실패 격리 원칙
- 장애는 발생한 구획에만 영향
- 다른 구획의 정상 동작 보장
- 전체 시스템 다운 방지
리소스 예약 원칙
- 각 구획에 전용 리소스 할당
- 리소스 경합 방지
- 예측 가능한 성능 제공
10.2 운영 원칙
점진적 성능 저하 원칙
- 완전한 장애보다는 성능 저하 선택
- 부분적 기능이라도 서비스 지속
- 사용자 경험 최소 영향
빠른 실패 원칙
- 리소스 한계 도달 시 즉시 실패 응답
- 무한 대기 상태 방지
- 시스템 응답성 유지
11. 주요 원리 및 작동 원리
11.1 작동 원리 다이어그램
graph TB
subgraph "Client Layer"
C1[Client 1]
C2[Client 2]
C3[Client 3]
end
subgraph "Bulkhead Layer"
subgraph "Service A Bulkhead"
TP1[Thread Pool A<br/>Max: 5 threads]
Q1[Queue A<br/>Capacity: 10]
end
subgraph "Service B Bulkhead"
TP2[Thread Pool B<br/>Max: 3 threads]
Q2[Queue B<br/>Capacity: 5]
end
subgraph "Service C Bulkhead"
TP3[Thread Pool C<br/>Max: 7 threads]
Q3[Queue C<br/>Capacity: 15]
end
end
subgraph "Service Layer"
SA[Service A]
SB[Service B]
SC[Service C]
end
C1 --> TP1
C2 --> TP2
C3 --> TP3
TP1 --> Q1 --> SA
TP2 --> Q2 --> SB
TP3 --> Q3 --> SC
style TP1 fill:#e1f5fe
style TP2 fill:#f3e5f5
style TP3 fill:#e8f5e8
style Q1 fill:#e1f5fe
style Q2 fill:#f3e5f5
style Q3 fill:#e8f5e8
11.2 세마포어 기반 작동 원리
sequenceDiagram
participant Client
participant Semaphore
participant Service
participant FallbackMethod
Client->>Semaphore: Request Permission
alt Permit Available
Semaphore-->>Client: Grant Permission
Client->>Service: Execute Request
Service-->>Client: Response
Client->>Semaphore: Release Permission
else No Permit Available
Semaphore-->>Client: Reject Request
Client->>FallbackMethod: Execute Fallback
FallbackMethod-->>Client: Fallback Response
end
작동 원리 설명:
- 요청 접수: 클라이언트로부터 서비스 호출 요청이 들어옵니다
- 허가 확인: 해당 서비스의 벌크헤드에서 사용 가능한 리소스(세마포어 허가 또는 스레드) 확인
- 리소스 할당: 사용 가능한 리소스가 있으면 할당하고 요청 처리
- 리소스 반환: 요청 처리 완료 후 리소스를 풀로 반환
- 폴백 처리: 리소스가 없으면 폴백 메서드 실행 또는 즉시 실패
11.3 스레드 풀 기반 작동 원리
graph LR
subgraph "Thread Pool Bulkhead"
A[Request Queue<br/>Capacity: 20] --> B[Core Threads: 5]
B --> C[Max Threads: 10]
C --> D[Service Execution]
E[Overflow] --> F[Rejection Handler]
end
A -->|Queue Full| E
style A fill:#ffcdd2
style B fill:#c8e6c9
style C fill:#c8e6c9
style D fill:#bbdefb
style E fill:#ffcdd2
style F fill:#fff3e0
12. 구조 및 아키텍처
12.1 전체 아키텍처 구조
graph TB
subgraph "Application Layer"
APP[Application Service]
end
subgraph "Bulkhead Management Layer"
BM[Bulkhead Manager]
CONFIG[Configuration]
METRICS[Metrics Collector]
end
subgraph "Resource Pool Layer"
subgraph "Service A Pool"
SA_TP[Thread Pool]
SA_SEM[Semaphore]
SA_QUEUE[Request Queue]
end
subgraph "Service B Pool"
SB_TP[Thread Pool]
SB_SEM[Semaphore]
SB_QUEUE[Request Queue]
end
subgraph "Service C Pool"
SC_TP[Thread Pool]
SC_SEM[Semaphore]
SC_QUEUE[Request Queue]
end
end
subgraph "External Services"
EXT_A[External Service A]
EXT_B[External Service B]
EXT_C[External Service C]
end
APP --> BM
BM --> CONFIG
BM --> METRICS
BM --> SA_TP
BM --> SB_TP
BM --> SC_TP
SA_TP --> SA_SEM
SA_SEM --> SA_QUEUE
SA_QUEUE --> EXT_A
SB_TP --> SB_SEM
SB_SEM --> SB_QUEUE
SB_QUEUE --> EXT_B
SC_TP --> SC_SEM
SC_SEM --> SC_QUEUE
SC_QUEUE --> EXT_C
12.2 필수 구성요소
| 구성요소 | 기능 | 역할 | 특징 |
|---|---|---|---|
| 리소스 풀 (Resource Pool) | 각 서비스별 전용 리소스 제공 | 격리된 실행 환경 보장 | 독립적 리소스 할당 |
| 동시성 제어기 (Concurrency Controller) | 동시 실행 요청 수 제한 | 리소스 오버플로우 방지 | 세마포어 또는 스레드 풀 기반 |
| 요청 큐 (Request Queue) | 대기 요청 임시 저장 | 버퍼링 및 순서 보장 | 용량 제한 및 타임아웃 |
| 메트릭 수집기 (Metrics Collector) | 성능 지표 수집 | 모니터링 및 알림 | 실시간 상태 추적 |
12.3 선택 구성요소
| 구성요소 | 기능 | 역할 | 특징 |
|---|---|---|---|
| 폴백 핸들러 (Fallback Handler) | 실패 시 대체 로직 실행 | 서비스 연속성 보장 | 기본값 반환 또는 캐시 활용 |
| 회로 차단기 (Circuit Breaker) | 반복적 실패 시 요청 차단 | 빠른 실패 및 복구 지원 | 자동 복구 메커니즘 |
| 재시도 메커니즘 (Retry Mechanism) | 일시적 실패 시 재시도 | 네트워크 오류 극복 | 지수 백오프 적용 |
| 로드 밸런서 (Load Balancer) | 요청 분산 | 성능 최적화 | 라운드 로빈, 가중치 등 |
13. 구현 기법
13.1 세마포어 기반 구현 (Semaphore-based Implementation)
정의: 세마포어를 사용하여 동시 실행 가능한 요청 수를 제한하는 방식
구성:
java.util.concurrent.Semaphore활용- 현재 스레드에서 직접 실행
- 허가(Permit) 기반 접근 제어
목적:
- 동기식 호출에서의 동시성 제어
- 메모리 효율적인 리소스 관리
- 빠른 응답 시간 보장
실제 예시:
시스템 구성:
graph LR
A[Incoming Request] --> B[Semaphore<br/>Permits: 10]
B -->|Permit Available| C[Execute in<br/>Current Thread]
B -->|No Permit| D[Fallback or<br/>Immediate Failure]
C --> E[Service Response]
D --> F[Fallback Response]
13.2 스레드 풀 기반 구현 (ThreadPool-based Implementation)
정의: 별도의 스레드 풀을 사용하여 비동기적으로 요청을 처리하는 방식
구성:
- 전용
ThreadPoolExecutor생성 - 큐 용량 및 스레드 수 제한
- CompletableFuture 기반 비동기 처리
목적:
- 비동기 호출에서의 격리
- 타임아웃 제어 가능
- 리소스 완전 격리
실제 예시:
| |
시스템 구성:
graph TB
A[Incoming Request] --> B[Thread Pool<br/>Core: 5, Max: 10]
B --> C[Request Queue<br/>Capacity: 20]
C --> D[Worker Thread]
D --> E[Service Execution]
C -->|Queue Full| F[Rejection Policy]
F --> G[Fallback Response]
E --> H[Async Response]
13.3 프로세스 기반 구현 (Process-based Implementation)
정의: 별도의 프로세스나 컨테이너를 사용하여 완전한 격리를 제공하는 방식
구성:
- Docker 컨테이너 또는 별도 JVM 프로세스
- 네트워크 통신 기반 호출
- 리소스 완전 분리
목적:
- 최고 수준의 격리
- 프로세스 크래시 격리
- 독립적인 배포 및 확장
시나리오: 마이크로서비스 환경에서 각 서비스를 별도 컨테이너로 배포하고, Kubernetes의 리소스 제한을 통해 벌크헤드 구현
14. 장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 장애 격리 (Fault Isolation) | 격리된 리소스 풀 구조로 인해 한 구획의 장애가 다른 구획에 전파되지 않아 전체 시스템 다운을 방지 |
| 장점 | 시스템 복원력 향상 (Enhanced Resilience) | 부분적 장애 상황에서도 정상 구획은 계속 동작하여 서비스 연속성 보장 |
| 장점 | 리소스 보호 (Resource Protection) | 각 구획별 전용 리소스 할당으로 중요 서비스의 리소스가 다른 서비스에 의해 고갈되는 것을 방지 |
| 장점 | 성능 예측 가능성 (Performance Predictability) | 구획별 리소스 제한으로 인해 예측 가능한 성능 특성 제공 |
| 장점 | 독립적 확장성 (Independent Scalability) | 각 구획을 독립적으로 확장할 수 있어 특정 서비스의 부하 증가에 효율적 대응 |
| 장점 | 빠른 장애 감지 (Fast Failure Detection) | 구획별 모니터링으로 장애 발생 시점과 범위를 신속하게 파악 |
| 장점 | 점진적 성능 저하 (Graceful Degradation) | 전체 시스템 다운 대신 부분적 기능 제한으로 사용자 경험 최소 영향 |
15. 단점과 문제점 그리고 해결방안
15.1 단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 복잡성 증가 | 구획별 설정 및 관리로 인한 시스템 복잡도 상승 | 자동화 도구 활용, 표준화된 설정 템플릿 사용 |
| 단점 | 리소스 오버헤드 | 각 구획별 별도 리소스 할당으로 인한 전체 리소스 사용량 증가 | 동적 리소스 조정, 리소스 공유 전략 도입 |
| 단점 | 설정 조정 어려움 | 적절한 구획 크기와 리소스 할당량 결정의 복잡성 | 모니터링 데이터 기반 자동 조정, A/B 테스트 활용 |
| 단점 | 개발 복잡도 증가 | 벌크헤드 로직 구현 및 유지보수 비용 증가 | 프레임워크 활용(Resilience4j, Hystrix), 코드 템플릿 제공 |
15.2 문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 리소스 낭비 | 구획별 고정 할당으로 인한 미사용 리소스 발생 | 전체 시스템 효율성 저하, 비용 증가 | 리소스 사용률 모니터링, 유휴 리소스 알림 | 동적 할당 정책 수립, 최소 보장 + 탄력적 확장 | 적응형 벌크헤드 구현, 리소스 공유 메커니즘 |
| 문제점 | 잘못된 구획 크기 설정 | 부하 패턴 분석 부족, 과대/과소 추정 | 성능 저하 또는 리소스 과할당 | 응답 시간 모니터링, 큐 대기 시간 추적 | 부하 테스트, 점진적 용량 조정 | 자동 크기 조정, 머신러닝 기반 예측 |
| 문제점 | 구획 간 불균형 | 서비스별 부하 패턴 차이, 정적 할당 | 일부 구획 과부하, 다른 구획 유휴 | 구획별 처리량 비교, 대기 큐 길이 모니터링 | 부하 분산 전략, 우선순위 기반 할당 | 동적 리밸런싱, 크로스 구획 리소스 차용 |
| 문제점 | 폴백 로직 복잡성 | 다양한 실패 시나리오, 비즈니스 로직 복잡성 | 개발 및 테스트 복잡도 증가, 버그 가능성 | 폴백 실행 빈도 모니터링, 에러 로그 분석 | 표준화된 폴백 패턴, 단순한 폴백 로직 | 폴백 전략 라이브러리, 자동 테스트 도구 |
16. 도전 과제
16.1 성능 최적화 과제
동적 리소스 조정 (Dynamic Resource Adjustment)
- 원인: 실시간 부하 변화에 대한 정적 설정의 한계
- 영향: 리소스 낭비 또는 성능 저하
- 해결 방법: 머신러닝 기반 예측 모델, 적응형 알고리즘 적용
구획 간 리소스 공유 (Inter-Bulkhead Resource Sharing)
- 원인: 구획별 독립성과 효율성 간의 트레이드오프
- 영향: 전체 시스템 처리량 감소
- 해결 방법: 계층적 벌크헤드 구조, 조건부 리소스 차용 메커니즘
16.2 관리 복잡성 과제
구성 관리 자동화 (Configuration Management Automation)
- 원인: 다수 구획의 개별 설정 관리 복잡성
- 영향: 운영 비용 증가, 설정 오류 가능성
- 해결 방법: 인프라스트럭처 as 코드(IaC), 중앙집중식 구성 관리
크로스 서비스 모니터링 (Cross-Service Monitoring)
- 원인: 분산된 구획별 메트릭의 통합 관리 필요
- 영향: 전체적인 시스템 상태 파악 어려움
- 해결 방법: 통합 모니터링 대시보드, 분산 추적 시스템
16.3 기술 진화 과제
클라우드 네이티브 환경 적응 (Cloud-Native Adaptation)
- 원인: 컨테이너, 서버리스 환경에서의 벌크헤드 적용 복잡성
- 영향: 기존 패턴의 적용성 제한
- 해결 방법: 클라우드 네이티브 벌크헤드 패턴 개발, 서비스 메시 활용
마이크로서비스 메시 통합 (Service Mesh Integration)
- 원인: 서비스 메시와 벌크헤드 패턴의 기능 중복 및 통합 필요
- 영향: 아키텍처 복잡성 증가, 성능 오버헤드
- 해결 방법: 서비스 메시 네이티브 벌크헤드 기능 활용
17. 분류 기준에 따른 종류 및 유형
| 분류 기준 | 종류/유형 | 특징 | 적용 사례 |
|---|---|---|---|
| 구현 방식 | 세마포어 기반 | 동기식, 빠른 응답, 메모리 효율적 | REST API, 동기 서비스 호출 |
| 구현 방식 | 스레드 풀 기반 | 비동기식, 타임아웃 제어, 완전 격리 | 백그라운드 작업, 장시간 처리 |
| 구현 방식 | 프로세스 기반 | 최고 격리 수준, 독립 배포 | 마이크로서비스, 컨테이너 환경 |
| 적용 범위 | 서비스 레벨 | 서비스 단위 격리 | 마이크로서비스 아키텍처 |
| 적용 범위 | 기능 레벨 | 기능 단위 격리 | 모놀리식 애플리케이션 내 기능 분리 |
| 적용 범위 | 리소스 레벨 | 특정 리소스 격리 | 데이터베이스 연결, 외부 API 호출 |
| 리소스 타입 | 스레드 풀 벌크헤드 | 스레드 리소스 격리 | CPU 집약적 작업 |
| 리소스 타입 | 연결 풀 벌크헤드 | 네트워크 연결 격리 | 데이터베이스, HTTP 클라이언트 |
| 리소스 타입 | 메모리 벌크헤드 | 메모리 영역 격리 | 캐시, 버퍼 관리 |
| 동적 특성 | 정적 벌크헤드 | 고정 리소스 할당 | 예측 가능한 부하 패턴 |
| 동적 특성 | 동적 벌크헤드 | 가변 리소스 할당 | 변동성 있는 부하 패턴 |
| 동적 특성 | 적응형 벌크헤드 | 자동 조정 리소스 할당 | AI/ML 기반 최적화 |
18. 실무 사용 예시
| 사용 맥락 | 함께 사용되는 기술/패턴 | 목적 | 효과 |
|---|---|---|---|
| 마이크로서비스 아키텍처 | Spring Cloud, Kubernetes, Service Mesh | 서비스 간 장애 격리 | 부분 장애 시에도 전체 시스템 가용성 유지 |
| API 게이트웨이 | Kong, Zuul, Ambassador | 외부 API 호출 제한 | 외부 서비스 장애가 내부 시스템에 미치는 영향 최소화 |
| 배치 처리 시스템 | Spring Batch, Apache Spark | 작업 유형별 리소스 분리 | 대용량 작업이 실시간 작업에 영향 주지 않음 |
| 데이터베이스 접근 | Connection Pool, HikariCP | DB 연결 풀 분리 | 특정 쿼리 성능 이슈가 다른 작업에 영향 없음 |
| 캐시 시스템 | Redis Cluster, Hazelcast | 캐시 인스턴스 분리 | 캐시 장애 시 부분적 성능 저하만 발생 |
| 메시지 큐 시스템 | RabbitMQ, Apache Kafka | 토픽/큐별 컨슈머 그룹 분리 | 특정 메시지 처리 실패가 다른 메시지에 영향 없음 |
| 로드 밸런싱 | HAProxy, NGINX | 서버 그룹별 부하 분산 | 서버 그룹 장애 시 다른 그룹으로 트래픽 라우팅 |
| 클라우드 환경 | AWS ECS, Azure Container | 컨테이너 리소스 제한 | 컨테이너별 독립적 확장 및 장애 처리 |
19. 활용 사례
19.1 전자상거래 플랫폼에서의 벌크헤드 패턴 적용
배경: 대규모 전자상거래 플랫폼에서 상품 조회, 주문 처리, 결제 처리, 재고 관리 등 다양한 서비스가 운영되고 있습니다. 특정 서비스의 성능 저하나 장애가 전체 시스템에 영향을 미치는 문제가 발생했습니다.
19.2 시스템 구성
graph TB
subgraph "Client Layer"
WEB[Web Browser]
MOBILE[Mobile App]
API[External API]
end
subgraph "API Gateway"
GATEWAY[Load Balancer/API Gateway]
end
subgraph "Bulkhead Layer"
subgraph "Product Service Bulkhead"
PSB[Thread Pool: 20<br/>Queue: 50<br/>Timeout: 2s]
end
subgraph "Order Service Bulkhead"
OSB[Thread Pool: 15<br/>Queue: 30<br/>Timeout: 5s]
end
subgraph "Payment Service Bulkhead"
PAYB[Thread Pool: 10<br/>Queue: 20<br/>Timeout: 10s]
end
subgraph "Inventory Service Bulkhead"
ISB[Thread Pool: 8<br/>Queue: 15<br/>Timeout: 3s]
end
end
subgraph "Service Layer"
PS[Product Service]
OS[Order Service]
PAYS[Payment Service]
IS[Inventory Service]
end
subgraph "Data Layer"
PRODDB[(Product DB)]
ORDERDB[(Order DB)]
PAYDB[(Payment DB)]
INVDB[(Inventory DB)]
end
WEB --> GATEWAY
MOBILE --> GATEWAY
API --> GATEWAY
GATEWAY --> PSB
GATEWAY --> OSB
GATEWAY --> PAYB
GATEWAY --> ISB
PSB --> PS
OSB --> OS
PAYB --> PAYS
ISB --> IS
PS --> PRODDB
OS --> ORDERDB
PAYS --> PAYDB
IS --> INVDB
19.3 Workflow
sequenceDiagram
participant User
participant Gateway
participant ProductBulkhead
participant OrderBulkhead
participant PaymentBulkhead
participant InventoryBulkhead
participant ProductService
participant OrderService
participant PaymentService
participant InventoryService
User->>Gateway: 상품 주문 요청
Gateway->>ProductBulkhead: 상품 정보 조회
ProductBulkhead->>ProductService: 실행 (Thread Pool 1개 사용)
ProductService-->>ProductBulkhead: 상품 정보 반환
ProductBulkhead-->>Gateway: 응답
Gateway->>InventoryBulkhead: 재고 확인
InventoryBulkhead->>InventoryService: 실행 (Thread Pool 1개 사용)
InventoryService-->>InventoryBulkhead: 재고 상태 반환
InventoryBulkhead-->>Gateway: 응답
Gateway->>OrderBulkhead: 주문 생성
OrderBulkhead->>OrderService: 실행 (Thread Pool 1개 사용)
OrderService-->>OrderBulkhead: 주문 ID 반환
OrderBulkhead-->>Gateway: 응답
Gateway->>PaymentBulkhead: 결제 처리
Note over PaymentBulkhead: 결제 서비스 지연 발생
PaymentBulkhead->>PaymentService: 실행 (모든 Thread Pool 사용됨)
PaymentService-->>PaymentBulkhead: 처리 지연
Gateway->>ProductBulkhead: 다른 사용자 상품 조회
Note over ProductBulkhead: 결제 서비스 지연과 무관하게 정상 동작
ProductBulkhead->>ProductService: 실행 (독립적 Thread Pool)
ProductService-->>ProductBulkhead: 정상 응답
ProductBulkhead-->>Gateway: 빠른 응답
19.4 벌크헤드 패턴의 역할
격리 및 보호:
- 결제 서비스의 지연이 발생해도 상품 조회, 주문 조회 등 다른 서비스는 정상 동작
- 각 서비스별 독립적인 스레드 풀로 리소스 경합 방지
- 서비스별 타임아웃 설정으로 무한 대기 방지
리소스 관리:
- 중요도에 따른 차등적 리소스 할당 (결제 > 주문 > 상품 조회)
- 큐 용량 제한으로 메모리 오버플로우 방지
- 실시간 모니터링을 통한 리소스 사용량 추적
19.5 벌크헤드 패턴 유무에 따른 차이점
벌크헤드 패턴 적용 전:
- 결제 서비스 지연 시 전체 시스템 스레드 풀 고갈
- 상품 조회 등 단순한 작업도 응답 지연 발생
- 연쇄 장애로 인한 전체 서비스 불가능 상태
벌크헤드 패턴 적용 후:
- 결제 서비스 지연이 다른 서비스에 영향 없음
- 각 서비스별 독립적인 성능 보장
- 부분적 장애 시에도 핵심 기능 유지 가능
- 전체 시스템 가용성 99.9%에서 99.95%로 향상
20. 구현 예시
다음은 전자상거래 플랫폼의 벌크헤드 패턴을 Spring Boot와 Resilience4j를 사용하여 구현한 예시입니다:—
21. 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 구분 | 고려사항 | 권장사항 |
|---|---|---|
| 리소스 계획 | 서비스별 적절한 리소스 할당량 결정 | 과거 부하 데이터 분석, 점진적 용량 증설, A/B 테스트를 통한 최적값 도출 |
| 모니터링 설정 | 구획별 성능 메트릭 및 알림 체계 구축 | Micrometer, Prometheus 연동, 대시보드 구성, 임계값 기반 자동 알림 |
| 폴백 전략 | 실패 시 대체 로직의 복잡성 관리 | 단순하고 빠른 폴백 로직, 캐시 활용, 기본값 제공, 점진적 성능 저하 |
| 테스트 전략 | 다양한 장애 시나리오에 대한 검증 | 카오스 엔지니어링, 부하 테스트, 장애 주입 테스트, 폴백 시나리오 테스트 |
| 설정 관리 | 환경별 설정 값의 일관성 유지 | 중앙집중식 설정 관리(Spring Cloud Config), 환경별 프로파일 분리 |
| 점진적 도입 | 기존 시스템에 무리 없는 적용 방안 | 핵심 서비스부터 단계적 적용, 카나리 배포, 기능 토글 활용 |
| 팀 교육 | 개발팀의 패턴 이해도 향상 | 워크샵 진행, 코드 리뷰 가이드라인, 모범 사례 공유 |
22. 최적화하기 위한 고려사항 및 주의할 점
| 구분 | 고려사항 | 권장사항 |
|---|---|---|
| 동적 조정 | 실시간 부하에 따른 리소스 자동 조정 | 머신러닝 기반 예측 모델, 적응형 벌크헤드 구현, 히스토리 데이터 활용 |
| 리소스 효율성 | 구획 간 유휴 리소스 활용 | 계층적 벌크헤드 구조, 조건부 리소스 차용, 우선순위 기반 할당 |
| 응답 시간 최적화 | 폴백 로직의 성능 최적화 | 비동기 폴백 처리, 로컬 캐시 활용, CDN 연동, 사전 계산된 결과 활용 |
| 메모리 관리 | 구획별 메모리 사용량 최적화 | JVM 힙 분석, 가비지 컬렉션 튜닝, 오프힙 캐시 활용 |
| 네트워크 최적화 | 구획 간 통신 오버헤드 최소화 | 연결 풀 재사용, Keep-Alive 설정, HTTP/2 활용, 로컬 캐시 우선 |
| 확장성 고려 | 마이크로서비스 환경에서의 확장 | 서비스 메시 활용, 컨테이너 기반 격리, 오토스케일링 연동 |
| 비용 최적화 | 클라우드 환경에서의 비용 효율성 | 스팟 인스턴스 활용, 예약 인스턴스 최적 배치, 리소스 사용률 모니터링 |
23. 주제와 관련하여 주목할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 구현 프레임워크 | Resilience4j | 세마포어/스레드풀 벌크헤드 | Java 환경에서 가장 널리 사용되는 복원력 라이브러리 |
| 구현 프레임워크 | Netflix Hystrix | 레거시 벌크헤드 구현 | 초기 벌크헤드 패턴 구현체, 현재는 유지보수 모드 |
| 구현 프레임워크 | Polly | .NET 환경 구현 | .NET 기반 애플리케이션을 위한 복원력 라이브러리 |
| 클라우드 플랫폼 | AWS App Mesh | 네트워크 레벨 벌크헤드 | 서비스 메시를 통한 트래픽 격리 및 제어 |
| 클라우드 플랫폼 | Kubernetes | 컨테이너 리소스 제한 | 네임스페이스, 리소스 쿼터를 통한 격리 |
| 클라우드 플랫폼 | Istio Service Mesh | 사이드카 패턴 벌크헤드 | 애플리케이션 레벨 투명한 벌크헤드 구현 |
| 모니터링 도구 | Micrometer | 메트릭 수집 | 벌크헤드 상태 및 성능 지표 수집 |
| 모니터링 도구 | Prometheus | 시계열 데이터 저장 | 벌크헤드 메트릭의 장기 보관 및 분석 |
| 모니터링 도구 | Grafana | 시각화 대시보드 | 벌크헤드 상태 실시간 모니터링 |
| 아키텍처 패턴 | Circuit Breaker | 회로 차단기 패턴 | 벌크헤드와 함께 사용되는 복원력 패턴 |
| 아키텍처 패턴 | Retry Pattern | 재시도 패턴 | 일시적 장애 대응을 위한 보완 패턴 |
| 아키텍처 패턴 | Timeout Pattern | 타임아웃 패턴 | 무한 대기 방지를 위한 필수 패턴 |
24. 반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 동시성 프로그래밍 | Java Concurrency | Semaphore, ThreadPoolExecutor | 벌크헤드 구현의 핵심 기술 요소 |
| 동시성 프로그래밍 | CompletableFuture | 비동기 프로그래밍 | 스레드 풀 벌크헤드 구현 필수 지식 |
| 성능 테스트 | JMeter/Gatling | 부하 테스트 도구 | 벌크헤드 효과 검증 및 최적화 |
| 성능 테스트 | Chaos Engineering | 장애 주입 테스트 | 벌크헤드 복원력 검증 방법론 |
| 모니터링 | APM 도구 | 애플리케이션 성능 모니터링 | 벌크헤드 효과 측정 및 분석 |
| 모니터링 | 로그 집계 | ELK Stack, Splunk | 분산 환경에서의 벌크헤드 동작 추적 |
| 클라우드 네이티브 | 컨테이너 오케스트레이션 | Kubernetes, Docker | 현대적 벌크헤드 구현 환경 |
| 클라우드 네이티브 | 서비스 메시 | Istio, Linkerd | 네트워크 레벨 벌크헤드 구현 |
| 아키텍처 설계 | 마이크로서비스 | 서비스 분해, API 설계 | 벌크헤드 적용 대상 식별 |
| 아키텍처 설계 | 분산 시스템 | CAP 정리, 일관성 모델 | 벌크헤드가 해결하는 분산 시스템 문제 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 핵심 개념 | Bulkhead (벌크헤드) | 선박의 격벽에서 유래된 격리 구획을 의미하는 용어 |
| 핵심 개념 | Fault Isolation (장애 격리) | 특정 구성 요소의 장애를 해당 영역에 국한시키는 기법 |
| 핵심 개념 | Cascading Failure (연쇄 장애) | 하나의 장애가 다른 구성 요소로 전파되어 발생하는 장애 |
| 구현 기술 | Semaphore (세마포어) | 동시 접근을 제한하는 동기화 프리미티브 |
| 구현 기술 | Thread Pool (스레드 풀) | 스레드를 미리 생성하여 재사용하는 패턴 |
| 구현 기술 | Connection Pool (연결 풀) | 데이터베이스 연결을 미리 생성하여 재사용하는 기법 |
| 성능 지표 | Throughput (처리량) | 단위 시간당 처리할 수 있는 요청 수 |
| 성능 지표 | Latency (지연 시간) | 요청 처리에 소요되는 시간 |
| 성능 지표 | Queue Depth (큐 깊이) | 대기 중인 요청의 수 |
| 복원력 패턴 | Circuit Breaker (회로 차단기) | 반복적 실패 시 요청을 차단하는 패턴 |
| 복원력 패턴 | Fallback (폴백) | 주 기능 실패 시 실행되는 대체 로직 |
| 복원력 패턴 | Timeout (타임아웃) | 최대 대기 시간 제한 |
| 모니터링 | Health Check (헬스 체크) | 서비스 상태 확인 메커니즘 |
| 모니터링 | Metrics (메트릭) | 시스템 성능 및 상태 지표 |
| 모니터링 | SLA (Service Level Agreement) | 서비스 수준 협약 |
참고 및 출처
- Resilient Microservice Design – Bulkhead Pattern
- Bulkhead Pattern - GeeksforGeeks
- Bulkhead pattern - Azure Architecture Center | Microsoft Learn
- 5 proven patterns for resilient software architecture design | TechTarget
- How to Build a Fault Tolerant Architecture with Bulkhead Pattern? | GeeksforGeeks
- Building a fault tolerant architecture with a Bulkhead Pattern on AWS App Mesh | Amazon Web Services
- Bulkhead Pattern with Spring Boot | Vinsguru
- Resilience4j Bulkhead Documentation
- Resilience4J: Introduction to Bulkhead - NashTech Blog
Bulkhead 패턴은 마이크로서비스 아키텍처(MSA)에서 시스템의 복원력과 장애 격리를 향상시키기 위해 사용되는 디자인 패턴이다.
Bulkhead 패턴은 선박의 격벽(bulkhead)에서 이름을 따왔다.
선박에서 격벽은 선체를 여러 구획으로 나누어 한 구획에 물이 차더라도 전체 선박이 침몰하지 않도록 하는 역할을 한다. 마찬가지로, 소프트웨어 시스템에서 Bulkhead 패턴은 시스템의 각 부분을 격리하여 한 부분의 실패가 전체 시스템으로 확산되는 것을 방지한다.
이 패턴을 효과적으로 사용하려면 시스템의 특성과 요구사항을 잘 이해하고, 적절한 격리 수준을 결정하는 것이 중요하다. Bulkhead 패턴을 통해 마이크로서비스 아키텍처의 안정성과 복원력을 크게 향상시킬 수 있다.
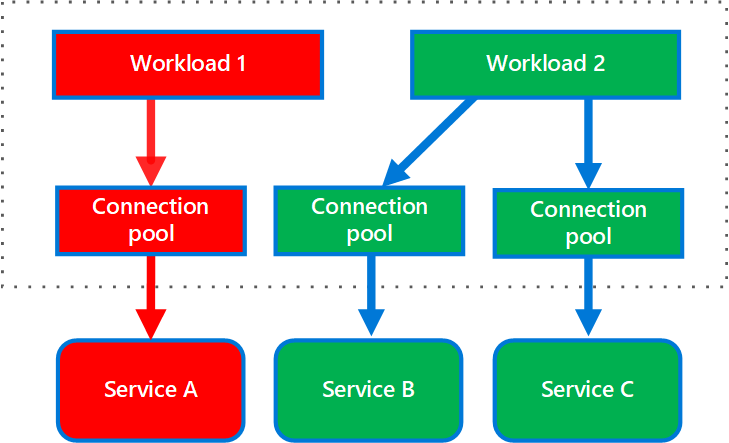
Bulkhead 패턴의 핵심 개념
- 격리(Isolation):
- 시스템을 여러 독립된 “구획"으로 나누어, 각 구획이 고유한 리소스 풀(스레드, 연결 등)을 사용하도록 한다.
- 장애가 특정 구획 내에서만 발생하고, 다른 구획으로 확산되지 않도록 격리한다.
- 자원 제한(Resource Limiting):
- Bulkhead 패턴은 자원의 과도한 소비를 방지하기 위해 각 구획에 고정된 양의 리소스를 할당한다.
- 예: 스레드 풀, 데이터베이스 연결 풀, 메모리 등.
- 장애 복원력(Fault Tolerance):
- 장애가 발생하더라도 다른 구획은 영향을 받지 않으므로, 시스템 전체의 안정성이 유지된다.
- 장애 구획은 독립적으로 복구된다.
Bulkhead 패턴의 목적
- 장애 격리: 시스템의 한 부분에서 발생한 장애가 다른 부분으로 전파되는 것을 방지한다.
- 리소스 관리: 각 컴포넌트나 서비스에 할당된 리소스를 제한하여 과도한 리소스 사용을 방지한다.
- 시스템 복원력 향상: 일부 서비스에 문제가 발생해도 전체 시스템은 계속 작동할 수 있도록 한다.
Bulkhead 패턴의 구현 방법
- 스레드 풀 분리: 각 서비스나 컴포넌트에 대해 별도의 스레드 풀을 할당한다.
- 프로세스 분리: 중요한 서비스를 별도의 프로세스로 실행한다.
- 컨테이너화: 각 서비스를 독립적인 컨테이너로 실행하여 리소스를 격리한다.
Bulkhead 패턴의 장점
- 장애 전파 방지: 한 서비스의 장애가 다른 서비스로 확산되는 것을 막는다.
- 리소스 효율성: 각 서비스에 필요한 만큼의 리소스만 할당하여 효율적으로 관리할 수 있다.
- 확장성 향상: 필요한 서비스만 독립적으로 확장할 수 있다.
- 성능 최적화: 각 서비스의 특성에 맞게 리소스를 최적화할 수 있다.
Bulkhead 패턴의 단점
- 복잡성 증가: 시스템 설계와 관리가 더 복잡해질 수 있다.
- 리소스 활용의 비효율: 격리된 리소스 풀로 인해 일부 리소스가 충분히 활용되지 않을 수 있다.
Bulkhead 패턴의 사용 사례
- 스레드 풀 분리:
- 각 서비스나 요청 유형마다 스레드 풀을 별도로 설정하여, 특정 스레드 풀의 과부하가 다른 서비스에 영향을 미치지 않도록 한다.
- 데이터베이스 연결 풀 분리:
- 서비스별로 데이터베이스 연결 풀을 분리하여, 한 서비스가 데이터베이스 연결을 과도하게 사용하더라도 다른 서비스가 안정적으로 동작할 수 있도록 한다.
- API 요청 분리:
- 고우선순위 요청과 저우선순위 요청을 분리하여, 트래픽이 폭증하더라도 중요한 요청이 처리될 수 있도록 한다.
Bulkhead 패턴 구현 예시
스레드 풀 기반 Bulkhead 예제
| |
설명
ThreadPoolExecutor를 사용하여 서비스별로 스레드 풀을 분리한다.- 서비스 A는 3개의 스레드만 사용할 수 있으며, 서비스 B는 2개의 스레드만 사용한다.
- 서비스 A에서 요청이 폭증하더라도 서비스 B는 독립적으로 동작한다.
Bulkhead 패턴 구현 시 고려사항
- 리소스 할당: 각 서비스나 컴포넌트에 적절한 리소스를 할당해야 한다.
- 모니터링: 각 격리된 부분의 성능과 리소스 사용을 모니터링해야 한다.
- 동적 조정: 필요에 따라 리소스 할당을 동적으로 조정할 수 있는 메커니즘을 고려해야 한다.
Bulkhead 패턴은 다른 MSA 패턴들과 함께 사용될 때 더욱 효과적이다. 예를 들어, Circuit Breaker 패턴과 함께 사용하면 시스템의 복원력을 더욱 향상시킬 수 있다.