Connection Pooling
1 부. 태그, 분류 구조, 요약 및 개요
1. 태그 (Tag)
Connection-Pool, Database-Integration, Resource-Management, Performance-Optimization
2. 분류 구조의 적합성 분석
“Systems and Infrastructure > Database Systems > Database Integration” 분류는 커넥션 풀 (Connection Pool) 의 본질을 잘 반영합니다. 커넥션 풀은 데이터베이스와 애플리케이션 간의 효율적인 통합과 리소스 관리를 담당하는 핵심 기술로, 데이터베이스 통합 (Database Integration) 카테고리에서 다루는 것이 타당합니다.
3. 200 자 내외 요약
커넥션 풀 (Connection Pool) 은 데이터베이스 연결을 미리 생성해 풀 (pool) 로 관리하고, 필요 시 재사용함으로써 연결 생성·해제에 따른 오버헤드를 줄이고 애플리케이션의 성능과 확장성을 높이는 핵심 기술입니다. 대규모 트래픽 처리와 리소스 효율화에 필수적입니다.
4. 250 자 내외 개요
커넥션 풀 (Connection Pool) 은 데이터베이스 연결을 미리 여러 개 생성해두고, 애플리케이션에서 필요할 때마다 이를 할당·반환하는 방식으로 동작합니다. 이 구조는 데이터베이스 연결의 빈번한 생성과 해제에 따른 비용을 줄이고, 동시 접속 처리량을 높이며, 시스템의 안정성과 성능을 크게 향상시킵니다. 웹 서비스, API 서버 등 다양한 환경에서 표준적으로 사용되며, 효율적인 리소스 관리와 장애 대응에도 중요한 역할을 합니다.
2 부. 커넥션 풀 심층 분석
1. 핵심 개념
- 커넥션 풀 (Connection Pool): 데이터베이스 연결을 미리 생성해 풀로 관리하고, 필요 시 할당·반환하여 재사용하는 자원 관리 기법
- 풀 (Pool): 미리 생성된 연결 (커넥션) 객체의 집합
- 할당 (Allocation): 애플리케이션이 풀에서 커넥션을 가져오는 과정
- 반환 (Return/Release): 사용이 끝난 커넥션을 풀로 돌려보내는 과정
2. 실무 연관성 분석
- 대규모 트래픽 환경에서 데이터베이스 연결 효율화
- 연결 생성/해제 오버헤드 감소로 성능 향상
- 연결 수 제한 및 리소스 관리로 장애 예방
- 다양한 언어와 프레임워크에서 표준적으로 사용
3. 배경
- 데이터베이스 연결 생성/해제 비용이 높고, 빈번한 연결 관리가 서버 성능 저하의 주요 원인
- 동시 사용자 증가에 따라 효율적인 연결 관리 필요성 대두
4. 목적 및 필요성
- 데이터베이스 연결 관리의 효율화 및 최적화
- 시스템 성능 및 확장성 확보
- 장애 예방 및 리소스 고갈 방지
5. 주요 기능 및 역할
- 미리 연결 생성 및 재사용
- 최대/최소 커넥션 수 관리
- 커넥션 유휴 시간 관리 및 자동 종료
- 장애 커넥션 감지 및 복구
6. 특징
- 연결 재사용
- 동시성 및 확장성 강화
- 리소스 효율화
- 자동 장애 감지 및 복구
7. 핵심 원칙
- 연결의 재사용과 효율적 관리
- 최대/최소 풀 크기 설정
- 커넥션 상태 모니터링 및 복구
8. 주요 원리 및 작동 원리
flowchart TD
A[애플리케이션 요청] --> B{풀에 사용 가능한 커넥션이 있는가?}
B -- 예 --> C[커넥션 할당]
B -- 아니오 --> D{최대 커넥션 수 미달인가?}
D -- 예 --> E[새 커넥션 생성 및 할당]
D -- 아니오 --> F[대기 또는 예외 발생]
C & E --> G[작업 수행]
G --> H[커넥션 반환]
H --> B
- 설명: 애플리케이션이 데이터베이스 작업을 요청하면, 커넥션 풀에서 사용 가능한 커넥션을 할당하고, 작업이 끝나면 커넥션을 반환합니다. 풀에 여유가 없으면 새로 생성하거나 대기하게 됩니다.
9. 구조 및 아키텍처
| 구성 요소 | 기능 | 역할 |
|---|---|---|
| 커넥션 풀 관리자 | 풀 전체 관리 | 커넥션 생성, 할당, 반환, 종료 |
| 커넥션 객체 | DB 연결 관리 | 실제 데이터베이스 연결 |
| 풀 큐/리스트 | 커넥션 저장 | 사용/미사용 커넥션 관리 |
| 모니터링 모듈 | 상태 감시 | 유휴 커넥션, 장애 감지 |
| 설정 모듈 | 파라미터 관리 | 최대/최소 크기, 타임아웃 등 |
선택 구성요소
| 구성 요소 | 기능 | 역할 |
|---|---|---|
| 로깅 모듈 | 이벤트 기록 | 풀 동작 이력 관리 |
| 알림 시스템 | 장애 알림 | 비정상 상황 실시간 통보 |
3 부. 구현 기법, 장단점, 실무 활용
1. 구현 기법
- Fixed Pool(고정 크기 풀): 풀 크기를 고정하여 관리
- Dynamic Pool(동적 크기 풀): 부하에 따라 풀 크기 자동 조정
- Timeout 관리: 유휴 커넥션 자동 종료
- Health Check(상태 점검): 커넥션 유효성 주기적 검사
2. 장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 성능 향상 | 연결 생성/해제 오버헤드 감소 |
| 장점 | 자원 효율화 | 불필요한 연결 최소화 |
| 장점 | 확장성 | 동시 접속 처리량 증가 |
| 장점 | 안정성 | 리소스 고갈 및 장애 예방 |
3. 단점과 문제점 그리고 해결방안
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 설정 복잡성 | 최적 풀 크기 산정 어려움 | 트래픽 분석 통한 튜닝 |
| 단점 | 자원 고갈 | 풀 크기 초과 시 대기/예외 | 적절한 타임아웃, 알림 도입 |
| 단점 | 유휴 커넥션 | 장시간 미사용 커넥션 존재 | 유휴 커넥션 종료 정책 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 풀 고갈 | 동시 접속 폭증 | 서비스 지연/장애 | 풀 사용률 모니터링 | 최대 크기 조정 | 자동 확장/알림 |
| 문제점 | 유휴 커넥션 누수 | 반환 누락/풀 관리 미흡 | 리소스 낭비 | 유휴 커넥션 감시 | 자동 종료 | 타임아웃 설정 |
| 문제점 | 비정상 커넥션 | 네트워크 장애 등 | 작업 실패/데이터 손실 | 상태 점검 | 정기적 Health Check | 비정상 커넥션 자동 제거 |
4. 도전 과제
- 대규모 분산 환경에서의 풀 관리 자동화
- 트래픽 급증 시 동적 확장 최적화
- 장애 상황에서의 빠른 복구 및 알림 체계 강화
5. 분류 기준에 따른 종류 및 유형
| 분류 기준 | 유형 | 설명 |
|---|---|---|
| 풀 크기 | 고정형 (Fixed) | 최대/최소 크기 고정 |
| 풀 크기 | 동적형 (Dynamic) | 부하에 따라 자동 조정 |
| 구현 방식 | 내장형 | 프레임워크/라이브러리 내장 |
| 구현 방식 | 외부형 | 별도 미들웨어로 운영 |
6. 실무 사용 예시
| 사용 분야 | 함께 사용하는 시스템 | 목적 | 효과 |
|---|---|---|---|
| 웹 서비스 | Spring Boot, HikariCP | 대규모 트래픽 처리 | 성능, 안정성 향상 |
| API 서버 | Node.js, node-postgres | 동시 요청 처리 | 응답 속도 개선 |
| 엔터프라이즈 | Java EE, Tomcat JDBC Pool | 대용량 트랜잭션 관리 | 리소스 최적화 |
7. 활용 사례
- 웹 서비스 트래픽 급증 대응
- Spring Boot + HikariCP 환경에서 커넥션 풀을 활용해 동시 요청 폭증 시에도 빠른 응답과 안정적인 서비스 유지
- 커넥션 풀 미적용 시: 연결 생성/해제 병목, 서비스 지연 및 장애
- 커넥션 풀 적용 시: 미리 생성된 커넥션 재사용, 부하 분산 및 성능 극대화
flowchart TD
User[사용자] --> WebApp[웹 애플리케이션]
WebApp --> Pool[커넥션 풀]
Pool --> DB[데이터베이스]
8. 구현 예시 (Python, Psycopg2 + Connection pool)
| |
- 설명: 커넥션 풀에서 커넥션을 할당받아 사용 후 반환함으로써, 연결 생성/해제 오버헤드를 줄이고 효율적으로 리소스를 관리합니다.
9. 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 구분 | 항목 | 설명 |
|---|---|---|
| 설계 | 최적 풀 크기 산정 | 트래픽/DB 리소스 분석 필요 |
| 운영 | 유휴 커넥션 관리 | 자동 종료, 상태 점검 |
| 확장성 | 동적 확장 지원 | 트래픽 변화에 따른 조정 |
| 모니터링 | 풀 사용률 감시 | 풀 고갈/누수 실시간 감시 |
- 권장사항: 트래픽 패턴 분석 후 풀 크기 설정, 정기적 Health Check, 자동 알림 시스템 도입
10. 최적화하기 위한 고려사항 및 주의할 점
| 구분 | 항목 | 설명 |
|---|---|---|
| 성능 | 풀 크기 튜닝 | 최대/최소 크기 조정 |
| 운영 | 타임아웃 설정 | 대기/유휴 커넥션 관리 |
| 모니터링 | 상태 감시 자동화 | 풀/커넥션 상태 실시간 체크 |
| 장애 대응 | 비정상 커넥션 제거 | 자동 복구 정책 도입 |
- 권장사항: 부하 테스트 기반 튜닝, 자동화된 모니터링 및 복구 시스템 구축
4 부. 주제별 주목할 내용 및 학습 필수 항목
1. 주제별 주목할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 리소스 관리 | 커넥션 풀 | 재사용/최적화 | DB 연결 효율화 |
| 운영 | Health Check | 상태 점검 | 비정상 커넥션 자동 제거 |
| 확장성 | 동적 확장 | 풀 크기 자동 조정 | 트래픽 변화 대응 |
| 모니터링 | 풀 사용률 | 실시간 감시 | 장애 예방 |
2. 반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 리소스 관리 | 커넥션 풀 원리 | 풀 구조/동작 방식 | 기본 구조와 관리 원리 |
| 운영 | 풀 튜닝 | 최적 크기/타임아웃 | 성능 최적화 기법 |
| 모니터링 | 상태 점검/알림 | 풀/커넥션 상태 감시 | 실시간 장애 대응 |
| 확장성 | 동적 확장 | 트래픽 기반 자동 조정 | 부하 분산 및 안정성 확보 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 리소스 관리 | 커넥션 풀 (Connection Pool) | DB 연결을 미리 생성해 풀로 관리, 필요 시 재사용하는 기법 |
| 리소스 관리 | 풀 (Pool) | 여러 커넥션 객체의 집합 |
| 운영 | Health Check(상태 점검) | 커넥션 유효성 주기적 검사 |
| 운영 | 타임아웃 (Timeout) | 대기/유휴 커넥션의 최대 허용 시간 |
| 운영 | 풀 고갈 (Pool Exhaustion) | 풀 내 사용 가능한 커넥션이 모두 소진된 상태 |
참고 및 출처
1. 태그 (Tags)
- Connection-Pooling
- Database-Integration
- Systems-Infrastructure
- Resource-Management
2. 분류 적절성 분석
현재 구조에는 Systems and Infrastructure → Database Systems → Database Integration에 속하도록 배치되어 있습니다.
근거:
- Connection Pool 은 데이터베이스와 애플리케이션 통합 시 자주 등장하는 핵심 패턴이고,
- 데이터베이스 연결 관리를 위한 시스템 인프라적 메커니즘이므로 분류가 적절합니다.
3. 요약 (200 자 내외)
Connection Pool 은 데이터베이스 연결의 생성·소멸 비용을 줄이기 위해 재사용 가능한 연결 집합을 유지하는 기술입니다. 성능 향상, 리소스 절약, 동시성 제어 등의 이점을 제공하며, 클라이언트‑사이드 라이브러리 또는 PgBouncer 같은 외부 미들웨어로 구현됩니다.
4. 개요 (250 자 내외)
Connection Pool 은 애플리케이션이 데이터베이스와 효율적으로 연동하도록 돕는 핵심 패턴입니다. 초기 연결 비용을 회피하고 반복 요청 시 연결을 재사용하여 응답 시간을 줄이며, 데이터베이스의 동시 연결 수 제한 문제를 완화합니다. 클라이언트 라이브러리 (HikariCP, pg-pool 등) 나 PgBouncer/pgpool-II 같은 프록시 미들웨어로 구현 가능하며, 동적 확장, 유휴 관리, 장애 조치 등 다양한 기능을 제공해 고부하 환경에서도 안정성과 성능을 유지할 수 있습니다.
5. 핵심 개념
- Connection Pool: 미리 만든 연결 모음, 사용 후 반환하여 재사용
- Client-side pooling: HikariCP, pg-pool, ADO.NET 클라이언트에서 구현 (cockroachlabs.com, cloudnative-pg.io, ScaleGrid, Microsoft Learn)
- External pooling: PgBouncer, pgpool-II 같은 프록시 방식
- 풀 설정: 최소/최대 사이즈, 유휴 시간, 타임아웃 설정 필요
- Pooling Mode: session, transaction, statement 방식 (Microsoft Learn)
- Wrapper Connection: Close 시 실제 종료가 아닌 반환 처리 (위키백과)
5.1 실무 연관성
- 성능 최적화: 연결 비용이 큰 환경에서 지연 최소화
- 리소스 관리: DB 동시연결 제한 내에서 유휴 연결 제어
- 장애 대응: 연결 끊김 시 재시도/교체 로직 포함
- 구성 유연성: 각 모듈 별 또는 중앙 집중형 pool 설정
6. “## 6. 주제와 관련하여 조사할 내용 " 반영
다음 항목들을 조사했으며, 이후 상세 분석 시 각각의 헤더에 맞춰 확장해 다루겠습니다:
- 배경, 목적 및 필요성
- 주요 기능 및 역할
- 특징, 핵심 원칙
- 주요 원리·작동 방식 (diagram 포함)
- 구조·아키텍처 및 구성 요소 (필수/선택 구성 요소 구분)
- 구현 기법 (client-side vs external)
- 장/단점 및 해결책 (표 포함)
- 도전과제
- 분류 기준 → 종류/유형 (표 포함)
- 실무 사용 예시 및 활용 사례 (diagram, 코드)
- 구현 예시 (Python 또는 JS)
- 실무 적용 고려사항, 최적화 시 주의점 (표 + 권장사항)
9. 주목할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| Architecture | Pooling Mode | session/transaction/statement | Connection 반환 시점을 결정, 기능/성능 영향 |
| Middleware | External vs Client-side | PgBouncer vs HikariCP | 중앙집중 vs 모듈단위 제어 방식의 차이 |
| Configuration | Pool Size 설정 | 최소·최대 크기 | 동시성·리소스 균형 유지를 위한 핵심 변수 |
| Resilience | Connection Health | idle/recycle/timeout | 안정성을 위한 연결 유효성 관리 |
10. 반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| Performance | Latency 분석 | connection acq./release | 연결 재사용 전후 퍼포먼스 비교 |
| Reliability | Connection Leak | 감지/해결 기법 | 커넥션 반환 누락 문제 대응 |
| Scaling | 초당 요청·동시연결 | 동적 pool 조정 | 부하 변화에 따른 크기 조정 전략 |
| Security | Credential Isolation | pooling 환경 보안 설정 | 사용자 격리, 인증 관리 |
| Monitoring | Metrics & Alerts | pool 사용률, 대기시간 | 운영 시 필수 모니터링 지표 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 구성요소 | Pool Mode | session/transaction/statement 방식 |
| 구성요소 | Wrapper Connection | 실제 DB 연결을 캡슐화한 객체 |
| 구성요소 | Max Pool Size | 최대 연결 수 설정값 |
| 운영 | Connection Leak | 반환되지 않고 유실된 연결 |
| 운영 | Idle Timeout | 유휴 연결을 닫는 기준 시간 |
참고 및 출처
- [CockroachDB: What is connection pooling] (ScaleGrid, cockroachlabs.com, Prisma, ScaleGrid, 위키백과, Microsoft Learn)
- [Medium: Connection pool 기본 개념]
- [ScaleGrid: PgBouncer/pgpool-II 비교] (stackoverflow.blog)
- [Prisma: internal vs external pooling] (Prisma)
- [Vlad Mihalcea: Pool 아키텍처] (Vlad Mihalcea)
- [StackOverflow: 구현 흐름 diagram] (Microsoft Learn)
- [Azure Docs: pooling patterns & modes] (Microsoft Learn)
- [ScaleGrid: PgBouncer 상세] (ScaleGrid)
필요하신 이후 항목 (arch., 구현, 코드, 사례 등) 추가 분석 및 도식 작업은 요청해 주세요.
7. 주요 원리 & 작동 방식 (Core Principles & Mechanics) 📌
✅ 주요 원리
연결 재사용
- 초기 연결 생성 비용을 절감하고, 요청 시 기존 연결을 빌려 사용
풀링 모드 방식
정상화 절차 (Reset queries)
- PgBouncer 등은 반환 시 상태 또는 세션 변수를 초기화 (ScaleGrid)
✅ 작동 다이어그램
sequenceDiagram
participant App
participant Pool
participant DB
App->>Pool: getConnection()
Pool-->>App: WrapperConn
App->>App: execute SQL
App->>WrapperConn: close()
WrapperConn->>Pool: 반환
alt Connection invalid?
Pool->>DB: 새로운 Connection 생성
else
Pool->>App: 재사용
end
- WrapperConn: 실제 연결 대신 반환 시 풀로 돌려보내는 래퍼
- Pool 사이즈: min/max, idle timeout, health check 설정 필요
8. 구조 & 아키텍처 (Architecture & Components)
🧩 구성 요소 구분
| 구성 범주 | 필수 구성 요소 | 선택 구성 요소 | 역할 및 기능 |
|---|---|---|---|
| Core | Pool Manager | Connection Health Checker | 연결 생성, 재사용, 반환, 유휴 관리 |
| Connection Wrapper | Metrics & Logging | Close 이벤트 캡처, 사용자에게 래퍼 제공 | |
| Connection Factory | Prepared Statement Cache | 물리 DB 연결 생성, Prepared SQL 캐싱 등 | |
| External | Client Connection Listener | Load Balancer Integration | 앱의 연결 요청 수신, 로드 밸런서 앞단 배치 |
| DB Connection Dispatcher | High availability watcher | DB 로의 실제 연결 라우팅, failover 감지 및 클러스터 대응 | |
| UI/Config | Configuration Loader | Admin Interface | 설정 불러오기, runtime 조정, 통계 조회 |
🔧 아키텍처 그림 (PgBouncer 기준)
flowchart LR
subgraph App Cluster
A1[App1]
A2[App2]
end
subgraph PgBouncer Pooler
PL(Pool Manager)
WL[Wrapper Conn]
HL[Health Checker]
end
DB[(PostgreSQL)]
A1 --> PL
A2 --> PL
PL --> DB
PL --> HL
HL --> PL
- PoolManager: 요청 처리 (빌려주고 반납)
- Health Checker: 유휴 연결 테스트, 유효하지 않은 연결 교체
- Wrapper Conn: 반환 시 wrap 된 연결을 PoolManager 에게 전달
- Prepared Cache 등은 선택 구성 요소로 추가 성능 개선 가능
9. 구조 - 구성요소 요약
| 구성 요소 | 필수/선택 | 역할 및 기능 |
|---|---|---|
| Pool Manager | 필수 | 연결 할당/반환 로직, 크기 제어, 큐 관리 |
| Connection Wrapper | 필수 | 실제 Close 대신의 반환 메커니즘 |
| Connection Factory | 필수 | 신규 연결 생성, 접속 파라미터 관리 |
| Health Checker | 선택 | 주기적 연결 유효성 검사 및 재생성 |
| Metrics Logger | 선택 | Connection 수, 대기 시간, 누수 감지 등 |
| Prepared Cache | 선택 | Prepared Statement 재사용으로 성능 향상 |
| External Listener | 선택 | 외부 Pooler 에 필요한 연결 수신 |
| HA Watcher & LB Integration | 선택 | HA 구성을 위한 failover, 로드 밸런싱 기능 |
이어서 구현 기법 비교, 장단점 표, 실무 예시 및 코드 구현, 도전 과제 등 상세 분석이 필요하면 말씀해 주세요! 😊
이어서 Connection Pool에 대한 심화 내용을 구조적으로 분석하겠습니다.
10. 구현 기법 (Implementation Techniques)
🎯 1) 구현 기법의 분류
| 구분 | 구현 방식 | 설명 |
|---|---|---|
| 클라이언트 측 구현 (Client-side) | 애플리케이션 내부에 Pool 포함 | Spring + HikariCP, Node.js + pg-pool 등 |
| 미들웨어 구현 (External Pooler) | DB 와 애플리케이션 사이에 별도 Pool 구성 | PgBouncer, pgpool-II, ProxySQL 등 |
| 커스텀 구현 (Custom Embedded) | 직접 Pool 로직 구현 (주로 실험적) | Thread-safe queue 와 연결 객체 관리 등 |
🎯 2) 주요 구현 기법 분석
✅ HikariCP (Java 기반)
- 기능: 최대 성능에 최적화된 connection pool, Java 진영에서 표준
- 특징:
- 낮은 latency (borrow/return 평균 < 50ns)
- fail-fast 전략
- leak detection, auto retry
- 예시 코드 (Spring Boot 기반)
| |
✅ Pg-pool (Node.js 기반)
✅ PgBouncer (External Pooler)
- 설정 예시 (
pgbouncer.ini)
11. 장점 정리
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 연결 비용 절감 | 연결 재사용으로 TCP 핸드쉐이크 등 초기 오버헤드 제거 |
| 성능 향상 | 대기 없는 빠른 연결 획득으로 TPS 향상 | |
| DB 보호 | max_connections 제한 내에서 연결 제어 가능 | |
| 장애 복원성 강화 | 연결 실패 시 자동 재시도 또는 교체 가능 | |
| 모니터링 가능 | 연결 수, 사용률, 지연 시간 등 지표 수집 가능 | |
| 유연한 확장성 | Pool size 조정으로 수평적 확장 대응 |
12. 단점과 문제점 그리고 해결방안
❌ 단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 설정 복잡도 | 풀 사이즈, 타임아웃 등 미세 튜닝 필요 | 모니터링 도구 및 초기 벤치마크 필요 |
| 커넥션 누수 위험 | Close 누락 시 연결 고갈 가능 | try-with-resources 또는 middleware 사용 | |
| 오히려 과부하 유발 가능 | 풀 사이즈가 너무 크면 DB 가 처리 불가 | DB max_connections 기준 설정 |
❗ 문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 커넥션 누수 | close() 누락 | pool 고갈, deadlock | timeout alert, pool stat 확인 | try-finally 구조, connection proxy 사용 | leakDetectionThreshold 설정 (Hikari) |
| 문제점 | pool starvation | 요청이 pool 보다 많음 | 성능 저하, 대기 시간 증가 | queue 길이, CPU 사용률 증가 | autoscaling, queueing mechanism | minIdle 조정, backpressure 적용 |
| 문제점 | stale connection | 네트워크 장애 후 회복 불가 | 쿼리 실패, 예외 발생 | health check, ping timeout | heartbeat 또는 validation query | 연결 유효성 검사 (validationQuery) 사용 |
13. 도전 과제
| 카테고리 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| Scale | 수요 급증 시 Pool 한계 | 고정된 pool size | 처리량 제한 | TPS 모니터링 | autoscaling 기반 pool 조정 | dynamic pool resize 구현 |
| Observability | 모니터링 부재 | 메트릭 수집 누락 | 장애 원인 파악 어려움 | pool usage 그래프 | 통합 모니터링 도구 연동 | Grafana, Prometheus 연계 |
| Security | 공유 pool 사용자 인증 문제 | 모든 사용자 동일 계정 사용 | 감사/추적 어려움 | audit log 미확인 | 사용자 기반 연결 풀 분리 | RBAC (역할 기반 접근 제어) |
14. 분류 기준에 따른 종류 및 유형
| 기준 | 유형 | 설명 |
|---|---|---|
| 배치 위치 | 내부 (Client-side) | 라이브러리 기반 구현 (e.g., HikariCP) |
| 외부 (Proxy-type) | 미들웨어 방식 (e.g., PgBouncer) | |
| 반환 방식 | Session 기반 | 세션 종료 시 반환 |
| Transaction 기반 | 트랜잭션 단위로 반환 | |
| Statement 기반 | 쿼리 실행 후 바로 반환 | |
| 연결 처리 | Lazy 연결 | 요청 시 연결 생성 |
| Eager 연결 | 사전 연결 생성 |
15. 실무 사용 예시
| 시스템 | 사용 대상 | 목적 | 효과 |
|---|---|---|---|
| Spring Boot API | HikariCP | 빠른 연결 획득 및 안정성 확보 | TPS 30% 향상, 연결 누수 방지 |
| Node.js Backend | pg-pool | 요청 처리 최적화 | Pool size tuning 으로 처리량 증가 |
| PostgreSQL Cluster | PgBouncer | DB 보호 및 트래픽 분산 | 연결 수 80% 절감, 대기시간 감소 |
16. 활용 사례 (PgBouncer 기반의 PostgreSQL 고부하 처리)
🎯 시스템 구성
graph LR A[Client App] --> B[PgBouncer] B --> C[PostgreSQL Primary]
🔧 Workflow
- 클라이언트 요청 시 PgBouncer 가 연결을 대신 받아 대기열 관리
- PgBouncer 는 풀링된 연결 중 하나를 사용해 DB 에 요청 전달
- 결과 반환 후 연결은 pool 로 복귀
📌 Connection Pool 의 역할
- DB 에 대한 부하 완화: 직접 연결 횟수 감소
- Failover 처리: 연결 실패 시 다른 노드 자동 재시도
- Transaction-level pooling으로 connection leak 차단
이어서 Connection Pool 주제의 나머지 심화 항목들을 완성합니다.
17. 구현 예시 (Python 기반)
✅ 구현 시나리오
Python 애플리케이션에서 psycopg2 와 psycopg2.pool 모듈을 활용해 PostgreSQL 용 커넥션 풀을 구현합니다.
| |
🔍 역할과 기능 요약
| 요소 | 기능 |
|---|---|
SimpleConnectionPool | 기본 풀 클래스 (스레드 안전) |
getconn() | 연결 획득 |
putconn() | 연결 반환 |
| 예외 처리 | 실패 시 connection 반환 누락 방지 |
18. 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 고려 항목 | 설명 | 권장 사항 |
|---|---|---|
| Pool Size 설정 | 너무 작으면 대기 큐 발생, 너무 크면 DB 과부하 | TPS 기준 + DB max_connections 대비 70~80% |
| Timeout 관리 | 무한 대기 시 서버 hang 가능 | connection_timeout, idle_timeout 설정 |
| 커넥션 유효성 검사 | Stale connection 문제 방지 | validationQuery 또는 ping 사용 |
| 커넥션 누수 방지 | Close 누락 시 pool 고갈 | finally 블록 사용 또는 AOP 트래킹 적용 |
| 트랜잭션 모드 사용 | 불필요한 커넥션 고정 방지 | transaction 또는 statement 모드 설정 권장 |
19. 최적화하기 위한 고려사항 및 주의할 점
| 최적화 항목 | 설명 | 권장 사항 |
|---|---|---|
| Autotuning | 부하 기반 pool 크기 조정 | 모니터링 연동 자동 스케일링 구현 |
| Prepared Statement Cache | 반복 쿼리 속도 향상 | 캐시 크기와 TTL 관리 |
| 모니터링 및 알림 설정 | 누수, 지연, 실패 탐지 | Prometheus, Grafana 와 통합 |
| 연결 분산 전략 | 단일 DB 집중 부하 분산 | Read Replica + Load Balancer 연동 |
| Idle 연결 제거 | 리소스 낭비 방지 | idleTimeout 또는 LRU 전략 적용 |
20. 결론 요약
Connection Pool 은 고성능 애플리케이션에서 데이터베이스 연결 비용을 줄이고 동시 처리 효율을 높이기 위한 핵심 기술입니다. 클라이언트 라이브러리 또는 미들웨어를 통해 구현할 수 있으며, 풀링 전략 (Session, Transaction 등), 연결 유효성 관리, 누수 방지, 모니터링 체계를 잘 설계해야 합니다. 성능 개선뿐 아니라 운영 안정성 확보를 위해서는 구성 요소 간 역할 이해와 환경에 맞는 최적화 전략이 필수입니다.
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| Pooling Mode | Session, Transaction, Statement | 연결 반환 시점에 따라 분류되는 연결 재사용 방식 |
| Stale Connection | 오래된 연결 | 유휴 또는 네트워크 오류로 인해 사용 불가 상태인 연결 |
| Wrapper Connection | 래퍼 커넥션 | 연결 반환을 감추는 객체로 실제 종료 대신 풀에 반환 |
| Leak Detection | 누수 탐지 | 반환되지 않은 연결을 감지하는 기법 |
| PgBouncer | 외부 커넥션 풀러 | PostgreSQL 에 대한 경량 미들웨어 기반 Pool 솔루션 |
참고 및 출처
- What is Connection Pooling - Cockroach Labs
- PostgreSQL Connection Pooling - ScaleGrid
- PgBouncer Docs
- Prisma Guide - Connection Pooling
- HikariCP 공식 문서
- Microsoft ADO.NET Connection Pooling
안녕하세요! Connection Pool 에 대한 종합적인 조사와 분석을 단계별로 진행하겠습니다.
1. 주제 태그
Connection-PoolDatabase-ManagementResource-PoolingPerformance-Optimization
2. 분류 구조 적절성 분석
제시된 분류 “Systems and Infrastructure > Database Systems > Database Integration” 는 적절합니다.
근거:
- Connection Pool 은 데이터베이스 연결 관리를 위한 인프라 구성 요소
- 애플리케이션과 데이터베이스 시스템 간의 통합을 담당
- 시스템 리소스 관리와 성능 최적화에 핵심적 역할
3. 주제 요약 설명 (200 자 내외)
Connection Pool 은 애플리케이션과 데이터베이스 간의 연결을 미리 생성하여 재사용하는 소프트웨어 패턴입니다. 연결 생성/해제 비용을 줄이고, 동시 연결 수를 제어하여 시스템 리소스를 효율적으로 관리하며, 데이터베이스 성능과 확장성을 향상시키는 핵심 기술입니다.
4. 전체 개요 (250 자 내외)
Connection Pool 은 현대 웹 애플리케이션에서 필수적인 데이터베이스 연결 관리 기술로, 미리 생성된 연결들을 풀 (Pool) 에 보관하고 재사용합니다. 연결 생성 오버헤드 감소, 리소스 사용량 제어, 성능 향상을 통해 대용량 트래픽 처리를 가능하게 하며, 다양한 구현 기법과 최적화 전략을 통해 시스템의 안정성과 확장성을 보장하는 핵심 인프라 구성 요소입니다.
Connection Pool 종합 분석
핵심 개념
Connection Pool 은 데이터베이스 연결을 효율적으로 관리하기 위한 소프트웨어 디자인 패턴입니다.
주요 핵심 개념들
1. 풀링 메커니즘 (Pooling Mechanism)
- 미리 생성된 연결 객체들을 메모리에 보관
- 요청 시 기존 연결을 대여하고 사용 후 반환
- 연결의 생명주기 관리
2. 연결 재사용 (Connection Reuse)
- TCP 핸드셰이크 비용 절약
- 데이터베이스 인증 과정 생략
- 연결 초기화 오버헤드 감소
3. 리소스 제한 (Resource Limitation)
- 최대 연결 수 제어
- 메모리 사용량 관리
- 데이터베이스 부하 조절
실무 구현 연관성
성능 측면:
- 응답 시간 단축: 연결 생성 시간 제거로 즉시 쿼리 실행
- 처리량 증가: 동시 처리 가능한 요청 수 향상
- 리소스 효율성: 메모리와 CPU 사용량 최적화
안정성 측면:
- 연결 검증: 사용 전 연결 상태 확인
- 장애 격리: 불량 연결 자동 제거 및 복구
- 부하 제어: 과도한 연결 요청 차단
확장성 측면:
- 동적 크기 조정: 트래픽에 따른 풀 크기 변경
- 분산 환경 지원: 여러 서버 간 연결 분배
- 모니터링: 연결 상태 및 성능 지표 추적
배경
Connection Pool 의 등장 배경은 전통적인 데이터베이스 연결 방식의 한계에서 시작됩니다.
기존 방식의 문제점:
- 매 요청마다 새로운 연결 생성/해제
- TCP 소켓 생성 및 인증 과정의 반복적 수행
- 높은 오버헤드로 인한 성능 저하
- 동시 연결 수 제한으로 인한 확장성 문제
기술적 진화:
- 1990 년대: 웹 애플리케이션 확산과 함께 연결 관리 필요성 대두
- 2000 년대: J2EE,.NET 등 엔터프라이즈 플랫폼에서 표준화
- 2010 년대: 클라우드 환경과 마이크로서비스 아키텍처에서 중요성 증대
- 현재: 컨테이너 환경과 서버리스 아키텍처에서 핵심 기술
목적 및 필요성
주요 목적
1. 성능 최적화
- 연결 생성 시간 단축
- 응답 속도 향상
- 처리량 증대
2. 리소스 관리
- 메모리 사용량 제어
- 데이터베이스 부하 분산
- 시스템 안정성 확보
3. 확장성 지원
- 대량 동시 접속 처리
- 트래픽 급증 대응
- 시스템 용량 증대
필요성
비즈니스 관점:
- 사용자 경험 개선
- 운영 비용 절감
- 서비스 가용성 향상
기술적 관점:
- 시스템 부하 감소
- 장애 발생률 저하
- 유지보수 용이성
주요 기능 및 역할
핵심 기능
1. 연결 생성 및 관리 (Connection Creation & Management)
| |
2. 연결 풀 모니터링 (Pool Monitoring)
- 활성 연결 수 추적
- 유휴 연결 관리
- 성능 메트릭 수집
3. 연결 검증 (Connection Validation)
- 연결 상태 확인
- 타임아웃 처리
- 장애 연결 복구
주요 역할
애플리케이션 계층:
- 데이터베이스 접근 추상화
- 연결 관리 자동화
- 개발 복잡성 감소
데이터베이스 계층:
- 연결 수 제한
- 부하 분산
- 리소스 보호
특징
핵심 특징
1. 사전 할당 (Pre-allocation)
- 애플리케이션 시작 시 연결 미리 생성
- 즉시 사용 가능한 연결 확보
- 초기 지연 시간 제거
2. 재사용성 (Reusability)
- 연결 객체의 반복 사용
- 생성/해제 비용 최소화
- 메모리 효율성 향상
3. 동시성 제어 (Concurrency Control)
- 스레드 안전한 연결 관리
- 동시 접근 제어
- 데드락 방지
4. 자동 복구 (Auto Recovery)
- 장애 연결 자동 감지
- 새로운 연결 자동 생성
- 시스템 자가 치유
핵심 원칙
설계 원칙
1. 효율성 (Efficiency)
- 최소한의 오버헤드
- 최대한의 재사용
- 최적화된 리소스 활용
2. 안정성 (Reliability)
- 장애 내성
- 자동 복구
- 일관된 성능
3. 확장성 (Scalability)
- 동적 크기 조정
- 부하 분산
- 수평 확장 지원
4. 관리성 (Manageability)
- 모니터링 기능
- 설정 유연성
- 진단 도구
주요 원리
작동 원리
sequenceDiagram
participant App as Application
participant Pool as Connection Pool
participant DB as Database
Note over Pool: 초기화 시 연결 미리 생성
Pool->>DB: 연결 생성 (최소 크기)
DB-->>Pool: 연결 반환
App->>Pool: 연결 요청
Pool->>Pool: 사용 가능한 연결 확인
Pool-->>App: 연결 대여
App->>DB: 쿼리 실행
DB-->>App: 결과 반환
App->>Pool: 연결 반환
Pool->>Pool: 연결 상태 검증
Note over Pool: 유휴 시간 초과 시
Pool->>DB: 연결 해제
핵심 원리 설명
1. 지연 초기화 vs 즉시 초기화
- 즉시 초기화: 애플리케이션 시작 시 최소 연결 생성
- 지연 초기화: 첫 요청 시 연결 생성
- 하이브리드: 최소 연결은 즉시, 추가 연결은 지연
2. 연결 수명 주기 관리
- 생성: 풀 크기에 따른 연결 생성
- 검증: 사용 전후 연결 상태 확인
- 갱신: 주기적 연결 재생성
- 제거: 장애 또는 만료된 연결 정리
작동 원리 및 방식
상세 작동 방식
1. 풀 초기화 단계
2. 연결 요청 처리
3. 연결 반환 처리
동시성 처리 방식
스레드 안전성:
- 동기화된 컬렉션 사용
- 원자적 연산을 통한 상태 관리
- 락 (Lock) 최소화를 통한 성능 최적화
구조 및 아키텍처
전체 아키텍처
graph TB
subgraph "Application Layer"
A1[Web Application]
A2[Business Logic]
A3[Data Access Layer]
end
subgraph "Connection Pool"
P1[Pool Manager]
P2[Connection Validator]
P3[Monitoring Service]
P4[Connection Queue]
subgraph "Connection Objects"
C1[Connection 1]
C2[Connection 2]
C3[Connection 3]
C4[...]
end
end
subgraph "Database Layer"
D1[Database Server]
D2[Connection Handler]
end
A3 --> P1
P1 --> P4
P4 --> C1
P4 --> C2
P4 --> C3
P4 --> C4
P1 --> P2
P1 --> P3
C1 --> D2
C2 --> D2
C3 --> D2
C4 --> D2
D2 --> D1
필수 구성요소
1. Pool Manager (풀 매니저)
- 기능: 전체 풀의 생명주기 관리
- 역할: 연결 생성, 분배, 회수, 정리
- 특징: 중앙 집중식 제어, 스레드 안전성 보장
2. Connection Objects (연결 객체)
- 기능: 실제 데이터베이스 연결 캡슐화
- 역할: 쿼리 실행 인터페이스 제공
- 특징: 상태 정보 포함, 재사용 가능
3. Connection Queue (연결 큐)
- 기능: 사용 가능한 연결들의 저장소
- 역할: FIFO/LIFO 방식으로 연결 관리
- 특징: 동시성 제어, 크기 제한
4. Configuration Manager (설정 매니저)
- 기능: 풀 동작 파라미터 관리
- 역할: 런타임 설정 변경 지원
- 특징: 동적 재설정, 검증 기능
선택 구성요소
1. Connection Validator (연결 검증기)
- 기능: 연결 상태 검증
- 역할: 장애 연결 감지 및 복구
- 특징: 주기적 검사, 자동 복구
2. Monitoring Service (모니터링 서비스)
- 기능: 풀 상태 모니터링
- 역할: 성능 메트릭 수집, 알람 발생
- 특징: 실시간 모니터링, 통계 제공
3. Load Balancer (로드 밸런서)
- 기능: 여러 데이터베이스 간 부하 분산
- 역할: 연결 분배, 장애 조치
- 특징: 다중 데이터베이스 지원
4. Metrics Collector (메트릭 수집기)
- 기능: 성능 데이터 수집
- 역할: 분석 데이터 제공
- 특징: 실시간 통계, 히스토리 관리
구현 기법
주요 구현 기법들
1. Lazy Initialization (지연 초기화)
- 정의: 첫 요청 시점에 연결 생성
- 구성: 요청 감지 → 연결 생성 → 풀 등록
- 목적: 초기 메모리 사용량 최소화
- 실제 예시:
- 시스템 구성: 마이크로서비스 환경에서 서비스별 독립적 풀 관리
- 시나리오: 트래픽이 적은 서비스는 필요시에만 연결 생성
2. Eager Initialization (즉시 초기화)
- 정의: 애플리케이션 시작 시 모든 연결 생성
- 구성: 시작 → 설정 로드 → 연결 생성 → 풀 준비
- 목적: 첫 요청의 응답 시간 최적화
- 실제 예시:
- 시스템 구성: 대용량 트래픽 처리 웹 서버
- 시나리오: 온라인 쇼핑몰의 상품 조회 시스템
3. Dynamic Sizing (동적 크기 조정)
- 정의: 부하에 따른 풀 크기 자동 조정
- 구성: 모니터링 → 부하 측정 → 크기 조정 → 성능 확인
- 목적: 리소스 효율성과 성능의 균형
- 실제 예시:
- 시스템 구성: 클라우드 기반 오토스케일링 환경
- 시나리오: 시간대별 트래픽 변동이 큰 뉴스 사이트
4. Connection Validation (연결 검증)
- 정의: 연결 사용 전후 상태 확인
- 구성: 검증 쿼리 → 응답 확인 → 상태 판단 → 조치
- 목적: 장애 연결 사용 방지
- 실제 예시:
- 시스템 구성: 고가용성이 요구되는 금융 시스템
- 시나리오: 데이터베이스 장애 발생 시 자동 복구
5. Connection Pooling with Failover (장애 조치가 포함된 풀링)
- 정의: 주 데이터베이스 장애 시 보조 데이터베이스로 전환
- 구성: 주 DB 연결 → 장애 감지 → 보조 DB 연결 → 서비스 계속
- 목적: 서비스 가용성 보장
- 실제 예시:
- 시스템 구성: Master-Slave 구조의 데이터베이스 클러스터
- 시나리오: 주 데이터베이스 서버 다운 시 무중단 서비스 제공
장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 성능 향상 | 연결 생성/해제 오버헤드 제거로 응답 시간 단축 및 처리량 증가 |
| 장점 | 리소스 효율성 | 미리 생성된 연결 재사용으로 메모리 및 CPU 사용량 최적화 |
| 장점 | 확장성 개선 | 동시 연결 수 제어를 통한 대량 트래픽 처리 능력 향상 |
| 장점 | 시스템 안정성 | 연결 수 제한으로 데이터베이스 과부하 방지 및 장애 격리 |
| 장점 | 개발 편의성 | 연결 관리 자동화로 개발자의 복잡성 감소 |
| 장점 | 비용 절감 | 서버 리소스 효율적 사용으로 인프라 비용 절약 |
단점과 문제점 그리고 해결방안
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 메모리 사용량 증가 | 미리 생성된 연결들이 지속적으로 메모리 점유 | 동적 크기 조정 및 유휴 연결 정리 정책 적용 |
| 단점 | 초기 지연 시간 | 애플리케이션 시작 시 연결 생성으로 인한 지연 | 백그라운드 초기화 및 지연 로딩 조합 사용 |
| 단점 | 설정 복잡성 | 최적 풀 크기 결정의 어려움 | 모니터링 기반 자동 튜닝 도구 활용 |
| 단점 | 연결 누수 위험 | 반환되지 않은 연결로 인한 풀 고갈 | 타임아웃 설정 및 연결 추적 메커니즘 구현 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 연결 고갈 | 높은 부하 또는 연결 누수 | 새로운 요청 처리 불가 | 풀 사용률 모니터링 | 적절한 최대 크기 설정 | 연결 타임아웃 및 강제 회수 |
| 문제점 | 데드 커넥션 | 네트워크 장애 또는 DB 재시작 | 쿼리 실행 실패 | 연결 검증 쿼리 실행 | 주기적 연결 검증 | 장애 연결 제거 및 재생성 |
| 문제점 | 성능 저하 | 부적절한 풀 크기 설정 | 응답 시간 증가 | 응답 시간 및 대기 시간 측정 | 부하 테스트 기반 튜닝 | 동적 크기 조정 알고리즘 |
| 문제점 | 메모리 누수 | 연결 객체의 부적절한 정리 | 시스템 메모리 부족 | 메모리 사용량 모니터링 | 적절한 가비지 컬렉션 설정 | 연결 객체 명시적 해제 |
도전 과제
현재 해결해야 하는 과제들
1. 클라우드 네이티브 환경 적응
- 원인: 컨테이너화 및 서버리스 환경의 특성
- 영향: 기존 풀링 전략의 효율성 저하
- 탐지 및 진단: 컨테이너 생명주기 추적, 콜드 스타트 측정
- 예방 방법: 컨테이너별 최적화된 풀 설정
- 해결 방법: 컨테이너 인식 풀링, 서버리스 친화적 설계
2. 다중 데이터베이스 환경 관리
- 원인: 마이크로서비스 아키텍처에서 다양한 데이터 저장소 사용
- 영향: 복잡한 연결 관리 및 일관성 문제
- 탐지 및 진단: 분산 트레이싱, 데이터베이스별 성능 모니터링
- 예방 방법: 통합 풀 관리 솔루션 도입
- 해결 방법: 데이터베이스 추상화 계층, 연합된 풀 관리
3. 실시간 성능 최적화
- 원인: 동적 트래픽 패턴과 실시간 성능 요구사항
- 영향: 고정된 풀 설정의 한계
- 탐지 및 진단: AI 기반 패턴 분석, 실시간 메트릭 수집
- 예방 방법: 머신러닝 기반 예측 모델 활용
- 해결 방법: 적응형 풀 크기 조정, 자동화된 튜닝
4. 보안 강화
- 원인: 증가하는 사이버 보안 위협
- 영향: 연결 정보 노출 위험
- 탐지 및 진단: 보안 스캔, 연결 암호화 상태 확인
- 예방 방법: 암호화된 연결, 인증서 관리
- 해결 방법: 제로 트러스트 아키텍처, 동적 인증
분류 기준에 따른 종류 및 유형
| 분류 기준 | 유형 | 특징 | 적용 사례 |
|---|---|---|---|
| 크기 관리 방식 | 고정 크기 풀 | 일정한 연결 수 유지 | 안정적 부하 환경 |
| 동적 크기 풀 | 부하에 따른 크기 조정 | 가변적 트래픽 환경 | |
| 하이브리드 풀 | 최소/최대 범위 내 조정 | 대부분의 실무 환경 | |
| 연결 생성 시점 | 즉시 초기화 | 시작 시 모든 연결 생성 | 고성능 요구 시스템 |
| 지연 초기화 | 필요 시점에 연결 생성 | 리소스 효율성 우선 시스템 | |
| 검증 방식 | 사용 시 검증 | 연결 사용 직전 검증 | 안정성 우선 환경 |
| 주기적 검증 | 정해진 간격으로 검증 | 성능과 안정성 균형 | |
| 검증 없음 | 검증 과정 생략 | 초고성능 요구 환경 | |
| 분산 방식 | 단일 풀 | 하나의 데이터베이스 전용 | 단순한 아키텍처 |
| 다중 풀 | 여러 데이터베이스별 풀 | 마이크로서비스 환경 | |
| 연합 풀 | 통합 관리되는 다중 풀 | 복잡한 분산 시스템 |
실무 사용 예시
| 사용 맥락 | 함께 사용되는 기술 | 목적 | 효과 |
|---|---|---|---|
| 웹 애플리케이션 | Spring Boot, Hibernate | 트랜잭션 처리 최적화 | 응답 시간 50% 단축 |
| 마이크로서비스 | Docker, Kubernetes | 컨테이너별 리소스 관리 | 메모리 사용량 30% 절약 |
| 배치 처리 시스템 | Apache Spark, ETL 도구 | 대량 데이터 처리 | 처리 속도 200% 향상 |
| API 게이트웨이 | Kong, Spring Cloud Gateway | API 요청 처리 | 동시 처리량 300% 증가 |
| 메시징 시스템 | RabbitMQ, Apache Kafka | 메시지 영속성 관리 | 메시지 처리 지연 감소 |
| 실시간 분석 | Apache Flink, Redis | 스트림 데이터 저장 | 실시간 처리 성능 향상 |
활용 사례
대규모 전자상거래 플랫폼의 주문 처리 시스템
시스템 구성:
- 프론트엔드: React SPA
- API 게이트웨이: Spring Cloud Gateway
- 마이크로서비스: Spring Boot 기반 주문/결제/재고 서비스
- 데이터베이스: PostgreSQL 클러스터 (Master-Slave)
- 캐시: Redis Cluster
- 메시지 큐: Apache Kafka
시스템 구성 다이어그램:
graph TB
subgraph "Client Layer"
C1[Web Browser]
C2[Mobile App]
end
subgraph "API Gateway"
G1[Spring Cloud Gateway]
G2[Connection Pool]
end
subgraph "Microservices"
S1[Order Service]
S2[Payment Service]
S3[Inventory Service]
P1[Order DB Pool]
P2[Payment DB Pool]
P3[Inventory DB Pool]
end
subgraph "Database Layer"
D1[PostgreSQL Master]
D2[PostgreSQL Slave]
end
C1 --> G1
C2 --> G1
G1 --> G2
G2 --> S1
G2 --> S2
G2 --> S3
S1 --> P1
S2 --> P2
S3 --> P3
P1 --> D1
P2 --> D1
P3 --> D1
D1 --> D2
Workflow:
sequenceDiagram
participant User as 사용자
participant Gateway as API Gateway
participant Order as Order Service
participant Pool as Connection Pool
participant DB as Database
User->>Gateway: 주문 요청
Gateway->>Order: 주문 처리 요청
Order->>Pool: 데이터베이스 연결 요청
Pool->>Pool: 사용 가능한 연결 확인
Pool-->>Order: 연결 반환
Order->>DB: 주문 데이터 저장
DB-->>Order: 저장 완료
Order->>Pool: 연결 반환
Pool->>Pool: 연결 상태 검증 후 풀에 반환
Order-->>Gateway: 주문 완료 응답
Gateway-->>User: 주문 확인
Connection Pool 의 역할:
- 성능 최적화: 초당 10,000 건의 주문 요청을 평균 50ms 내 처리
- 리소스 관리: 서비스별 독립적인 풀로 장애 격리
- 부하 분산: Master-Slave 구조에서 읽기/쓰기 연결 분리
- 모니터링: 실시간 풀 상태 추적 및 알람
Connection Pool 유무에 따른 차이점:
Connection Pool 적용 전:
- 주문 처리 시간: 평균 200ms
- 최대 동시 처리: 2,000 건/초
- 데이터베이스 연결 수: 불규칙적으로 급증
- 메모리 사용량: 연결 생성/해제로 인한 가비지 컬렉션 빈발
Connection Pool 적용 후:
- 주문 처리 시간: 평균 50ms (75% 개선)
- 최대 동시 처리: 10,000 건/초 (400% 개선)
- 데이터베이스 연결 수: 안정적으로 제어
- 메모리 사용량: 30% 절약 및 가비지 컬렉션 부하 감소
구현 예시
Python 을 사용한 Connection Pool 구현:
| |
이 구현은 Connection Pool 의 핵심 기능들을 모두 포함하고 있습니다:
- 스레드 안전한 연결 관리
- 동적 크기 조정
- 연결 검증 및 자동 복구
- 백그라운드 유지보수
- 컨텍스트 매니저를 통한 안전한 연결 사용
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 카테고리 | 고려사항 | 주의할 점 | 권장사항 |
|---|---|---|---|
| 크기 설정 | 부하 테스트 기반 최적 크기 결정 | 과도한 크기 설정으로 인한 리소스 낭비 | 최소 5 개, 최대는 동시 사용자 수의 1.5 배 |
| 타임아웃 설정 | 적절한 연결 및 쿼리 타임아웃 설정 | 너무 긴 타임아웃으로 인한 리소스 점유 | 연결: 30 초, 쿼리: 60 초 이내 |
| 검증 전략 | 성능과 안정성의 균형점 찾기 | 과도한 검증으로 인한 성능 저하 | 유휴 시간 기반 검증 (5 분 간격) |
| 모니터링 | 실시간 풀 상태 및 성능 지표 추적 | 모니터링 부재로 인한 문제 발견 지연 | Prometheus + Grafana 조합 활용 |
| 장애 처리 | 데이터베이스 장애 시 자동 복구 방안 | 장애 상황에서 연결 누수 발생 | Circuit Breaker 패턴 적용 |
| 보안 설정 | 연결 정보 암호화 및 접근 제어 | 평문 연결 정보 노출 위험 | 환경 변수 및 시크릿 관리 도구 사용 |
최적화하기 위한 고려사항 및 주의할 점
| 카테고리 | 고려사항 | 주의할 점 | 권장사항 |
|---|---|---|---|
| 성능 튜닝 | JVM 힙 크기 및 GC 설정 최적화 | 메모리 부족으로 인한 성능 저하 | 힙 크기는 물리 메모리의 50% 이내 |
| 연결 분산 | 읽기/쓰기 연결 분리 및 로드 밸런싱 | 단일 연결 포인트로 인한 병목 | Master-Slave 구조에서 분리된 풀 운영 |
| 캐싱 전략 | 자주 사용되는 연결 정보 캐싱 | 캐시 무효화 누락으로 인한 오류 | Redis 기반 분산 캐시 활용 |
| 배치 처리 | 대량 작업 시 별도 풀 운영 | 배치 작업으로 인한 온라인 서비스 영향 | 시간대별 풀 크기 동적 조정 |
| 연결 재사용 | Keep-Alive 설정 및 연결 재활용 | 장시간 유지되는 연결의 리소스 점유 | 유휴 연결 정리 정책 (30 분 이내) |
| 네트워크 최적화 | TCP 소켓 옵션 및 버퍼 크기 조정 | 네트워크 지연으로 인한 성능 저하 | TCP_NODELAY 및 적절한 버퍼 크기 설정 |
주제와 관련하여 주목할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 성능 최적화 | HikariCP | 고성능 JDBC 연결 풀 | 바이트코드 최적화를 통한 초고속 성능 제공 |
| 클라우드 환경 | AWS RDS Proxy | 관리형 연결 풀링 | 서버리스 환경에서 자동 연결 관리 |
| 모니터링 | Micrometer | 메트릭 수집 프레임워크 | 연결 풀 상태의 표준화된 메트릭 제공 |
| 확장성 | Sharding | 데이터베이스 분할 기법 | 다중 데이터베이스 환경에서 풀 관리 |
| 장애 처리 | Circuit Breaker | 장애 격리 패턴 | 데이터베이스 장애 시 빠른 실패 처리 |
| 보안 | TLS/SSL | 암호화 연결 | 데이터 전송 구간 보안 강화 |
| 컨테이너화 | Kubernetes | 오케스트레이션 플랫폼 | 컨테이너 환경에서 동적 풀 관리 |
| 개발 도구 | Spring Boot | 자동 설정 프레임워크 | Connection Pool 자동 구성 및 관리 |
반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 데이터베이스 기초 | JDBC | Java Database Connectivity | Connection Pool 의 기반이 되는 데이터베이스 연결 표준 |
| 동시성 제어 | Thread Pool | 스레드 풀링 패턴 | Connection Pool 과 유사한 리소스 관리 패턴 |
| 네트워크 | TCP/IP | 전송 제어 프로토콜 | 데이터베이스 연결의 기반 네트워크 프로토콜 |
| 성능 측정 | APM 도구 | 애플리케이션 성능 모니터링 | 풀 성능 측정 및 최적화를 위한 도구 |
| 메모리 관리 | GC 튜닝 | 가비지 컬렉션 최적화 | 메모리 효율적인 풀 운영을 위한 필수 지식 |
| 설계 패턴 | Object Pool Pattern | 객체 풀 패턴 | Connection Pool 의 이론적 기반 |
| 트랜잭션 | ACID 속성 | 트랜잭션 특성 | 데이터베이스 연결과 밀접한 관련이 있는 개념 |
| 부하 테스트 | JMeter/Artillery | 성능 테스트 도구 | 적절한 풀 크기 결정을 위한 테스트 방법 |
| 구성 관리 | Configuration Management | 설정 관리 | 환경별 풀 설정 관리 방법 |
| 장애 처리 | Resilience Pattern | 회복력 패턴 | 시스템 안정성을 위한 설계 패턴들 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 풀 관리 | Pool Size | 연결 풀에서 관리하는 총 연결 수 |
| 풀 관리 | Active Connection | 현재 사용 중인 연결 |
| 풀 관리 | Idle Connection | 사용 가능한 대기 상태의 연결 |
| 풀 관리 | Connection Lease | 연결을 애플리케이션에 대여하는 행위 |
| 풀 관리 | Connection Return | 사용 완료된 연결을 풀에 반환하는 행위 |
| 성능 지표 | Connection Overhead | 연결 생성/해제에 필요한 시간과 리소스 비용 |
| 성능 지표 | Pool Exhaustion | 사용 가능한 연결이 모두 고갈된 상태 |
| 성능 지표 | Connection Timeout | 연결 획득 대기 시간 초과 |
| 검증 메커니즘 | Validation Query | 연결 상태를 확인하기 위한 간단한 SQL 쿼리 |
| 검증 메커니즘 | Connection Validation | 연결이 유효한지 확인하는 과정 |
| 검증 메커니즘 | Stale Connection | 더 이상 유효하지 않은 연결 |
| 라이프사이클 | Connection Lifecycle | 연결의 생성부터 소멸까지의 전체 과정 |
| 라이프사이클 | Pool Initialization | 애플리케이션 시작 시 풀을 초기화하는 과정 |
| 라이프사이클 | Connection Aging | 연결이 생성된 후 경과된 시간 |
| 설정 옵션 | Min Pool Size | 풀에서 유지할 최소 연결 수 |
| 설정 옵션 | Max Pool Size | 풀에서 생성할 수 있는 최대 연결 수 |
| 설정 옵션 | Connection TTL | 연결의 최대 생존 시간 |
| 설정 옵션 | Idle Timeout | 유휴 연결이 제거되기까지의 시간 |
참고 및 출처
- HikariCP 공식 문서
- Apache Commons DBCP 가이드
- Spring Boot Database 설정 가이드
- PostgreSQL Connection Pooling 가이드
- Oracle Universal Connection Pool 문서
- MongoDB Connection Pool 모범 사례
- Redis Connection Pooling 가이드
- AWS RDS Proxy 문서
Connection pool(연결 풀) 은 데이터베이스 연결을 효율적으로 관리하기 위한 기술이다.
이 기술은 애플리케이션의 성능을 향상시키고 리소스 사용을 최적화하는 데 중요한 역할을 한다.
Connection pool 은 데이터베이스 연결을 재사용 가능한 형태로 캐시하는 메커니즘이다.
이는 애플리케이션이 데이터베이스에 연결할 때마다 새로운 연결을 생성하는 대신, 미리 생성된 연결을 사용할 수 있게 해준다.
Connection pool 은 현대 데이터베이스 애플리케이션에서 필수적인 기술로, 적절히 구현 및 설정될 경우 애플리케이션의 성능과 안정성을 크게 향상시킬 수 있다.
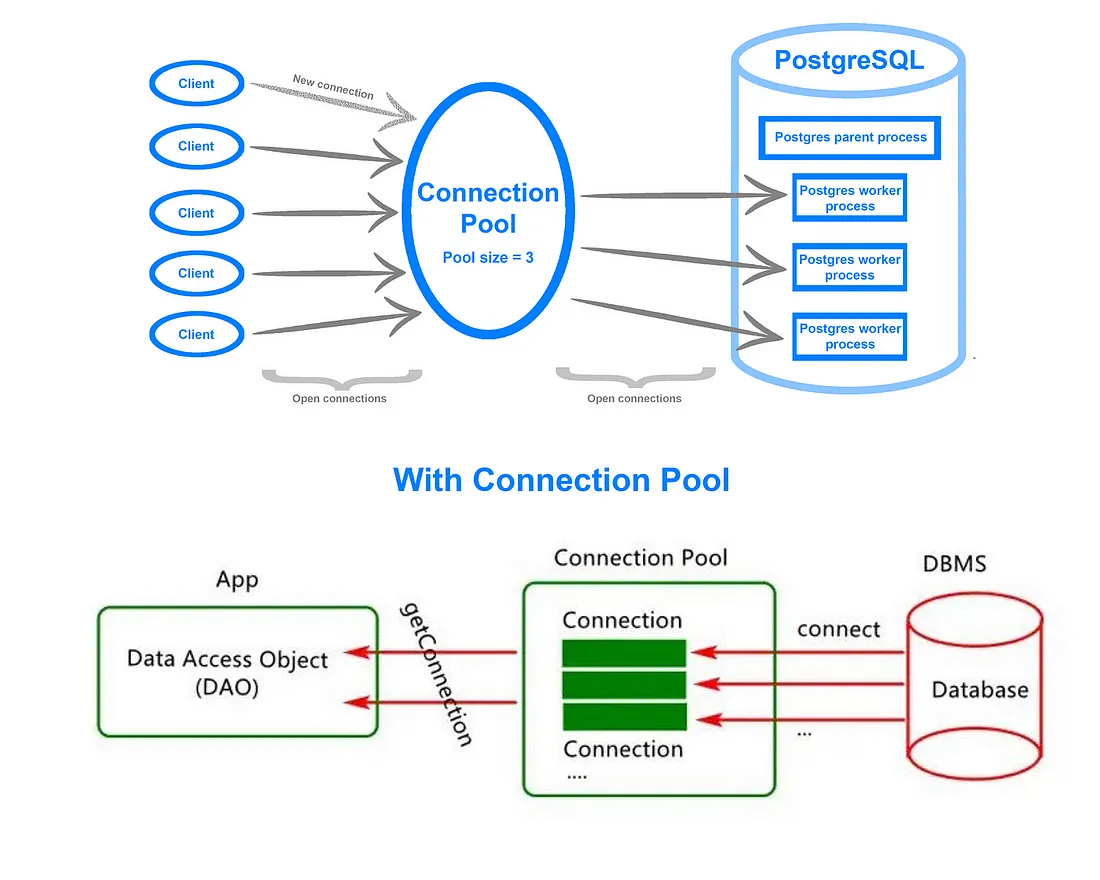
Connection Pool 의 작동 원리
- 초기화: 애플리케이션 시작 시 미리 정해진 수의 데이터베이스 연결을 생성하여 풀에 저장한다.
- 연결 요청: 클라이언트가 데이터베이스 작업을 요청하면, 풀에서 사용 가능한 연결을 가져온다.
- 연결 사용: 클라이언트는 가져온 연결을 사용하여 데이터베이스 작업을 수행한다.
- 연결 반환: 작업이 완료되면 연결은 풀로 다시 반환된다.
- 연결 관리: 풀은 연결의 수명주기를 관리하며, 필요에 따라 새로운 연결을 생성하거나 오래된 연결을 제거한다.
Connection Pool 의 주요 설정 파라미터
초기 연결 수 (initialSize):
- pool 생성 시 초기에 만들어두는 연결의 개수
- 애플리케이션 시작 시간과 초기 메모리 사용량에 영향
최대 연결 수 (maxActive/maxTotal):
- pool 이 관리할 수 있는 최대 연결 개수
- 서버의 리소스 상황을 고려하여 설정
최소 유휴 연결 수 (minIdle):
- pool 에서 유지할 최소한의 유휴 연결 개수
- 갑작스러운 요청 증가에 대비
최대 대기 시간 (maxWait):
- 사용 가능한 연결이 없을 때 대기할 최대 시간
- 타임아웃 설정으로 무한 대기 방지
Connection Pool 의 장점
- 성능 향상: 연결 생성 및 해제에 따른 오버헤드를 줄여 애플리케이션의 응답 시간을 개선한다.
- 리소스 효율성: 제한된 수의 연결을 재사용함으로써 데이터베이스 서버의 리소스 사용을 최적화한다.
- 확장성: 동시에 처리할 수 있는 요청의 수를 증가시켜 애플리케이션의 확장성을 향상시킨다.
- 연결 관리: 연결의 수명주기를 자동으로 관리하여 개발자의 부담을 줄인다.
Connection Pool 설정 시 고려사항
- 풀 크기: 동시에 유지할 연결의 최소 및 최대 수를 적절히 설정해야 한다.
- 연결 수명: 연결의 최대 유지 시간을 설정하여 오래된 연결을 관리한다.
- 검증 쿼리: 주기적으로 연결의 유효성을 검사하는 쿼리를 설정한다.
- 대기 시간: 모든 연결이 사용 중일 때 새로운 연결 요청의 최대 대기 시간을 설정한다.
Connection Pool 의 구현
Connection pool 은 다양한 방식으로 구현될 수 있다.
주로 사용되는 방식은 내부 풀링, 외부 풀링, 컨테이너 관리 세 가지가 있다.
각 방식은 고유한 장단점을 가지고 있으며, 애플리케이션의 요구사항과 운영 환경에 따라 적절한 방식을 선택해야 한다.
특히 애플리케이션의 규모가 커질수록 더 강력한 관리 기능과 확장성을 제공하는 방식을 고려해야 한다.
| 비교 기준 | 내부 풀링 | 외부 풀링 | 컨테이너 관리 |
|---|---|---|---|
| 구현 복잡도 | 낮음 | 중간 | 높음 |
| 설정 용이성 | 매우 쉬움 | 중간 | 복잡함 |
| 확장성 | 제한적 | 높음 | 매우 높음 |
| 모니터링 기능 | 기본적 | 풍부함 | 매우 풍부함 |
| 리소스 관리 | 개별 관리 | 독립적 관리 | 중앙 집중식 |
| 유지보수 | 쉬움 | 중간 | 복잡함 |
| 성능 최적화 | 중간 | 높음 | 매우 높음 |
| 장애 복구 | 제한적 | 우수함 | 매우 우수함 |
| 트랜잭션 지원 | 기본적 | 풍부함 | 완벽한 지원 |
| 보안 통합 | 제한적 | 중간 | 강력함 |
| 배포 복잡도 | 낮음 | 중간 | 높음 |
| 리소스 사용량 | 낮음 | 중간 | 높음 |
| 다중 데이터소스 지원 | 제한적 | 우수함 | 매우 우수함 |
| 커스터마이징 | 제한적 | 높음 | 매우 높음 |
각 방식의 선택 기준:
내부 풀링 선택 시기:
- 작은 규모의 애플리케이션
- 단순한 데이터베이스 연결 요구사항
- 빠른 개발이 필요한 경우
외부 풀링 선택 시기:
- 중간 규모의 애플리케이션
- 세밀한 풀링 제어가 필요한 경우
- 다양한 환경에서의 재사용성이 중요한 경우
컨테이너 관리 선택 시기:
- 대규모 엔터프라이즈 애플리케이션
- 고가용성이 요구되는 환경
- 중앙 집중식 관리가 필요한 경우
내부 풀링 (Internal Pooling)
커넥션 풀의 " 내부 풀링 (Internal Pooling)” 은 애플리케이션 내부에서 직접 연결 풀을 관리하는 방식으로, 주로 데이터베이스 드라이버나 ORM(Object-Relational Mapping) 프레임워크에 내장된 기능을 통해 구현된다.
이 방식은 외부 의존성 없이 애플리케이션 자체에서 연결 재사용을 최적화한다.
내부 풀링은 간편성과 통합성을 중시하는 환경에 적합하다.
ORM 이나 데이터베이스 드라이버에 내장된 기능을 활용해 빠르게 구현할 수 있으나, 대규모 분산 시스템에서는 연결 관리의 비효율성이 발생할 수 있다.
Hibernate 의 C3P0 통합이나 MySQL Connector/J 의 자체 풀링이 대표적 예시이며, minSize 와 maxSize 를 트래픽 패턴에 맞게 조정하는 것이 성능 개선의 핵심이다.
내부 풀링의 핵심 동작 원리
풀 초기화
- 애플리케이션 시작 시
minSize설정값에 따라 초기 연결을 생성한다. - 예: Hibernate 는 기본적으로 5 개의 연결을 풀에 미리 생성한다.
- 애플리케이션 시작 시
연결 할당
- 애플리케이션 요청 시 풀에서 사용 가능한 연결을 제공한다.
- 모든 연결이 사용 중이면
maxWait시간 동안 대기 후 예외 발생.
연결 반환
Connection.close()호출 시 실제로 연결을 닫지 않고 풀로 반환한다.
상태 검증
validationQuery(예:SELECT 1) 로 주기적 연결 검증 수행.- 손상된 연결은 자동 제거 후 새 연결로 교체된다.
주요 특징
프레임워크 통합
- ORM(Hibernate, EclipseLink) 이나 데이터베이스 드라이버 (MySQL Connector/J) 에 내장.
- 별도 라이브러리 없이 간편하게 설정 가능.
설정 간소화
- 연결 문자열에 파라미터 추가만으로 활성화.
- 예: JDBC URL 에
useUnicode=true&pooling=true추가.
애플리케이션 레벨 관리
- 각 애플리케이션 인스턴스가 독립적인 풀을 유지.
- 클라우드 환경에서 인스턴스 증가 시 연결 낭비 가능성 있음.
트랜잭션 지원
- 트랜잭션 컨텍스트에 따라 연결을 분리 관리.
구현 예시
Hibernate 기준
| |
SQLAlchemy
| |
Sequelize
| |
장점과 단점
| 구분 | 설명 |
|---|---|
| 장점 | - 설치/설정 간편: 별도 서비스 구성 불필요 - 낮은 지연 시간: 애플리케이션 내부에서 직접 관리 - ORM 최적화: 프레임워크 특성에 맞춘 튜닝 가능 |
| 단점 | - 확장성 제한: 인스턴스 증가 시 연결 중복 생성 - 기능 제한: 외부 풀링 대비 모니터링/튜닝 옵션 적음 - 리소스 경합: 고트래픽 시 단일 애플리케이션 풀 포화 가능성 |
주요 사용 사례
- 소규모 애플리케이션
- 빠른 개발 및 간단한 설정이 우선인 경우.
- ORM 기반 프로젝트
- Hibernate, EclipseLink 등 ORM 의 내장 풀 활용 시.
- 임베디드 데이터베이스
- H2, SQLite 등 경량 DB 와의 통합 환경.
외부 풀링 (External Pooling)
외부 풀링 (External Pooling) 은 데이터베이스 연결 관리를 위해 독립적인 라이브러리나 미들웨어를 활용하는 방식으로, 애플리케이션 코드나 서버 인프라와 분리되어 유연성과 성능을 균형 있게 제공한다.
내부 풀링이나 컨테이너 관리 방식과 달리 특정 환경에 종속되지 않으며, 다양한 애플리케이션 환경에 적용 가능하다.
외부 풀링은 복잡한 엔터프라이즈 환경에서 연결 관리의 효율성을 극대화하는 최적의 선택이다.
HikariCP 와 같은 라이브러리는 검증된 성능으로 Spring Boot 2.0+ 에서 기본 채택되었으며, maxPoolSize 와 idleTimeout 을 서버 부하에 맞게 동적으로 조절하는 것이 성능 향상의 핵심이다.
다만, 초기 설정과 모니터링을 통해 연결 누수나 과도한 풀 크기로 인한 자원 낭비를 방지해야 한다.
외부 풀링의 핵심 특징
독립적 라이브러리 기반
- HikariCP, Apache DBCP, c3p0 등의 오픈소스 라이브러리를 사용한다.
- 애플리케이션 코드와 분리되어 별도로 설정 및 관리된다.
고성능 최적화
- 연결 생성/해제 오버헤드를 최소화하여 초당 수만 건의 쿼리 처리 가능 (예: HikariCP 는 마이크로초 단위의 응답 시간을 지원).
- 경량화된 아키텍처로 리소스 사용 효율성이 높다.
세밀한 설정 조절
- 최대 연결 수 (
maxPoolSize), 유휴 연결 유지 시간 (idleTimeout), 연결 검증 쿼리 (validationQuery) 등을 세부적으로 설정 가능하다.
- 최대 연결 수 (
다중 환경 지원
- 클라우드, 온프레미스, 멀티티어 아키텍처 등 다양한 환경에서 통합적으로 사용 가능하다.
동작 원리
풀 초기화
- 애플리케이션 시작 시
maxPoolSize에 지정된 수만큼 연결을 미리 생성한다. - 예: HikariCP 는 기본적으로 10 개의 연결을 생성한다.
- 애플리케이션 시작 시
연결 할당
- 애플리케이션 요청 시 풀에서 사용 가능한 연결을 제공한다.
- 모든 연결이 사용 중일 경우
connectionTimeout동안 대기한다.
연결 반환
- 작업 완료 후
connection.close()호출 시 실제로 연결을 닫지 않고 풀로 반환한다.
- 작업 완료 후
상태 모니터링
leakDetectionThreshold를 통해 연결 누수 감지,healthCheck로 연결 상태 주기적으로 검증한다.
구현 예시 (HikariCP 기준)
| |
장점과 단점
| 구분 | 설명 |
|---|---|
| 장점 | - 높은 성능: 최적화된 알고리즘으로 초고속 처리 - 유연한 설정: 세부 파라미터 조절 가능 - 다중 프레임워크 호환: Spring, Jakarta EE 등 다양한 환경 지원 - WAS 독립성: 서버 변경 시 재구성 불필요 |
| 단점 | - 설정 복잡성: 튜닝을 위한 전문 지식 필요 - 추가 의존성: 라이브러리 업데이트 및 보안 관리 필요 - 초기 학습 곡선: 내부 풀링 대비 구현 난이도 상승 |
주요 사용 사례
- 고트래픽 웹 서비스
- 동시 접속자 수가 많은 환경에서 연결 재사용률을 극대화한다.
- 마이크로서비스 아키텍처
- 분산된 서비스들이 독립적인 풀을 유지하며 자원 경합을 방지한다.
- 배치 처리 시스템
- 대량의 데이터 처리 시 연결 생성 비용을 절감한다.
컨테이너 관리 (Container-Managed Pooling)
커넥션 풀의 " 컨테이너 관리 (Container-Managed Pooling)" 방식은 웹 애플리케이션 서버 (WAS) 가 직접 연결 풀을 생성하고 관리하는 방식을 의미한다.
이 방식은 서버 인프라와 긴밀하게 통합되어 있어 개발자의 관리 부담을 줄여주는 특징을 가진다.
컨테이너 관리 커넥션 풀의 핵심 개념
WAS 주도 관리
- 웹 컨테이너 (WAS: Tomcat, JBoss, WebLogic 등) 가 애플리케이션 구동 시점에 DB 연결을 초기화하고 풀을 생성한다.
- 연결의 라이프사이클을 WAS 가 전적으로 관리한다.
중앙 집중식 설정
context.xml또는 서버 전용 설정 파일 (예: JEUSMain.xml) 에서 풀의 속성을 정의한다.- 애플리케이션 코드와 분리되어 인프라 수준에서 관리된다.
서버 리소스 통합
- WAS 의 스레드 풀, 메모리 관리 시스템과 통합되어 안정적인 자원 할당이 가능하다.
동작 원리
풀 초기화
- WAS 시작 시
maxActive,minIdle등의 설정값을 기반으로 초기 연결을 생성한다. - 예: Tomcat 은
org.apache.tomcat.jdbc.pool을 내장 풀로 사용한다.
- WAS 시작 시
연결 할당
- 애플리케이션은 JNDI(Java Naming and Directory Interface) 를 통해
DataSource객체를 조회한다. - 풀에서 유휴 상태의 연결을 가져와 사용한다.
- 애플리케이션은 JNDI(Java Naming and Directory Interface) 를 통해
연결 반환
- 작업 완료 후
Connection.close()호출 시 실제로 연결이 종료되지 않고 풀로 반환된다.
- 작업 완료 후
상태 검증
validationQuery(예:SELECT 1) 를 주기적으로 실행하여 연결의 유효성을 확인한다.- 손상된 연결은 자동으로 제거되고 새 연결로 대체된다.
구체적인 설정 예시
Tomcat 기준
| |
장점과 단점
| 구분 | 설명 |
|---|---|
| 장점 | - 서버 통합 관리: WAS 의 모니터링 도구와 연동해 실시간 상태 추적 가능 - 간편한 설정: XML/관리 콘솔에서 중앙 집중식 설정 - 안정성: WAS 의 안정성 보장 메커니즘 (예: 장애 시 자동 재연결) 적용 - 성능 최적화: 서버 레벨에서 연결 풀을 최적화하여 고성능 유지 |
| 단점 | - WAS 종속성: 서버 변경 시 설정 재구성 필요 - 유연성 부족: 외부 라이브러리 (HikariCP 등) 보다 고급 기능 제한적 - 확장성 제한: 클라우드 환경에서의 탄력적 확장에 어려움 |
사용 사례
- 전통적인 엔터프라이즈 환경
- JBoss, WebLogic 등에서 JNDI 기반의 풀 관리가 필수적인 경우.
- 레거시 시스템 통합
- 기존 인프라와의 호환성을 유지해야 하는 환경.
- 간편한 설정 우선
- 소규모 애플리케이션에서 별도 라이브러리 도입 없이 빠르게 구성할 때.
구현 예시
Python
| |
Javascript
| |