Celery
Celery는 파이썬으로 작성된 분산 작업 큐 시스템이다.
주로 웹 애플리케이션에서 비동기 작업 처리와 작업 스케줄링을 위해 사용된다.
Celery는 파이썬으로 작성된 비동기 작업 큐/작업 스케줄러이다. 분산 메시지 전달을 기반으로 동작하며, 실시간 처리와 작업 스케줄링을 지원한다.
주요 역할:
- 비동기 작업 처리
- 실시간 작업 처리
- 예약된 작업 실행
- 분산 시스템에서의 작업 관리
Celery는 복잡한 비동기 작업 처리와 분산 시스템 구축에 매우 유용한 도구이다.
웹 애플리케이션의 성능을 향상시키고 확장성을 높이는 데 큰 도움이 된다.
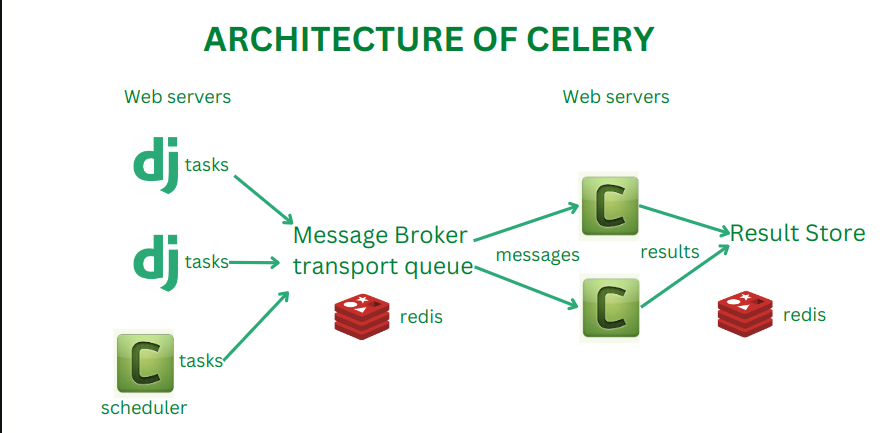
Celery의 특징
- 유연성: 다양한 브로커(RabbitMQ, Redis 등)와 결과 백엔드를 지원한다.
- 확장성: 수평적 확장이 용이하여 대규모 처리에 적합하다.
- 신뢰성: 작업 재시도, 타임아웃 등의 기능으로 안정적인 처리를 보장한다.
- 모니터링: Flower와 같은 도구를 통해 실시간 모니터링이 가능하다.
- 대규모 처리: 단일 Celery는 1분에 수백만 건의 작업을 처리할 수 있는 속도를 제공한다.
- 확장 가능성: Custom pool 구현, 직렬화기, 압축 구조, 로깅, 스케줄러, consumer, producer 등 다양한 기능을 사용하거나 확장할 수 있다.
Celery의 비동기 작업 방식의 장점
Celery의 비동기 작업 방식은 동기 방식과 비교했을 때 다음과 같은 장점들이 있다:
- 성능 향상: 비동기 방식은 동기보다 복잡하지만, 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 다른 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있다.
- 응답성 향상: 긴 작업을 수행하는 동안 UI가 차단되지 않으므로, 사용자는 다른 작업을 계속 수행할 수 있다. 이는 특히 웹 및 모바일 애플리케이션에서 중요하며, 사용자와의 상호 작용을 유지하면서 백그라운드에서 복잡한 작업을 수행할 수 있다.
- 자원 최적화: 비동기 프로그래밍을 사용하면 시스템 자원을 보다 효율적으로 사용할 수 있다. 예를 들어, 네트워크 요청을 기다리는 동안 CPU는 다른 계산을 수행할 수 있으며, 이로 인해 전체 시스템의 효율성이 향상된다.
- 유연성과 확장성: 비동기 코드는 모듈화 및 재사용이 용이하며, 다양한 환경과 상황에서 확장성 있게 동작할 수 있다.
- 대규모 처리 가능: 예를 들어 웹 애플리케이션에서 데이터베이스 쿼리를 수행할 때, 비동기 방식으로 처리하면 데이터베이스에서 응답이 올 때까지 기다리는 동안에도 다른 요청을 처리할 수 있다. 이렇게 비동기 방식을 사용하면, 대규모 트래픽에서도 안정적으로 동작할 수 있는 웹 애플리케이션을 만들 수 있다.
이러한 장점들로 인해 Celery를 사용한 비동기 작업 처리는 특히 시간이 오래 걸리는 작업이나 대량의 요청을 처리해야 하는 상황에서 매우 유용하다.
Celery의 구성 요소
Celery의 주요 구성 요소는 다음과 같다:
클라이언트 (Client)
클라이언트는 작업을 생성하고 브로커에 전송하는 역할을 한다.
일반적으로 웹 애플리케이션이나 스크립트가 클라이언트가 된다.
클라이언트는 Celery를 사용하여 작업을 정의하고 실행을 요청한다.브로커 (Broker)
브로커는 클라이언트와 워커 사이에서 메시지를 중개하는 역할을 한다.
작업 메시지를 저장하고 워커에게 전달하는 역할을 수행한다.
Celery에서는 RabbitMQ나 Redis가 이 역할을 수행한다.워커 (Worker)
워커는 브로커로부터 작업을 받아 실제로 실행하는 프로세스이다.
여러 워커를 동시에 실행하여 작업을 병렬 처리할 수 있다.
작업 결과를 결과 백엔드에 저장할 수 있다.결과 백엔드 (Result Backend)
결과 백엔드는 작업의 상태와 결과를 저장한다.
클라이언트가 작업 상태를 조회하거나 결과를 가져올 때 사용한다.
Redis, 데이터베이스 등을 백엔드로 사용할 수 있다.
추가적인 구성 요소로는 다음과 같은 것들이 있다:
Beat (스케줄러)
Beat는 주기적인 작업 스케줄링을 위한 스케줄러이다.
이를 통해 정기적으로 실행되어야 하는 작업을 관리할 수 있다.Flower
Flower는 Celery 모니터링 및 관리를 위한 웹 기반 도구이다.
이를 통해 작업의 진행 상황을 실시간으로 모니터링하고 관리할 수 있다.
이러한 구성 요소들이 유기적으로 작동하여 Celery가 분산 작업 큐 시스템으로서의 기능을 수행할 수 있게 한다.
Celery의 주요 기능
- 비동기 작업 처리
- 작업 스케줄링
- 작업 분산
- 작업 모니터링
- 결과 저장 및 관리
Celery 사용 방법
Celery 설치:
1pip install celeryCelery 애플리케이션 생성:
Celery 워커 실행:
1celery -A tasks worker --loglevel=info작업 실행:
기능별 예시
비동기 작업 처리
이메일 전송 예제:
가장 흔한 Celery 사용 사례는 이메일 전송이다.
Celery를 사용하면 사용자 요청에 대한 응답 시간을 줄이면서 백그라운드에서 이메일을 보낼 수 있다.
작업 스케줄링
Celery는 crontab을 사용하여 작업을 정기적으로 실행할 수 있다.
예를 들어, 매주 월요일 오전 7시에 작업을 실행하려면 다음과 같이 설정한다:
작업 체이닝
Chain은 여러 개의 작업을 순차적으로 실행할 수 있게 해주는 Celery 기능이다.
각 작업이 완료된 후 그 결과가 다음 작업에 전달된다.
참고 및 출처
Celery - Distributed Task Queue — Celery 5.4.0 documentation