아래는 CIDR(Classless Inter-Domain Routing)에 대한 1단계 기본 분석 및 검증 결과로, 주제 유형 식별과 복잡도 평가, 대표 태그, 분류 체계 검증, 핵심 요약 및 전체 개요 단계 내용입니다.[1][2][3][4][5][6][7][8][9][10][11][12]
CIDR(Classless Inter-Domain Routing)은 1993년 IETF 표준(RFC1518/1519)으로 등장하였으며, 클래스 기반 IP 주소 부여체계의 한계(주소 낭비/비효율)를 극복하고 네트워크 라우팅 성능을 향상시키기 위한 필수 기술로 자리잡았습니다. CIDR은 네트워크와 호스트 영역을 비트 단위로 자유롭게 구획하여 다양한 크기의 IP 블록 할당과 라우팅 경로 집계를 가능하게 만들었습니다. 이로써 라우팅 테이블 규모가 감소하며 주소 공간의 유연성도 크게 확대되었습니다. 오늘날 CIDR는 모든 현업 네트워크 설계, 클라우드, 대규모 서비스에서 필수적으로 사용되며, IPv6에도 확장 적용됩니다.[4][7][9][2][5][6][11]
아래는 CIDR(Classless Inter-Domain Routing) 2단계 “개념 체계화 및 검증” 내용으로, 핵심 개념 구조화와 실무 연관성 분석을 포함합니다.[1][2]
importipaddress# CIDR 네트워크 객체 생성net=ipaddress.ip_network('192.168.1.0/24')print("네트워크 주소:",net.network_address)# 네트워크 주소 출력print("서브넷 마스크:",net.netmask)# 서브넷 마스크 출력print("가능한 호스트 개수:",net.num_addresses)# IP 범위 개수print("첫번째 할당 IP:",list(net.hosts()))# 첫 번째 호스트 IPprint("마지막 할당 IP:",list(net.hosts())[-1])# 마지막 호스트 IP
CIDR(클래스 없는 도메인 간 라우팅)은 네트워크 규모나 설계 목적에 따라 자유롭게 IP 주소 블록을 배정하는 방식으로, 네트워크 라우팅 효율성과 주소 공간 활용도를 극대화하는 핵심 표준입니다. 비트 단위 프리픽스 표기(/24 등)를 사용하여 서브넷과 집계 체계를 유연하게 설계하며, IPv4/IPv6 공통 적용 및 글로벌 네트워크 인프라에 필수적으로 활용됩니다.[2][1]
CIDR (Classless Inter-Domain Routing, 클래스리스 도메인 간 라우팅)은 기존 클래스 기반 IP 주소 할당의 비효율성을 해결하기 위해 개발된 IP 주소 할당 및 라우팅 방법입니다. 가변 길이 서브넷 마스크 (VLSM)를 사용하여 더 유연하고 효율적인 IP 주소 공간 활용을 가능하게 합니다.
CIDR은 1993년 RFC 1519로 표준화된 IP 주소 할당 및 라우팅 방법론입니다. 클래스 A, B, C의 고정된 네트워크 크기 제약을 제거하고, 네트워크 접두사 표기법(/24 등)을 통해 임의 크기의 네트워크 할당을 가능하게 했습니다. 이를 통해 IP 주소 공간의 효율적 활용, 라우팅 테이블 크기 감소, 인터넷 확장성 향상을 실현했습니다. 현재 모든 인터넷 라우팅과 네트워크 설계의 기반 기술로 활용되고 있습니다.
graph TB
A[CIDR 표기: 192.168.1.0/24] --> B[IP 주소: 192.168.1.0]
A --> C[접두사 길이: /24]
B --> D[32비트 이진 표현]
C --> E[네트워크 비트 수: 24]
D --> F[11000000.10101000.00000001.00000000]
E --> G[서브넷 마스크: 255.255.255.0]
F --> H[네트워크 부분: 11000000.10101000.00000001]
G --> I[호스트 부분: 8비트]
H --> J[네트워크 주소: 192.168.1.0]
I --> K[사용 가능 호스트: 254개]
graph TD
A[패킷 도착] --> B[목적지 IP 주소 추출]
B --> C[라우팅 테이블 검색]
C --> D[가장 긴 접두사 매칭]
D --> E{매칭 결과}
E -->|일치| F[해당 인터페이스로 전송]
E -->|불일치| G[기본 게이트웨이로 전송]
F --> H[패킷 전달]
G --> H
graph TB
subgraph "IANA (Internet Assigned Numbers Authority)"
A[전체 IPv4 주소 공간 관리]
end
subgraph "RIR (Regional Internet Registry)"
B[지역별 주소 블록 할당]
B1[ARIN - 북미]
B2[RIPE NCC - 유럽]
B3[APNIC - 아시아태평양]
B4[LACNIC - 라틴아메리카]
B5[AFRINIC - 아프리카]
end
subgraph "ISP/LIR (Internet Service Provider/Local Internet Registry)"
C[ISP별 주소 블록 관리]
end
subgraph "End User Organizations"
D[최종 사용자 네트워크]
D1[기업 네트워크]
D2[캠퍼스 네트워크]
D3[데이터센터]
end
A --> B
B --> B1
B --> B2
B --> B3
B --> B4
B --> B5
B1 --> C
B2 --> C
B3 --> C
C --> D
D --> D1
D --> D2
D --> D3
IANA: 전체 IPv4 주소 공간 (0.0.0.0/0)
↓
APNIC: 아시아태평양 지역 블록 (예: 203.0.0.0/8)
↓
Korean ISP: 국내 ISP 할당 블록 (예: 203.248.0.0/13)
↓
대기업 고객: 기업별 할당 블록 (예: 203.248.0.0/16)
↓
부서별 서브넷: 세부 네트워크 분할 (예: 203.248.1.0/24)
graph TB
subgraph "Application Layer"
A[네트워크 애플리케이션]
end
subgraph "Transport Layer"
B[TCP/UDP]
end
subgraph "Network Layer"
C[IP Protocol]
C1[CIDR 주소 지정]
C2[라우팅 결정]
end
subgraph "Routing Protocols"
D[BGP-4]
E[OSPF]
F[RIP-2]
G[IS-IS]
end
subgraph "Data Link Layer"
H[Ethernet/PPP]
end
A --> B
B --> C
C --> C1
C --> C2
C1 --> D
C1 --> E
C1 --> F
C1 --> G
C --> H
1단계: 전체 주소 공간 확보 (예: 10.0.0.0/8)
2단계: 지역별 분할 (예: 서울 10.1.0.0/16, 부산 10.2.0.0/16)
3단계: 건물별 분할 (예: A동 10.1.1.0/24, B동 10.1.2.0/24)
4단계: 층별 분할 (예: 1층 10.1.1.0/26, 2층 10.1.1.64/26)
5단계: 용도별 분할 (예: 사무용 10.1.1.0/28, 서버용 10.1.1.16/28)
2. Bottom-Up 설계 방법
정의: 실제 요구사항부터 시작하여 상위로 집약하는 방법
특징: 실용적이고 효율적인 주소 활용
목적: 주소 낭비 최소화, 실제 필요량 기반 설계
사용 상황: 기존 네트워크 최적화, 리소스 제약 환경
1단계: 각 부서별 호스트 수 조사
- 개발팀: 50대 → /26 필요 (62개 주소)
- 마케팅팀: 20대 → /27 필요 (30개 주소)
- 관리팀: 10대 → /28 필요 (14개 주소)
2단계: 여유분 포함 계산 (30% 성장 고려)
- 개발팀: 65대 → /26 유지
- 마케팅팀: 26대 → /27 유지
- 관리팀: 13대 → /28 유지
3단계: 연속된 주소 공간 할당
- 192.168.1.0/26 → 개발팀
- 192.168.1.64/27 → 마케팅팀
- 192.168.1.96/28 → 관리팀
- 192.168.1.112/28 → 예비
4단계: 상위 집약 확인
- 전체: 192.168.1.0/24로 집약 가능
3. VLSM (Variable Length Subnet Masking) 구현
정의: 하나의 네트워크 내에서 다양한 크기의 서브넷 생성
특징: 효율적인 주소 활용, 유연한 네트워크 설계
목적: 각 세그먼트의 실제 요구사항에 맞는 정확한 크기 할당
# VLSM 계산 예제defcalculate_vlsm(network,requirements):"""
VLSM 서브넷 계산 함수
network: 기본 네트워크 (예: "192.168.1.0/24")
requirements: 각 서브넷별 호스트 수 요구사항
"""importipaddress# 기본 네트워크 정의base_network=ipaddress.IPv4Network(network)print(f"기본 네트워크: {base_network}")print(f"사용 가능한 주소 수: {base_network.num_addresses-2}")# 요구사항을 호스트 수 기준으로 정렬 (큰 것부터)sorted_reqs=sorted(requirements.items(),key=lambdax:x[1],reverse=True)allocated_subnets=[]current_network=base_network.network_addressfordept,host_countinsorted_reqs:# 필요한 접두사 길이 계산 (2^n >= host_count + 2)importmathneeded_bits=math.ceil(math.log2(host_count+2))prefix_length=32-needed_bits# 서브넷 생성subnet=ipaddress.IPv4Network(f"{current_network}/{prefix_length}")allocated_subnets.append((dept,subnet,host_count))print(f"{dept}: {subnet} ({subnet.num_addresses-2}개 호스트)")# 다음 서브넷을 위한 주소 계산current_network=subnet.broadcast_address+1returnallocated_subnets# 사용 예시requirements={"개발팀":50,"마케팅팀":20,"관리팀":10,"서버실":8,"게스트":5}subnets=calculate_vlsm("192.168.1.0/24",requirements)
importipaddressimportmathfromtypingimportDict,List,Tuple# 기업 네트워크 요구사항 정의classNetworkRequirement:def__init__(self,name:str,host_count:int,growth_factor:float=1.3):self.name=nameself.host_count=host_countself.growth_factor=growth_factor# 30% 성장여유를 고려한 실제 필요 호스트 수self.actual_need=int(host_count*growth_factor)defcalculate_prefix_length(self)->int:"""호스트 수를 기반으로 필요한 접두사 길이 계산"""# 네트워크 주소와 브로드캐스트 주소 제외needed_addresses=self.actual_need+2# 2의 거듭제곱으로 올림needed_bits=math.ceil(math.log2(needed_addresses))return32-needed_bits# 가상의 ABC 기업 네트워크 요구사항company_requirements=[NetworkRequirement("본사_개발팀",120),NetworkRequirement("본사_영업팀",80),NetworkRequirement("본사_관리팀",40),NetworkRequirement("본사_서버실",30),NetworkRequirement("지사1_사무실",60),NetworkRequirement("지사2_사무실",45),NetworkRequirement("DMZ_웹서버",10),NetworkRequirement("DMZ_메일서버",5),NetworkRequirement("게스트_네트워크",50),NetworkRequirement("관리_네트워크",20)]print("=== ABC 기업 네트워크 요구사항 분석 ===")total_hosts=0forreqincompany_requirements:prefix=req.calculate_prefix_length()available_hosts=(2**(32-prefix))-2total_hosts+=req.actual_needprint(f"{req.name}: {req.host_count}대 → {req.actual_need}대 (여유분 포함)")print(f" 필요 접두사: /{prefix} (사용가능: {available_hosts}개)")print(f"\n총 필요 호스트 수: {total_hosts}개")
defdesign_vlsm_network(base_network:str,requirements:List[NetworkRequirement])->List[Tuple[str,ipaddress.IPv4Network,int]]:"""
VLSM을 사용하여 네트워크를 효율적으로 분할
base_network: 기본 네트워크 (예: "10.0.0.0/16")
requirements: 네트워크 요구사항 리스트
"""base_net=ipaddress.IPv4Network(base_network)print(f"\n=== VLSM 네트워크 설계 (기본: {base_net}) ===")# 호스트 수가 많은 순서로 정렬 (큰 서브넷부터 할당)sorted_reqs=sorted(requirements,key=lambdax:x.actual_need,reverse=True)allocated_subnets=[]current_address=base_net.network_addressforreqinsorted_reqs:prefix_length=req.calculate_prefix_length()try:# 현재 주소에서 시작하는 서브넷 생성subnet=ipaddress.IPv4Network(f"{current_address}/{prefix_length}")# 기본 네트워크 범위 내에 있는지 확인ifnotsubnet.subnet_of(base_net):print(f"오류: {req.name}을 위한 충분한 주소 공간이 없습니다.")breakallocated_subnets.append((req.name,subnet,req.actual_need))print(f"{req.name}:")print(f" 할당 네트워크: {subnet}")print(f" 사용가능 호스트: {subnet.num_addresses-2}개")print(f" 실제 필요량: {req.actual_need}개")print(f" 효율성: {(req.actual_need/(subnet.num_addresses-2))*100:.1f}%")# 다음 서브넷을 위한 주소 계산current_address=subnet.broadcast_address+1exceptValueErrorase:print(f"오류: {req.name} 할당 실패 - {e}")breakreturnallocated_subnets# VLSM 설계 실행allocated_networks=design_vlsm_network("10.0.0.0/16",company_requirements)
graph TB
subgraph "백본 네트워크 (Tier 1)"
A[Seoul Core: 203.248.0.0/13]
B[Busan Core: 203.249.0.0/13]
C[Daegu Core: 203.250.0.0/13]
end
subgraph "지역 집선 (Tier 2)"
D[Seoul Metro: 203.248.0.0/16]
E[Gangnam: 203.248.1.0/16]
F[Busan Metro: 203.249.0.0/16]
end
subgraph "가입자 서비스 (Tier 3)"
G[아파트단지 A: 203.248.0.0/20]
H[오피스빌딩 B: 203.248.16.0/20]
I[주택가 C: 203.248.32.0/22]
end
A --> D
A --> E
B --> F
D --> G
E --> H
D --> I
# KT 네트워크 주소 체계 시뮬레이션classISPNetworkDesign:def__init__(self):# 할당받은 주소 블록 (예시)self.allocated_blocks=["203.248.0.0/13",# Seoul Region"203.249.0.0/13",# Busan Region "203.250.0.0/13"# Daegu Region]defdesign_hierarchical_allocation(self,region_block:str):"""계층적 주소 할당 설계"""region_net=ipaddress.IPv4Network(region_block)print(f"지역 블록: {region_net}")print(f"총 사용가능 주소: {region_net.num_addresses:,}개")# Tier 2: 시/도 단위 분할 (/16)metro_networks=list(region_net.subnets(new_prefix=16))print(f"\n시/도별 할당 (/{16}):")metro_assignments=["Seoul_Central","Seoul_Gangnam","Seoul_Gangbuk","Incheon","Gyeonggi_North","Gyeonggi_South"]fori,metroinenumerate(metro_assignments[:len(metro_networks)]):metro_net=metro_networks[i]print(f" {metro}: {metro_net} ({metro_net.num_addresses:,}개)")# Tier 3: 가입자 서비스 단위 (/20 ~ /22)service_nets=list(metro_net.subnets(new_prefix=20))print(f" 서비스 블록 수: {len(service_nets)}개 (각각 {service_nets[0].num_addresses}개)")# 실행isp_design=ISPNetworkDesign()isp_design.design_hierarchical_allocation("203.248.0.0/13")
graph TB
subgraph "Global HQ (Seoul)"
A[Global Core: 10.0.0.0/8]
end
subgraph "Americas"
B[US East: 10.1.0.0/16]
C[US West: 10.2.0.0/16]
D[Brazil: 10.3.0.0/16]
end
subgraph "EMEA"
E[London: 10.10.0.0/16]
F[Frankfurt: 10.11.0.0/16]
G[Dubai: 10.12.0.0/16]
end
subgraph "APAC"
H[Seoul: 10.20.0.0/16]
I[Tokyo: 10.21.0.0/16]
J[Singapore: 10.22.0.0/16]
end
A --> B
A --> E
A --> H
B --> C
B --> D
E --> F
E --> G
H --> I
H --> J
# 글로벌 멀티클라우드 CIDR 설계classGlobalCIDRDesign:def__init__(self):self.global_block=ipaddress.IPv4Network("10.0.0.0/8")self.regions={"americas":{"base":"10.1.0.0/12","countries":16},"emea":{"base":"10.16.0.0/12","countries":16},"apac":{"base":"10.32.0.0/12","countries":16}}defallocate_country_blocks(self,region_name:str):"""국가별 /16 블록 할당"""region_info=self.regions[region_name]region_net=ipaddress.IPv4Network(region_info["base"])print(f"=== {region_name.upper()} 지역 할당 ===")print(f"지역 블록: {region_net}")# 국가별 /16 블록 생성country_blocks=list(region_net.subnets(new_prefix=16))# 샘플 국가 할당sample_countries={"americas":["US_East","US_West","Canada","Brazil","Mexico"],"emea":["UK","Germany","France","UAE","South_Africa"],"apac":["Korea","Japan","Singapore","Australia","India"]}countries=sample_countries.get(region_name,[])fori,countryinenumerate(countries):ifi<len(country_blocks):country_net=country_blocks[i]print(f" {country}: {country_net}")# 각 국가 내 환경별 분할 (Dev/Staging/Prod)env_subnets=list(country_net.subnets(new_prefix=18))print(f" Production: {env_subnets[0]} (/18)")print(f" Staging: {env_subnets[1]} (/18)")print(f" Development: {env_subnets[2]} (/18)")print(f" Reserved: {env_subnets[3]} (/18)")# 실행global_design=GlobalCIDRDesign()forregionin["americas","emea","apac"]:global_design.allocate_country_blocks(region)print()
# CIDR 사용률 모니터링 시스템 예시importipaddressimportjsonfromdatetimeimportdatetime,timedeltaclassCIDRMonitoring:def__init__(self):self.subnet_usage={}self.thresholds={"warning":0.70,"critical":0.85,"emergency":0.95}defcheck_subnet_utilization(self,subnet_cidr:str,used_ips:int):"""서브넷 사용률 검사 및 알림"""subnet=ipaddress.IPv4Network(subnet_cidr)total_usable=subnet.num_addresses-2# 네트워크/브로드캐스트 제외utilization=used_ips/total_usable# 사용률 기록self.subnet_usage[subnet_cidr]={"timestamp":datetime.now().isoformat(),"used_ips":used_ips,"total_usable":total_usable,"utilization":utilization}# 임계값 검사 및 알림ifutilization>=self.thresholds["emergency"]:returnself._generate_alert("EMERGENCY",subnet_cidr,utilization)elifutilization>=self.thresholds["critical"]:returnself._generate_alert("CRITICAL",subnet_cidr,utilization)elifutilization>=self.thresholds["warning"]:returnself._generate_alert("WARNING",subnet_cidr,utilization)return{"status":"OK","utilization":utilization}def_generate_alert(self,level:str,subnet:str,utilization:float):"""알림 메시지 생성"""messages={"WARNING":f"서브넷 {subnet} 사용률 {utilization:.1%} - 확장 계획 수립 필요","CRITICAL":f"서브넷 {subnet} 사용률 {utilization:.1%} - 즉시 확장 또는 최적화 필요","EMERGENCY":f"서브넷 {subnet} 사용률 {utilization:.1%} - 긴급 대응 필요!"}return{"status":level,"message":messages[level],"utilization":utilization,"timestamp":datetime.now().isoformat()}defpredict_exhaustion(self,subnet_cidr:str,growth_rate_per_day:int):"""IP 주소 고갈 시점 예측"""ifsubnet_cidrnotinself.subnet_usage:return"데이터 부족"usage_data=self.subnet_usage[subnet_cidr]remaining_ips=usage_data["total_usable"]-usage_data["used_ips"]ifgrowth_rate_per_day<=0:return"현재 증가율로는 고갈 없음"days_to_exhaustion=remaining_ips/growth_rate_per_dayexhaustion_date=datetime.now()+timedelta(days=days_to_exhaustion)return{"days_remaining":round(days_to_exhaustion,1),"exhaustion_date":exhaustion_date.strftime("%Y-%m-%d"),"recommendation":self._get_expansion_recommendation(days_to_exhaustion)}def_get_expansion_recommendation(self,days_remaining:float):"""확장 권장사항 제공"""ifdays_remaining<30:return"즉시 확장 또는 대체 서브넷 할당 필요"elifdays_remaining<90:return"다음 분기 내 확장 계획 수립 권장"else:return"현재 수준 유지, 정기 모니터링 지속"# 사용 예시monitor=CIDRMonitoring()# 실제 사용률 검사result1=monitor.check_subnet_utilization("192.168.1.0/24",180)# 70.9% 사용result2=monitor.check_subnet_utilization("10.0.1.0/28",12)# 85.7% 사용print("사용률 검사 결과:")print(f"192.168.1.0/24: {result1}")print(f"10.0.1.0/28: {result2}")# 고갈 예측prediction=monitor.predict_exhaustion("10.0.1.0/28",0.5)# 일일 0.5개 증가print(f"\n고갈 예측: {prediction}")
# CIDR 기반 보안 정책 생성기classSecurityPolicyGenerator:def__init__(self):self.security_zones={"dmz":{"cidr":"10.1.0.0/24","security_level":"medium"},"internal":{"cidr":"10.2.0.0/16","security_level":"high"},"guest":{"cidr":"10.3.0.0/24","security_level":"low"},"management":{"cidr":"10.4.0.0/28","security_level":"critical"}}self.default_policies={"critical":["deny_all_inbound","log_all_traffic","encrypt_required"],"high":["deny_external_inbound","allow_internal","log_security_events"],"medium":["allow_web_traffic","deny_admin_ports","basic_logging"],"low":["allow_internet","deny_internal","minimal_logging"]}defgenerate_firewall_rules(self,source_zone:str,dest_zone:str):"""존 간 방화벽 규칙 자동 생성"""source_info=self.security_zones.get(source_zone)dest_info=self.security_zones.get(dest_zone)ifnotsource_infoornotdest_info:return{"error":"존 정보 없음"}source_cidr=source_info["cidr"]dest_cidr=dest_info["cidr"]source_level=source_info["security_level"]dest_level=dest_info["security_level"]rules=[]# 보안 레벨 기반 규칙 생성ifself._is_higher_security(source_level,dest_level):# 높은 보안 → 낮은 보안: 허용 (아웃바운드)rules.extend([f"ALLOW {source_cidr} → {dest_cidr} tcp/80,443",f"ALLOW {source_cidr} → {dest_cidr} udp/53",f"LOG {source_cidr} → {dest_cidr} any"])elifself._is_lower_security(source_level,dest_level):# 낮은 보안 → 높은 보안: 제한적 허용rules.extend([f"DENY {source_cidr} → {dest_cidr} tcp/22,3389",f"ALLOW {source_cidr} → {dest_cidr} tcp/80,443",f"LOG {source_cidr} → {dest_cidr} any"])else:# 동일 레벨: 기본 허용rules.extend([f"ALLOW {source_cidr} → {dest_cidr} any",f"LOG {source_cidr} → {dest_cidr} security_events"])return{"source_zone":source_zone,"destination_zone":dest_zone,"rules":rules,"policy_basis":f"{source_level} → {dest_level}"}def_is_higher_security(self,source:str,dest:str):"""보안 레벨 비교 (높음→낮음)"""levels={"critical":4,"high":3,"medium":2,"low":1}returnlevels.get(source,0)>levels.get(dest,0)def_is_lower_security(self,source:str,dest:str):"""보안 레벨 비교 (낮음→높음)"""levels={"critical":4,"high":3,"medium":2,"low":1}returnlevels.get(source,0)<levels.get(dest,0)defgenerate_compliance_report(self):"""규정 준수 보고서 생성"""report={"timestamp":datetime.now().isoformat(),"compliance_checks":[],"violations":[],"recommendations":[]}# 네트워크 분리 검사forzone_name,zone_infoinself.security_zones.items():cidr=ipaddress.IPv4Network(zone_info["cidr"])# PCI DSS 요구사항 검사 (예시)ifzone_info["security_level"]=="critical":check={"standard":"PCI DSS 1.2","requirement":"네트워크 분리","zone":zone_name,"cidr":str(cidr),"status":"COMPLIANT","details":"중요 시스템이 별도 서브넷에 격리됨"}else:check={"standard":"ISO 27001","requirement":"네트워크 접근 제어","zone":zone_name,"cidr":str(cidr),"status":"COMPLIANT","details":"적절한 접근 제어 정책 적용"}report["compliance_checks"].append(check)returnreport# 사용 예시security_gen=SecurityPolicyGenerator()# 존 간 방화벽 규칙 생성dmz_to_internal=security_gen.generate_firewall_rules("dmz","internal")guest_to_management=security_gen.generate_firewall_rules("guest","management")print("=== 방화벽 규칙 자동 생성 ===")print(f"DMZ → Internal: {dmz_to_internal}")print(f"Guest → Management: {guest_to_management}")# 컴플라이언스 보고서compliance_report=security_gen.generate_compliance_report()print(f"\n=== 규정 준수 현황 ===")forcheckincompliance_report["compliance_checks"]:print(f"{check['standard']}: {check['status']} - {check['details']}")
# CIDR 기반 이상 트래픽 탐지classCIDRSecurityMonitor:def__init__(self):self.baseline_traffic={}self.anomaly_threshold=2.0# 표준편차 배수defanalyze_traffic_patterns(self,src_cidr:str,dst_cidr:str,packet_count:int,byte_count:int):"""서브넷 간 트래픽 패턴 분석"""flow_key=f"{src_cidr}→{dst_cidr}"# 기준선 트래픽 저장/업데이트ifflow_keynotinself.baseline_traffic:self.baseline_traffic[flow_key]={"packet_samples":[],"byte_samples":[],"last_update":datetime.now()}baseline=self.baseline_traffic[flow_key]baseline["packet_samples"].append(packet_count)baseline["byte_samples"].append(byte_count)# 최근 30개 샘플만 유지iflen(baseline["packet_samples"])>30:baseline["packet_samples"]=baseline["packet_samples"][-30:]baseline["byte_samples"]=baseline["byte_samples"][-30:]# 이상 탐지 (최소 10개 샘플 필요)iflen(baseline["packet_samples"])>=10:returnself._detect_anomaly(flow_key,packet_count,byte_count)return{"status":"learning","message":"기준선 학습 중"}def_detect_anomaly(self,flow_key:str,current_packets:int,current_bytes:int):"""통계적 이상 탐지"""importstatisticsbaseline=self.baseline_traffic[flow_key]# 패킷 수 이상 검사packet_mean=statistics.mean(baseline["packet_samples"])packet_stdev=statistics.stdev(baseline["packet_samples"])packet_zscore=abs(current_packets-packet_mean)/packet_stdevifpacket_stdev>0else0# 바이트 수 이상 검사 byte_mean=statistics.mean(baseline["byte_samples"])byte_stdev=statistics.stdev(baseline["byte_samples"])byte_zscore=abs(current_bytes-byte_mean)/byte_stdevifbyte_stdev>0else0# 이상 판정ifpacket_zscore>self.anomaly_thresholdorbyte_zscore>self.anomaly_threshold:severity="HIGH"ifmax(packet_zscore,byte_zscore)>3.0else"MEDIUM"return{"status":"anomaly_detected","severity":severity,"flow":flow_key,"details":{"current_packets":current_packets,"baseline_packets":f"{packet_mean:.1f}±{packet_stdev:.1f}","packet_zscore":round(packet_zscore,2),"current_bytes":current_bytes,"baseline_bytes":f"{byte_mean:.1f}±{byte_stdev:.1f}","byte_zscore":round(byte_zscore,2)},"recommended_action":self._get_response_recommendation(severity)}return{"status":"normal","flow":flow_key}def_get_response_recommendation(self,severity:str):"""대응 권장사항"""recommendations={"HIGH":["즉시 트래픽 차단 검토","상세 패킷 분석 수행","소스 IP 기반 조사 시작","보안팀 에스컬레이션"],"MEDIUM":["트래픽 패턴 지속 모니터링","추가 로그 수집 활성화","1시간 후 재평가"]}returnrecommendations.get(severity,["일반 모니터링 지속"])# 실행 예시security_monitor=CIDRSecurityMonitor()# 정상 트래픽 학습foriinrange(20):normal_result=security_monitor.analyze_traffic_patterns("10.1.0.0/24","10.2.0.0/24",packet_count=100+i*5,# 점진적 증가byte_count=50000+i*2500)# 이상 트래픽 테스트anomaly_result=security_monitor.analyze_traffic_patterns("10.1.0.0/24","10.2.0.0/24",packet_count=500,# 급격한 증가byte_count=250000)print("=== 보안 모니터링 결과 ===")print(f"이상 트래픽 탐지: {anomaly_result}")
# CIDR 관련 문제 진단 및 해결 시스템classCIDRTroubleshooter:def__init__(self):self.network_inventory={}self.routing_table=[]self.known_issues=[]defadd_network_segment(self,name:str,cidr:str,gateway:str,vlan_id:int=None):"""네트워크 세그먼트 등록"""self.network_inventory[name]={"cidr":ipaddress.IPv4Network(cidr),"gateway":gateway,"vlan_id":vlan_id,"status":"active"}defdiagnose_ip_conflicts(self):"""IP 주소 충돌 진단"""print("=== IP 주소 충돌 진단 ===")conflicts=[]segments=list(self.network_inventory.items())fori,(name1,info1)inenumerate(segments):forj,(name2,info2)inenumerate(segments[i+1:],i+1):ifinfo1["cidr"].overlaps(info2["cidr"]):conflict={"type":"IP_OVERLAP","severity":"CRITICAL","segment1":name1,"cidr1":str(info1["cidr"]),"segment2":name2,"cidr2":str(info2["cidr"]),"overlap_network":str(info1["cidr"].overlap(info2["cidr"])),"resolution":self._generate_conflict_resolution(name1,info1["cidr"],name2,info2["cidr"])}conflicts.append(conflict)print(f"❌ 충돌 발견:")print(f" {name1} ({conflict['cidr1']}) ↔ {name2} ({conflict['cidr2']})")print(f" 중복 구간: {conflict['overlap_network']}")print(f" 해결방안: {conflict['resolution']['method']}")ifnotconflicts:print("✅ IP 주소 충돌 없음")returnconflictsdef_generate_conflict_resolution(self,name1:str,cidr1:ipaddress.IPv4Network,name2:str,cidr2:ipaddress.IPv4Network):"""충돌 해결방안 생성"""ifcidr1.prefixlen<cidr2.prefixlen:# 더 큰 네트워크를 분할smaller_net=cidr2larger_net=cidr1subnet_to_split=name1else:smaller_net=cidr1larger_net=cidr2subnet_to_split=name2# 대안 서브넷 제안supernet=smaller_net.supernet()alternatives=[]try:forsubnetinsupernet.subnets(new_prefix=smaller_net.prefixlen):ifnotsubnet.overlaps(larger_net):alternatives.append(str(subnet))iflen(alternatives)>=3:# 최대 3개 대안 제시breakexcept:alternatives=["수동 재할당 필요"]return{"method":f"{subnet_to_split} 네트워크 재할당","alternatives":alternatives,"impact":"해당 세그먼트 재구성 필요"}defdiagnose_routing_issues(self,target_ip:str):"""라우팅 문제 진단"""print(f"\n=== 라우팅 진단 (목적지: {target_ip}) ===")target=ipaddress.IPv4Address(target_ip)matching_routes=[]# 매칭되는 라우트 찾기forrouteinself.routing_table:iftargetinroute["network"]:matching_routes.append(route)ifnotmatching_routes:diagnosis={"issue":"NO_ROUTE","severity":"CRITICAL","description":f"{target_ip}에 대한 라우트 없음","resolution":["기본 라우트(0.0.0.0/0) 확인","상위 네트워크 라우트 추가","라우팅 프로토콜 설정 점검"]}eliflen(matching_routes)>1:# 최장 접두사 매칭 검증longest_prefix=max(route["network"].prefixlenforrouteinmatching_routes)best_routes=[rforrinmatching_routesifr["network"].prefixlen==longest_prefix]iflen(best_routes)>1:diagnosis={"issue":"MULTIPLE_EQUAL_ROUTES","severity":"WARNING","description":f"동일한 길이의 복수 라우트 존재","routes":[f"{r['network']} via {r['next_hop']}"forrinbest_routes],"resolution":["라우트 메트릭 조정","라우트 우선순위 설정","ECMP(Equal Cost Multi-Path) 설정 확인"]}else:diagnosis={"issue":"NORMAL_ROUTING","severity":"INFO","description":"정상적인 라우팅","selected_route":f"{best_routes[0]['network']} via {best_routes[0]['next_hop']}"}else:diagnosis={"issue":"NORMAL_ROUTING","severity":"INFO","description":"정상적인 라우팅","selected_route":f"{matching_routes[0]['network']} via {matching_routes[0]['next_hop']}"}print(f"진단 결과: {diagnosis['issue']} ({diagnosis['severity']})")print(f"설명: {diagnosis['description']}")if"resolution"indiagnosis:print("해결방안:")forresolutionindiagnosis["resolution"]:print(f" - {resolution}")returndiagnosisdefgenerate_network_health_report(self):"""네트워크 헬스 종합 보고서"""print(f"\n=== 네트워크 상태 종합 보고서 ===")# IP 충돌 검사conflicts=self.diagnose_ip_conflicts()conflict_count=len(conflicts)# 서브넷 활용률 분석total_networks=len(self.network_inventory)utilization_data=[]forname,infoinself.network_inventory.items():# 실제 환경에서는 DHCP 서버나 IPAM에서 사용률 데이터 수집# 여기서는 예시로 임의 값 사용mock_utilization=hash(name)%80+10# 10-89% 범위utilization_data.append({"network":name,"cidr":str(info["cidr"]),"utilization":mock_utilization})# 문제 요약issues_summary={"critical":conflict_count,"warning":len([uforuinutilization_dataifu["utilization"]>80]),"info":len([uforuinutilization_dataifu["utilization"]<20])}print(f"네트워크 세그먼트 수: {total_networks}")print(f"IP 충돌 수: {issues_summary['critical']}")print(f"고사용률 네트워크 수: {issues_summary['warning']}")print(f"저사용률 네트워크 수: {issues_summary['info']}")# 권장사항recommendations=[]ifissues_summary['critical']>0:recommendations.append("즉시 IP 충돌 해결 필요")ifissues_summary['warning']>0:recommendations.append("고사용률 네트워크 확장 검토")ifissues_summary['info']>2:recommendations.append("저사용률 네트워크 통합 검토")ifnotrecommendations:recommendations.append("현재 네트워크 상태 양호")print(f"\n권장사항:")forrecinrecommendations:print(f" - {rec}")return{"summary":issues_summary,"conflicts":conflicts,"utilization":utilization_data,"recommendations":recommendations}# 실행 예시troubleshooter=CIDRTroubleshooter()# 네트워크 세그먼트 등록troubleshooter.add_network_segment("DMZ","192.168.1.0/24","192.168.1.1")troubleshooter.add_network_segment("Internal","192.168.2.0/24","192.168.2.1")troubleshooter.add_network_segment("Guest","192.168.1.128/25","192.168.1.129")# 충돌 발생!troubleshooter.add_network_segment("Management","10.0.0.0/28","10.0.0.1")# 라우팅 테이블 추가troubleshooter.routing_table=[{"network":ipaddress.IPv4Network("192.168.0.0/16"),"next_hop":"10.1.1.1","metric":1},{"network":ipaddress.IPv4Network("10.0.0.0/8"),"next_hop":"10.1.1.2","metric":1},{"network":ipaddress.IPv4Network("0.0.0.0/0"),"next_hop":"10.1.1.254","metric":10}]# 진단 수행conflicts=troubleshooter.diagnose_ip_conflicts()routing_diag=troubleshooter.diagnose_routing_issues("192.168.1.100")health_report=troubleshooter.generate_network_health_report()
# CIDR 표준 준수 모니터링 시스템classCIDRComplianceMonitor:def__init__(self):self.compliance_rules={"rfc_1519":{"description":"CIDR 기본 표준","checks":["valid_cidr_notation","proper_aggregation","no_classful_assumptions"]},"rfc_4632":{"description":"현대 CIDR 가이드라인","checks":["efficient_allocation","hierarchical_structure","documentation_completeness"]}}defvalidate_cidr_notation(self,cidr_list:list):"""CIDR 표기법 유효성 검증"""validation_results=[]forcidrincidr_list:try:network=ipaddress.IPv4Network(cidr,strict=False)# 표준 준수 검사issues=[]# 호스트 비트가 0이 아닌 경우 (non-strict 모드에서 자동 수정됨)ifcidr!=str(network):issues.append(f"호스트 비트 포함: {cidr} → {network} 권장")# 비효율적인 접두사 길이 (예: /32는 호스트 주소)ifnetwork.prefixlen==32:issues.append("단일 호스트 주소(/32)는 네트워크 용도로 부적절")elifnetwork.prefixlen==31:issues.append("Point-to-Point 링크가 아닌 경우 /31 사용 주의")result={"cidr":cidr,"status":"WARNING"ifissueselse"VALID","normalized":str(network),"issues":issues}exceptValueErrorase:result={"cidr":cidr,"status":"INVALID","error":str(e),"issues":["유효하지 않은 CIDR 표기법"]}validation_results.append(result)returnvalidation_resultsdefcheck_aggregation_efficiency(self,route_list:list):"""라우트 집약 효율성 검사"""networks=[]forrouteinroute_list:try:networks.append(ipaddress.IPv4Network(route))exceptValueError:continueifnotnetworks:return{"efficiency":0,"details":"유효한 네트워크 없음"}# 집약 전후 비교original_count=len(networks)aggregated=list(ipaddress.collapse_addresses(networks))aggregated_count=len(aggregated)efficiency=((original_count-aggregated_count)/original_count)*100return{"original_routes":original_count,"aggregated_routes":aggregated_count,"efficiency_percent":round(efficiency,1),"potential_savings":original_count-aggregated_count,"status":"EXCELLENT"ifefficiency>50else"GOOD"ifefficiency>20else"POOR"}# 실행 예시compliance_monitor=CIDRComplianceMonitor()# CIDR 표기법 검증test_cidrs=["192.168.1.0/24",# 정상"192.168.1.5/24",# 호스트 비트 포함"10.0.0.1/32",# 단일 호스트"172.16.0.0/31",# Point-to-Point"invalid/24"# 잘못된 형식]validation_results=compliance_monitor.validate_cidr_notation(test_cidrs)print("=== CIDR 표기법 검증 ===")forresultinvalidation_results:print(f"{result['cidr']}: {result['status']}")if'issues'inresult:forissueinresult['issues']:print(f" - {issue}")# 집약 효율성 검사test_routes=["192.168.0.0/24","192.168.1.0/24","192.168.2.0/24","192.168.3.0/24",# 집약 가능"10.1.0.0/24","10.1.1.0/24",# 집약 가능"172.16.0.0/24"# 독립적]efficiency_result=compliance_monitor.check_aggregation_efficiency(test_routes)print(f"\n=== 라우트 집약 효율성 ===")print(f"원본 라우트: {efficiency_result['original_routes']}개")print(f"집약 라우트: {efficiency_result['aggregated_routes']}개")print(f"효율성: {efficiency_result['efficiency_percent']}% ({efficiency_result['status']})")
이로써 Phase 6의 운영 및 최적화 단계가 완료되었습니다. 이어서 Phase 7의 고급 주제 및 미래 전망으로 계속 진행하겠습니다.
# IPv4 주소 고갈 시뮬레이션defcalculate_ipv4_exhaustion_timeline():"""IPv4 주소 고갈 시점 예측"""# 현재 상황 (2025년 기준)total_ipv4_space=2**32# 약 43억 개reserved_addresses=int(total_ipv4_space*0.15)# 예약 주소 15%usable_addresses=total_ipv4_space-reserved_addresses# 현재 할당률 (추정)current_allocation_rate=0.85# 85% 할당remaining_addresses=int(usable_addresses*(1-current_allocation_rate))# 연간 증가율 (IoT, 클라우드 등)annual_growth_rates={"conservative":0.03,# 3% 연간 증가"moderate":0.05,# 5% 연간 증가 "aggressive":0.08# 8% 연간 증가}predictions={}forscenario,growth_rateinannual_growth_rates.items():# 현재 연간 소비량 추정current_annual_consumption=int(usable_addresses*current_allocation_rate*growth_rate)# 단순 선형 예측 (실제로는 더 복잡)years_remaining=remaining_addresses/current_annual_consumptionpredictions[scenario]={"years_remaining":round(years_remaining,1),"exhaustion_year":2025+int(years_remaining),"annual_consumption":f"{current_annual_consumption:,}","mitigation_urgency":"높음"ifyears_remaining<5else"중간"ifyears_remaining<10else"낮음"}returnpredictionsexhaustion_predictions=calculate_ipv4_exhaustion_timeline()print("=== IPv4 주소 고갈 예측 ===")forscenario,predictioninexhaustion_predictions.items():print(f"{scenario.upper()} 시나리오:")print(f" 예상 고갈 시점: {prediction['exhaustion_year']}년")print(f" 남은 기간: {prediction['years_remaining']}년")print(f" 연간 소비량: {prediction['annual_consumption']}개")print(f" 대응 긴급도: {prediction['mitigation_urgency']}")print()
# SDN 기반 동적 CIDR 관리 개념classSDNCIDRController:def__init__(self):self.network_policies={}self.traffic_patterns={}self.dynamic_allocations={}defdefine_allocation_policy(self,policy_name:str,rules:dict):"""동적 할당 정책 정의"""self.network_policies[policy_name]={"triggers":rules.get("triggers",[]),"actions":rules.get("actions",[]),"constraints":rules.get("constraints",{}),"priority":rules.get("priority",100)}defanalyze_traffic_demand(self,traffic_data:dict):"""트래픽 패턴 분석 및 서브넷 수요 예측"""predictions={}forsrc_subnet,flowsintraffic_data.items():total_bandwidth=sum(flow["bandwidth"]forflowinflows)unique_destinations=len(set(flow["dst"]forflowinflows))# 수요 증가 패턴 분석growth_indicator=total_bandwidth/len(flows)ifflowselse0ifgrowth_indicator>1000:# Mbps 기준predictions[src_subnet]={"demand_level":"high","recommended_action":"subnet_expansion","expansion_factor":2.0}elifgrowth_indicator>500:predictions[src_subnet]={"demand_level":"medium","recommended_action":"monitoring","expansion_factor":1.5}else:predictions[src_subnet]={"demand_level":"low","recommended_action":"optimize","expansion_factor":1.0}returnpredictionsdefauto_allocate_subnet(self,demand_prediction:dict,available_space:str):"""수요 예측 기반 자동 서브넷 할당"""base_network=ipaddress.IPv4Network(available_space)allocations=[]# 수요가 높은 순으로 정렬sorted_demands=sorted(demand_prediction.items(),key=lambdax:{"high":3,"medium":2,"low":1}[x[1]["demand_level"]],reverse=True)current_address=base_network.network_addressforsubnet_name,demand_infoinsorted_demands:ifdemand_info["demand_level"]=="high":# 고수요: /22 할당 (1022 호스트)new_prefix=22elifdemand_info["demand_level"]=="medium":# 중수요: /24 할당 (254 호스트)new_prefix=24else:# 저수요: /26 할당 (62 호스트)new_prefix=26try:allocated_subnet=ipaddress.IPv4Network(f"{current_address}/{new_prefix}")ifallocated_subnet.subnet_of(base_network):allocations.append({"subnet_name":subnet_name,"allocated_cidr":str(allocated_subnet),"demand_level":demand_info["demand_level"],"host_capacity":allocated_subnet.num_addresses-2})# 다음 할당을 위한 주소 계산current_address=allocated_subnet.broadcast_address+1exceptValueError:# 공간 부족 시 할당 중단breakreturnallocations# 사용 예시sdn_controller=SDNCIDRController()# 정책 정의sdn_controller.define_allocation_policy("auto_expansion",{"triggers":["high_utilization","traffic_growth"],"actions":["allocate_additional_subnet","notify_admin"],"constraints":{"max_prefix_length":26,"min_hosts":30}})# 트래픽 데이터 분석sample_traffic={"web_tier":[{"dst":"10.2.0.0/24","bandwidth":800},{"dst":"10.3.0.0/24","bandwidth":600}],"app_tier":[{"dst":"10.4.0.0/24","bandwidth":400},{"dst":"10.5.0.0/24","bandwidth":300}],"db_tier":[{"dst":"10.6.0.0/24","bandwidth":200}]}demand_analysis=sdn_controller.analyze_traffic_demand(sample_traffic)auto_allocations=sdn_controller.auto_allocate_subnet(demand_analysis,"10.10.0.0/16")print("=== SDN 기반 동적 CIDR 관리 ===")print("수요 분석 결과:")forsubnet,demandindemand_analysis.items():print(f" {subnet}: {demand['demand_level']} 수요 - {demand['recommended_action']}")print("\n자동 할당 결과:")forallocationinauto_allocations:print(f" {allocation['subnet_name']}: {allocation['allocated_cidr']} ({allocation['host_capacity']}개 호스트)")
# 듀얼 스택 전환 계획 도구classDualStackTransitionPlanner:def__init__(self):self.ipv4_networks={}self.ipv6_networks={}self.transition_phases=[]defmap_ipv4_to_ipv6(self,ipv4_cidr:str,ipv6_prefix:str):"""IPv4 네트워크의 IPv6 매핑 계획"""ipv4_net=ipaddress.IPv4Network(ipv4_cidr)# IPv6 서브넷 크기 계산 (일반적으로 /64 사용)ipv6_subnet_size=64# IPv4 서브넷 수만큼 IPv6 서브넷 생성ipv4_subnets=list(ipv4_net.subnets(new_prefix=24))# /24로 분할ipv6_base=ipaddress.IPv6Network(f"{ipv6_prefix}/{ipv6_subnet_size-8}")# /56으로 시작ipv6_subnets=list(ipv6_base.subnets(new_prefix=ipv6_subnet_size))mapping=[]fori,ipv4_subnetinenumerate(ipv4_subnets):ifi<len(ipv6_subnets):mapping.append({"ipv4":str(ipv4_subnet),"ipv6":str(ipv6_subnets[i]),"hosts_ipv4":ipv4_subnet.num_addresses-2,"hosts_ipv6":"사실상 무제한 (2^64)"})returnmappingdefcreate_transition_timeline(self,total_duration_months:int=24):"""전환 타임라인 생성"""phases=[{"phase":1,"name":"준비 및 계획","duration_months":3,"activities":["IPv6 주소 할당 신청 (RIR)","네트워크 장비 IPv6 지원 확인","IPv6 주소 체계 설계","DNS 인프라 IPv6 지원 준비"],"deliverables":["IPv6 주소 계획서","호환성 매트릭스"]},{"phase":2,"name":"인프라 기반 구축","duration_months":6,"activities":["코어 네트워크 IPv6 활성화","DNS 서버 AAAA 레코드 설정","방화벽 IPv6 정책 구성","모니터링 시스템 IPv6 지원"],"deliverables":["듀얼 스택 인프라","IPv6 보안 정책"]},{"phase":3,"name":"서비스 전환","duration_months":9,"activities":["웹 서비스 IPv6 활성화","애플리케이션 IPv6 호환성 테스트","로드밸런서 듀얼 스택 구성","CDN IPv6 지원 활성화"],"deliverables":["IPv6 서비스 포트폴리오","성능 벤치마크"]},{"phase":4,"name":"완전 전환 및 최적화","duration_months":6,"activities":["IPv4 의존성 최소화","IPv6-only 네트워크 구간 구축","성능 최적화 및 튜닝","운영 프로세스 정립"],"deliverables":["IPv6 기본 네트워크","운영 가이드"]}]returnphasesdefcalculate_transition_roi(self,current_ipv4_costs:dict,projected_savings:dict):"""전환 ROI 계산"""# IPv4 관련 비용annual_ipv4_costs=sum(current_ipv4_costs.values())# IPv6 전환으로 인한 절약annual_savings=sum(projected_savings.values())# 전환 비용 (일회성)transition_costs={"equipment_upgrade":500000,# 장비 업그레이드"training":100000,# 교육 비용"consulting":200000,# 컨설팅"downtime":150000,# 서비스 중단 비용"testing":80000# 테스트 및 검증}total_transition_cost=sum(transition_costs.values())# ROI 계산 (3년 기준)three_year_savings=annual_savings*3roi_percent=((three_year_savings-total_transition_cost)/total_transition_cost)*100payback_years=total_transition_cost/annual_savingsifannual_savings>0elsefloat('inf')return{"annual_ipv4_costs":annual_ipv4_costs,"annual_savings":annual_savings,"total_transition_cost":total_transition_cost,"three_year_savings":three_year_savings,"roi_percent":round(roi_percent,1),"payback_years":round(payback_years,1)}# 실행 예시transition_planner=DualStackTransitionPlanner()# IPv4-IPv6 매핑 계획ipv4_mapping=transition_planner.map_ipv4_to_ipv6("192.168.0.0/16","2001:db8::")print("=== IPv4-IPv6 네트워크 매핑 ===")formappinginipv4_mapping[:3]:# 처음 3개만 표시print(f"IPv4: {mapping['ipv4']} → IPv6: {mapping['ipv6']}")# 전환 타임라인timeline=transition_planner.create_transition_timeline()print(f"\n=== IPv6 전환 타임라인 ===")forphaseintimeline:print(f"Phase {phase['phase']}: {phase['name']} ({phase['duration_months']}개월)")foractivityinphase['activities'][:2]:# 주요 활동 2개만 표시print(f" - {activity}")# ROI 분석current_costs={"ip_address_lease":120000,# 연간 IP 주소 임대료"nat_equipment":80000,# NAT 장비 운영비"complexity_overhead":150000# 복잡성으로 인한 운영비}projected_savings={"simplified_networking":200000,# 네트워킹 단순화"reduced_nat_costs":100000,# NAT 비용 절감"improved_performance":50000# 성능 향상 효과}roi_analysis=transition_planner.calculate_transition_roi(current_costs,projected_savings)print(f"\n=== IPv6 전환 ROI 분석 ===")print(f"연간 IPv4 관련 비용: {roi_analysis['annual_ipv4_costs']:,}원")print(f"연간 예상 절약액: {roi_analysis['annual_savings']:,}원")print(f"전환 투자비용: {roi_analysis['total_transition_cost']:,}원")print(f"3년 ROI: {roi_analysis['roi_percent']}%")print(f"투자회수 기간: {roi_analysis['payback_years']}년")
# 의도 기반 네트워킹에서의 CIDR 자동 관리classIntentBasedCIDRManager:def__init__(self):self.network_intents={}self.current_state={}self.policies={}defdefine_network_intent(self,intent_name:str,requirements:dict):"""네트워크 의도 정의"""self.network_intents[intent_name]={"performance":requirements.get("performance",{}),"security":requirements.get("security",{}),"availability":requirements.get("availability",{}),"scalability":requirements.get("scalability",{}),"compliance":requirements.get("compliance",[])}deftranslate_intent_to_cidr(self,intent_name:str):"""의도를 구체적인 CIDR 설정으로 변환"""ifintent_namenotinself.network_intents:return{"error":"의도를 찾을 수 없음"}intent=self.network_intents[intent_name]cidr_configuration={}# 성능 요구사항 → 서브넷 크기 결정ifintent["performance"].get("latency")=="low":cidr_configuration["subnet_size"]="/26"# 작은 브로드캐스트 도메인elifintent["performance"].get("throughput")=="high":cidr_configuration["subnet_size"]="/22"# 큰 서브넷으로 집약 효과else:cidr_configuration["subnet_size"]="/24"# 기본값# 보안 요구사항 → 네트워크 분리 설계security_level=intent["security"].get("isolation","medium")ifsecurity_level=="high":cidr_configuration["segmentation"]="micro"# 마이크로 세그멘테이션cidr_configuration["default_policy"]="deny_all"elifsecurity_level=="medium":cidr_configuration["segmentation"]="standard"# 표준 서브넷 분리cidr_configuration["default_policy"]="allow_internal"else:cidr_configuration["segmentation"]="minimal"# 최소 분리cidr_configuration["default_policy"]="allow_most"# 가용성 요구사항 → 중복성 설계availability=intent["availability"].get("sla","standard")ifavailability=="critical":cidr_configuration["redundancy"]="multi_az"cidr_configuration["failover"]="automatic"elifavailability=="high":cidr_configuration["redundancy"]="dual_path"cidr_configuration["failover"]="fast"# 확장성 요구사항 → 성장 여유분growth_expectation=intent["scalability"].get("growth_rate","moderate")ifgrowth_expectation=="aggressive":cidr_configuration["growth_factor"]=3.0elifgrowth_expectation=="moderate":cidr_configuration["growth_factor"]=2.0else:cidr_configuration["growth_factor"]=1.5return{"intent_name":intent_name,"cidr_configuration":cidr_configuration,"implementation_plan":self._generate_implementation_plan(cidr_configuration)}def_generate_implementation_plan(self,config:dict):"""구현 계획 자동 생성"""plan=[]# 서브넷 생성 단계plan.append({"step":1,"action":"create_subnets","details":f"서브넷 크기 {config['subnet_size']}로 네트워크 분할","automation":"terraform apply subnet-config.tf"})# 보안 정책 적용plan.append({"step":2,"action":"apply_security_policies","details":f"{config['segmentation']} 수준의 보안 분리 구현","automation":f"ansible-playbook security-{config['segmentation']}.yml"})# 중복성 구성if"redundancy"inconfig:plan.append({"step":3,"action":"configure_redundancy","details":f"{config['redundancy']} 중복성 구성","automation":"kubectl apply -f redundancy-config.yaml"})returnplan# 사용 예시ibn_manager=IntentBasedCIDRManager()# 의도 정의ibn_manager.define_network_intent("web_application",{"performance":{"latency":"low","throughput":"high"},"security":{"isolation":"high","encryption":"required"},"availability":{"sla":"critical","uptime":"99.99%"},"scalability":{"growth_rate":"aggressive","auto_scale":True},"compliance":["PCI-DSS","SOX"]})# 의도를 CIDR 설정으로 변환cidr_plan=ibn_manager.translate_intent_to_cidr("web_application")print("=== 의도 기반 CIDR 설계 ===")print(f"의도: {cidr_plan['intent_name']}")print("CIDR 설정:")forkey,valueincidr_plan['cidr_configuration'].items():print(f" {key}: {value}")print("\n구현 계획:")forstepincidr_plan['implementation_plan']:print(f" 단계 {step['step']}: {step['action']}")print(f" 상세: {step['details']}")print(f" 자동화: {step['automation']}")
# 서비스 메시 환경에서의 CIDR 역할 변화classServiceMeshNetworking:def__init__(self):self.service_registry={}self.traffic_policies={}self.traditional_subnets={}defcompare_networking_models(self):"""기존 CIDR vs 서비스 메시 모델 비교"""comparison={"traditional_cidr":{"traffic_control":"IP 주소 및 포트 기반","security":"네트워크 경계 보안","load_balancing":"L3/L4 로드밸런서","observability":"네트워크 플로우 모니터링","complexity":"물리적 토폴로지 의존","scalability":"서브넷 크기 제약"},"service_mesh":{"traffic_control":"서비스 ID 기반","security":"상호 TLS 인증","load_balancing":"L7 어플리케이션 레벨","observability":"분산 추적 및 메트릭","complexity":"로직 중심 추상화","scalability":"서비스 단위 확장"}}# 하이브리드 접근법hybrid_model={"cidr_role":"인프라 계층 기본 연결성","service_mesh_role":"애플리케이션 계층 트래픽 관리","integration_points":["서비스 메시 데이터 플레인을 위한 CIDR 할당","클러스터 간 연결을 위한 네트워크 피어링","외부 서비스 접근을 위한 egress gateway"],"benefits":["인프라와 애플리케이션 관심사 분리","각 계층별 최적화된 기술 활용","점진적 마이그레이션 가능"]}return{"traditional":comparison["traditional_cidr"],"service_mesh":comparison["service_mesh"],"hybrid":hybrid_model}defdesign_hybrid_architecture(self,cluster_requirements:dict):"""하이브리드 아키텍처 설계"""design={}# 클러스터별 CIDR 할당forcluster_name,requirementsincluster_requirements.items():pod_count=requirements.get("max_pods",1000)service_count=requirements.get("max_services",100)# Pod CIDR 계산 (일반적으로 /16 또는 /14)ifpod_count>4000:pod_cidr_prefix=14# ~262k podselifpod_count>1000:pod_cidr_prefix=16# ~65k podselse:pod_cidr_prefix=18# ~16k pods# Service CIDR 계산 (일반적으로 /16 또는 /20)ifservice_count>1000:service_cidr_prefix=16else:service_cidr_prefix=20design[cluster_name]={"pod_cidr":f"10.{len(design)*4}.0.0/{pod_cidr_prefix}","service_cidr":f"10.{len(design)*4+1}.0.0/{service_cidr_prefix}","node_cidr":f"10.{len(design)*4+2}.0.0/24","service_mesh_config":{"mtls_mode":"STRICT","traffic_policy":"default_deny","observability":"enabled"}}returndesign# 실행 예시service_mesh=ServiceMeshNetworking()# 네트워킹 모델 비교networking_comparison=service_mesh.compare_networking_models()print("=== 네트워킹 모델 비교 ===")print("기존 CIDR 모델:")foraspect,descriptioninnetworking_comparison["traditional"].items():print(f" {aspect}: {description}")print("\n서비스 메시 모델:")foraspect,descriptioninnetworking_comparison["service_mesh"].items():print(f" {aspect}: {description}")print("\n하이브리드 접근법:")hybrid=networking_comparison["hybrid"]print(f"CIDR 역할: {hybrid['cidr_role']}")print(f"서비스 메시 역할: {hybrid['service_mesh_role']}")# 하이브리드 아키텍처 설계cluster_reqs={"production":{"max_pods":5000,"max_services":200},"staging":{"max_pods":1000,"max_services":50},"development":{"max_pods":500,"max_services":30}}hybrid_design=service_mesh.design_hybrid_architecture(cluster_reqs)print(f"\n=== 하이브리드 아키텍처 설계 ===")forcluster,configinhybrid_design.items():print(f"{cluster} 클러스터:")print(f" Pod CIDR: {config['pod_cidr']}")print(f" Service CIDR: {config['service_cidr']}")print(f" Node CIDR: {config['node_cidr']}")
CIDR의 본질: CIDR(Classless Inter-Domain Routing)은 1993년 RFC 1519로 표준화된 혁신적인 IP 주소 할당 및 라우팅 방법론입니다. 기존 클래스 기반 시스템의 주소 낭비 문제를 해결하고, 인터넷의 폭발적 성장에 대응하기 위해 개발되었습니다.
핵심 가치:
효율성: 가변 길이 서브넷 마스킹(VLSM)을 통한 정확한 크기의 주소 할당
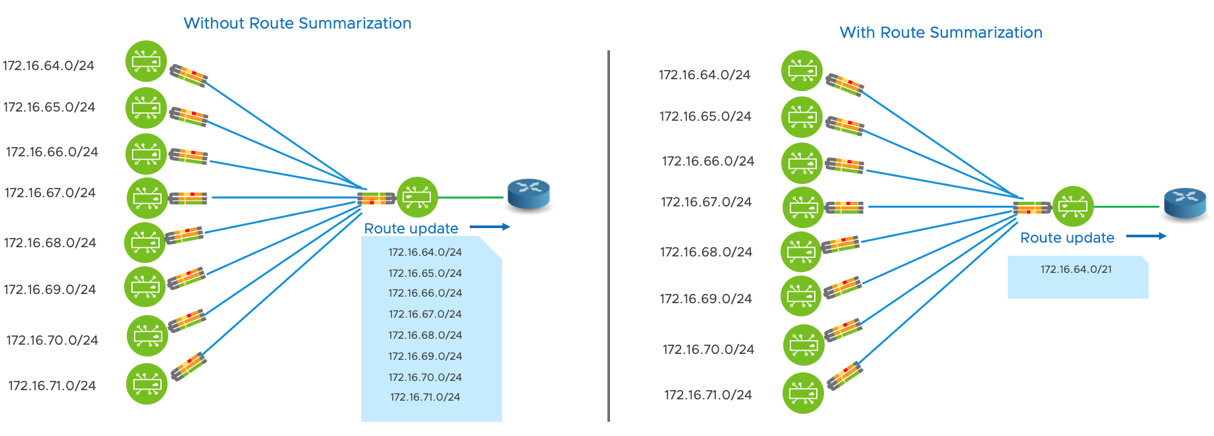
확장성: 라우트 집약을 통한 라우팅 테이블 크기 최적화
유연성: 조직의 실제 요구사항에 맞는 계층적 네트워크 설계
현대적 의미: 단순한 주소 할당 기법을 넘어, 클라우드 컴퓨팅, 컨테이너 오케스트레이션, 서비스 메시 등 현대 IT 인프라의 기반 기술로 자리잡았습니다.
CIDR(클래스리스 도메인 간 라우팅)은 **프리픽스 길이(/n)**로 네트워크를 표현해 주소 공간을 절약하고 **라우팅 테이블을 요약(aggregation)**하여 인터넷 라우터 상태 크기 증가를 억제한다. IPv4·IPv6 모두에 적용되며, VLSM(가변 길이 서브넷 마스크)과 LPM(최장일치)을 기반으로 동작한다.
CIDR은 과거 클래스 기반(A/B/C) 한계를 극복하기 위해 **프리픽스 기반 주소 표기와 요약 경로(supernetting)**를 도입했다. 결과적으로 주소 할당 정책, 라우팅 프로토콜, 사업자(RIR/LIR) 정책이 CIDR 중심으로 재편되었다. 실무에서는 VPC/VNet 설계, 온프레미스-클라우드 연동, ACL/보안 경계, BGP 요약, NAT/Anycast/Multihoming에 직결된다. IPv6에서는 /64 관행, 다양한 프리픽스 길이 허용 등 운영 가이드가 추가된다.
flowchart LR
A[요구사항: 주소/보안/경계] --> B[VLSM 설계]
B --> C[프리픽스 블록 테이블]
C --> D[요약 경로(Summarization)]
D --> E[BGP/IGP 라우팅 업데이트]
E --> F[LPM 포워딩]
F --> G[운영: 모니터링/트러블슈팅]
# CIDR 계산 기본: 네트워크 크기, 브로드캐스트(IPv4), 첫/마지막 주소fromipaddressimportip_networkdefnet_info(cidr:str):net=ip_network(cidr,strict=True)# 잘못된 호스트 비트 포함 방지hosts=net.num_addresses-(2ifnet.version==4andnet.prefixlen<31else0)return{"version":net.version,"network":str(net.network_address),"broadcast":str(net.broadcast_address)ifnet.version==4elseNone,"prefixlen":net.prefixlen,"size":net.num_addresses,"usable_hosts":max(hosts,0),"first":str(list(net.hosts())[0])ifhosts>0elsestr(net.network_address),"last":str(list(net.hosts())[-1])ifhosts>0elsestr(net.network_address),}print(net_info("192.0.2.0/27"))
fromipaddressimportip_network,collapse_addressesdefsummarize(networks:list[str]):nets=[ip_network(n)forninnetworks]# 인접·중첩 네트워크 자동 축약return[str(n)fornincollapse_addresses(nets)]print(summarize(["203.0.113.0/25","203.0.113.128/25"]))# → ['203.0.113.0/24']
fromipaddressimportip_networkimportmathdefvlsm(base_cidr:str,host_requirements:list[int]):"""가장 큰 수요부터 2^k로 반올림하여 할당. IPv4 전용(브로드캐스트 고려).
반환: [(cidr, hosts)]
"""base=ip_network(base_cidr,strict=True)# 큰 수요 우선reqs=sorted(host_requirements,reverse=True)cursor=base.network_addressresult=[]forhinreqs:need=h+2# 네트워크/브로드캐스트p=32-math.ceil(math.log2(need))subnet=ip_network(f"{cursor}/{p}",strict=False)# 경계 정렬: subnet.network_address 기준으로 다시 생성subnet=ip_network(f"{subnet.network_address}/{p}")result.append((str(subnet),h))# 다음 시작점으로 이동cursor=subnet.broadcast_address+1ifcursor>base.broadcast_address:raiseValueError("요구량이 기본 블록을 초과합니다")returnresultprint(vlsm("10.0.0.0/16",[500,2000,50,50]))
# 요약 경계 검증: 모든 하위가 상위 프리픽스에 포함되는지 검사fromipaddressimportip_networkdefcovered(parent:str,children:list[str])->bool:p=ip_network(parent)returnall(ip_network(c).subnet_of(p)forcinchildren)print(covered("10.0.0.0/16",["10.0.0.0/20","10.0.16.0/20"]))# True
RFC 7608 — IPv6 Prefix Length Recommendation for Forwarding
NetBox, phpIPAM, FRRouting 등 프로젝트 문서
CIDR은 1993년에 도입된 IP 주소 할당 및 라우팅 방식으로, 기존의 클래스 기반 주소 체계(Classful Addressing)의 한계를 극복하기 위해 만들어졌다. 인터넷이 급속도로 성장하면서 기존의 고정된 클래스 체계로는 IP 주소를 효율적으로 할당하기 어려워졌고, 이를 해결하기 위해 더 유연한 주소 할당 방식이 필요해지면서 탄생되었다. 네트워크 정보를 여러 개로 나누어진 Sub-Network 들을 모두 나타낼 수 있는 하나의 Network 로 통합해서 보여주는 방법이다.
CIDR(Classless Inter-Domain Routing)는 IP 주소를 할당하고 라우팅하는 방식 자체를 의미하는 반면, CIDR 블록은 CIDR 방식을 사용하여 실제로 정의된 특정 주소의 범위를 의미한다. 예를 들어 192.168.1.0/24와 같은 특정 네트워크 주소 범위를 CIDR 블록이라고 한다.
구체적인 예시를 들어보면:
CIDR은 “/24"나 “/16"과 같은 접두어 길이를 사용하여 네트워크를 유연하게 분할할 수 있게 해주는 방식.
CIDR 블록은 이 방식을 사용하여 실제로 정의된 “192.168.1.0/24"나 “10.0.0.0/16"과 같은 특정 주소 범위.
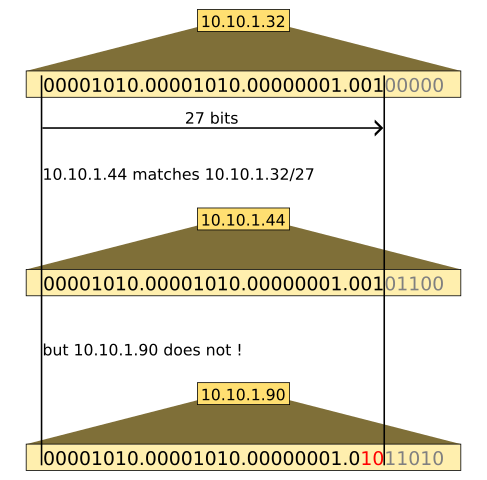
예를 들어 192.168.1.0/24라는 CIDR 블록은 192.168.1.0부터 192.168.1.255까지의 256개 연속된 IP 주소를 포함한다. CIDR 블록이라 불리는 그룹에 포함된 여러 IP 주소는 이진 표기를 하였을 때 동일한 일련의 초기 비트를 가진다. 만약 이진 형태로 변화한 IP 주소의 첫 자리 비트에서 CIDR 접두어 N 비트 길이만큼 일치한다면, 해당 IP 주소는 CIDR 블록의 일부라고 하며, CIDR 접두어와 일치한다고 한다.
IPv6 주소에서도 사용될 수 있으며, 이 경우 긴 주소로 말미암아 접두어 길이는 0~128 까지의 범위를 지닌다.
Source: https://ko.wikipedia.org/wiki/CIDR
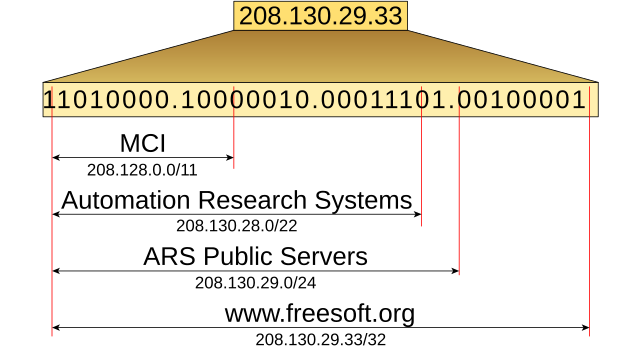
CIDR 블록의 할당
1990 년대 후반, 208.130.29.33 은 www.fresssoft.org 웹 서버에 할당되어 있었는데, 3 개의 CIDR 접두어를 가진다.
큰 CIDR 블록인 208.128.0.0/11 이 ARIN(북미 RIR) 에서 MCI 에 할당됨.
버지니아주에 있는 재공급업자인 Automation Research Systems 는 MCI 로부터 인터넷 접속을 승인받아 208.130.28.0/22 를 부여받음.
ARS 는 /24 블록을 공공 서버용으로 할당하였고, 208.130.29.33 은 그 중 하나이다.
하나의 주소에 대한 이러한 여러 CIDR 접두어는 네트워크상의 서로 다른 영역에서 각각 사용된다.
MCI 네트워크 외부에서는 208.128.0.0/11 접두어가 MCI 트래픽 영역으로 접근하기 위해 사용된다.
MCI 네트워크 내부에서는 208.128.28.0/22 가 사용되며, 패킷을 ARS 로 보내는 역할을 한다.