Large-scale Management
대규모 버전 관리 시스템 (Version Control Systems) 의 엔터프라이즈 활용은 수백 명의 개발자와 수십 기가바이트 이상의 코드베이스를 효율적으로 관리하기 위한 전략과 기술을 포함한다. Git 과 같은 분산 버전 관리 시스템 (DVCS) 은 유연성과 확장성을 제공하지만, 대규모 환경에서는 성능 최적화, 브랜칭 전략, 접근 제어, 코드 소유권 관리 등 추가적인 고려사항이 필요하다. 이를 위해 Partial Clone, Shallow Clone, Submodule, CODEOWNERS 파일 등의 기능이 활용되며, 팀 규모에 따른 브랜칭 전략도 중요하다.
핵심 개념
대규모 버전 관리 시스템은 많은 개발자와 대용량 코드베이스를 효율적으로 관리하기 위한 프레임워크이다. 이는 단순한 코드 변경 기록을 넘어서 복잡한 개발 워크플로우를 지원하고, 대규모 팀의 협업을 가능하게 하며, 지리적으로 분산된 개발 환경에서도 원활하게 작동할 수 있어야 한다.
주요 핵심 개념으로는:
- 분산 버전 관리 (Distributed Version Control): 전체 리포지토리의 복사본을 각 개발자가 로컬에 가지고 작업하는 방식으로, 네트워크 의존성을 줄이고 병렬 개발을 촉진한다.
- 스케일러블 아키텍처 (Scalable Architecture): 수천 명의 개발자와 수백만 라인의 코드를 처리할 수 있는 구조를 제공한다.
- 모듈화된 리포지토리 (Modularized Repository): 대규모 코드베이스를 관리하기 위해 논리적으로 분리된 모듈 또는 서브모듈로 구성한다.
- 스마트 캐싱 및 압축 (Smart Caching and Compression): 대용량 데이터를 효율적으로 처리하기 위한 기술적 최적화를 적용한다.
- 자동화된 워크플로우 (Automated Workflows): CI/CD 파이프라인과의 통합을 통해 코드 품질 관리와 배포 과정을 자동화한다.
목적
대규모 버전 관리 시스템의 주요 목적은 다음과 같다:
- 협업 효율성 최대화: 수백, 수천 명의 개발자가 동시에 작업할 수 있는 환경을 제공한다.
- 코드 품질 보장: 대규모 코드베이스에서도 일관된 품질을 유지할 수 있도록 지원한다.
- 개발 속도 향상: 충돌 최소화와 병렬 개발을 통해 개발 주기를 단축한다.
- 규정 준수 지원: 감사 추적, 접근 제어, 승인 워크플로우 등을 통해 규제 요구사항을 충족한다.
- 지식 공유 촉진: 코드 리뷰, 문서화, 변경 이력 추적을 통해 팀 내 지식 전파를 돕는다.
필요성
대규모 버전 관리 시스템이 필요한 이유는 다음과 같다:
- 코드베이스 증가: 현대 소프트웨어 프로젝트의 규모와 복잡성이 계속 증가하고 있다.
- 분산 팀 구조: 글로벌 개발 팀과 원격 근무 환경이 일반화되면서 효율적인 협업 도구의 필요성이 높아졌다.
- 통합 및 배포 주기 단축: 지속적 통합과 배포 환경에서는 효율적인 코드 관리가 필수적이다.
- 기술 부채 관리: 대규모 프로젝트에서 코드 품질과 일관성을 유지하기 위해 체계적인 관리가 필요하다.
- 보안 및 컴플라이언스: 엔터프라이즈 환경에서는 코드 접근 제어와 변경 이력 추적이 규제 준수를 위해 중요하다.
주요 기능
대규모 버전 관리 시스템은 다음과 같은 주요 기능을 제공한다:
- 고급 브랜칭 및 병합 전략: 복잡한 개발 워크플로우를 지원하는 유연한 브랜칭 모델을 제공한다.
- 대용량 리포지토리 최적화: 부분 클론 (Partial Clone), 얕은 클론 (Shallow Clone) 등의 기술을 통해 대용량 리포지토리의 효율적인 처리를 지원한다.
- 접근 제어 및 권한 관리: 세분화된 접근 제어와 권한 관리를 통해 코드 보안을 강화한다.
- 자동화된 워크플로우 통합: CI/CD 파이프라인과의 원활한 통합을 지원한다.
- 코드 리뷰 및 품질 관리: 코드 리뷰, 정적 분석, 테스트 자동화 등의 품질 관리 도구와의 통합을 제공한다.
- 모니터링 및 분석: 리포지토리 성능, 개발자 활동, 병목 현상 등을 분석하는 도구를 제공한다.
- 스크립트 및 후크 (Hooks): 사용자 정의 워크플로우와 자동화를 지원하는 확장 메커니즘을 제공한다.
역할
대규모 버전 관리 시스템의 주요 역할은 다음과 같다:
- 중앙 코드 저장소: 모든 소스 코드와 관련 자산의 단일 신뢰 소스 (Single Source of Truth) 로 기능한다.
- 협업 허브: 개발자 간의 효율적인 협업을 위한 플랫폼을 제공한다.
- 품질 관문: 코드 리뷰와 자동화된 검증을 통해 코드 품질을 보장한다.
- 지식 관리 시스템: 코드 변경 이력과 결정 사항을 문서화하여 조직의 지식을 보존한다.
- 배포 파이프라인 통합 요소: CI/CD 과정의 핵심 구성 요소로서 지속적 통합과 배포를 지원한다.
특징
대규모 버전 관리 시스템의 주요 특징은 다음과 같다:
- 확장성: 수천 명의 개발자와 수백만 라인의 코드를 처리할 수 있는 구조를 갖추고 있다.
- 분산 아키텍처: 네트워크 의존성을 줄이고 오프라인 작업을 지원하는 분산 모델을 채택하고 있다.
- 유연한 워크플로우: 다양한 개발 방법론과 조직 구조에 맞춰 조정할 수 있는 유연성을 제공한다.
- 강력한 병합 기능: 복잡한 병합 상황을 효율적으로 처리할 수 있는 도구를 제공한다.
- 성능 최적화: 대용량 데이터와 많은 사용자를 처리하기 위한 다양한 최적화 기법을 적용한다.
- 통합성: 다양한 개발 도구와 시스템과의 원활한 통합을 지원한다.
핵심 원칙
대규모 버전 관리 시스템의 핵심 원칙은 다음과 같다:
- 단일 신뢰 소스 (Single Source of Truth): 모든 코드의 권위 있는 버전을 중앙에서 관리한다.
- 비파괴적 변경 (Non-destructive Changes): 변경 사항은 항상 이전 상태를 보존하는 방식으로 적용된다.
- 병렬 개발 지원 (Parallel Development): 여러 개발자가 동시에 작업할 수 있는 환경을 제공한다.
- 투명성 (Transparency): 모든 변경 사항은 추적 가능하고 가시적이어야 한다.
- 자동화 우선 (Automation First): 반복적인 작업은 가능한 자동화하여 효율성을 높인다.
- 모듈성 (Modularity): 대규모 코드베이스는 논리적인 단위로 분할하여 관리한다.
- 성능과 사용성의 균형 (Balance between Performance and Usability): 대규모 리포지토리에서도 사용자 경험을 해치지 않는 성능을 유지한다.
주요 원리
대규모 버전 관리 시스템의 주요 원리는 다음과 같다:
- 변경 사항 추적: 모든 코드 변경을 개별 커밋으로 기록하고, 각 커밋은 고유한 식별자를 가진다.
- 분기 및 병합: 독립적인 개발 라인 (브랜치) 을 생성하고 나중에 통합 (병합) 할 수 있는 메커니즘을 제공한다.
- 분산 저장 및 동기화: 각 개발자가 전체 리포지토리의 복사본을 가지고 작업한 후 변경 사항을 동기화할 수 있다.
- 충돌 해결: 동일한 코드 영역을 여러 개발자가 수정할 때 발생하는 충돌을 감지하고 해결하는 메커니즘을 제공한다.
- 데이터 압축 및 최적화: 저장 공간과 네트워크 사용량을 최소화하기 위한 다양한 기술을 적용한다.
작동 원리
대규모 버전 관리 시스템의 작동 원리는 다음과 같다:
- 객체 모델: 파일 내용 (blob), 디렉토리 구조 (tree), 변경 사항 (commit), 참조 (reference) 등을 객체로 저장한다.
- 델타 압축: 연속된 버전 간의 차이만을 저장하여 공간을 절약한다.
- 내용 주소 지정 (Content-Addressed Storage): 파일의 내용에 기반한 해시를 사용하여 객체를 식별한다.
- 분산 동기화: 변경 사항을 푸시 (push) 하고 풀 (pull) 하는 메커니즘을 통해 리포지토리를 동기화한다.
- 브랜치와 태그: 특정 커밋을 가리키는 포인터를 사용하여 개발 라인과 릴리스를 관리한다.
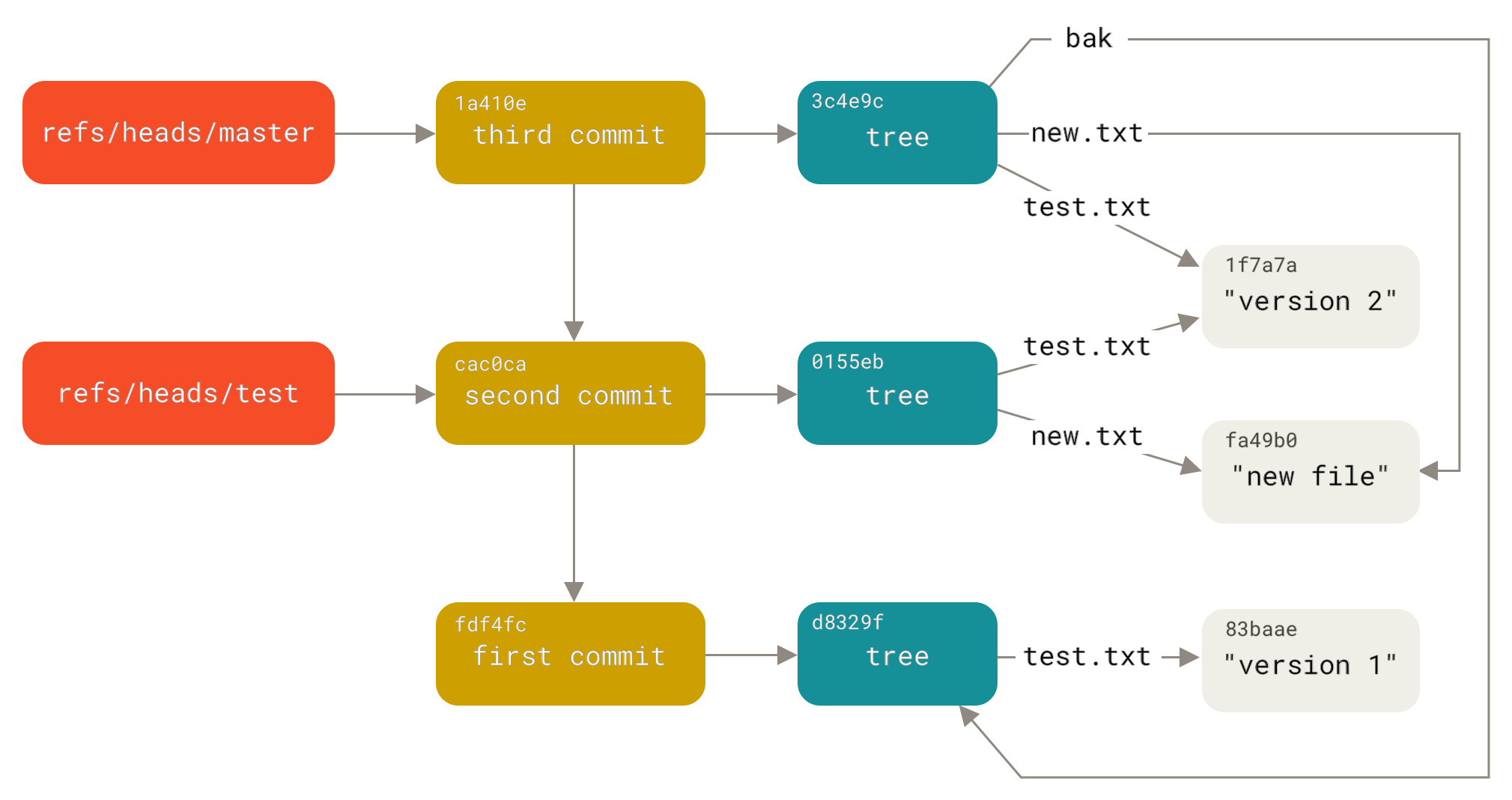
구성 요소 및 아키텍처
대규모 버전 관리 시스템의 주요 구성 요소 및 아키텍처는 다음과 같다:
| 구성 요소 | 역할 | 주요 기능 |
|---|---|---|
| 중앙 리포지토리 (Central Repository) | 공식 버전 저장 및 공유 | 푸시/풀 요청 처리, 권한 관리, 웹훅 트리거 |
| 로컬 리포지토리 (Local Repository) | 개발자의 작업 리포지토리 | 오프라인 작업, 브랜칭, 로컬 커밋 관리 |
| 객체 저장소 (Object Store) | 내부 데이터베이스로 코드 및 메타데이터 저장 | 내용 기반 주소 지정, 압축 저장, 가비지 컬렉션 |
| 인덱스/스테이징 영역 (Index/Staging Area) | 커밋 전 변경 사항 준비 | 선택적 커밋 준비, 임시 변경 사항 저장 |
| 참조 관리자 (Reference Manager) | 브랜치 및 참조 관리 | HEAD, 태그, 브랜치 포인터 업데이트 및 충돌 처리 |
| 병합 엔진 (Merge Engine) | 분기 간 변경 사항 통합 | 3-way 병합, 충돌 감지 및 자동 병합 수행 |
| 훅 및 트리거 (Hooks and Triggers) | 자동화 및 외부 통합 | 이벤트 기반 스크립트 실행, 정책 적용, 외부 연동 |
| 접근 제어 및 인증 시스템 (Access Control and Authentication System) | 리포지토리 접근 제어 | 사용자 인증, 권한 검증, 접근 감사 로깅 |
이외에도
- CI/CD 파이프라인: 코드 변경 사항을 자동으로 빌드, 테스트, 배포하는 파이프라인을 구성한다.
- 캐시 서버: 클론 및 페치 속도를 향상시키기 위해 캐시 서버를 도입한다.
등이 있다.
장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 협업 효율성 | 수천 명의 개발자가 동시에 작업할 수 있는 환경을 제공 |
| 변경 이력 추적 | 코드 변경 사항을 체계적으로 관리 | |
| 자동화된 리뷰 | CODEOWNERS 를 통한 리뷰 프로세스 자동화 | |
| 코드 품질 향상 | 코드 리뷰, 자동화된 테스트, 정책 적용을 통한 품질 보장 | |
| 개발 속도 증가 | 병렬 개발과 효율적인 병합을 통한 개발 주기 단축 | |
| 유연한 워크플로우 | 다양한 개발 방법론과 조직 구조에 맞춤화 가능 | |
| 규제 준수 | 감사 추적, 승인 절차, 접근 제어를 통한 규제 요구사항 충족 | |
| ⚠ 단점 | 학습 곡선 | 복잡한 기능과 개념으로 인한 초기 학습 어려움 |
| 성능 이슈 | 대규모 리포지토리에서의 클론, 풀, 푸시 등의 작업 시 성능 저하 | |
| 관리 복잡성 | 대규모 시스템 운영과 최적화에 필요한 전문 지식 요구 | |
| 오버헤드 | 복잡한 워크플로우와 정책이 개발 프로세스에 추가하는 오버헤드 | |
| 도구 종속성 | 특정 버전 관리 시스템에 종속되어 전환 비용 증가 |
Partial Clone 구성
- 정의: 필요한 파일만 선택적으로 클론하여, 대규모 리포지토리의 클론 시간을 단축한다.
- 장점: 클론 시간 및 디스크 사용량 감소
- 단점: 일부 Git 명령어의 제한
구성 방법:
서버 측 설정:
클라이언트 측 사용:
프로토콜 고려사항:
- Partial Clone 은 Git 프로토콜 v2 에서 가장 효율적으로 작동
- HTTPS 또는 SSH 프로토콜 사용 가능
필요한 객체 자동 다운로드:
- 커밋 체크아웃, 병합, 체리픽 등의 작업 시 필요한 객체가 자동으로 다운로드됨
- 일부 명령은 누락된 객체로 인해 실패할 수 있으므로
--missing=allow-any플래그 사용 고려
실무 구성 예시:
1 2 3 4 5 6 7 8# CI/CD 파이프라인에서의 빠른 클론 git -c protocol.version=2 clone --filter=blob:none --single-branch --branch=main <repository-url> # 대형 모노리포에서 특정 디렉토리만 작업 git -c protocol.version=2 clone --filter=blob:none <repository-url> cd repo-name git sparse-checkout init --cone git sparse-checkout set path/to/directory
Shallow Clone 최적화
- 정의: 최근 커밋만 클론하여, 저장 공간과 네트워크 사용량을 줄인다.
- 장점: 빠른 클론 및 빌드 시간 단축
- 단점: 전체 히스토리 접근 불가
최적화 방법:
기본 Shallow Clone:
단일 브랜치 최적화:
필요에 따라 이력 확장:
태그 및 참조 최적화:
CI/CD 파이프라인 최적화:
주의사항 및 제한:
- 일부 Git 작업 (예:
git blame) 은 전체 이력이 필요할 수 있음 - 기존 shallow 리포지토리에서 새 브랜치 생성 시 제약 발생 가능
- 푸시 작업에 제한이 있을 수 있으므로 주로 읽기 전용 작업에 적합
- 일부 Git 작업 (예:
대규모 리포지토리 관리 팁
대용량 리포지토리 관리는 특별한 전략과 도구가 필요하다.
대규모의 리포지토리를 효율적으로 관리하기 위한 팁은 다음과 같다:
| 구분 | 전략 | 설명 |
|---|---|---|
| 1. 대용량 파일 분리 | Git LFS 도입 | 바이너리/미디어 파일을 Git LFS 로 분리 저장 |
.gitattributes 설정 | 추적할 파일 유형 지정하여 자동 관리 | |
| 기존 파일 마이그레이션 | git lfs migrate 로 기존 파일 이전 | |
| 2. 리포지토리 최적화 | 가비지 컬렉션 | git gc --aggressive 로 불필요한 객체 정리 |
| 브랜치/태그 정리 | git remote prune origin 으로 사용되지 않는 참조 제거 | |
| 커밋 이력 정리 | rebase -i, filter-branch 로 커밋 간소화 (주의 요망) | |
| 3. 모듈식 접근 | 코드 분할 | 기능별 디렉토리 구조, 모듈화 적용 |
| 모노리포 도구 사용 | Bazel, Buck, Gradle 등으로 통합 빌드 및 의존성 관리 | |
| 4. 네트워크 및 스토리지 최적화 | 캐싱 서버 | GitHub/GitLab 미러 서버로 네트워크 부하 감소 |
| 지역 미러 구축 | 글로벌 팀 대상 지역별 접근성 개선 | |
| 고성능 인프라 | SSD, 고속 네트워크 등 하드웨어 성능 강화 | |
| 5. 선택적 체크아웃 | Sparse Checkout | 필요한 디렉토리만 작업 공간에 다운로드 |
| Partial/ Shallow Clone | --filter=blob:none, --depth=1 옵션으로 속도 개선 | |
| 단일 브랜치 클론 | --single-branch 로 브랜치 수 제한 | |
| 6. CI/CD 최적화 | 증분 빌드 | 변경된 파일 기준 최소 단위 빌드 및 테스트 |
| 캐싱 전략 | 의존성, 아티팩트 캐싱으로 빌드 시간 단축 | |
| 병렬화 | 여러 작업을 동시에 실행해 파이프라인 속도 향상 | |
| 7. 인프라 요구사항 | 서버 성능 향상 | RAM, CPU, 디스크 성능 확보 |
| 네트워크 확보 | 고속 네트워크로 Git 트래픽 처리 | |
| 백업 전략 | 자동화된 백업과 재해 복구 절차 운영 | |
| 8. 모니터링 및 유지보수 | 리포지토리 성능 측정 | 클론 속도, 객체 수, 히스토리 깊이 등 모니터링 |
| 유지보수 자동화 | 정기적인 gc, 불필요한 객체 자동 정리 | |
| 사용 분석 | 리포지토리 이용 패턴 기반 최적화 전략 수립 |
Submodule
정의:
하나의 Git 리포지토리 안에 다른 Git 리포지토리를 포함시키는 기능. 대규모 프로젝트에서 공통 모듈 또는 라이브러리를 재사용할 때 사용된다.대규모 환경에서의 활용:
- 공통 라이브러리 모듈화: 여러 프로젝트에서 사용하는 코드를 서브모듈로 분리
- 제 3 자 의존성 관리: 외부 라이브러리를 서브모듈로 포함하여 버전 고정
- 대규모 코드베이스 분할: 논리적 구성 요소를 서브모듈로 분리하여 관리
활용 사례:
- 여러 프로젝트 간 공통된 로직 (예: 인증, 로깅 등) 을 분리하여 별도의 서브모듈로 관리
- 오픈소스 서드파티 라이브러리를 특정 버전으로 고정해 프로젝트 내 포함
기본 사용법:
서브모듈 버전 관리:
서브모듈 작업 흐름:
- 서브모듈 변경 사항 커밋: 서브모듈 디렉토리 내에서 일반적인 Git 작업 수행
- 메인 리포지토리 업데이트: 서브모듈 참조 커밋 업데이트
- CI/CD 통합: 서브모듈 변경 감지 및 테스트 자동화
장점:
- 모듈 간 독립성 유지
- 코드 재사용성 향상
주의사항:
- 관리 복잡성 증가 (서브모듈의 버전 동기화 필요)
- 서브모듈 중첩 관리: 복잡한 중첩 구조는 관리 어려움 증가
- CI/CD 에서 서브모듈 초기화를 명확히 처리해야 함
- 학습 곡선: 팀원들이 서브모듈 작업 흐름에 익숙해져야 함
CODEOWNERS
정의:
GitHub, GitLab 등에서 지원하는 기능으로, 특정 파일/디렉토리에 대한 소유자 (리뷰어) 를 명시한다.기본 설정:
대규모 환경에서의 활용:
- 코드 품질 보장: 전문가가 관련 코드 변경 검토
- 지식 공유 촉진: 코드 영역별 전문가 식별
- 책임 명확화: 특정 컴포넌트의 책임자 지정
- 자동 리뷰어 할당: PR 생성 시 관련 소유자에게 자동 알림
활용 효과:
- 자동 리뷰 요청으로 코드 품질 향상
- 책임 분산 및 명확한 코드 소유권 분배
- 보안 강화 (중요 파일에 대한 리뷰 강제화)
활용 팁:
- 팀별 CODEOWNERS 관리 기준을 문서화
- CI 파이프라인과 연동하여 리뷰 없이는 병합 불가하도록 설정
팀 구조 반영:
고급 패턴 활용:
통합 및 자동화:
- PR 승인 규칙 연동: CODEOWNERS 기반 승인 요구사항 설정
- 자동화된 알림: 코드 변경 시 관련 소유자에게 알림
- 문서화 연계: 코드 소유권과 기술 문서 연결
소유권 관리 모범 사례:
- 정기적인 검토 및 업데이트: 조직 변화 반영
- 과도한 알림 방지: 파일별로 소유자 수 제한
- 지식 공유 촉진: 로테이션 또는 멘토링 프로그램과 연계
팀 규모별 브랜칭 전략
팀 규모와 프로젝트 특성에 따라 적합한 브랜칭 전략이 달라진다.
주요 전략들은 다음과 같다:
소규모 팀 (1-10 명)
GitHub Flow:
단순한 단일 메인 브랜치 (main) 전략
모든 변경사항은 기능 브랜치에서 시작하여 PR 을 통해 메인으로 병합
지속적 배포에 적합, 간단한 워크플로우
구현:
트렁크 기반 개발:
대부분의 작업이 직접 메인 브랜치 (트렁크) 에 커밋
복잡한 기능은 짧은 수명의 기능 브랜치로 개발
지속적 통합 강조, 빠른 피드백 루프
구현:
중규모 팀 (10-50 명)
Feature Branch Workflow:
각 기능은 독립된 브랜치에서 개발
코드 리뷰와 자동화된 테스트 후 메인 브랜치로 병합
여러 기능의 병렬 개발에 적합
구현:
환경별 브랜치:
개발 (develop), 스테이징 (staging), 프로덕션 (main) 브랜치 유지
기능은 develop 에 병합 후 환경별로 승격
품질 게이트와 단계적 릴리스 관리에 적합
구현:
대규모 팀 (50 명 이상)
GitFlow:
엄격한 브랜치 구조: main, develop, feature, release, hotfix
명확한 릴리스 주기와 버전 관리
복잡한 프로젝트와 여러 버전 병행 유지에 적합
구현:
확장된 환경 브랜치:
다양한 환경과 단계를 반영하는 브랜치 구조
마이크로서비스 또는 컴포넌트별 브랜치 전략 결합
복잡한 배포 시나리오와 다양한 환경에 적합
구현:
릴리스 트레인 모델:
정기적인 일정에 따라 릴리스 브랜치 생성
특정 기간까지 준비된 기능만 릴리스에 포함
대규모 프로젝트와 안정적인 릴리스 주기 필요 시 적합
구현:
팀 규모별 브랜칭 전략 선택 지침
- 소규모 팀:
- 단순성과 속도 우선
- 소통 오버헤드 최소화
- GitHub Flow 또는 트렁크 기반 개발 추천
- 중규모 팀:
- 명확한 협업 프로세스 필요
- 자동화된 테스트와 코드 리뷰 강화
- Feature Branch Workflow 또는 간소화된 환경별 브랜치 추천
- 대규모 팀:
- 명확한 역할과 책임 정의
- 상세한 문서화와 교육 필요
- 릴리스 프로세스와 규정 준수 고려
- GitFlow, 릴리스 트레인 또는 커스텀 하이브리드 전략 추천
실무 적용 예시
| 산업/분야 | 적용 사례 | 구현 방식 | 성과/이점 |
|---|---|---|---|
| 대형 소프트웨어 기업 | Google 의 모노리포 | 10 억 라인 이상의 코드를 단일 리포지토리에서 관리, 맞춤형 도구 개발 | 코드 재사용 증가, 의존성 관리 단순화, 표준화된 개발 환경 |
| 웹 서비스 | Facebook 의 대규모 Git 리포지토리 | Mercurial 에서 Git 으로 마이그레이션, 사용자 정의 확장 개발 | 빠른 클론 및 체크아웃, 개발자 경험 향상 |
| 게임 개발 | 언리얼 엔진 소스 코드 관리 | Perforce 와 Git 하이브리드 모델, 대용량 에셋 처리 최적화 | 대용량 바이너리 파일 효율적 관리, 분산 팀 협업 개선 |
| 오픈소스 프로젝트 | Linux 커널 개발 | Git 을 사용한 분산 개발 모델, 이메일 기반 패치 관리 | 전 세계 개발자 참여 가능, 성능과 확장성 유지 |
| 금융 서비스 | 투자 은행 트레이딩 플랫폼 | 엄격한 접근 제어와 감사 추적이 가능한 Git 워크플로우, CI/CD 통합 | 규제 준수 강화, 릴리스 안정성 향상 |
| 임베디드 시스템 | 자동차 소프트웨어 개발 | 하드웨어 종속 코드와 일반 코드를 구분한 멀티리포 구조 | 다양한 하드웨어 변형 관리 용이, 모듈 재사용 촉진 |
| 클라우드 서비스 | Microsoft Azure 서비스 개발 | 수백 개의 마이크로서비스를 관리하는 혼합 모노/멀티리포 접근 | 독립적인 서비스 개발과 배포, 전체 시스템 일관성 유지 |
| 대규모 데이터 과학 | Netflix 의 데이터 파이프라인 코드 | 데이터 모델과 처리 로직을 Git 으로 버전 관리, CI/CD 와 통합 | 데이터 파이프라인 변경 이력 추적, 재현 가능한 분석 보장 |
활용 예시
시나리오: 글로벌 금융 서비스 회사의 거래 플랫폼 개발
- 초기 설정:
- 모노리포 구조를 채택하여 거래 플랫폼의 모든 서비스 코드를 단일 Git 리포지토리에 통합
- Git LFS 를 구성하여 대용량 테스트 데이터 파일 관리 최적화
- 지역별 개발팀을 위한 지역 미러 서버 설정
- 개발 워크플로우:
- 트렁크 기반 개발 접근 방식 채택: 개발자는 단기 피처 브랜치에서 작업 후 빠르게 메인 브랜치에 통합
- 모든 코드 변경은 CI 시스템에서 자동 테스트 실행 후 코드 리뷰 통과 필요
- CODEOWNERS 파일을 사용하여 특정 컴포넌트에 대한 전문가 리뷰 강제
- 최적화 전략:
- 개발자는 Sparse Checkout 을 사용하여 필요한 모듈만 체크아웃
- Git Partial Clone 을 통해 필요한 파일만 다운로드하여 대규모 리포지토리 처리 성능 개선
- 서브모듈을 활용하여 공통 라이브러리와 프레임워크를 독립적으로 관리
- 권한 관리:
- 역할 기반 접근 제어를 구현하여 팀과 역할에 따른 권한 할당
- 규제 요구사항을 충족하기 위해 모든 변경 사항에 서명 요구
- 감사 로그를 중앙 보안 시스템과 통합하여 모든 접근 및 변경 추적
- 확장 및 성능:
- 세계 각 지역의 개발자를 위한 캐싱 프록시 서버 배포
- 정기적인 리포지토리 최적화 및 가비지 컬렉션 스케줄링
- 대규모 병합 시나리오에 대한 자동화된 충돌 해결 도구 개발
- 결과:
- 3,000 명 이상의 개발자가 동시에 작업 가능
- 릴리스 주기가 월별에서 주별로 단축
- 코드 품질 개선 및 버그 감소
- 규제 감사 효율성 향상
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 영역 | 고려사항 | 주의할 점 | 권장 사항 |
|---|---|---|---|
| 리포지토리 구조 | 프로젝트 규모와 모듈 간 의존성 | 너무 많은 리포지토리는 관리 복잡성 증가 | 논리적 경계를 기반으로 모노/멀티리포 결정, 점진적 전환 고려 |
| 브랜칭 전략 | 팀 규모, 릴리스 주기, 배포 모델 | 과도하게 복잡한 브랜칭 모델은 개발 흐름 방해 | 최소한의 브랜치 유형으로 시작, 필요에 따라 확장 |
| 접근 제어 | 보안 요구사항, 규제 준수, 팀 구조 | 너무 제한적인 권한은 개발 속도 저하 | 최소 권한 원칙 적용, 필요에 따라 세분화 |
| CI/CD 통합 | 빌드 시간, 테스트 범위, 배포 대상 | 무거운 CI 파이프라인은 버전 관리 성능에 영향 | 증분 빌드, 테스트 캐싱, 병렬 실행 구현 |
| 변경 관리 | 코드 리뷰 정책, 승인 흐름, 품질 게이트 | 과도한 리뷰 요구사항은 개발 속도 저하 | 리스크 기반 리뷰 정책, 자동화된 코드 분석 |
| 팀 문화 | 협업 관행, 지식 공유, 문서화 | 버전 관리 관행의 불일치는 협업 효율성 저하 | 명확한 가이드라인, 교육, 멘토링 프로그램 |
| 마이그레이션 | 레거시 시스템, 기존 이력, 전환 비용 | 급격한 전환은 혼란과 생산성 저하 초래 | 단계적 마이그레이션, 병행 운영 기간 설정 |
| 기술 부채 | 코드 품질, 구조적 문제, 오래된 패턴 | 방치된 기술 부채는 시간이 지날수록 해결 비용 증가 | 정기적인 리팩토링, 지속적 개선 문화 |
| 교육 및 도구 | 개발자 숙련도, 도구 사용성, 학습 곡선 | 복잡한 도구와 부족한 교육은 저항과 오용 초래 | 맞춤형 교육, 명확한 문서화, 사용자 친화적 도구 |
| 측정 및 개선 | 성능 지표, 개발자 경험, 프로세스 효율성 | 측정 없는 변경은 실제 개선인지 확인 불가 | 핵심 지표 정의, 정기적 측정, 피드백 기반 조정 |
| 글로벌 팀 지원 | 시간대 차이, 네트워크 지연, 문화적 차이 | 중앙화된 인프라는 원격 팀에 불리한 경험 제공 | 분산 미러, 비동기 워크플로우, 문화적 고려사항 반영 |
| 확장성 계획 | 성장 예측, 리소스 요구사항, 아키텍처 제한 | 단기적 해결책은 향후 확장 시 병목 현상 초래 | 3-5 년 성장 계획 고려, 확장 가능한 아키텍처 설계 |
최적화하기 위한 고려사항 및 주의할 점
| 영역 | 고려사항 | 주의할 점 | 권장 사항 |
|---|---|---|---|
| 서버 인프라 | 하드웨어 사양, 네트워크 대역폭, 저장소 성능 | 저사양 서버는 대규모 리포지토리 처리 시 병목 현상 | SSD 스토리지, 충분한 메모리, 멀티코어 CPU 구성 |
| 클라이언트 성능 | 로컬 작업 환경, 네트워크 연결성, 디스크 공간 | 사양 미달 클라이언트는 느린 개발 경험 초래 | 최소 요구사항 명시, SSD 권장, 로컬 캐싱 활성화 |
| 네트워크 최적화 | 지리적 분산, 지연 시간, 대역폭 제한 | 원격 위치의 높은 지연 시간은 개발 효율성 저하 | 지역별 미러 서버, HTTP/2 프로토콜, 압축 활성화 |
| 대용량 파일 처리 | 바이너리 에셋, 미디어 파일, 대용량 데이터셋 | Git 내 대용량 파일은 전체 리포지토리 성능에 영향 | Git LFS 구현, 외부 저장소 연계, 자동 필터링 |
| 리포지토리 크기 관리 | 히스토리 크기, 불필요한 파일, 중복 콘텐츠 | 지속적인 크기 증가는 모든 Git 작업 속도 저하 | .gitignore 최적화, 정기적 GC, 불필요 파일 정리 |
| 캐싱 전략 | 객체 캐싱, 메타데이터 캐싱, 인덱스 최적화 | 비효율적 캐싱은 반복 작업 성능 저하 | 객체 캐시 구성, 빠른 저장 매체 활용, 캐시 워밍 |
| 프로토콜 선택 | HTTP vs SSH vs Git, 인증 방식, 보안 요구사항 | 적절하지 않은 프로토콜은 불필요한 오버헤드 발생 | 상황에 맞는 프로토콜 선택, HTTP/2 또는 SSH 권장 |
| 클론 및 체크아웃 최적화 | 리포지토리 크기, 작업 스타일, 개발 패턴 | 전체 리포지토리 클론은 대규모 프로젝트에서 비효율적 | 부분 클론, 얕은 클론, Sparse 체크아웃 활용 |
| 병합 성능 | 브랜치 크기, 충돌 복잡성, 병합 빈도 | 대규모 병합은 심각한 성능 병목 및 충돌 위험 | 자주 병합, 작은 변경 단위, 자동 충돌 해결 도구 |
| 객체 스토리지 최적화 | 압축률, 참조 효율성, 가비지 컬렉션 | 비효율적 객체 저장은 디스크 공간 낭비 및 성능 저하 | 정기적 리팩, 패킹 최적화, 압축 설정 조정 |
| 분산 작업 지원 | 오프라인 작업, 부분 동기화, 병렬 처리 | 전체 동기화 의존성은 분산 환경에서 작업 어려움 | 번들 기능 활용, 부분 푸시/풀, 로컬 캐싱 강화 |
| 모니터링 및 진단 | 성능 지표, 병목 현상 식별, 문제 해결 | 모니터링 부재는 성능 저하 원인 파악 어려움 | 시스템 모니터링 구축, 성능 벤치마크, 정기 검토 |
| 백업 및 복구 최적화 | 백업 주기, 증분 백업, 복구 시간 | 비효율적 백업은 저장 공간 낭비 및 복구 시간 증가 | 증분 백업, 병렬 백업 프로세스, 복구 테스트 |
| 자동화 및 스크립팅 | 반복 작업, 유지보수 활동, 최적화 프로세스 | 수동 최적화 의존은 일관성 부족 및 누락 위험 | 자동화된 유지보수 스크립트, 성능 모니터링 자동화 |
최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 확장성 | 서버리스 Git 아키텍처 | 클라우드 기반 Git 인프라로 확장성을 극대화하는 접근법 등장 |
| 분산 스토리지 최적화 | 블록체인 기술을 응용한 분산 저장 방식으로 대규모 리포지토리 성능 개선 | |
| 자동화 | AI 기반 코드 리뷰 | 머신러닝을 활용한 자동 코드 리뷰와 품질 검사 도구 통합 |
| 스마트 병합 도구 | 충돌 해결을 자동화하고 최적의 병합 전략을 제안하는 AI 기반 도구 | |
| 모노리포 | 멀티레이어 모노리포 | 논리적 분리와 물리적 통합을 결합한 하이브리드 모노리포 아키텍처 |
| 모노리포 특화 도구 | Nx, Turborepo 등 대규모 모노리포를 효율적으로 관리하는 전용 도구 성장 | |
| 개발자 경험 | 클라우드 개발 환경 통합 | GitHub Codespaces, GitPod 등 클라우드 개발 환경과 버전 관리 통합 |
| 시각적 버전 관리 도구 | 복잡한 버전 관리 개념을 직관적으로 시각화하는 도구 발전 | |
| 보안 및 규정 준수 | 고급 정적 분석 통합 | 코드 커밋 및 PR 시 자동화된 보안 취약점 및 라이센스 검사 |
| 서명 기반 워크플로우 | 모든 커밋에 디지털 서명을 요구하는 제로 트러스트 접근법 확산 | |
| 분산 협업 | 이벤트 기반 동기화 | 메시지 큐와 이벤트 스트리밍을 활용한 고성능 리포지토리 동기화 |
| 하이브리드 작업 최적화 | 원격 및 사무실 개발자를 위한 최적화된 버전 관리 워크플로우 |
주목해야 할 기술
| 주제 | 항목 | 설명 |
|---|---|---|
| 분산 저장 | 메모리 중심 Git 프로토콜 | RAM 기반 처리로 대규모 리포지토리 성능을 크게 향상시키는 새로운 프로토콜 |
| 블록 수준 중복 제거 | 파일이 아닌 콘텐츠 블록 단위로 중복을 제거하여 스토리지 효율성 극대화 | |
| AI 통합 | 코드 변경 예측 | 패턴 학습을 통해 코드 변경의 영향을 예측하고 테스트 전략 제안 |
| 자연어 커밋 분석 | 커밋 메시지와 코드 변경을 분석하여 문서화 자동화 및 지식 관리 | |
| 협업 도구 | 실시간 코드 협업 | Google Docs 와 유사한 실시간 코드 편집 및 버전 관리 통합 |
| 대화형 코드 리뷰 | 브랜치와 PR 에 직접 음성 및 비디오 코멘트를 추가할 수 있는 대화형 리뷰 | |
| 구조적 병합 | 의미 기반 병합 | 구문 트리와 의미 분석을 활용한 지능형 자동 병합 기술 |
| 코드 리팩토링 인식 병합 | 리팩토링과 기능 변경을 구분하여 병합 충돌 감소 | |
| 성능 최적화 | 압축 및 인덱싱 혁신 | 새로운 압축 알고리즘과 인덱싱 기술을 통한 대규모 리포지토리 성능 개선 |
| 네트워크 프로토콜 최적화 | HTTP/3 및 QUIC 기반 Git 프로토콜로 네트워크 지연 최소화 | |
| 규정 준수 | 자동화된 감사 추적 | 모든 변경 사항에 대한 불변의 감사 기록을 자동으로 생성하는 기술 |
| 정책 as 코드 | 버전 관리 정책을 코드로 정의하고 자동으로 적용하는 접근법 | |
| Git 대안 | Jujutsu (JJ) | Rust 기반의 Git 대체 버전 관리 도구로, 직관적인 UI 와 강력한 히스토리 편집 기능 제공 |
| 대용량 관리 | Git LFS 3.x | 성능 개선 및 스토리지 정책이 강화된 Git LFS 최신 버전 |
앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 인공지능 혁신 | 자율적 코드 관리 | AI 가 자동으로 코드 품질, 의존성, 보안을 모니터링하고 개선 제안 |
| 지능형 협업 조정 | 팀 구성, 작업 할당, 리뷰어 선정을 최적화하는 AI 기반 협업 관리 | |
| 인프라 발전 | 양자 저장 기술 | 양자 컴퓨팅을 활용한 초고속, 초대용량 버전 관리 시스템 |
| 에지 컴퓨팅 통합 | 지역 에지 노드를 활용한 전 세계적으로 분산된 개발 팀을 위한 초저지연 접근 | |
| 클라우드 통합 | Git-as-a-Service | Git 리포지토리 자체를 클라우드 서비스화하여 관리 자동화 확대 |
| 방법론 변화 | GitOps 의 주류화 | 인프라와 애플리케이션 구성을 Git 으로 관리하는 방식의 표준화 |
| 마이크로서비스 버전 관리 | 서비스 단위 독립 버전 관리와 통합 거버넌스의 균형에 초점 | |
| 지식 관리 중심화 | 코드 변경을 넘어 의사결정과 지식 관리 플랫폼으로 진화 | |
| 사용자 인터페이스 | 가상현실 코드 협업 | VR/AR 환경에서 팀이 코드베이스를 시각적으로 탐색하고 협업하는 도구 |
| 자연어 기반 버전 관리 | 음성 명령과 자연어 인터페이스를 통한 버전 관리 시스템 제어 | |
| 규제 환경 | 디지털 증거 표준화 | 법적 요구사항을 충족하는 코드 변경 이력의 증거 보존 표준 |
| 윤리적 AI 개발 추적 | AI 시스템 개발의 결정과 변경을 추적하고 감사하는 특수 버전 관리 도구 | |
| 보안 우선 | Git-based SAST 강화 | Git 내 정적 분석 및 보안 검사 기능이 커밋 시점에서 작동 |
추가 학습 주제
| 카테고리 | 주제 | 간략한 설명 |
|---|---|---|
| 고급 Git 기술 | Git 내부 구조 및 객체 모델 | Git 의 내부 저장 메커니즘, 객체 유형, 참조 시스템의 심층 이해 |
| Git 확장 및 훅 시스템 | 자체 Git 명령과 자동화 워크플로우 구현을 위한 확장 메커니즘 | |
| Git 프로토콜 및 전송 최적화 | 네트워크 프로토콜, 압축, 패킹 알고리즘의 최적화 | |
| 대규모 버전 관리 아키텍처 | 분산 버전 관리 시스템 설계 | 글로벌 규모의 DVCS 설계 원칙 및 아키텍처 패턴 |
| 고가용성 Git 서버 구성 | 장애 내성과 확장성을 갖춘 엔터프라이즈 Git 인프라 구축 | |
| 재해 복구 및 백업 전략 | 대규모 리포지토리의 백업, 복구, 연속성 계획 | |
| 성능 최적화 | Git 벤치마킹 및 성능 분석 | 리포지토리 성능 측정, 병목 현상 식별, 최적화 기회 평가 |
| 대규모 리포지토리 리팩토링 전략 | 기존 대형 리포지토리의 구조 재구성 및 최적화 방법 | |
| 캐싱 및 미러링 전략 | 글로벌 개발 팀을 위한 분산 캐싱 및 미러링 설계 | |
| 워크플로우 및 자동화 | CI/CD 파이프라인 통합 | 버전 관리와 지속적 통합/배포 시스템의 효율적인 통합 |
| 자동화된 코드 리뷰 시스템 구축 | 대규모 팀을 위한 효율적인 코드 리뷰 프로세스 자동화 | |
| GitOps 워크플로우 구현 | 인프라 및 애플리케이션 관리에 Git 기반 운영 방식 적용 | |
| 소프트웨어 공급망 보안 | 이력 관리와 소프트웨어 공급망 보안 | 코드 출처, 변경 이력, 취약점 추적을 통한 보안 강화 |
| 서명 및 검증 워크플로우 | 코드 무결성과 출처를 보장하는 암호화 서명 체계 | |
| 이중 인증 및 보안 정책 구현 | 보안 규정 준수를 위한 버전 관리 시스템 보안 강화 방안 |
관련 분야 학습 주제
| 카테고리 | 주제 | 간략한 설명 |
|---|---|---|
| 소프트웨어 아키텍처 | 모노리포 vs 멀티리포 설계 | 대규모 코드베이스 구성에 대한 아키텍처 접근법 비교 |
| 마이크로서비스 버전 관리 | 분산 서비스 아키텍처에서의 버전 관리 전략 | |
| 컴포넌트 기반 개발과 버전 관리 | 재사용 가능한 컴포넌트 개발과 버전 관리의 연계 | |
| DevOps | GitOps 방법론 | Git 을 중심으로 한 인프라 및 애플리케이션 관리 방식 |
| 배포 파이프라인 설계 | 버전 관리와 통합된 CI/CD 파이프라인 구축 | |
| 불변 인프라와 버전 관리 | 코드로서의 인프라와 Git 기반 구성 관리 | |
| 데이터베이스 및 스토리지 | 대용량 객체 스토리지 | Git LFS 와 유사한 대용량 파일 관리 시스템의 설계 및 구현 |
| 분산 데이터베이스 설계 | 글로벌 분산 환경을 위한 데이터 저장 및 동기화 전략 | |
| 시계열 데이터와 이력 관리 | 시간에 따른 데이터 변화 추적을 위한 저장 기술 | |
| 협업 및 프로젝트 관리 | 분산 팀 관리 방법론 | 지리적으로 분산된 팀의 효율적인 협업 체계 구축 |
| 지식 관리 시스템 | 코드 이력과 개발 결정 사항의 문서화 및 지식화 | |
| 애자일 개발과 버전 관리 통합 | 애자일 방법론에 최적화된 버전 관리 워크플로우 | |
| 보안 및 규정 준수 | 규제 환경의 변경 관리 | 금융, 의료 등 규제 산업의 코드 변경 관리 요구사항 |
| 사이버 보안과 코드 이력 | 보안 감사 및 위협 감지를 위한 코드 변경 분석 | |
| 개인정보 보호와 버전 관리 | 민감한 정보의 안전한 관리를 위한 버전 관리 전략 |
용어 정리
| 용어 | 설명 |
|---|---|
| 모노리포 (Monorepo) | 여러 프로젝트와 라이브러리를 단일 리포지토리에서 관리하는 방식 |
| 멀티리포 (Multirepo) | 각 프로젝트나 컴포넌트를 독립된 리포지토리로 관리하는 방식 |
| Git LFS(Large File Storage) | 대용량 바이너리 파일을 효율적으로 관리하기 위한 Git 확장 |
| Sparse Checkout | 리포지토리의 일부 파일이나 디렉토리만 작업 공간에 체크아웃하는 기능 |
| Git Hooks | 특정 Git 이벤트 발생 시 자동으로 실행되는 스크립트 |
| GitOps | Git 을 단일 진실 소스로 사용하여 인프라와 애플리케이션을 관리하는 방법론 |
| Shallow Clone | 전체 이력이 아닌 최근 일부 커밋만 복제하는 방식 |
| Partial Clone | 리포지토리의 모든 객체가 아닌 필요한 객체만 선택적으로 복제하는 기능 |
| Branch Protection Rules | 중요 브랜치의 변경사항을 제어하고 품질을 보장하기 위한 규칙 |
| Delta Compression | 연속된 버전 간의 차이만을 저장하여 공간을 절약하는 기술 |
| GPG 서명 | 커밋에 대한 암호화된 서명을 통해 작성자를 인증하는 기능 |
| Submodule | 다른 Git 리포지토리를 현재 리포지토리의 하위 모듈로 포함시키는 기능 |
| CODEOWNERS | 파일별 책임자를 지정하여 자동 리뷰를 강제하는 Git 기능 |
참고 및 출처
- Version Control Systems 비교표
- Git Partial Clone 문서
- AI 기반 VCS 트렌드
- Partial Clone 소개 – GitLab 공식 블로그
- Git Shallow Clone 설명 – GeeksForGeeks
- CODEOWNERS 문서 – GitHub Docs
- Git Submodule 공식 문서
- Git Protocol V2 소개 – Git 공식 블로그
- GitOps에 대한 CNCF 공식 문서
- Git 공식 문서
- GitHub 대규모 리포지토리 관리 가이드
- Google의 모노리포 접근법에 관한 논문
- Microsoft DevOps 블로그: 대규모 Git
- Facebook의 대규모 Git 사용 사례 연구
- Git 내부 구조 해설서
- LinkedIn의 GitOps 적용 사례
- Uber의 대규모 모노리포 관리 전략