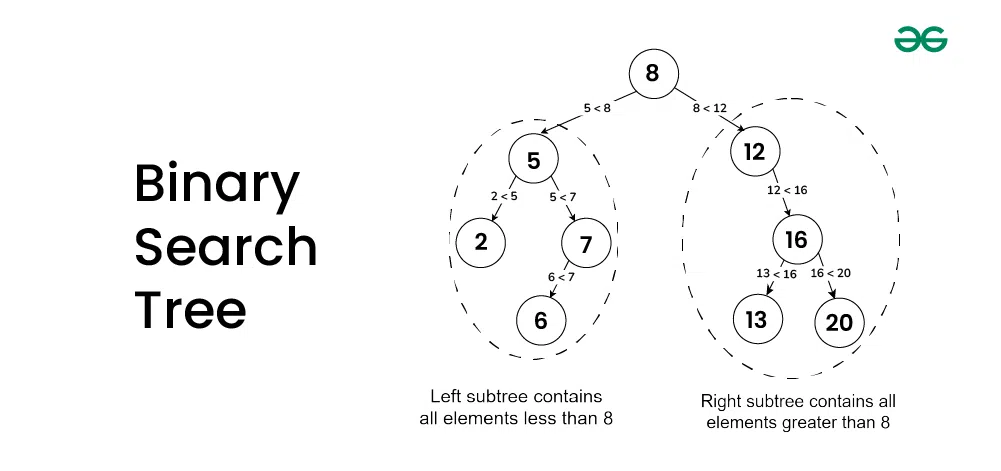
classTreeNode:def__init__(self,key):self.key=key# 노드의 키 값self.left=None# 왼쪽 자식 노드self.right=None# 오른쪽 자식 노드def__str__(self):returnstr(self.key)classBinarySearchTree:def__init__(self):self.root=None# 트리의 루트 노드# 기본 연산들은 다음 섹션에서 구현할 예정입니다.
defsearch(self,key):"""이진 검색 트리에서 키 값을 검색"""returnself._search_recursive(self.root,key)def_search_recursive(self,node,key):# 기본 경우: 노드가 없거나 찾는 키와 일치하는 경우ifnodeisNoneornode.key==key:returnnode# 키가 현재 노드보다 작으면 왼쪽 서브트리에서 검색ifkey<node.key:returnself._search_recursive(node.left,key)# 키가 현재 노드보다 크면 오른쪽 서브트리에서 검색else:returnself._search_recursive(node.right,key)
defsearch_iterative(self,key):"""이진 검색 트리에서 키 값을 반복적으로 검색"""current=self.rootwhilecurrentisnotNone:ifcurrent.key==key:returncurrentelifkey<current.key:current=current.leftelse:current=current.rightreturnNone# 키를 찾지 못한 경우
definsert(self,key):"""이진 검색 트리에 키 삽입"""self.root=self._insert_recursive(self.root,key)def_insert_recursive(self,node,key):# 삽입 위치에 도달한 경우 새 노드 생성ifnodeisNone:returnTreeNode(key)# 키가 현재 노드보다 작으면 왼쪽 서브트리에 삽입ifkey<node.key:node.left=self._insert_recursive(node.left,key)# 키가 현재 노드보다 크면 오른쪽 서브트리에 삽입elifkey>node.key:node.right=self._insert_recursive(node.right,key)# 키가 이미 존재하는 경우 (중복 처리 방식에 따라 다름)else:returnnode# 중복 무시 (또는 다른 처리)returnnode
definsert_iterative(self,key):"""이진 검색 트리에 키를 반복적으로 삽입"""new_node=TreeNode(key)# 트리가 비어있는 경우ifself.rootisNone:self.root=new_nodereturncurrent=self.rootparent=NonewhilecurrentisnotNone:parent=currentifkey<current.key:current=current.leftelifkey>current.key:current=current.rightelse:return# 중복 키는 무시 (또는 다른 처리)# 새 노드를 부모 노드에 연결ifkey<parent.key:parent.left=new_nodeelse:parent.right=new_node
defdelete(self,key):"""이진 검색 트리에서 키 삭제"""self.root=self._delete_recursive(self.root,key)def_delete_recursive(self,node,key):# 기본 경우: 키를 찾지 못한 경우ifnodeisNone:returnNone# 삭제할 키 찾기ifkey<node.key:node.left=self._delete_recursive(node.left,key)elifkey>node.key:node.right=self._delete_recursive(node.right,key)else:# 삭제할 노드를 찾은 경우# 경우 1 & 2: 자식이 없거나 하나인 경우ifnode.leftisNone:returnnode.rightelifnode.rightisNone:returnnode.left# 경우 3: 두 자식이 있는 경우# 중위 후속자(오른쪽 서브트리에서 가장 작은 노드)를 찾음successor=self._find_min(node.right)node.key=successor.key# 후속자의 키를 현재 노드로 복사# 중위 후속자 삭제node.right=self._delete_recursive(node.right,successor.key)returnnodedef_find_min(self,node):"""트리의 최소값(가장 왼쪽) 노드 찾기"""current=nodewhilecurrent.leftisnotNone:current=current.leftreturncurrent
definorder_traversal(self):"""중위 순회로 노드 방문 (정렬된 순서)"""result=[]self._inorder_recursive(self.root,result)returnresultdef_inorder_recursive(self,node,result):ifnodeisnotNone:self._inorder_recursive(node.left,result)# 왼쪽 서브트리 방문result.append(node.key)# 현재 노드 방문self._inorder_recursive(node.right,result)# 오른쪽 서브트리 방문
defpreorder_traversal(self):"""전위 순회로 노드 방문"""result=[]self._preorder_recursive(self.root,result)returnresultdef_preorder_recursive(self,node,result):ifnodeisnotNone:result.append(node.key)# 현재 노드 방문self._preorder_recursive(node.left,result)# 왼쪽 서브트리 방문self._preorder_recursive(node.right,result)# 오른쪽 서브트리 방문
defpostorder_traversal(self):"""후위 순회로 노드 방문"""result=[]self._postorder_recursive(self.root,result)returnresultdef_postorder_recursive(self,node,result):ifnodeisnotNone:self._postorder_recursive(node.left,result)# 왼쪽 서브트리 방문self._postorder_recursive(node.right,result)# 오른쪽 서브트리 방문result.append(node.key)# 현재 노드 방문
deffind_min(self):"""트리의 최소 키 값 찾기"""ifself.rootisNone:returnNonecurrent=self.rootwhilecurrent.leftisnotNone:current=current.leftreturncurrent.keydeffind_max(self):"""트리의 최대 키 값 찾기"""ifself.rootisNone:returnNonecurrent=self.rootwhilecurrent.rightisnotNone:current=current.rightreturncurrent.key
defget_height(self,node):"""노드의 높이 계산"""ifnodeisNone:return-1returnmax(self.get_height(node.left),self.get_height(node.right))+1defget_balance_factor(self,node):"""노드의 균형 요소 계산"""ifnodeisNone:return0returnself.get_height(node.left)-self.get_height(node.right)
classAVLNode(TreeNode):def__init__(self,key):super().__init__(key)self.height=0# 노드의 높이classAVLTree(BinarySearchTree):def__init__(self):super().__init__()def_get_height(self,node):ifnodeisNone:return-1returnnode.heightdef_update_height(self,node):ifnodeisnotNone:node.height=max(self._get_height(node.left),self._get_height(node.right))+1def_get_balance(self,node):ifnodeisNone:return0returnself._get_height(node.left)-self._get_height(node.right)def_left_rotate(self,x):y=x.rightT2=y.left# 회전 수행y.left=xx.right=T2# 높이 업데이트self._update_height(x)self._update_height(y)returny# 새 루트 반환def_right_rotate(self,y):x=y.leftT2=x.right# 회전 수행x.right=yy.left=T2# 높이 업데이트self._update_height(y)self._update_height(x)returnx# 새 루트 반환definsert(self,key):"""AVL 트리에 키 삽입"""self.root=self._insert_recursive(self.root,key)def_insert_recursive(self,node,key):# 일반 BST 삽입ifnodeisNone:returnAVLNode(key)ifkey<node.key:node.left=self._insert_recursive(node.left,key)elifkey>node.key:node.right=self._insert_recursive(node.right,key)else:returnnode# 중복 키는 무시# 노드 높이 업데이트self._update_height(node)# 균형 요소 확인balance=self._get_balance(node)# 균형이 깨진 경우 회전으로 복구# 좌-좌 케이스ifbalance>1andkey<node.left.key:returnself._right_rotate(node)# 우-우 케이스ifbalance<-1andkey>node.right.key:returnself._left_rotate(node)# 좌-우 케이스ifbalance>1andkey>node.left.key:node.left=self._left_rotate(node.left)returnself._right_rotate(node)# 우-좌 케이스ifbalance<-1andkey<node.right.key:node.right=self._right_rotate(node.right)returnself._left_rotate(node)returnnode
def_preorder_recursive(self,node,result):ifnodeisnotNone:result.append(node.key)# 현재 노드 방문self._preorder_recursive(node.left,result)# 왼쪽 서브트리 방문self._preorder_recursive(node.right,result)# 오른쪽 서브트리 방문defpostorder_traversal(self):"""후위 순회로 노드 방문"""result=[]self._postorder_recursive(self.root,result)returnresultdef_postorder_recursive(self,node,result):ifnodeisnotNone:self._postorder_recursive(node.left,result)# 왼쪽 서브트리 방문self._postorder_recursive(node.right,result)# 오른쪽 서브트리 방문result.append(node.key)# 현재 노드 방문defget_height(self):"""트리의 높이 계산"""returnself._height_recursive(self.root)def_height_recursive(self,node):ifnodeisNone:return-1left_height=self._height_recursive(node.left)right_height=self._height_recursive(node.right)returnmax(left_height,right_height)+1defis_bst(self):"""이진 검색 트리 속성을 만족하는지 확인"""returnself._is_bst_recursive(self.root,float('-inf'),float('inf'))def_is_bst_recursive(self,node,min_val,max_val):# 빈 트리는 BST 속성을 만족ifnodeisNone:returnTrue# 현재 노드가 범위를 벗어나면 BST가 아님ifnode.key<=min_valornode.key>=max_val:returnFalse# 왼쪽과 오른쪽 서브트리가 BST인지 재귀적으로 확인return(self._is_bst_recursive(node.left,min_val,node.key)andself._is_bst_recursive(node.right,node.key,max_val))
defrange_query(self,low,high):"""low와 high 사이의 모든 키 값 반환"""result=[]self._range_query_recursive(self.root,low,high,result)returnresultdef_range_query_recursive(self,node,low,high,result):ifnodeisNone:return# 현재 노드가 범위 내에 있는지 확인iflow<=node.key<=high:# 중위 순회와 유사한 방식으로 진행self._range_query_recursive(node.left,low,high,result)# 왼쪽 서브트리 탐색result.append(node.key)# 현재 노드 추가self._range_query_recursive(node.right,low,high,result)# 오른쪽 서브트리 탐색# 현재 노드가 범위보다 크면 왼쪽 서브트리만 탐색elifnode.key>high:self._range_query_recursive(node.left,low,high,result)# 현재 노드가 범위보다 작으면 오른쪽 서브트리만 탐색elifnode.key<low:self._range_query_recursive(node.right,low,high,result)
순위 쿼리(Rank Query) 주어진 키보다 작은 키의 개수를 찾는 연산. 이를 구현하려면 각 노드가 자신의 왼쪽 서브트리에 있는 노드의 수를 추적해야 한다.
classRankTreeNode(TreeNode):def__init__(self,key):super().__init__(key)self.left_size=0# 왼쪽 서브트리의 노드 수classRankBST(BinarySearchTree):def__init__(self):super().__init__()definsert(self,key):"""순위 정보를 유지하며 키 삽입"""self.root=self._insert_with_rank(self.root,key)def_insert_with_rank(self,node,key):ifnodeisNone:returnRankTreeNode(key)ifkey<node.key:node.left=self._insert_with_rank(node.left,key)node.left_size+=1# 왼쪽 서브트리에 노드 추가elifkey>node.key:node.right=self._insert_with_rank(node.right,key)returnnodedefrank(self,key):"""주어진 키보다 작은 키의 개수"""returnself._rank_recursive(self.root,key)def_rank_recursive(self,node,key):ifnodeisNone:return0ifkey<node.key:returnself._rank_recursive(node.left,key)elifkey>node.key:# 현재 노드와 왼쪽 서브트리의 크기 + 오른쪽 서브트리의 순위returnnode.left_size+1+self._rank_recursive(node.right,key)else:# key == node.keyreturnnode.left_size
근사 검색(Nearest Neighbor Search) 주어진 키에 가장 가까운 키를 찾는 연산.
deffind_nearest(self,key):"""주어진 키에 가장 가까운 키 찾기"""ifself.rootisNone:returnNonenearest=self.root.keymin_diff=abs(key-nearest)current=self.rootwhilecurrentisnotNone:# 현재 노드와 키 사이의 차이 계산current_diff=abs(key-current.key)# 더 가까운 노드를 찾으면 업데이트ifcurrent_diff<min_diff:nearest=current.keymin_diff=current_diff# 키가 같으면 정확한 일치를 찾은 것이므로 종료ifcurrent.key==key:returnkey# 트리를 순회ifkey<current.key:current=current.leftelse:current=current.rightreturnnearest
이진 검색 트리를 사용한 동적 집합 연산 이진 검색 트리는 집합이나 맵 자료구조를 구현하는 데 사용될 수 있으며, 다음과 같은 동적 집합 연산을 지원한다.
defunion(self,other_bst):"""두 BST의 합집합"""# 다른 BST의 모든 노드를 현재 BST에 삽입elements=other_bst.inorder_traversal()forkeyinelements:self.insert(key)defintersection(self,other_bst):"""두 BST의 교집합"""result=BinarySearchTree()elements=self.inorder_traversal()# 현재 BST의 요소 중 다른 BST에도 있는 요소만 삽입forkeyinelements:ifother_bst.search(key):result.insert(key)returnresultdefdifference(self,other_bst):"""현재 BST에서 다른 BST의 요소를 제외한 차집합"""result=BinarySearchTree()elements=self.inorder_traversal()# 현재 BST의 요소 중 다른 BST에 없는 요소만 삽입forkeyinelements:ifnotother_bst.search(key):result.insert(key)returnresult
defmin_distance(self):"""BST에서 인접한 키 사이의 최소 거리"""# 중위 순회로 정렬된 키 목록 얻기keys=self.inorder_traversal()iflen(keys)<2:returnfloat('inf')# 노드가 부족한 경우min_diff=float('inf')foriinrange(1,len(keys)):diff=keys[i]-keys[i-1]min_diff=min(min_diff,diff)returnmin_diff
defkth_smallest(self,k):"""BST에서 k번째로 작은 요소"""# 중위 순회로 정렬된 키 목록 얻기keys=self.inorder_traversal()if1<=k<=len(keys):returnkeys[k-1]else:returnNone# k가 범위를 벗어나면 None 반환
defkth_smallest_optimized(self,k):"""BST에서 k번째로 작은 요소 (최적화 버전)"""count=[0]# 방문한 노드 수 추적result=[None]# 결과 저장용 변수 (배열로 전달하여 변경 가능하게 함)definorder(node):ifnodeisNoneorcount[0]>=k:returninorder(node.left)count[0]+=1ifcount[0]==k:result[0]=node.keyreturninorder(node.right)inorder(self.root)returnresult[0]
이진 검색 트리의 두 노드 사이의 최소 공통 조상(LCA) 두 노드의 가장 가까운 공통 조상을 찾는 문제.
deflowest_common_ancestor(self,p,q):"""두 키의 최소 공통 조상 찾기"""returnself._lca_recursive(self.root,p,q)def_lca_recursive(self,node,p,q):# 기본 경우ifnodeisNone:returnNone# 둘 다 현재 노드보다 작으면 왼쪽 서브트리에서 LCA 찾기ifp<node.keyandq<node.key:returnself._lca_recursive(node.left,p,q)# 둘 다 현재 노드보다 크면 오른쪽 서브트리에서 LCA 찾기ifp>node.keyandq>node.key:returnself._lca_recursive(node.right,p,q)# 현재 노드가 두 키 사이에 있거나 둘 중 하나와 같으면 LCAreturnnode.key
classMapNode:def__init__(self,key,value):self.key=key# 검색에 사용되는 키self.value=value# 키와 연관된 값self.left=Noneself.right=NoneclassTreeMap:def__init__(self):self.root=Nonedefput(self,key,value):"""키-값 쌍 삽입 또는 업데이트"""self.root=self._put_recursive(self.root,key,value)def_put_recursive(self,node,key,value):ifnodeisNone:returnMapNode(key,value)ifkey<node.key:node.left=self._put_recursive(node.left,key,value)elifkey>node.key:node.right=self._put_recursive(node.right,key,value)else:node.value=value# 키가 존재하면 값 업데이트returnnodedefget(self,key):"""키에 해당하는 값 검색"""node=self._get_recursive(self.root,key)returnnode.valueifnodeelseNonedef_get_recursive(self,node,key):ifnodeisNone:returnNoneifkey<node.key:returnself._get_recursive(node.left,key)elifkey>node.key:returnself._get_recursive(node.right,key)else:returnnodedefdelete(self,key):"""키-값 쌍 삭제"""self.root=self._delete_recursive(self.root,key)def_delete_recursive(self,node,key):# 기본 삭제 로직은 일반 BST와 동일# …
classTreeSet:def__init__(self):self.bst=BinarySearchTree()# 내부적으로 BST 사용defadd(self,key):"""세트에 키 추가"""self.bst.insert(key)defcontains(self,key):"""세트에 키가 포함되어 있는지 확인"""returnself.bst.search(key)defremove(self,key):"""세트에서 키 제거"""self.bst.delete(key)defsize(self):"""세트에 있는 요소 수"""returnlen(self.bst.inorder_traversal())defto_list(self):"""세트의 모든 요소를 정렬된 목록으로 반환"""returnself.bst.inorder_traversal()
classMultiSetNode:def__init__(self,key,count=1):self.key=key# 키 값self.count=count# 키의 빈도수self.left=Noneself.right=NoneclassMultiSet:def__init__(self):self.root=Noneself.size=0# 총 요소 수 (중복 포함)defadd(self,key):"""멀티셋에 키 추가"""result=self._add_recursive(self.root,key)self.root=result[0]self.size+=result[1]# 크기 증가 여부def_add_recursive(self,node,key):ifnodeisNone:return(MultiSetNode(key),1)# (새 노드, 크기 증가 1)size_change=0ifkey<node.key:result=self._add_recursive(node.left,key)node.left=result[0]size_change=result[1]elifkey>node.key:result=self._add_recursive(node.right,key)node.right=result[0]size_change=result[1]else:node.count+=1# 키가 존재하면 카운트 증가size_change=1return(node,size_change)defremove(self,key):"""멀티셋에서 키 하나 제거"""ifself.rootisNone:returnresult=self._remove_recursive(self.root,key)self.root=result[0]self.size-=result[1]# 크기 감소 여부def_remove_recursive(self,node,key):ifnodeisNone:return(None,0)# (노드 없음, 크기 변화 없음)size_change=0ifkey<node.key:result=self._remove_recursive(node.left,key)node.left=result[0]size_change=result[1]elifkey>node.key:result=self._remove_recursive(node.right,key)node.right=result[0]size_change=result[1]else:# 키를 찾은 경우ifnode.count>1:node.count-=1# 카운트 감소size_change=1else:# 노드 삭제 (기본 BST 삭제 로직)# …size_change=1return(node,size_change)defcount(self,key):"""멀티셋에서 키의 빈도수"""node=self._find_node(self.root,key)returnnode.countifnodeelse0def_find_node(self,node,key):ifnodeisNone:returnNoneifkey<node.key:returnself._find_node(node.left,key)elifkey>node.key:returnself._find_node(node.right,key)else:returnnode
classCachingBST(BinarySearchTree):def__init__(self,cache_size=10):super().__init__()self.cache={}# 키-노드 캐시self.cache_size=cache_sizeself.access_count={}# 각 키의 접근 횟수defsearch(self,key):# 캐시에서 먼저 검색ifkeyinself.cache:self.access_count[key]+=1returnTrue# 트리에서 검색found=super().search(key)# 찾았으면 캐시에 추가iffound:self._add_to_cache(key)returnfounddef_add_to_cache(self,key):# 캐시가 가득 찼으면 가장 적게 접근한 항목 제거iflen(self.cache)>=self.cache_size:min_key=min(self.access_count.items(),key=lambdax:x[1])[0]delself.cache[min_key]delself.access_count[min_key]# 캐시에 노드 추가node=self._search_recursive(self.root,key)self.cache[key]=nodeself.access_count[key]=1
병렬 처리(Parallel Processing) 이진 검색 트리의 연산을 병렬화하여 성능을 향상시킬 수 있다. 예를 들어, 큰 데이터셋을 여러 서브트리로 분할하고 각 서브트리를 병렬로 처리할 수 있다.