배열 (Array)
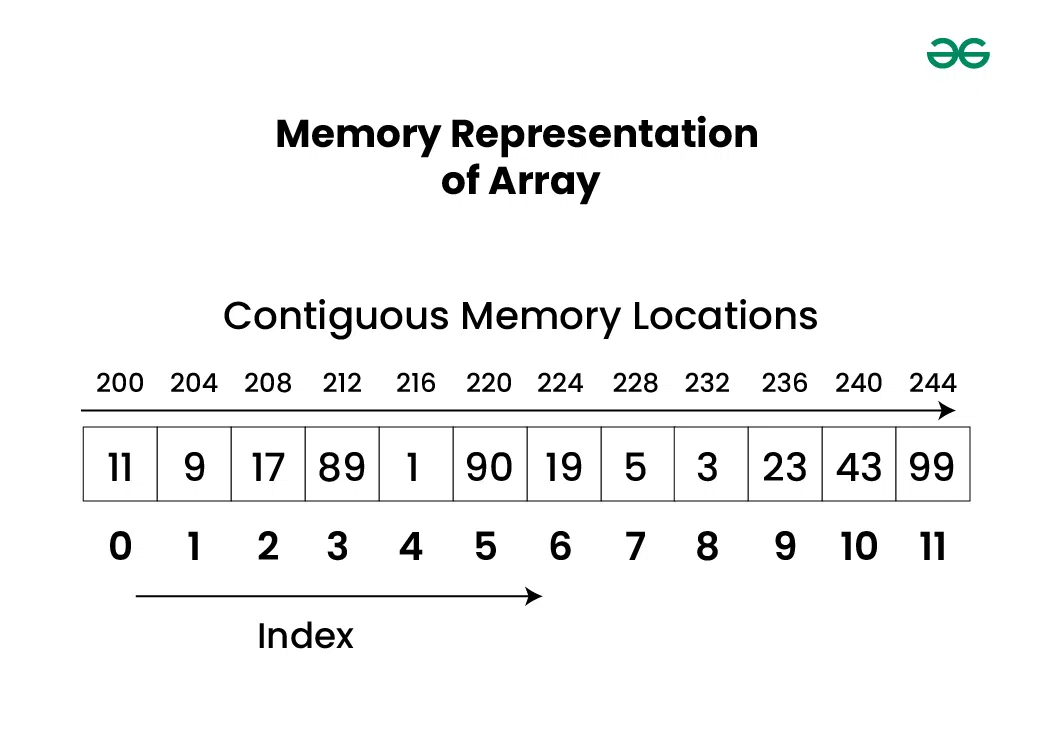
배열은 동일한 데이터 타입의 여러 값을 연속적인 메모리 공간에 순차적으로 저장하는 선형 자료구조로, 인덱스를 통해 빠른 접근이 가능한 특징이 있다.
배열은 초기 한 번 선언 시 정해진 크기를 가지며, 이 크기를 변경하기 어렵기 때문에 메모리 관리와 연산 측면에서 장단점을 지니고 있다.
- 배열은 같은 데이터 타입의 값들을 하나의 변수명으로 관리하며, 각 요소는 메모리상에 연속된 위치에 저장된다.
- **인덱스(index)**를 이용하여 원하는 위치의 데이터를 빠르게 검색할 수 있으며, 대부분 0번부터 시작하는 경우가 많다.
- 배열은 선형 자료구조이므로, 요소들이 순차적으로 배치되어 있어 특정 인덱스에 접근할 때 기본 위치에 오프셋을 더하는 방식으로 계산된다.
배열의 특징
연속성
배열의 요소들은 메모리상에 연속적으로 저장된다.
이는 요소에 빠르게 접근할 수 있게 해주지만, 크기 변경에는 제약이 있다.인덱싱
배열의 각 요소는 고유한 인덱스 번호를 가지며, 이 인덱스를 통해 O(1) 시간 복잡도로 직접 접근이 가능하다.고정된 크기(일부 언어)
C와 같은 일부 언어에서는 배열 선언 시 크기를 미리 지정해야 하며, 이후 변경이 불가능하다.
반면 JavaScript, Python 등 동적 언어에서는 크기가 자유롭게 변할 수 있다.동일한 데이터 타입
전통적인 배열은 모든 요소가 동일한 데이터 타입을 가져야 한다. 이는 메모리 계산을 단순화하고 효율적인 저장을 가능하게 한다.
배열의 장점
- 빠른 검색 및 접근: 인덱스를 통한 직접 접근(random access)이 가능하여 데이터 검색이 빠르다.
- 캐시 효율성: 메모리 공간이 연속적이기 때문에 캐시 지역성(Cache Locality) 활용하여 캐시 적중률이 높아 성능에 유리하다.
- 구현이 간단함: 한 번 선언하면 요소 관리가 용이하며, 복잡한 부가정보 없이 데이터를 저장할 수 있다.
배열의 캐시 인접성(Cache Locality)이 왜 중요할까?
- 배열은 메모리 내에 연속적으로 배치되기 때문에 하나의 원소에 접근할 때 인접한 여러 원소들이 동시에 캐시에 로드되어, 이후의 접근 시 빠른 데이터 처리가 가능해진다.
배열과 캐시 인접성의 개념
- 배열은 메모리 상에 연속된 블록에 데이터를 저장한다.
- 한 번의 메모리 접근으로 캐시 라인에 로드된 데이터를 활용해 여러 원소에 빠르게 접근할 수 있다.
- 인접한 데이터들이 캐시에 함께 로드되므로, 순차적인 데이터 접근(예: 반복문을 통한 처리)이 효율적으로 동작한다.
캐시 인접성이 중요한 이유
- 빠른 메모리 접근: 배열 원소 접근 시 인접한 원소들도 함께 로드되어, 추가 메모리 접근 없이도 빠른 데이터 처리를 할 수 있다.
- 캐시 히트율 증가: 순차적 접근은 캐시 미스 횟수를 줄여 전체 연산 시간을 단축시키며, 이는 응용 프로그램의 성능 향상에 크게 기여한다.
- 효율적인 데이터 처리: 특히 대량의 데이터를 다루는 경우, 캐시 인접성이 높은 구조인 배열은 포인터 기반의 분산형 자료구조(예: 연결 리스트)보다 훨씬 효율적이다.
실무적 예시와 고려사항
- 배열에 저장된 정수형 데이터에 대해 반복문으로 순차적으로 접근하는 경우, 첫 번째 원소 접근 시 인접한 여러 값들이 캐시에 로드되어 이후 반복문 내에서 빠른 접근이 가능하다. 이는 데이터 분석, 이미지 처리, 과학 연산 등 많은 분야에서 성능 최적화의 핵심 요소로 작용한다.
- 반면, 연결 리스트와 같이 메모리 내에 비연속적으로 분산된 자료구조는 캐시 미스가 잦아 접근 속도가 저하되므로, 데이터 구조 선택 시 캐시 인접성을 중요한 고려 요소로 삼아야 한다.
- 캐시 인접성을 최대한 활용하기 위해서는 순차적인 데이터 접근 패턴을 유지하는 것이 좋으며, 이를 위해 필요한 경우 배열 혹은 행 우선(row-major) 방식의 2D 배열과 같은 캐시 친화적 자료구조를 선택하는 것이 유리하다.
배열의 단점
- 크기 변경의 어려움: 한 번 선언된 크기를 변경하기 어렵기 때문에, 데이터 추가 시 크기 초과 문제가 발생할 수 있다.
- 삽입 및 삭제의 비효율성: 중간에 요소를 삽입하거나 삭제할 때 해당 인덱스 이후의 모든 요소 이동이 필요하여 연산 비용이 증가한다.
- 메모리 활용의 한계: 고정된 크기로 인해 할당한 메모리 공간의 일부가 사용되지 않을 경우 메모리 낭비가 발생할 수 있다.
배열의 주요 연산 및 시간 복잡도
| 연산 | 설명 | 시간 복잡도 |
|---|---|---|
| 접근 (Access) | 배열[index]를 이용한 요소 접근 | O(1) |
| 탐색 (Search) | 특정 값을 찾기 위해 전체 배열을 순회 | O(n) |
| 삽입 (Insert) | 배열 중간에 요소 삽입 (이동이 필요) | O(n) |
| 삭제 (Delete) | 특정 요소 삭제 후 이동 필요 | O(n) |
- 접근: 배열의 인덱스를 알고 있다면 즉시 접근 가능 (
O(1)) - 탐색: 배열에서 특정 값을 찾기 위해 선형 탐색이 필요 (
O(n)) - 삽입 및 삭제: 요소 이동이 필요하므로 최악의 경우 O(n) 이다.
배열과 연결 리스트 비교
| 비교 항목 | 배열 (Array) | 연결 리스트 (Linked List) |
|---|---|---|
| 메모리 할당 | 연속된 공간에 할당 | 노드별 개별 할당 |
| 접근 속도 | 빠름 (O(1)) | 느림 (O(n)) |
| 크기 조절 | 불가능 (고정 크기) | 가능 (동적 크기) |
| 삽입/삭제 | 비효율적 (O(n)) | 효율적 (O(1) ~ O(n)) |
| 메모리 사용 | 효율적 (오버헤드 없음) | 비효율적 (포인터 필요) |
- 배열은 고정된 크기로 선언되며, 크기 변경이 어렵지만 빠른 데이터 접근이 가능하다.
- 연결 리스트는 동적으로 크기 변경이 가능하지만 노드 탐색이 느리다.
배열의 종류
1차원 배열: 가장 기본적인 형태로, 한 줄로 데이터가 나열된다.
다차원 배열: 2차원, 3차원 등 여러 차원으로 구성된 배열이다. 2차원 배열은 행과 열을 가진 표 형태로 생각할 수 있다.
희소 배열(Sparse Array): 대부분의 요소가 기본값(보통 0)인 배열을 효율적으로 저장하기 위한 특수한 형태이다.
배열의 구현 방식
정적 배열: 메모리에 고정된 크기로 할당되며, 크기 변경이 불가능하다.
동적 배열: 필요에 따라 크기가 조정되는 배열이다. 많은 현대 언어들은 내부적으로 동적 배열을 구현하고 있다.
동적 배열의 확장 원리:
- 배열이 가득 차면 더 큰 크기(보통 2배)의 새 배열을 할당
- 기존 배열의 모든 요소를 새 배열로 복사
- 기존 배열 메모리 해제
- 새 배열 참조로 업데이트
언어별 배열 구현 특징
C/C++
- 정적 크기 배열과 동적 할당 배열 모두 지원
- 메모리 직접 관리 필요
- 포인터 연산을 통한 접근 가능
Java
- 배열은 객체로 취급
- 기본형, 참조형 배열 모두 지원
- ArrayList로 동적 크기 지원
Python
- 리스트(List)가 동적 배열 역할
- 다양한 타입의 요소 저장 가능
- 내장 메서드가 풍부함
JavaScript
- 배열은 객체의 특수한 형태
- 동적 크기와 다양한 타입 지원
- 희소 배열 지원
배열의 응용
- 벡터(Vector): 동적 크기를 가진 배열의 추상화된 형태로, C++의 STL vector나 Java의 ArrayList 등이 있다.
- 행렬(Matrix): 2차원 배열을 활용한 수학적 객체로, 선형대수학에서 중요하게 사용된다.
- 스택과 큐: 배열을 기반으로 구현될 수 있는 또 다른 자료구조.
대표적인 배열 알고리즘
정렬 알고리즘
배열 요소를 특정 순서로 재배열하는 알고리즘.
- 버블 정렬, 선택 정렬, 삽입 정렬: O(n²)
- 퀵 정렬, 합병 정렬: O(n log n)
검색 알고리즘
- 선형 검색: 배열의 모든 요소를 순차적으로 확인
- 이진 검색: 정렬된 배열에서 중간값 비교를 통해 검색 범위를 절반씩 줄여가는 방식
| |
실무에서의 배열 활용 팁
적절한 초기 크기 설정: 동적 배열을 사용할 때도 예상되는 데이터 크기에 맞게 초기 크기를 설정하면 불필요한 재할당을 줄일 수 있다.
슬라이싱(Slicing) 활용: 많은 언어에서 배열의 일부분을 쉽게 추출할 수 있는 슬라이싱 기능을 제공한다.
배열 복사 시 주의점: 얕은 복사(Shallow Copy)와 깊은 복사(Deep Copy)의 차이를 이해하고 적절히 활용해야 한다.