Data Lake vs. Data Warehouse vs. Data Lakehouse
1. 태그
Data-Lake, Data-Warehouse, Data-Lakehouse, Data-Architecture
2. 계층 구조 적합성 및 의견
현재 “Data Lake vs. Data Warehouse vs. Data Lakehouse” 비교 주제는 “Software Engineering > Design and Architecture > Architecture Styles and Patterns > Architecture Styles > Data-Centric Architecture” 카테고리에 적합함.
만약 추가 세분화가 필요하다면 아래 구조도 고려할 수 있음.
- Computer Science and Engineering
└─ Software Engineering
└─ Design and Architecture
└─ Data Architecture Styles
└─ [Data Lake, Data Warehouse, Data Lakehouse Architecture]
근거:
→ 세 개의 아키텍처는 데이터 중심 구조 (Data-Centric Architecture) 에서 실제로 데이터 저장·분석 관점의 대표적 스타일이므로, 데이터 아키텍처 (Data Architecture) 레벨에서 한 번 더 분류하면 관리 및 설명에 용이함.
3. 200 자 요약
데이터 레이크 (Data Lake), 데이터 웨어하우스 (Data Warehouse), 데이터 레이크하우스 (Data Lakehouse) 는 대용량 데이터 저장 및 분석을 위한 아키텍처로 각각의 구조·목적·특징이 다르다. 조직의 데이터 활용 목표에 따라 각 방식이 적합하게 적용되며, 최근에는 데이터 레이크하우스 구조가 두 개의 장점을 결합하는 형태로 주목받고 있다.
4. 개요 (250 자)
데이터 레이크 (Data Lake), 데이터 웨어하우스 (Data Warehouse), 데이터 레이크하우스 (Data Lakehouse) 는 엔터프라이즈 환경에서 대량의 데이터를 저장, 관리, 분석하는 3 대 아키텍처 스타일이다. 데이터 레이크는 비정형 데이터, 데이터 웨어하우스는 정형 데이터를 중점적으로 처리하며, 데이터 레이크하우스는 이 둘의 장점을 융합한 새로운 접근 방식이다. 각각의 구조적 차이, 기술 스택, 확장성 및 실무 적용 사례와 한계, 그리고 도전 과제들이 존재하며, 목적과 상황에 따라 선택 및 설계 방식이 달라진다.
5. 핵심 개념
1) 데이터 레이크 (Data Lake)
- 대용량 비정형/정형 데이터를 원시 형태로 저장
- 데이터 정제 (ETL, Extract, Transform, Load) 이전 단계의 원본 데이터 활용에 중점
- 확장성과 유연성 매우 높음
2) 데이터 웨어하우스 (Data Warehouse)
- 정형화된 구조 및 스키마로 데이터 저장
- 데이터 전처리 (정제, 집계) 후 로드되어 분석 성능 최적화
- BI (Business Intelligence, 비즈니스 인텔리전스) 및 보고 중심 환경에 최적화
3) 데이터 레이크하우스 (Data Lakehouse)
- 레이크와 웨어하우스의 장점 결합
- 데이터 레이크의 확장성, 다양성과 웨어하우스의 신뢰성 (일관성, 트랜잭션, 관리성) 을 동시에 제공
- 최신 분석, AI (인공지능), ML (머신러닝) 작업에 적합
실무 연관성
- 데이터 엔지니어링 파이프라인 설계, 운영, 최적화에 대한 지식 필수
- 스토리지, 컴퓨팅, 보안, 거버넌스 정책 구현
- Hadoop(하둡), Spark(스파크), Apache Hive(하이브), Snowflake(스노우플레이크), Databricks(데이터브릭스) 등 기술 선택
6. 상세 비교 및 분석
[비교 개요]
- 데이터 구조, 처리 방식, 저장 가능한 데이터의 타입, 분석 환경, 보안과 거버넌스, 성능, 확장성 등 다양한 측면에서 차이 존재
항목별 비교 (요약)
| 구분 | Data Lake (데이터 레이크) | Data Warehouse (데이터 웨어하우스) | Data Lakehouse (데이터 레이크하우스) |
|---|---|---|---|
| 저장 데이터 유형 | 비정형/정형/반정형 | 정형 데이터 | 모든 데이터 유형 |
| 저장 형식 | 원시 데이터 | 구조화 (스키마 기반) | 원시 + 구조화 데이터 |
| ETL(변환) 시점 | 적재 (Load) 후 변환 (ELT) | 적재 (Load) 전 변환 (ETL) | 모두 가능, 유연함 |
| 확장성 | 매우 높음 | 상대적으로 제한적 | 매우 높음 |
| 분석 성능 | 분석 도구 (추후 처리 필요) | BI(즉시 분석 최적화) | BI + ML + 빅데이터 지원 |
| 비용 | 상대적으로 낮음 | 상대적으로 높음 | 중간~낮음 (최적화 가능) |
| 주 사용 목적 | 대용량/다양한 데이터 저장 및 AI/ML | 일반적 분석, 리포팅, BI | 분석 + AI/ML 통합 |
| 대표 기술 | Hadoop, Amazon S3, Azure Data Lake | Teradata, Snowflake, Google BigQuery | Databricks, Delta Lake, AWS Lake Formation |
개별 비교 항목 확장 표
| 항목 | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| 데이터 적재 | 빠르게 원시 상태 | 정규화·스키마필수 | 둘 다 지원 |
| 확장성 | 무한·저가 | 용량당비싸짐 | 무한·동적 |
| 분석/AI 활용 | 별도 추가 필요 | 제한적 | 통합 지원 |
| 데이터 갱신 | 복잡/불편 | 용이 | 용이 |
| 데이터 품질 | 낮거나 불일치 가능 | 매우 높음 | 높음 |
| 거버넌스 | 복잡 | 우수 | 최신 요구 충족 |
| 데이터 탐색 | 제한적 | 효율적 | 효율적 |
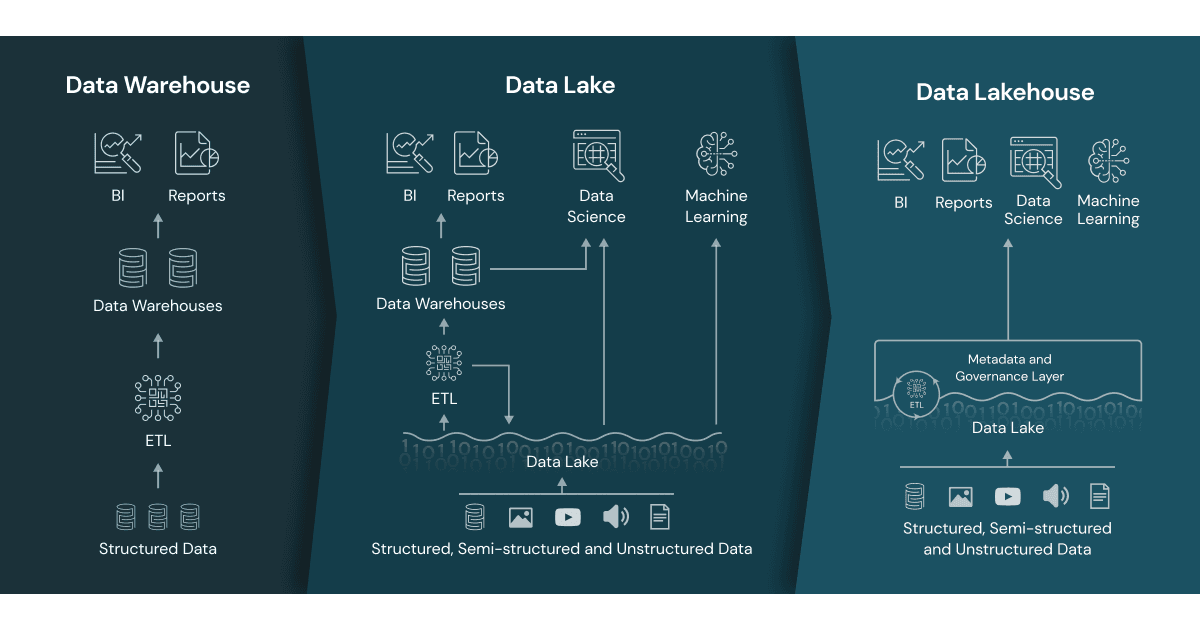
구조 및 아키텍처 (예시 다이어그램)
flowchart TD
subgraph Data Lake
A1[Raw Data] --> B1[Distributed Storage (ex: S3, HDFS)]
B1 --> C1[Data Discovery/AI Processing]
end
subgraph Data Warehouse
A2[ETL Pipeline] --> B2[RDBMS Storage (ex: Snowflake, BigQuery)]
B2 --> C2[BI Tools]
end
subgraph Data Lakehouse
A3[Raw + Structured Data] --> B3[Unified Storage]
B3 --> C3[ACID Transaction Layer]
C3 --> D3[BI/AI/ML]
end
- 설명:
- 데이터 레이크는 다양한 소스의 원시 데이터를 분산 스토리지에 적재 후, 별도 분석 과정을 거침.
- 데이터 웨어하우스는 데이터 전처리 (ETL) 후 RDBMS (관계형 데이터베이스 관리 시스템, Relational Database Management System) 기반으로 저장·분석.
- 데이터 레이크하우스는 단일 스토리지에 여러 데이터 유형을 저장, 트랜잭션·거버넌스 계층과 분석 엔진을 통합.
구성 요소 (필수/선택 구분 포함)
| 아키텍처 유형 | 필수 구성 요소 | 선택적 구성 요소 |
|---|---|---|
| 데이터 레이크 | 오브젝트 스토리지, 메타데이터 카탈로그, 데이터 적재 파이프라인 | 데이터 스트림, 데이터 거버넌스, 데이터 인덱스 |
| 데이터 웨어하우스 | ETL 도구, RDBMS, BI 도구, 데이터 모델 | 데이터 마트, 자동화 확장, 캐싱 계층 |
| 데이터 레이크하우스 | 통합 스토리지, ACID 트랜잭션 계층, 쿼리 엔진, 메타데이터/거버넌스 | ETL/ELT 도구, ML 프레임워크, 실시간 처리 |
구현 기법 및 방법
데이터 레이크
- 오브젝트 스토리지 (Amazon S3, Azure Data Lake, HDFS 등) 활용해 대량/비정형 데이터 저장
- 메타스토어 (Hive 메타스토어 등) 로 데이터 탐색성 부여
- 데이터 적재 파이프라인 (ETL/ELT 도구)
- 예시: Apache Spark(아파치 스파크) 로 S3 에 데이터 적재, Glue 로 메타데이터 관리
데이터 웨어하우스
- ETL 로 데이터 정제, RDBMS 기반 스키마 데이터 저장
- BI(비즈니스 인텔리전스, Business Intelligence) 도구와 즉시 연동
- 예시: Snowflake(스노우플레이크), Google BigQuery(구글 빅쿼리) 등
데이터 레이크하우스
- Lake + Warehouse 통합 스토리지, 트랜잭션 레이어 (Delta Lake, Apache Hudi 등)
- ACID 지원, 메타데이터 관리, 데이터 버저닝
- Spark SQL, Databricks 등으로 최신 분석 및 ML 워크로드 지원
- 예시: Databricks Lakehouse, Delta Lake 기반 시스템
실무에서 효과적으로 적용하기 위한 고려사항 및 권장사항
| 구분 | 고려사항/주의점 | 권장사항 |
|---|---|---|
| Data Lake | 데이터 품질 관리, 메타데이터 표준화 | 데이터 거버넌스 및 메타카탈로그 강화 |
| Data Warehouse | ETL 프로세스 자동화, 스키마 관리 | 데이터 모델 표준화 및 변경관리 프로세스 도입 |
| Data Lakehouse | 데이터 일관성/무결성, 애플리케이션 호환성 | 트랜잭션 계층 (Bronze/Silver/Gold Layer) 적용 |
최적화하기 위한 고려사항 및 권장사항
| 구분 | 최적화 사항 | 권장사항 |
|---|---|---|
| Data Lake | 파티셔닝, 파일 포맷 최적화 (Parquet 등) | 쿼리 효율·비용 계산 최적화 |
| Data Warehouse | 인덱싱, 고도화된 쿼리 최적화 | 사용량 기반 확장 (오토스케일링 등) |
| Data Lakehouse | 캐싱 및 레이아웃 최적화, 증분 처리 | 다양한 워크로드별 구분 저장지 사용 |
강점과 약점 (장단점)
| 구분 | 강점 | 약점/단점 |
|---|---|---|
| Data Lake | 확장성, 비용 효율, 다양성 | 데이터 품질 및 관리 이슈, 일관성 약함 |
| Data Warehouse | 일관성, 성능, BI 최적화 | 비용, 비정형 데이터 유연성 낮음 |
| Data Lakehouse | 확장성 + 일관성, 유연성, 통합성 | 구현 난이도, 최신 기술 의존성 |
장점
| 구분 | 항목 | 설명 |
|---|---|---|
| Data Lake | 비용 효율 | 저가 오브젝트 스토리지와 확장 가능 구조로 비용 압축 가능 |
| 다양성 | 비정형·정형 데이터를 모두 저장 가능 | |
| Data Warehouse | 신뢰성 | 스키마와 전처리 기반으로 데이터 일관성/품질 높음 |
| 최적화 | 쿼리 성능, BI 분석에 최적화 | |
| Data Lakehouse | 통합성 | AI/ML, BI, 실시간 분석까지 하나로 지원 |
| 효율성 | 트랜잭션, 거버넌스 계층으로 데이터 품질 보장 |
단점과 문제점 및 해결책
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| Data Lake | 데이터 스파게티화 | 관리·품질 미흡으로 데이터가 뒤섞임 | 메타데이터/거버넌스 강화, 표준화 |
| 보안 이슈 | 액세스 관리 미흡 | IAM(계정 및 접근 제어, Identity and Access Management) 적용 | |
| Data Warehouse | 확장성 한계 | 대용량/새로운 데이터 유형 추가 비용/제한 | 클라우드 기반 도입, 탄력적 확장 도구 활용 |
| Data Lakehouse | 구현 복잡성 | 아키텍처 복잡, 호환성 이슈 | 통합 플랫폼 (Delta Lake 등) 채택 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| Data Lake | 데이터 품질 미흡 | 스키마 없는 데이터 적재 | 신뢰도 저하 | 데이터 프로파일링 | 표준화 정책, 메타데이터 수집 | 정기 데이터 검증, 거버넌스 강화 |
| Data Warehouse | 확장성 제한 | 고정 스키마, 물리적 확장 한계 | 비용 증가/서비스 지연 | 쿼리 성능 모니터링 | 클라우드 기반, 자동 확장 | 클라우드 마이그레이션 |
| Data Lakehouse | 통합 호환성 문제 | 다중 프레임워크 연동 | 운영·기술 복잡성 | 통합 테스트 | 통합 표준 도입, 문서화 | 플랫폼 통합, 커스텀 커넥터 개발 |
실무 사용 예시 (요약 표)
| 구분 | 사용 서비스 예 | 주요 활용 목적 | 기대 효과 |
|---|---|---|---|
| Data Lake | AWS S3+Glue | AI 학습 데이터 저장 및 분산처리 | 비용 절감, 대용량 데이터 활용 |
| Data Warehouse | Snowflake | 회계/의사결정 지원용 BI 리포트 | 빠른 분석, 신뢰성 |
| Data Lakehouse | Databricks | ML/BI/실시간 분석 통합 | 통합 분석, 워크로드 연결 |
활용 사례
시나리오:
금융사에서 고객 거래 로그·콜센터 녹취 등 비정형 + 정형 데이터 통합 분석 기반의 이상 거래 탐지 시스템 구축
시스템 구성:
- 원본 데이터: 콜센터 음성, 거래 로그, 채팅 기록, 모바일 앱 로그 등
- 저장: 데이터 레이크하우스 (AWS S3 + Delta Lake)
- 처리: Databricks 기반 실시간 처리, Spark ML
- 활용: 위험 스코어링 및 실시간 모니터링
시스템 구성 다이어그램:
flowchart TD
R1[Raw Data (Voice, Logs, Chat)] --> S1[S3 Bucket]
S1 --> D1[Delta Lake]
D1 --> T1[Databricks Runtime]
T1 --> M1[Spark ML (AI/ML Process)]
M1 --> R2[Anomaly Detection]
R2 --> V1[Portal 및 Dashboard]
Workflow:
- 원시 데이터가 S3 버킷에 저장됨
- Delta Lake 레이어에서 트랜잭션/메타데이터 관리
- Databricks Runtime 에서 대규모 분석 및 AI/ML 처리
- 실시간 이상 거래 탐지 및 대시보드 반영
역할:
- S3: 데이터 저장
- Delta Lake: 트랜잭션 및 품질 관리
- Databricks/Spark: 분석 파이프라인 실행
- Portal: 결과 시각화
유무에 따른 차이점:
- 기존 Data Lake 만 사용시 데이터 품질 및 일관성 확보 어려움, Data Lakehouse 도입 후 데이터 정합성·속도 개선
구현 예시 (Python with Delta Lake 주석 포함)
| |
도전 과제
1. 실무 환경 도전 과제 및 해법
- 데이터 품질 관리:
- 원인: 다양한 소스, 비정형 데이터 증가
- 영향: 분석 신뢰성 저하
- 대응: 데이터 거버넌스, 메타데이터 강화, 데이터 검증 자동화
- 확장성과 비용 효율화:
- 원인: 지속적 데이터 증가
- 영향: 예산 초과, 성능 저하
- 대응: 오토스케일링, 데이터 파티셔닝, 스토리지 최적화
- 실시간·AI/ML 대응력:
- 원인: 타임 투 인사이트 (Time to Insight) 단축 요구
- 영향: 리스크 미탐지, 의사결정 지연
- 대응: 스트림 처리, Lakehouse 기반 실시간 레이어 구축
- 플랫폼 호환성 및 데이터 통합:
- 원인: 이기종 데이터 소스/분석 툴 혼재
- 영향: 데이터 사일로, 관리 복잡성
- 대응: 표준화된 API, 통합 데이터 카탈로그 활용
11. 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 구조적 융합 | Lakehouse | Lake+Warehouse 장점 동시 실현 |
| 데이터 거버넌스 | 관리 | 메타데이터/품질 관리 필수 |
| 트랜잭션/무결성 | Delta | ACID 지원 필수로 현실화 |
| 실시간 분석 | 워크플로우 | ML/BI/실시간 모두 결합 |
12. 반드시 학습해야 할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 아키텍처 설계 | 구조 | Lake, Warehouse, Lakehouse | 각각의 구조 및 장단점 학습 |
| 데이터 엔지니어링 | 파이프라인 | ETL/ELT | 데이터 흐름, 변환 방법, 도구 사용법 |
| 빅데이터 분석 | 도구 | Spark, Hive | 대규모 분산 분석 툴 학습 |
| 거버넌스 및 보안 | 정책 | IAM, 메타데이터 | 데이터 접근 통제 및 데이터 품질 관리 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 데이터 아키텍처 | 데이터 레이크 (Data Lake) | 원시/비정형/정형 데이터 대용량 저장소 |
| 데이터 아키텍처 | 데이터 웨어하우스 (Data Warehouse) | 정형 데이터 분석용 통합 데이터 저장소 |
| 데이터 아키텍처 | 데이터 레이크하우스 (Data Lakehouse) | 레이크 + 웨어하우스 장점 결합 차세대 데이터 구조 |
| 데이터 엔지니어링 | ETL (Extract Transform Load) | 데이터 추출, 변환, 적재 순의 처리 방식 |
| 데이터 엔지니어링 | ELT (Extract Load Transform) | 데이터 추출 후 적재, 그다음 변환 처리 방식 |
| 거버넌스/품질 | 메타데이터 (Metadata) | 데이터 정보에 대한 정보 |
| 거버넌스/보안 | IAM (Identity and Access Management) | 계정·접근 제어체계 |
| 빅데이터 | 오브젝트 스토리지 (Object Storage) | 프레임워크·클라우드 기반 파일 저장 서비스 |
| 분석 | BI (Business Intelligence) | 비즈니스 데이터 분석·리포팅 방법론/도구 |
| 분석 | ML (Machine Learning) | 기계 학습, AI 의 한 분야 |
| 트랜잭션 | ACID | 원자성, 일관성, 고립성, 지속성 데이터 원칙 |
참고 및 출처
- What is a Data Lakehouse? (Databricks 공식 설명)
- AWS Data Lakes and Analytics 설명
- Snowflake vs Lakehouse vs Data Lake 차이
- Data Lakes, Warehouses, and Lakehouses 설명 (Microsoft)
- Data Lakehouse Architecture (Google Cloud)
- Delta Lake 소개
추가 심화 비교 및 심층 분석
13. 심층 실무 최적화 전략 및 워크플로우
데이터 레이크 (Data Lake)
- 워크플로우 최적화: 데이터 적재 자동화 (ELT) 와 주기적인 데이터 프로파일링을 통해 데이터 혼잡 방지
- 구성 예시:
- 비정형 로그 데이터가 Amazon S3(오브젝트 스토리지) 로 직접 유입
- Glue Crawler(메타데이터 관리) 가 자동으로 데이터 카탈로그 갱신
- 보안·권한 관리는 IAM(Identity and Access Management) 과 S3 버킷 정책 병행
- 실제 권장 패턴: 스키마 온 리드 (schema on read, 읽을 때 스키마 적용) 방식과, 점진적 데이터 거버넌스 정책을 결합해 데이터 정합성 유지
데이터 웨어하우스 (Data Warehouse)
- 워크플로우 최적화: ETL 단계에서 변환 규칙 정교화, 데이터 마트 (Data Mart) 로 주제별 빠른 액세스 가능하도록 설계
- 구성 예시:
- OLTP(Online Transaction Processing) 데이터가 ETL 처리 후 Snowflake 또는 Google BigQuery(관계형 데이터 웨어하우스) 로 적재
- 쿼리 최적화 및 인덱싱, 권한 분리 기반 감사 (audit) 체계 구축
- 실제 권장 패턴: ETL 파이프라인의 자동화 및 오케스트레이션 도구 사용 (Airflow 등) 으로 복잡도·오류 최소화
데이터 레이크하우스 (Data Lakehouse)
- 워크플로우 최적화: Delta Lake, Apache Hudi(ACID 지원 트랜잭션 계층) 기반의 실시간 스트리밍과 배치 워크로드 병행
- 구성 예시:
- 다양한 소스 데이터가 S3, HDFS 로 직행한 뒤, Delta Lake/Apache Hudi 로 트랜잭션 및 증분 변경 이력 관리
- Databricks 또는 Apache Spark 환경에서 BI, AI/ML 분석이 통합 처리됨
- 실제 권장 패턴: 레이크와 웨어하우스 구조의 ’ 계층적 저장 (Bronze-Silver-Gold Layering)’ 적용—초기 원시 데이터→정제 데이터→비즈니스 목적별 집계 데이터 분리로 품질, 일관성, 성능 동시 보장
실무 적용 예시 (Workflow, 구성, 워크플로우)
| 주요 흐름 | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| 데이터 유입 | 원시데이터 대용량·다양성 즉시 적재 | ETL 변환, 정제된 데이터 적재 | 원시 + 변환 데이터 계층 구조 적재·관리 |
| 데이터 사용 | ML/R&D/탐색형 분석 | BI/리포트/표준 분석 | 분석 +AI/ML+ 리얼타임 통합지원 |
| 데이터 보안 | 버킷별 정책, IAM, 암호화 등 | RDBMS 권한체계, 감사로그 | 트랜잭션 계층 + 정제 + 동적 정책 (KMS 등) 적용 |
| 최적화 포인트 | 파티션·포맷, 메타데이터 카탈로그 | 쿼리/스토리지/인덱싱 최적화 | ACID, 증분처리, 계층 분리, 분산캐시 |
구조 다이어그램 (종합)
flowchart TB
subgraph Source
S1[IoT/Log/DB/파일/외부API 데이터]
end
subgraph Ingest
S2[ETL/ELT/스트리밍]
end
subgraph Storage
L1[Data Lake (S3/HDFS)]
W1[Data Warehouse (RDBMS)]
LH1[Data Lakehouse (Delta Lake 등)]
end
subgraph Process
P1[정형·비정형 분석]
P2[BI 분석]
P3[AI/ML/실시간]
end
S1 --> S2
S2 --> L1
S2 --> W1
S2 --> LH1
L1 --> P1
W1 --> P2
LH1 --> P2
LH1 --> P3
P1 -.실험/탐색.-> P3
- 설명: 현실 업무에서는 Ingest 계층에서 각 시스템별로 데이터가 분기 또는 연동되며 Lakehouse 구조의 경우 분석·AI 실시간 처리를 모두 담아내고, 데이터 품질·거버넌스 구성을 계층화하여 관리한다.
14. 최신 트렌드 및 기술 확장
- 데이터 메쉬 (Data Mesh): 조직 전체에 데이터 소유권을 분산, 각 도메인 팀이 자체적으로 데이터 레이크/레이크하우스를 관리
- 오픈테이블 포맷: Delta Lake, Apache Iceberg, Apache Hudi 와 같이 트랜잭션·버저닝·증분 처리를 오픈소스로 구현
- 클라우드 네이티브: AWS Lake Formation, Google BigLake, Azure Synapse 등 클라우드전용 최적화 플랫폼 확장 중
15. 실무 적용시 체크리스트 및 권장 체크포인트
| 단계 | 체크리스트 항목 | 권장·최적화 포인트 |
|---|---|---|
| 설계단계 | 데이터 유형/용도 식별 | 비정형/정형 비율, 용도 중심구조 선정 |
| 적재단계 | 메타데이터 자동화 | 메타데이터/카탈로그 자동화툴 적용 |
| 운영단계 | 품질·정합성 진단 도구 | 데이터 품질관리/정합성 검증 자동화 적용 |
| 확장단계 | 오토스케일/비용분석 | 스토리지/쿼리 사용량 모니터링 + 자동최적화 적용 |
| 분석·활용단계 | BI/AI/ML 분리·통합 플로우 | 계층적 저장, 최신 프레임워크/오픈소스 적용 |
16. 실전 적용에 앞서 반드시 정리해야 할 노하우
- 모범 사례: 데이터 처리·분석 목적별로 구조 차별화, 거버넌스 우선 → 뒤늦은 거버넌스는 나중에 치명적 부담
- 오픈소스와 클라우드 역량: 오픈 테이블 포맷 (Delta, Iceberg 등), 클라우드 관리형 서비스의 트렌드에 맞춰 기술 스택 선정
- 자동화 및 지속적 개선: ETL/ELT·파이프라인, 모니터링, 최적화 작업의 자동화 및 코드화
용어 정리 (추가)
| 카테고리 | 용어 (한글/영문) | 설명 |
|---|---|---|
| 데이터 거버넌스/품질 | 데이터 메쉬 (Data Mesh) | 조직 전체에 데이터 소유권 및 관리 분산, 도메인 중심 거버넌스 방식 |
| 트랜잭션/저장 포맷 | 오픈 테이블 포맷 (Open Table Format) | 오픈소스 트랜잭션, 버저닝 지원 테이블 포맷 (Delta, Iceberg 등) |
| 클라우드 아키텍처 | 오토스케일링 (Auto Scaling) | 데이터/분석량 급증 시 자동으로 자원 증감하는 기능 |
| 데이터 계층화 | 브론즈/실버/골드 레이어 (Bronze/Silver/Gold Layer) | 계층적 데이터 정제·저장 구조 |
참고 및 출처 (계속)
- Data Lakehouse 트렌드 및 Iceberg/Hudi/Delta 비교
- Modern Data Architecture 흐름 (Google Cloud)
- 데이터 메쉬 개념과 실제
- AWS Data Lake Formation 공식 문서
17. 도입 전략 및 실무 환경 적용 프레임워크
도입 시 고려해야 할 주요 전략
- 목표 명확화
데이터가 실시간 분석, 대규모 저장, AI 및 비즈니스 인텔리전스 (BI, Business Intelligence) 중 어디에 중점을 두는지 우선순위 선정이 필수다.- 분석 중심: 데이터 웨어하우스 (정형 + 쿼리 최적화)
- AI/ML + 대규모 원본 데이터: 데이터 레이크
- 통합·혼합 분석 및 확장성: 데이터 레이크하우스
- 파일 포맷 및 저장계층 선정
- Parquet, ORC, Avro 등 컬럼 지향 저장 포맷은 쿼리 효율과 압축률 모두를 높인다.
- 트랜잭션 레이어 (Delta Lake, Apache Hudi) 는 데이터 품질과 실시간 분석을 보장한다.
- 데이터 거버넌스 실행
- 메타데이터 관리 및 데이터 카탈로그는 데이터 검색성, 거버넌스 및 보안 준수에 반드시 필요하다.
- 데이터 딕셔너리 (데이터 사전) 와 정책 문서화는 실무 운영 혼란을 예방한다.
- 프로그래머블 데이터 파이프라인
- Airflow, Dagster, Prefect 등 워크플로우 오케스트레이션 도구 선정
- 파이프라인 자동화 및 코드 기반 관리로 배포, 변경, 유지보수 효율성 확보
실무 환경 적용 프레임워크 예시
- 데이터 소스 분석 및 분류
- 정형/비정형 여부, 데이터 크기와 흐름 빈도 파악
- 아키텍처 레이아웃 설계
- 데이터 유입 → 저장 → 처리 및 분석 → 활용의 전체 경로를 도식화
- 도구 선정
- 스토리지: Amazon S3, Google Cloud Storage, Azure Data Lake
- 처리: Databricks, Spark, Snowflake, BigQuery, Delta Lake, Hudi
- 거버넌스: Glue Catalog, Data Catalog, DataHub
- 운영 자동화
- 프로그래밍 기반의 데이터 검증, 품질 점검 (alert·모니터링), 자원 활용도 오토스케일
- 최종 목적지 (분석·AI·BI) 에 최적화
- BI 툴: Tableau, Power BI
- AI/ML: Databricks, SageMaker, Vertex AI
18. 실패 및 리스크 관리 방안
- 사일로화와 혼돈 방지
- 소스별 독립 처리로 인한 데이터 사일로 (Data Silo) 및 품질 변동 리스크 관찰
- 데이터 레이크는 반드시 거버넌스 강화, 품질 모니터링 시스템 구축 병행
- 확장성 폭주로 인한 비용 과다 방지
- 파일 수, 데이터 보존 기간 등 스토리지 관리 기준을 설정
- 사용량 기반 오토스케일 및 클라우드 비용 경계 기능 적극 도입
- 실시간 및 AI/ML 결함 대응
- 배치·실시간 혼합 처리가 필요한 경우, 워크플로우 단계별로 장애 포인트 분리
- 트랜잭션 오류, 데이터 충돌, 가용성 저하 시 롤백 및 재처리 로직 설계
19. 현업 활용 팁
- Pipeline 코드형 관리
모든 워크플로우 (ETL/ELT, 품질관리, 스케줄링) 는 코드로 관리 (파이썬 등) 해 Git 등 버전 단위로 이력 관리 - 분석·ML 데이터 계층 분리
브론즈 (원본), 실버 (정제), 골드 (의사결정/AI 최적화) 레이어 분리로 업무·분석 목적 충돌 최소화 - 철저한 모니터링
작업 실패, 품질 저하, 권한 이슈 등은 중앙 집중 모니터링 (CloudWatch, Stackdriver, Datadog 등) 구축으로 빠르게 감지
주목할 최신 용어 및 기술 (보충)
| 카테고리 | 용어 (한글/영문) | 설명 |
|---|---|---|
| 최적화 | 파티셔닝 (Partitioning) | 대량 데이터 대상 빠른 쿼리·분산 처리 위한 논리 분할 구조 |
| 분석 자동화 | 오케스트레이션 (Orchestration) | 분석·ETL/ELT 워크플로의 자동화 및 흐름 제어 |
| 데이터 거버넌스 | 데이터 카탈로그 (Data Catalog) | 전체 데이터셋의 메타데이터 중앙 관리 체계 |
| 최신 기술 트렌드 | 리얼타임 데이터 (Real-time Data) | 실시간 데이터 처리 및 대응 기술 |
| 분석 인터페이스 | 메타스토어 (Metastore) | 데이터셋의 메타정보 (스키마, 위치 등) 중앙 관리 시스템 |
참고 및 출처 (최신 보충)
- Apache Hudi, Iceberg, Delta Lake 비교
- 현대 데이터 아키텍처 설계 흐름 (Google Cloud)
- 모던 데이터 거버넌스와 Data Catalog
- 워크플로우 자동화 예제 (Airflow 공식)
- AWS S3 Storage Classes와 비용
위 내용을 기반으로, 다양한 환경에서 데이터 레이크, 데이터 웨어하우스, 데이터 레이크하우스 아키텍처를 최적으로 설계·구현하고, 최신 도구 및 전략을 결합해 진화하는 데이터 활용 패러다임을 선도할 수 있다
한국어로 상세한 조사 분석을 수행하겠습니다. 먼저 주제에 대한 최신 정보를 조사하겠습니다.
Data Lake vs. Data Warehouse vs. Data Lakehouse 종합 분석
1. 태그
Data-Lake, Data-Warehouse, Data-Lakehouse, Cloud-Analytics
2. 분류 구조 검토
“## 4. 주제의 분류 " 에 작성된 **“Computer Science and Engineering > Software Engineering > Design and Architecture > Architecture Styles and Patterns > Architecture Styles > Data-Centric Architecture”**는 적절한 분류입니다.
더 적절한 분류 제안:
| |
근거:
- 이 주제들은 시스템 설계의 핵심 구성 요소로서 데이터베이스 시스템의 하위 범주에 더 적합함
- 소프트웨어 엔지니어링보다는 시스템 설계 관점에서 접근하는 것이 실무적으로 더 유용함
- 데이터 아키텍처 패턴은 현대 클라우드 환경에서 매우 중요한 분야로 독립적인 카테고리가 필요함
3. 주제 요약
데이터 레이크 (Data Lake), 데이터 웨어하우스 (Data Warehouse), 데이터 레이크하우스 (Data Lakehouse) 는 대용량 데이터 저장 및 분석을 위한 세 가지 주요 아키텍처입니다. 데이터 웨어하우스는 구조화된 데이터의 고성능 분석에 특화되어 있고, 데이터 레이크는 다양한 형태의 원시 데이터를 저장하며, 데이터 레이크하우스는 두 접근법의 장점을 결합한 하이브리드 솔루션입니다.
4. 개요
현대 조직들이 폭발적으로 증가하는 데이터를 효과적으로 관리하고 활용하기 위해 발전시킨 세 가지 핵심 데이터 저장 아키텍처입니다. 각각은 고유한 특성과 사용 사례를 가지며, 조직의 데이터 전략과 요구사항에 따라 선택됩니다. 특히 클라우드 네이티브 환경에서 Apache Iceberg, Delta Lake 등의 오픈 테이블 포맷을 통해 데이터 레이크하우스가 차세대 솔루션으로 주목받고 있습니다.
5. 핵심 개념
5.1 핵심 개념 정리
데이터 웨어하우스 (Data Warehouse)
- 스키마 온 라이트 (Schema-on-Write): 데이터 저장 시점에 스키마를 적용하여 구조화
- OLAP (Online Analytical Processing): 복잡한 분석 쿼리에 최적화된 처리 방식
- ETL (Extract, Transform, Load): 데이터 추출, 변환, 적재 과정
- 차원 모델링 (Dimensional Modeling): 팩트 테이블과 차원 테이블로 구성된 데이터 모델
데이터 레이크 (Data Lake)
- 스키마 온 리드 (Schema-on-Read): 데이터 읽기 시점에 스키마를 적용
- ELT (Extract, Load, Transform): 원시 데이터를 먼저 로드하고 필요시 변환
- 오브젝트 스토리지 (Object Storage): S3, HDFS 등을 활용한 확장 가능한 저장소
- 데이터 스웜프 (Data Swamp): 거버넌스 부족으로 인한 데이터 품질 저하 문제
데이터 레이크하우스 (Data Lakehouse)
- 오픈 테이블 포맷 (Open Table Format): Apache Iceberg, Delta Lake, Apache Hudi
- ACID 트랜잭션 (ACID Transactions): 원자성, 일관성, 격리성, 지속성 보장
- 타임 트래블 (Time Travel): 데이터의 과거 상태 조회 기능
- 스키마 진화 (Schema Evolution): 스키마 변경에 대한 유연한 대응
5.2 실무 구현 연관성
인프라스트럭처 관점
- 클라우드 플랫폼: AWS, Azure, GCP 의 관리형 서비스 활용
- 컴퓨트와 스토리지 분리: 독립적인 확장성과 비용 최적화
- 멀티 클러스터 아키텍처: 동시성과 격리를 위한 워크로드 분산
데이터 엔지니어링 관점
- 데이터 파이프라인 설계: 실시간/배치 처리 요구사항 분석
- 데이터 거버넌스: 메타데이터 관리, 접근 제어, 데이터 계보 추적
- 성능 최적화: 파티셔닝, 인덱싱, 쿼리 최적화 전략
6. 주제별 상세 조사 및 비교 분석
6.1 등장 및 발전 배경
데이터 웨어하우스
- 1980 년대 후반: Bill Inmon 이 데이터 웨어하우스 개념 정립
- 1990 년대: 비즈니스 인텔리전스 (BI) 도구와 함께 발전
- 2000 년대: MPP (Massively Parallel Processing) 아키텍처 도입
- 2010 년대: 클라우드 기반 솔루션 (Snowflake, BigQuery) 등장
데이터 레이크
- 2010 년: James Dixon (Pentaho CTO) 이 데이터 레이크 용어 도입
- 2010 년대 초: Hadoop 생태계와 함께 급성장
- 2015 년: AWS S3 를 중심으로 한 클라우드 데이터 레이크 확산
- 2020 년: 관리형 데이터 레이크 서비스 (AWS Lake Formation) 등장
데이터 레이크하우스
- 2017 년: Netflix 가 Apache Iceberg 개발, Databricks 가 Delta Lake 발표
- 2020 년: Databricks 가 “Data Lakehouse” 용어 대중화
- 2021 년: Apache Hudi 프로젝트 성숙화
- 2024 년: 주요 클라우드 업체들의 레이크하우스 솔루션 통합
6.2 목적 및 필요성
| 구분 | 데이터 웨어하우스 | 데이터 레이크 | 데이터 레이크하우스 |
|---|---|---|---|
| 주요 목적 | 구조화된 데이터의 고성능 분석 및 리포팅 | 다양한 형태의 원시 데이터 저장 및 탐색적 분석 | 통합된 데이터 플랫폼을 통한 다양한 워크로드 지원 |
| 해결하고자 하는 문제 | 분산된 데이터 소스 통합, 일관된 분석 환경 제공 | 대용량 비정형 데이터 저장 비용 절감, 확장성 확보 | 데이터 사일로 제거, 중복 인프라 비용 절감 |
| 달성 목표 | 신뢰할 수 있는 단일 진실 공급원 (SSOT) 구축 | 유연한 데이터 저장소를 통한 혁신 가속화 | 웨어하우스와 레이크의 장점을 결합한 최적화된 솔루션 |
6.3 주요 기능 및 역할
데이터 웨어하우스의 기능과 역할
- 기능: OLAP 쿼리 처리, 집계 연산 최적화, 메타데이터 관리
- 역할: 비즈니스 인텔리전스의 기반, 정기 보고서 생성, 의사결정 지원
- 관계: BI 도구 → 데이터 웨어하우스 → ETL → 운영 시스템
데이터 레이크의 기능과 역할
- 기능: 원시 데이터 저장, 스키마 유연성, 대용량 처리
- 역할: 데이터 사이언스 실험 환경, 머신러닝 모델 훈련, 탐색적 분석
- 관계: ML/AI 도구 → 데이터 레이크 → ELT → 다양한 데이터 소스
데이터 레이크하우스의 기능과 역할
- 기능: ACID 트랜잭션, 스키마 진화, 타임 트래블, 통합 메타데이터
- 역할: 통합 분석 플랫폼, 실시간/배치 처리 통합, 데이터 거버넌스 중심
- 관계: 다양한 분석 도구 → 레이크하우스 → 통합 데이터 계층 → 모든 데이터 소스
6.4 특징 비교
| 특징 | 데이터 웨어하우스 | 데이터 레이크 | 데이터 레이크하우스 |
|---|---|---|---|
| 데이터 형태 | 구조화된 데이터 | 모든 형태 (구조화/반구조화/비구조화) | 모든 형태 + 구조화된 접근 |
| 스키마 적용 | Schema-on-Write | Schema-on-Read | 두 방식 모두 지원 |
| 성능 | 높음 (특정 워크로드) | 중간 (유연성 위주) | 높음 (다양한 워크로드) |
| 비용 | 높음 | 낮음 | 중간 |
| 확장성 | 제한적 | 매우 높음 | 매우 높음 |
| 데이터 품질 | 높음 | 가변적 | 높음 (ACID 지원) |
6.5 핵심 원칙
데이터 웨어하우스 핵심 원칙
- 주제 지향성 (Subject-Oriented): 비즈니스 주제별 데이터 구성
- 통합성 (Integrated): 일관된 형식의 데이터 통합
- 시간 변동성 (Time-Variant): 시간에 따른 데이터 변화 추적
- 비휘발성 (Non-Volatile): 데이터의 안정적 보존
데이터 레이크 핵심 원칙
- 스키마 유연성: 데이터 구조의 사전 정의 불필요
- 저장 우선: 활용 방법을 나중에 결정
- 원시 데이터 보존: 원본 형태 유지
- 확장성 우선: 수평적 확장 가능한 아키텍처
데이터 레이크하우스 핵심 원칙
- 오픈 포맷: 벤더 종속성 회피
- ACID 준수: 데이터 일관성 보장
- 통합 메타데이터: 단일 메타데이터 계층
- 컴퓨트 - 스토리지 분리: 독립적 확장성
6.6 주요 원리 및 작동 원리
graph TD
A[Data Sources] --> B[Data Warehouse ETL]
A --> C[Data Lake ELT]
A --> D[Data Lakehouse Ingestion]
B --> E[Structured Storage]
C --> F[Raw Data Storage]
D --> G[Open Table Format]
E --> H[BI Tools]
F --> I[ML/Analytics Tools]
G --> J[Unified Analytics Platform]
subgraph "Data Warehouse Flow"
B --> K[Transform] --> L[Load] --> E
end
subgraph "Data Lake Flow"
C --> M[Load] --> N[Transform on Query] --> F
end
subgraph "Data Lakehouse Flow"
D --> O[Metadata Layer] --> P[ACID Transactions] --> G
end
데이터 웨어하우스 작동 원리
- 데이터 추출: 운영 시스템에서 데이터 추출
- 데이터 변환: 비즈니스 규칙에 따른 정제 및 변환
- 데이터 적재: 차원 모델에 따른 구조화된 저장
- 쿼리 처리: 최적화된 SQL 엔진을 통한 고속 처리
데이터 레이크 작동 원리
- 원시 데이터 적재: 변환 없이 원본 형태로 저장
- 메타데이터 등록: 데이터 카탈로그에 위치 및 형식 정보 등록
- 스키마 추론: 읽기 시점에 스키마 해석
- 분산 처리: Spark, Hadoop 등을 활용한 대용량 처리
데이터 레이크하우스 작동 원리
- 통합 적재: 다양한 형태의 데이터를 오픈 포맷으로 저장
- 메타데이터 관리: 통합된 메타데이터 계층에서 스키마 및 버전 관리
- ACID 트랜잭션: Delta Lake, Iceberg 등을 통한 트랜잭션 보장
- 다중 엔진 지원: Spark, Trino, Presto 등 다양한 컴퓨트 엔진 지원
6.7 구조 및 아키텍처
graph TB
subgraph "데이터 웨어하우스 아키텍처"
A1[Data Sources] --> A2[ETL Layer]
A2 --> A3[Staging Area]
A3 --> A4[Data Warehouse]
A4 --> A5[Data Marts]
A5 --> A6[BI Tools]
end
subgraph "데이터 레이크 아키텍처"
B1[Data Sources] --> B2[Ingestion Layer]
B2 --> B3[Raw Data Zone]
B3 --> B4[Processed Data Zone]
B4 --> B5[Analytics Tools]
B6[Data Catalog] -.-> B3
B6 -.-> B4
end
subgraph "데이터 레이크하우스 아키텍처"
C1[Data Sources] --> C2[Ingestion Layer]
C2 --> C3[Storage Layer with Open Table Format]
C3 --> C4[Metadata Layer]
C4 --> C5[Compute Engines]
C5 --> C6[Analytics Applications]
end
6.8 구성 요소
필수 구성요소 vs 선택 구성요소
| 구분 | 필수 구성요소 | 선택 구성요소 |
|---|---|---|
| 데이터 웨어하우스 | 관계형 데이터베이스, ETL 도구, 메타데이터 관리 | 데이터 마트, OLAP 큐브, 데이터 버추얼라이제이션 |
| 데이터 레이크 | 오브젝트 스토리지, 데이터 카탈로그, 처리 엔진 | 데이터 거버넌스 도구, 스트리밍 플랫폼, ML 플랫폼 |
| 데이터 레이크하우스 | 오픈 테이블 포맷, 메타데이터 계층, 컴퓨트 엔진 | 데이터 버전 관리, 실시간 스트리밍, AI/ML 통합 도구 |
6.9 구현 기법 및 방법
클라우드 네이티브 구현
- 정의: 클라우드 서비스를 활용한 관리형 솔루션
- 구성: Snowflake, BigQuery, Databricks 등
- 목적: 운영 복잡성 감소 및 확장성 확보
- 실제 예시:
- 시스템 구성: AWS S3 + Snowflake + dbt + Looker
- 시나리오: 전자상거래 회사의 통합 분석 플랫폼 구축
하이브리드 멀티클라우드 구현
- 정의: 여러 클라우드 제공업체의 서비스를 조합
- 구성: 데이터 저장은 한 클라우드, 컴퓨트는 다른 클라우드
- 목적: 벤더 종속성 회피 및 최적 비용 구현
- 실제 예시:
- 시스템 구성: AWS S3 + Google BigQuery + Azure ML
- 시나리오: 글로벌 제조업체의 지역별 데이터 분산 처리
오픈소스 기반 구현
- 정의: Apache 생태계를 활용한 자체 구축
- 구성: Apache Spark + Apache Iceberg + Apache Airflow
- 목적: 완전한 커스터마이징 및 비용 절감
- 실제 예시:
- 시스템 구성: Kubernetes + Spark + Iceberg + Trino
- 시나리오: 스타트업의 비용 효율적인 데이터 플랫폼
6.10 실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 고려사항 | 데이터 웨어하우스 | 데이터 레이크 | 데이터 레이크하우스 | 권장사항 |
|---|---|---|---|---|
| 데이터 거버넌스 | 엄격한 스키마 관리 필요 | 메타데이터 관리 복잡 | 통합 거버넌스 프레임워크 | 초기부터 거버넌스 정책 수립 |
| 성능 최적화 | 인덱싱 및 파티셔닝 전략 | 파일 크기 및 압축 최적화 | 테이블 포맷별 최적화 기법 | 정기적인 성능 모니터링 및 튜닝 |
| 보안 및 접근제어 | 행/열 수준 보안 구현 | 세밀한 권한 관리 어려움 | 통합된 보안 모델 | 역할 기반 접근 제어 (RBAC) 적용 |
| 비용 관리 | 예측 가능한 비용 구조 | 저장 비용 최적화 필요 | 컴퓨트 - 스토리지 분리 활용 | 사용량 기반 모니터링 및 최적화 |
| 기술 인력 | SQL 및 BI 도구 전문가 | 데이터 엔지니어링 역량 | 통합된 기술 스택 이해 | 지속적인 교육 및 스킬 개발 |
6.11 최적화하기 위한 고려사항 및 주의할 점
| 최적화 영역 | 데이터 웨어하우스 | 데이터 레이크 | 데이터 레이크하우스 | 권장사항 |
|---|---|---|---|---|
| 쿼리 성능 | 구체화된 뷰 활용 | 파티셔닝 전략 수립 | 클러스터링 및 Z-order 최적화 | 워크로드 패턴 분석 기반 최적화 |
| 저장 효율성 | 압축 및 인코딩 | 파일 포맷 선택 (Parquet) | 테이블 포맷 기능 활용 | 정기적인 압축 및 정리 작업 |
| 확장성 | 수직/수평 확장 계획 | 자동 확장 설정 | 멀티 클러스터 설계 | 예상 성장률 기반 용량 계획 |
| 데이터 품질 | ETL 검증 로직 강화 | 데이터 프로파일링 도구 | 스키마 진화 정책 수립 | 자동화된 데이터 품질 체크 |
| 운영 효율성 | 자동화된 모니터링 | 라이프사이클 관리 | 통합 운영 도구 활용 | DevOps/DataOps 문화 도입 |
7. 서로에 대한 강점과 약점
| 구분 | 강점 | 약점 |
|---|---|---|
| 데이터 웨어하우스 | 높은 쿼리 성능, 검증된 안정성, 강력한 BI 도구 지원 | 높은 비용, 스키마 변경 복잡성, 비정형 데이터 처리 한계 |
| 데이터 레이크 | 저렴한 저장 비용, 유연한 스키마, 대용량 처리 | 데이터 품질 관리 어려움, 복잡한 거버넌스, 쿼리 성능 저하 |
| 데이터 레이크하우스 | 유연성과 성능 균형, ACID 트랜잭션 지원, 통합 플랫폼 | 상대적으로 새로운 기술, 복잡한 구현, 벤더별 차이점 |
8. 장점
| 구분 | 항목 | 설명 |
|---|---|---|
| 장점 | 높은 쿼리 성능 | 웨어하우스의 최적화된 스토리지 엔진과 인덱싱으로 복잡한 분석 쿼리를 빠르게 처리 |
| 데이터 일관성 | 웨어하우스의 스키마 강제와 레이크하우스의 ACID 트랜잭션으로 높은 데이터 품질 보장 | |
| 비용 효율성 | 레이크의 오브젝트 스토리지와 레이크하우스의 컴퓨트 - 스토리지 분리로 저렴한 저장 비용 | |
| 확장성 | 레이크와 레이크하우스의 클라우드 네이티브 아키텍처로 탄력적인 확장 가능 | |
| 다양한 데이터 형태 지원 | 레이크와 레이크하우스의 스키마 유연성으로 구조화/비구조화 데이터 모두 처리 | |
| 실시간 처리 | 레이크하우스의 스트리밍 지원으로 배치와 실시간 데이터 통합 처리 |
9. 단점과 문제점 그리고 해결방안
9.1 단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 높은 구현 복잡성 | 레이크하우스의 다양한 컴포넌트 통합으로 인한 아키텍처 복잡성 | 관리형 서비스 활용 및 점진적 마이그레이션 |
| 벤더 종속성 | 웨어하우스의 특정 벤더 기술에 대한 의존성 | 오픈 소스 대안 검토 및 멀티 클라우드 전략 | |
| 기술 인력 부족 | 레이크하우스 등 새로운 기술 스택에 대한 전문 인력 부족 | 지속적인 교육 프로그램 및 컨설팅 활용 | |
| 데이터 거버넌스 복잡성 | 레이크의 유연성으로 인한 데이터 품질 및 보안 관리 어려움 | 자동화된 거버넌스 도구 도입 |
9.2 문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 데이터 스웜프화 | 레이크의 메타데이터 관리 부족 | 데이터 발견성 저하, 중복 데이터 증가 | 데이터 카탈로그 도구 활용 | 데이터 거버넌스 정책 수립 | 자동화된 메타데이터 수집 및 분류 |
| 쿼리 성능 저하 | 파티셔닝 전략 부재, 파일 크기 최적화 실패 | 사용자 경험 악화, 분석 지연 | 성능 모니터링 도구 | 워크로드 패턴 분석 기반 설계 | 적응형 쿼리 최적화 및 캐싱 | |
| 비용 급증 | 비효율적인 리소스 사용, 중복 저장 | 예산 초과, ROI 저하 | 비용 모니터링 대시보드 | 리소스 사용량 예측 모델 | 자동화된 리소스 스케일링 | |
| 보안 침해 | 세밀한 접근 제어 부족 | 데이터 유출, 컴플라이언스 위반 | 접근 로그 분석 | 최소 권한 원칙 적용 | 동적 데이터 마스킹 및 암호화 |
10. 도전 과제
10.1 기술적 도전 과제
멀티 클라우드 상호 운용성
- 원인: 클라우드 제공업체별 서로 다른 API 및 데이터 포맷
- 영향: 벤더 종속성 심화, 마이그레이션 비용 증가
- 해결 방법:
- 오픈 스탠다드 기반 솔루션 채택 (Apache Iceberg, Delta Lake)
- 멀티 클라우드 추상화 계층 구축
- 컨테이너 기반 워크로드 관리
실시간 데이터 처리 통합
- 원인: 배치와 스트리밍 처리 아키텍처의 근본적 차이
- 영향: 데이터 지연, 일관성 문제, 복잡한 운영
- 해결 방법:
- Lambda/Kappa 아키텍처 적용
- 통합 스트리밍 플랫폼 (Apache Kafka, Pulsar) 활용
- Change Data Capture (CDC) 구현
10.2 운영적 도전 과제
데이터 거버넌스 자동화
- 원인: 대용량 데이터와 다양한 데이터 소스로 인한 수동 관리의 한계
- 영향: 데이터 품질 저하, 컴플라이언스 리스크 증가
- 해결 방법:
- AI 기반 데이터 분류 및 태깅
- 자동화된 데이터 계보 추적
- 정책 기반 데이터 접근 제어
조직 간 데이터 공유
- 원인: 부서별 데이터 사일로, 서로 다른 기술 스택
- 영향: 데이터 중복, 분석 결과 불일치
- 해결 방법:
- 데이터 메시 아키텍처 도입
- 연합 쿼리 엔진 활용
- 표준화된 데이터 계약 정의
11. 활용 사례
시나리오: 글로벌 전자상거래 기업의 통합 데이터 플랫폼 구축
시스템 구성:
- 데이터 소스: 웹사이트 로그, 모바일 앱 이벤트, 트랜잭션 DB, 고객 서비스 시스템
- 데이터 레이크하우스: Apache Iceberg + AWS S3 + Trino
- 실시간 스트리밍: Apache Kafka + Apache Flink
- 분석 도구: Apache Superset, Jupyter Notebooks, Tableau
- ML 플랫폼: MLflow + Apache Spark MLlib
시스템 구성 다이어그램:
graph TB
subgraph "Data Sources"
A1[Website Logs]
A2[Mobile App Events]
A3[Transaction DB]
A4[Customer Service]
end
subgraph "Streaming Layer"
B1[Apache Kafka]
B2[Apache Flink]
end
subgraph "Data Lakehouse"
C1[Apache Iceberg Tables]
C2[AWS S3 Storage]
C3[Trino Query Engine]
C4[Metadata Catalog]
end
subgraph "Analytics Layer"
D1[Apache Superset]
D2[Jupyter Notebooks]
D3[Tableau]
D4[MLflow]
end
A1 --> B1
A2 --> B1
A3 --> B1
A4 --> B1
B1 --> B2
B2 --> C1
C1 --> C2
C4 --> C1
C3 --> D1
C3 --> D2
C3 --> D3
C3 --> D4
Workflow:
- 실시간 데이터 수집: Kafka 를 통해 다양한 소스에서 데이터 스트리밍
- 스트림 처리: Flink 를 사용한 실시간 데이터 변환 및 집계
- 데이터 저장: Iceberg 테이블로 ACID 트랜잭션 보장하며 S3 에 저장
- 쿼리 처리: Trino 를 통한 대화형 분석 및 SQL 기반 데이터 접근
- 분석 및 시각화: 다양한 도구를 통한 비즈니스 인텔리전스 및 ML 파이프라인
역할:
- Kafka: 고가용성 데이터 스트리밍 플랫폼
- Flink: 실시간 데이터 처리 및 변환
- Iceberg: 데이터 버전 관리 및 ACID 트랜잭션
- Trino: 고성능 분산 SQL 쿼리 엔진
- S3: 확장 가능한 오브젝트 스토리지
유무에 따른 차이점:
- 기존 상황: 부서별 독립적인 데이터웨어하우스, 월 단위 배치 처리, 높은 인프라 비용
- 도입 후: 실시간 데이터 분석, 70% 인프라 비용 절감, 단일 데이터 소스 구축
구현 예시:
| |
12. 주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| Apache Iceberg | 오픈 테이블 포맷 | Netflix 에서 개발한 대용량 분석 테이블 포맷, 스키마 진화와 타임 트래블 지원 |
| Delta Lake | Databricks 레이크하우스 | ACID 트랜잭션을 데이터 레이크에 제공하는 오픈소스 스토리지 레이어 |
| Snowflake 아키텍처 | 멀티 클러스터 공유 데이터 | 컴퓨트와 스토리지 분리로 독립적 확장성 제공하는 클라우드 DW |
| 실시간 OLAP | ClickHouse, Apache Druid | 실시간 분석 워크로드를 위한 특화된 컬럼형 데이터베이스 |
| Data Mesh | 분산 데이터 아키텍처 | 도메인 중심의 데이터 소유권과 연합 거버넌스 모델 |
| ACID 트랜잭션 | 데이터 일관성 보장 | 원자성, 일관성, 격리성, 지속성을 통한 데이터 신뢰성 확보 |
| Query Federation | 연합 쿼리 엔진 | 다양한 데이터 소스를 통합 쿼리할 수 있는 Trino, Presto 등 |
| Schema Evolution | 스키마 진화 | 기존 데이터에 영향 없이 스키마를 변경할 수 있는 기능 |
13. 반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 클라우드 플랫폼 | AWS 데이터 서비스 | S3, Redshift, Athena, EMR | 아마존 웹 서비스의 데이터 관련 서비스 생태계 |
| GCP 데이터 서비스 | BigQuery, Cloud Storage, Dataflow | 구글 클라우드의 데이터 분석 플랫폼 | |
| Azure 데이터 서비스 | Synapse Analytics, Data Lake Storage | 마이크로소프트 애저의 데이터 플랫폼 | |
| 오픈소스 생태계 | Apache Spark | 분산 데이터 처리 | 대용량 데이터 처리를 위한 통합 분석 엔진 |
| Apache Kafka | 실시간 스트리밍 | 고성능 분산 스트리밍 플랫폼 | |
| Apache Airflow | 워크플로우 오케스트레이션 | 데이터 파이프라인 스케줄링 및 모니터링 | |
| 데이터 모델링 | 차원 모델링 | 스타/스노우플레이크 스키마 | 비즈니스 인텔리전스를 위한 데이터 모델링 기법 |
| 데이터 볼트 | 엔터프라이즈 DW 모델링 | 확장 가능하고 유연한 데이터 웨어하우스 모델링 | |
| 원 빅 테이블 | 와이드 테이블 모델링 | 비정규화된 분석용 테이블 설계 | |
| 성능 최적화 | 파티셔닝 전략 | 수평/수직 파티셔닝 | 쿼리 성능 향상을 위한 데이터 분할 기법 |
| 인덱싱 기법 | 클러스터드/논클러스터드 인덱스 | 빠른 데이터 검색을 위한 인덱스 전략 | |
| 압축 및 인코딩 | 컬럼형 압축 기법 | 저장 공간 효율성을 위한 데이터 압축 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 아키텍처 | MPP (Massively Parallel Processing) | 대규모 병렬 처리 아키텍처로 여러 노드에서 동시에 쿼리 처리 |
| SMP (Symmetric Multiprocessing) | 대칭형 멀티프로세싱으로 여러 CPU 가 메모리를 공유하는 구조 | |
| NUMA (Non-Uniform Memory Access) | 비균등 메모리 접근 아키텍처 | |
| 데이터 포맷 | Parquet | 컬럼형 데이터 저장 포맷으로 압축률과 쿼리 성능 최적화 |
| ORC (Optimized Row Columnar) | 하이브에서 개발된 최적화된 컬럼형 스토리지 포맷 | |
| Avro | 스키마 진화를 지원하는 바이너리 데이터 직렬화 포맷 | |
| 쿼리 엔진 | Trino (구 PrestoSQL) | 분산 SQL 쿼리 엔진으로 다양한 데이터 소스 연합 쿼리 지원 |
| Apache Drill | 스키마 프리 SQL 쿼리 엔진 | |
| Apache Impala | 하둡 생태계용 고성능 SQL 엔진 | |
| 데이터 처리 | CDC (Change Data Capture) | 데이터베이스 변경 사항을 실시간으로 캡처하는 기술 |
| Upsert | Update + Insert 의 합성어로 존재하면 업데이트, 없으면 삽입하는 연산 | |
| Compaction | 작은 파일들을 큰 파일로 합치는 최적화 작업 | |
| 메타데이터 | Data Lineage | 데이터 계보로 데이터의 출처와 변환 과정을 추적 |
| Data Catalog | 데이터 자산을 검색하고 이해할 수 있는 메타데이터 저장소 | |
| Schema Registry | 스키마 버전 관리 및 호환성을 제공하는 중앙 저장소 |
참고 및 출처
- Data Warehouse Vs Data Lake Vs Data Lakehouse: Key Differences
- Data Warehouses vs. Data Lakes vs. Data Lakehouses | IBM
- Data Warehouse vs. Data Lake vs. Data Lakehouse | Striim
- Data Lake vs. Data Warehouse vs. Data Lakehouse | Amplitude
- What is a Data Lakehouse & How does it Work? | Apache Hudi
- Apache Iceberg vs Delta Lake | DataCamp
- Snowflake Cloud Data Warehouse Architecture | XenonStack
- BigQuery vs Snowflake Comparison | Netguru
- Key Concepts & Architecture | Snowflake Documentation
- Open Data Lakehouse Architecture | Starburst
1. 태그 (영문, 하이픈 사용)
- Data-Lake
- Data-Warehouse
- Data-Lakehouse
- Data-Architecture
2. 분류 구조 적절성 검토
기존 “Computer Science and Engineering > … > Architecture Styles > Data‑Centric Architecture” 는 적절하나,
Data Lakehouse 는 전통적 데이터 웨어하우스와 호수 기반 스토리지의 결합체이므로,
이를 반영해 다음과 같이 하위 구조를 보완할 수 있습니다:
이 구조는 상위 범위 ‘System Design > Distributed Systems’ 아래에 Data-centric Architecture 로 묶고,
DW / Lake / Lakehouse 를 동등한 개념으로 나누는 것이 실무 아키텍처 관점에서 명확합니다.
3. 요약 문장 (~200 자)
Data Warehouse 는 구조화된 데이터를 스키마‑온‑라이트 방식으로 저장하여 BI 중심의 분석에 최적화된 반면,
Data Lake 는 비정형/raw 데이터를 스키마‑온‑리드 방식으로 대규모 유연 저장에 적합합니다.
Data Lakehouse 는 두 방식을 통합해 메타데이터 관리와 SQL 성능 보장을 통해 데이터 통합 플랫폼을 제공합니다. (Atlan)
4. 개요 (~250 자)
Data Warehouse 는 과거 CRM, ERP 등 구조화된 기업 데이터를 ETL/ELT 기반으로 정형 저장해 BI 및 레거시 분석에 특화된 시스템입니다.
Data Lake 는 모든 유형의 데이터를 스키마 없이 원시 그대로 저장하고, 데이터 과학·머신러닝 작업에 유연성을 제공합니다.
Data Lakehouse 는 이 둘을 통합하여 스키마‑온‑라이트와 온‑리드, ACID 트랜잭션, 오픈 테이블 포맷을 기반으로 실시간 분석, ML, BI 를 단일 플랫폼에서 실행 가능하게 합니다.
대량 데이터 저장 대비 비용 효율, 거버넌스, 성능 최적화를 동시에 달성하는 현대 데이터 시스템 아키텍처입니다.
5. 핵심 개념
데이터 웨어하우스 (Data Warehouse)
- 스키마‑온‑라이트 (schema-on-write): 저장 전 정형화
- ETL / ELT 기반 데이터 통합
- 정형 데이터 중심, BI⁄리포팅 최적화
- ACID 트랜잭션 보장, 데이터 품질 제어
데이터 레이크 (Data Lake)
- 스키마‑온‑리드 (schema-on-read): 읽기 시 정형화
- 원시, 반정형, 비정형 데이터 저장 가능
- 비용 효율적 객체 저장소 (예: S3, ADLS)
- ML 및 데이터 분석 유연성 극대화
데이터 레이크하우스 (Data Lakehouse)
- 오픈 테이블 포맷 (Apache Iceberg, Delta Lake 등)
- 메타데이터 관리, 스키마 진화, 타임 트래블 지원
- ACID 트랜잭션, 인덱싱/캐시, 데이터 카탈로그
- 구조화와 비구조화 데이터를 단일 플랫폼에서 관리
- SQL 기반 쿼리 + ML⁄AI 워크로드 지원 (ConnectWise)
구현 연관성 분석
- 레이크하우스는 레이크 저장소 위에 웨어하우스를 얹은 형태이며,
메타데이터 레이어와 스키마 관리 기능이 실무에서 데이터 품질과 엔지니어링 파이프라인 구현에 핵심입니다. - ETL/ELT 도구, Apache Spark, 포맷 관리 (Parquet, Delta), 카탈로그 (Hive, Glue), ACID 를 지원하는 분산 엔진이 통합되어야 합니다.
6. 비교 분석 개요 및 표
개요
각 아키텍처는 저장 방식, 스키마 적용 시점, 쿼리 성능, 비용, 적합한 워크로드 측면에서 서로 차별화됩니다.
다음 표는 주요 항목별 비교입니다.
| 구분 | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| 저장 데이터 | 정형 | 정형/반정형/비정형 | 모두 |
| 스키마 적용 | on-write | on-read | 하이브리드 (on-read/write) |
| 비용 | 높음 | 낮음 | 비용 효율적 |
| ACID 보장 | ✔ | ✘ | ✔ |
| 쿼리 성능 (BI) | 우수 | 낮음 | 우수 (튜닝 필요) (Reddit, Dremio, 데이터캠프) |
| ML/AI 지원 | 제한적 | 매우 유연 | 통합 지원 |
| 거버넌스/카탈로그 | 강력 | 약함 (스웜 위험) | 강력 + 버전관리 |
7. 구조 및 아키텍처 다이어그램
- 레이어 구성: Ingestion, Storage, Metadata, API, Consumption 계층으로 구성됨 (Serokell Software Development Company)
- 스토리지 분리: Compute 와 Storage 분리 (Data Lake 기반), 오브젝트 스토리지 활용
- 메타데이터 레이어: ACID, 스키마 진화, 시간 여행, 인덱싱 제공
8. 구성 요소
필수 구성 요소
- 스토리지 레이어: S3 / ADLS / GCS 등 객체 스토리지
- 오픈 테이블 포맷: Delta Lake, Apache Iceberg 등
- 메타데이터 카탈로그: Hive 메타스토어, AWS Glue, Iceberg catalog
- 쿼리 엔진: Spark SQL, Presto/Trino, Databricks
- 트랜잭션 관리: ACID, 스냅샷 isolation
선택 구성 요소
- 캐싱 / 인덱싱 계층: Delta cache, z-order indexing
- 데이터 품질/라벨링 도구: Deequ, Great Expectations
- 데이터 거버넌스 툴: Purview, Alation
- 스트리밍 플랫폼: Kafka, kinesis, Flink
9. 구현 기법 및 방법
- ELT 기반 ingest: 원시 데이터 → 객체 스토리지 저장 → 테이블 포맷으로 변환
- Delta Lake 사용: MERGE, UPDATE, DELETE 통해 ACID 트랜잭션 적용
- Time Travel 활용: 테이블 버전 조회 및 복원
- 스키마 진화 지원: Parquet schema merge, Iceberg schema evolution
- 여러 쿼리 엔진 연결: BI 툴 (Power BI, Tableau) 와 통합
10. 실무 적용 및 주의사항
| 고려사항 | 설명 | 권장사항 |
|---|---|---|
| 데이터 거버넌스 | 메타데이터 일관성 유지 | 카탈로그 자동화, 스키마 정책 설정 |
| 쿼리 성능 | 큰 테이블 탐색 시 느림 | 인덱싱, 파티셔닝, 클러스터링 도입 |
| 비용 관리 | 스토리지·컴퓨팅 비용 증가 | 티어드 스토리지, Auto‑scaling 활용 |
| 기술 복잡성 | 오픈 포맷 관리가 어려움 | 관리형 서비스 (Delta, Iceberg) 적극 활용 |
| 성숙도 | 레이크하우스 도구 생태계 성숙 중 | 검증된 솔루션 우선 적용, PoC 실행 |
11. 최적화 고려사항
| 항목 | 고려사항 | 권장 |
|---|---|---|
| 파티셔닝 | 쿼리 필터 컬럼 기준 파티셔닝 | 전략적 파티셔닝 계획 |
| 인덱싱/클러스터링 | 자주 조회하는 컬럼 중심 | Z‑order indexing 등 활용 |
| 캐시 | 빈번한 쿼리에 대해 캐싱 | Delta cache, Presto cache |
| 테이블 정리 | 스냅샷 증가, 파일 수 증가 | VACUUM, OPTIMIZE 주기적 실행 |
| 비용 최적화 | 스토리지·컴퓨팅 분리 | 사용 안 할 때 compute off |
12. 강점과 약점 비교
| 유형 | 항목 | 설명 |
|---|---|---|
| 강점 | 통합 플랫폼 | 원시 + 정형 데이터 단일 저장소 |
| 비용 효율성 | 객체 스토리지 기반 확장성 | |
| ACID & SQL | 신뢰성 있는 분석 제공 | |
| 유연한 워크로드 | BI, ML, 스트리밍 모두 지원 | |
| 약점 | 복잡성 | 오픈 포맷과 관리 추가 부담 |
| 성숙도 | DW 보다 아직 신생 기술 | |
| 초기 비용 | 도입 및 전문 인력 필요 |
13. 단점 및 문제점과 해결 방안
단점
| 구분 | 항목 | 설명 | 해결책 |
|---|---|---|---|
| 단점 | 높은 복잡도 | 레이크와 웨어하우스 기능 통합 관리 필요 | 관리형 서비스 사용, 자동화 도입 |
| 초기 도입 비용 | 도구 학습, 인프라 준비 비용 존재 | 단계적 PoC, ROI 평가 기반 도입 | |
| 툴 성숙도 부족 | 일부 툴 기능 제한적 | 충분한 벤더 조사 후 선택 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 데이터 스웜화 | 메타데이터 부재 | 검색 어려움, 낮은 품질 | 정기 데이터 카탈로그 감사 | 거버넌스 자동화 도구 도입 | 데이터 품질 툴 + 카탈로그 |
| 문제점 | 쿼리 성능 저하 | 큰 단일 파일, 인덱스 없음 | BI 속도 저하 | 쿼리 속도 모니터링 | 파티션, 인덱스 설계 | OPTIMIZE / VACUUM 주기 실행 |
14. 기타 사항
- Data Mesh, Data Fabric 등과 비교 시 Lakehouse 는 중앙집중형이지만 유연한 거버넌스와 분산 소유권 구조에 대한 보완 고려 필요 (ConnectWise, AltexSoft)
- 오픈 포맷: Delta Lake, Apache Iceberg, Hudi 비교 및 도입 전략 학습 권장.
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 아키텍처 | Schema‑on‑write | 저장 시 스키마 검사 방식 |
| 아키텍처 | Schema‑on‑read | 읽기 시 스키마 적용 방식 |
| 저장 | ACID | Atomicity, Consistency, Isolation, Durability |
| 저장 | Time travel | 테이블의 이전 버전 조회 기능 |
| 저장 | Open Table Format | Delta Lake, Apache Iceberg 등 포맷 |
| 데이터 관리 | Metadata catalog | 데이터 객체에 대한 설명 및 인덱스 정보 저장소 |
참고 및 출처
- [AltexSoft: Data Lakehouse 개념 및 구조 설명] (https://www.altexsoft.com/blog/data-lakehouse/)
- [Atlan: Data Warehouse / Lake / Lakehouse 비교] (https://atlan.com/data-warehouse-vs-data-lake-vs-data-lakehouse/)
- [SyncComputing: Lakehouse 기능 요약] (https://synccomputing.com/data-lake-vs-data-warehouse-vs-data-lakehouse/)
- [Datacamp, Serokell, IBM 자료 종합]
필요한 부분 (예: 특정 플랫폼 예시, 활용 사례 등 추가 요청하시면 단계별로 확장 가능합니다.
이어서 아래 항목부터 상세하게 작성합니다:
활용 사례
시나리오:
대형 전자상거래 플랫폼에서는 웹 로그, 제품 클릭, 주문 데이터, 고객 지원 로그 등 다양한 데이터 소스를 실시간으로 수집하며, 이를 기반으로 추천 알고리즘, 사용자 행동 분석, 매출 리포트 등을 생성하고자 한다.
시스템 구성:
- 실시간 이벤트 스트리밍 (Kafka)
- 데이터 저장소: AWS S3 기반 Data Lake
- 레이크하우스 메타 레이어: Delta Lake
- 분석 쿼리: Databricks SQL / Apache Spark
- BI 대시보드: Power BI / Tableau
- ML 모델 학습: MLflow, PySpark 기반 모델 트레이닝
- 데이터 거버넌스: AWS Glue, Unity Catalog
시스템 구성 다이어그램:
flowchart TD
subgraph Source
A1[Web Logs] --> E[Kafka]
A2[Transaction DB] --> F[Change Data Capture]
end
E --> B1[Ingestion Layer (Kafka Connect, Spark Streaming)]
F --> B1
B1 --> B2[Raw Data Zone (S3)]
B2 --> B3[Delta Lake Storage]
B3 --> C1[Databricks SQL (BI)]
B3 --> C2[PySpark ML 모델 학습]
B3 --> C3[Power BI Dashboard]
B3 --> C4[Data Governance (Glue, Unity Catalog)]
Workflow:
- Kafka 를 통해 사용자 활동 로그 및 주문 이벤트 스트리밍 수집
- Spark Streaming 으로 수집 → Delta Lake 에 저장
- Delta Lake 에서 ACID 트랜잭션 보장된 테이블 포맷 관리
- Databricks SQL 을 통해 BI 대시보드와 실시간 리포트 생성
- 동일한 데이터셋을 PySpark 기반 ML 모델 학습에도 활용
- Glue/Unity Catalog 를 통해 테이블, 권한, 메타데이터 중앙 관리
역할:
- Data Lake: 로그, 원시 데이터의 대용량 저장소 역할
- Data Lakehouse (Delta Lake): ACID 트랜잭션, 스키마 진화, 통합 분석 처리
- BI: Power BI, Tableau 에서 실시간 쿼리 처리
- ML: PySpark 기반 추천 모델 학습
유무에 따른 차이점:
| 항목 | 레이크하우스 도입 전 | 레이크하우스 도입 후 |
|---|---|---|
| 분석 정확도 | 데이터 정합성 부족, ETL 오류 발생 | ACID 보장된 정형화된 분석 |
| 데이터 처리 | 데이터 사일로 존재, 복잡한 파이프라인 | 단일 저장소 기반 분석 통합 |
| ML 적용성 | 중복 데이터 및 데이터 불일치 | 동일 테이블 기반 ML 모델 학습 용이 |
| 유지보수 | 스키마 관리, 중복 인프라 | 스키마 진화, 단일 플랫폼 관리 |
구현 예시 (PySpark + Delta Lake):
| |
주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 기술 스택 | Delta Lake | ACID 트랜잭션과 스키마 진화를 지원하는 테이블 포맷 |
| 오픈 포맷 | Apache Iceberg | 대규모 레이크 테이블 포맷, 시간여행 및 SQL 인터페이스 지원 |
| 데이터 관리 | Data Catalog | 테이블 메타데이터 관리 및 검색성 제공 |
| 아키텍처 전략 | Unified Analytics | ML, BI, ELT 워크로드를 단일 플랫폼에서 실행 가능 |
| 실무 적용 | Multi-cloud 레이크하우스 | AWS, GCP, Azure 에서 동시 지원 및 분석 가능 환경 구성 |
반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| 데이터 아키텍처 | Table Format | Delta Lake, Iceberg, Hudi | 오픈 레이크하우스 테이블 포맷의 차이와 사용법 |
| 쿼리 성능 최적화 | Z‑Order, OPTIMIZE | 파티션 최적화 | 대용량 데이터 쿼리 가속 기법 |
| 데이터 거버넌스 | Unity Catalog, Purview | 보안/정책 관리 | 사용자/테이블 수준의 권한 관리 및 감사 로그 |
| 워크로드 통합 | MLflow, Spark MLlib | 분석 파이프라인 통합 | 분석에서 모델 학습까지 연결하는 실무 전략 |
| 데이터 파이프라인 | Streaming Ingest | Kafka → Delta | 실시간 데이터 수집 및 분석 처리 구조 |
마무리 요약
Data Warehouse, Data Lake, Data Lakehouse 는 각각 전통 BI 분석, 데이터 확장성과 유연성, 최신 통합 분석 환경을 대표합니다.
특히 Lakehouse 는 최근 AI/ML 기반 분석과 실시간 요구에 적합한 하이브리드 아키텍처로 부상하며, 오픈 포맷, ACID 지원, 거버넌스, 비용 효율성을 갖춘 데이터 통합 전략으로 주목받고 있습니다.
이어서 다음 항목들을 중심으로 정리합니다:
도전 과제 (Challenges)
데이터 웨어하우스, 레이크, 레이크하우스를 실무에 적용할 때 직면하는 기술적/운영적 도전 과제를 다음과 같이 카테고리화하여 정리합니다.
1. 기술적 도전 과제
| 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|
| 스키마 진화 충돌 | 데이터 생산자 - 소비자 간 버전 불일치 | 분석 실패, 모델 학습 오류 | 스키마 호환성 체크 | 자동 테스트 및 카탈로그 버전 관리 | 스키마 enforcement 및 버전 추적 |
| 쿼리 성능 저하 | 분산 환경, 비정형 데이터 탐색 | SLA 미충족, BI 성능 저하 | 쿼리 지연 로그, scan volume | 파티셔닝/인덱싱 전략 수립 | OPTIMIZE, Z-Order 등 적용 |
| 데이터 품질 저하 | 비정형 입력, 잘못된 변환 | 분석 오차 및 인사이트 오류 | Deequ, Great Expectations 등으로 검증 | 정합성 체크, 라벨링 전략 | 검증 루틴 자동화 및 경고 시스템 |
| 메타데이터 불일치 | 다양한 테이블 포맷과 카탈로그 병행 | 카탈로그 혼선, 쿼리 오류 | 카탈로그 상태 진단 도구 | 중앙 카탈로그 정책 수립 | Unity Catalog, Glue 등의 통합 적용 |
| 파일 수 증가 | 분산 병렬 처리 후 작은 파일 생성 | I/O 오버헤드 증가, 성능 저하 | Storage monitoring | 데이터 정합성 확보 후 병합 | VACUUM, COMPACT, OPTIMIZE 주기 실행 |
2. 운영 및 관리 도전 과제
| 항목 | 원인 | 영향 | 탐지 및 진단 | 예방 방법 | 해결 방법 및 기법 |
|---|---|---|---|---|---|
| 비용 예측 불가 | 사용량 기반 요금제, auto-scaling | 예산 초과 | Cloud Cost 분석도구 | 리소스 별 사용 제한 설정 | Auto Termination, Budget 알람 설정 |
| 거버넌스 미비 | 다수의 데이터 사용자, 권한 분산 | 데이터 노출, 규정 위반 | 감사 로그, 접근 추적 | 최소 권한 원칙 적용 | Data Catalog + RBAC 기반 정책 설정 |
| 기술 격차 | 다양한 오픈소스/클라우드 도구 | 운영 혼선, 장애 처리 지연 | 기술 이해도 평가 | 도구 표준화, 문서화 | 도구별 교육, 통합 운영 설계 |
| 버전/포맷 호환성 | 다양한 오픈 테이블 포맷 | Spark, Presto 등 엔진 호환 문제 | 쿼리 실행 실패 이력 추적 | 표준 포맷 사용 우선 | Delta, Iceberg 등 단일 채택 전략 |
기타 사항
관련 개념 비교 대상 정리:
추가로 비교하거나 연계 학습이 필요한 주제는 다음과 같습니다.
| 주제 | 항목 | 설명 |
|---|---|---|
| Data Mesh | 분산 소유권 기반 데이터 플랫폼 | Lakehouse 와는 조직 모델에서 차별화 |
| Data Fabric | 메타데이터 기반 데이터 자동화 레이어 | 데이터 통합 접근 방식 중심 |
| Open Table Format | Delta vs Iceberg vs Hudi | 데이터 품질, 성능, 카탈로그 처리 방식의 차이 |
| Columnar Formats | Parquet vs ORC vs Avro | 저장 최적화 포맷 비교 |
| Unified Platform | Snowflake, Databricks, Google BigLake | 실무 구축 시 주요 플랫폼 선택 고려 대상 |
참고 아키텍처 트렌드 및 학습 연계 항목
반드시 학습해야할 내용
| 카테고리 | 주제 | 항목 | 설명 |
|---|---|---|---|
| Storage Architecture | Separation of Storage and Compute | 레이크하우스 기반 성능과 비용 분리 | |
| Distributed Query Engine | Presto, Trino | 데이터 레이크에 직접 SQL 실행 | |
| Open Table Formats | Delta Lake, Iceberg, Hudi | ACID + 성능 + 스키마 진화 핵심 기술 | |
| Governance & Catalog | Unity Catalog, AWS Glue, Hive Metastore | 테이블 메타데이터, 권한 관리 핵심 요소 | |
| Pipeline Tooling | Apache Spark, dbt, Airflow | 데이터 수집 및 변환 파이프라인 구축 |
요약 정리
Data Warehouse, Data Lake, Data Lakehouse 는 각각 특정 목적과 아키텍처 스타일을 기반으로 설계되었으며,
실제 시스템 설계 시에는 단순히 저장과 분석의 관점뿐 아니라 비용, 성능, 유연성, 데이터 품질, 거버넌스까지 고려해야 합니다.
특히 Data Lakehouse 는 단일 저장소 기반의 분석 통합이라는 강점을 가지며,
오픈 테이블 포맷, 메타데이터 카탈로그, 트랜잭션 관리 기술이 중요한 성공 요인입니다.
다음 작성 가능 항목 (선택 가능)
- Delta Lake vs Apache Iceberg vs Apache Hudi 상세 비교
- Lakehouse vs Data Mesh 조직 설계 관점 비교
- 플랫폼별 아키텍처 비교 (Databricks vs Snowflake vs GCP BigLake)
- 보안 및 거버넌스 전략: Lakehouse 에서 권한 관리, 감사, 데이터 분리
필요한 방향을 알려주시면 이어서 상세 작성해드리겠습니다.