Data Pipeline Pattern
데이터 파이프라인 패턴은 데이터를 원천에서 목적지로 이동시키는 과정을 자동화하고 최적화하는 아키텍처 패턴이다.
이 패턴은 데이터의 수집, 처리, 저장, 분석에 이르는 전체 과정을 효율적으로 관리하는 데 사용된다.
데이터 파이프라인 패턴을 효과적으로 구현하면 데이터 기반 의사결정을 지원하고, 비즈니스 인텔리전스를 향상시킬 수 있다. 각 조직의 요구사항과 데이터 특성에 맞는 최적의 패턴을 선택하고 구현하는 것이 중요하다.
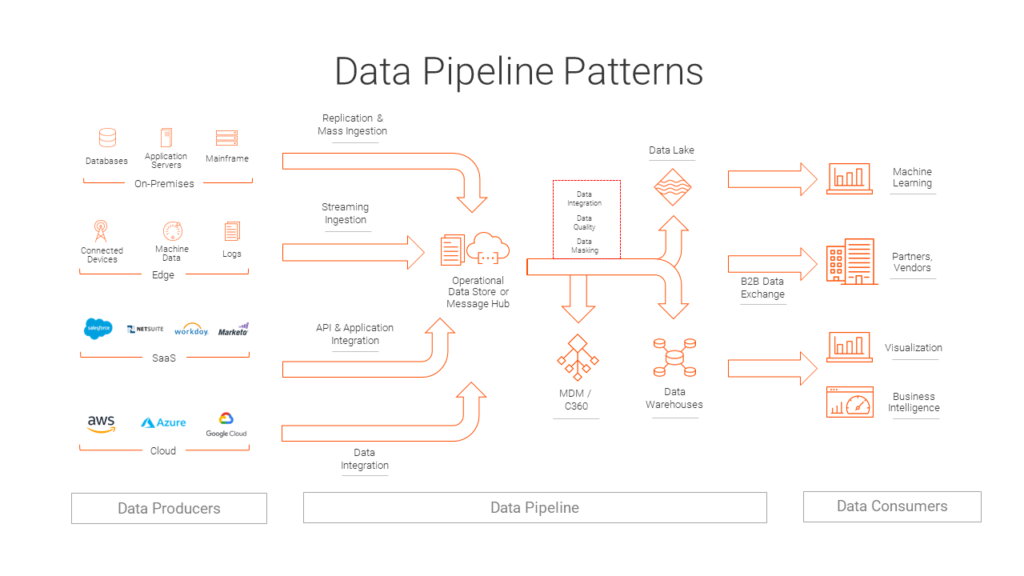
데이터 파이프라인의 주요 구성요소
데이터 수집 (Data Ingestion)
- 다양한 소스(데이터베이스, API, 로그 파일 등)에서 데이터를 추출한다.
- 실시간 또는 배치 방식으로 데이터를 수집할 수 있다.
데이터 처리 및 변환 (Data Processing and Transformation)
- 원시 데이터를 정제, 변환, 집계하여 분석에 적합한 형태로 만듭니다.
- ETL(Extract, Transform, Load) 또는 ELT(Extract, Load, Transform) 프로세스가 이 단계에서 수행된다.
데이터 저장 (Data Storage)
- 처리된 데이터를 데이터 웨어하우스, 데이터 레이크 등에 저장한다.
데이터 분석 및 시각화 (Data Analysis and Visualization)
- 저장된 데이터를 분석하고 인사이트를 도출한다.
- BI 도구를 사용하여 데이터를 시각화한다.
주요 데이터 파이프라인 패턴
ETL (Extract, Transform, Load)
- 데이터를 추출하여 변환한 후 목적지에 로드하는 전통적인 방식이다.
- 복잡한 데이터 변환이 필요한 경우에 적합하다.
ELT (Extract, Load, Transform)
- 데이터를 먼저 목적지에 로드한 후 변환을 수행한다.
- 대규모 데이터 처리에 효과적이며, 클라우드 환경에서 많이 사용된다.
스트리밍 ETL
- 실시간으로 데이터를 수집, 처리, 저장한다.
- 센서 데이터, 로그 데이터 등 지속적으로 생성되는 데이터에 적합하다.
데이터 레이크 아키텍처
- 대량의 원시 데이터를 저장하고 필요에 따라 처리하는 방식이다.
- 다양한 형식의 데이터를 유연하게 저장하고 분석할 수 있다.
구현 시 고려사항
- 확장성: 데이터 볼륨 증가에 대응할 수 있는 아키텍처를 설계해야 한다.
- 신뢰성: 데이터 손실을 방지하고 일관성을 유지해야 한다.
- 유연성: 새로운 데이터 소스나 처리 요구사항을 쉽게 추가할 수 있어야 한다.
- 모니터링: 파이프라인의 성능과 상태를 지속적으로 모니터링해야 한다.
- 데이터 품질: 데이터의 정확성과 일관성을 보장하기 위한 검증 단계를 포함해야 한다.
구현 도구 및 기술
- Apache Spark: 대규모 데이터 처리에 적합한 분산 컴퓨팅 프레임워크이다.
- Apache Airflow: 복잡한 데이터 파이프라인의 워크플로우를 관리하는 데 사용된다.
- Apache Kafka: 실시간 데이터 스트리밍에 효과적이다.
- AWS Glue, Azure Data Factory: 클라우드 기반의 ETL 서비스이다.