Data Engineering
1. 주제의 분류 적합성
데이터 엔지니어링 (Data Engineering) 은 데이터 수집, 저장, 처리, 분석을 위한 인프라 구축 및 관리에 초점을 맞춘 분야로, 컴퓨터 과학 및 공학 (Computer Science and Engineering) 의 핵심 하위 분야로 분류됩니다. 이는 소프트웨어 개발, 시스템 설계, 알고리즘 최적화 등과 밀접하게 연관되어 있습니다 [1][7].
2. 200 자 내외 요약 설명
데이터 엔지니어링은 데이터 파이프라인 설계, ETL(Extract-Transform-Load) 프로세스 구축, 데이터 저장소 관리 등을 통해 분석·AI 모델에 필요한 고품질 데이터를 제공하는 분야입니다. 데이터 엔지니어는 구조화/비구조화 데이터를 처리하며, 2025 년에는 AI 통합, 실시간 처리, LakeDB 등 기술이 주목받고 있습니다 [4][5][8].
3. 200 자 내외 개요
데이터 엔지니어링은 데이터의 수집·정제·저장·전달을 체계화하여 분석 및 의사결정을 지원합니다. 주요 구성 요소로는 데이터 레이크, 웨어하우스, ETL 도구, 분산 처리 프레임워크 (Spark, Hadoop) 가 있으며, 최신 트렌드로는 AI 기반 자동화, 데이터 메시 (Data Mesh), 엣지 컴퓨팅이 부상합니다. 실무에서는 확장성·보안·효율성을 고려한 인프라 설계가 핵심입니다 [3][6][9].
4. 핵심 개념
- ETL/ELT: 데이터 추출·변환·적재 프로세스 [3].
- 데이터 파이프라인: 데이터 흐름을 자동화하는 시스템 [7].
- 데이터 레이크: 원시 데이터 저장소 (S3, Hadoop)[9].
- 데이터 웨어하우스: 정제된 데이터 분석용 저장소 (Redshift, BigQuery)[9].
- 분산 처리: 대용량 데이터 병렬 처리 (Spark, Flink)[3].
- 데이터 거버넌스: 품질·보안·규정 준수 관리 [4].
5. 주요 내용 정리
목적 및 필요성
- 데이터 접근성: 분석·AI 모델에 신뢰할 수 있는 데이터 제공 [7].
- 효율성: 자동화를 통한 처리 시간 단축 [3].
- 규모 확장: 대량 데이터 처리 인프라 구축 [9].
주요 기능 및 역할
- 데이터 수집: API, 로그 파일, 센서 등에서 데이터 추출 [3].
- 정제·변환: 노이즈 제거, 형식 표준화 [3].
- 저장·관리: 데이터 레이크·웨어하우스 운영 [9].
- 모니터링: 파이프라인 성능·오류 감시 [6].
특징
- 확장성: 클라우드 기반 수평 확장 [5].
- 실시간 처리: Kafka, Flink 활용 [4].
- 다양한 데이터 형식: 정형·비정형 (텍스트, 이미지) 지원 [3].
핵심 원칙
- 신뢰성: 데이터 정확성 보장 [6].
- 유연성: 변화하는 요구사항 대응 [9].
- 보안: 암호화·접근 제어 [4].
주요 원리 및 작동 원리
| |
Spark 처리 예시:
구조 및 아키텍처
- 계층 구조:
- 수집 계층: Kafka, Flume
- 저장 계층: S3(레이크), Redshift(웨어하우스)
- 처리 계층: Spark, Airflow
- 서비스 계층: API·대시보드 [9].
구성 요소
| 구성 요소 | 설명 |
|---|---|
| 수집 도구 | Apache NiFi, Kafka |
| 저장소 | HDFS, Snowflake |
| 처리 엔진 | Spark, Flink |
| 오케스트레이션 | Airflow, Luigi |
장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 확장성 | 클라우드·분산 처리로 대량 데이터 지원 |
| 자동화 | 반복 작업 효율화 | |
| 다목적 활용 | 분석·AI·비즈니스 인텔리전스 지원 | |
| ⚠ 단점 | 복잡성 | 다양한 도구 통합 난이도 |
| 유지보수 비용 | 인프라 관리 리소스 소요 | |
| 보안 리스크 | 데이터 유출·오용 가능성 |
도전 과제
- 실시간 처리: 저지연 스트리밍 데이터 대응 [4].
- 데이터 품질: 노이즈·결측치 관리 [3].
- AI 통합: ML 모델 연동 파이프라인 구축 [8].
분류에 따른 종류 및 유형
| 분류 | 유형 | 설명 |
|---|---|---|
| 처리 방식 | 배치 처리: 주기적 대량 데이터 (Spark) | |
| 실시간 처리: 즉시 분석 (Kafka+Flink) | ||
| 저장소 | 레이크: 원시 데이터 저장 (S3) | |
| 웨어하우스: 정제된 데이터 분석 (Redshift) |
실무 적용 예시
| 분야 | 예시 | 설명 |
|---|---|---|
| e-commerce | 고객 행동 분석 | 클릭스트림 데이터 수집·분석 |
| 헬스케어 | 환자 데이터 통합 | EHR(전자의무기록) 파이프라인 구축 |
활용 사례 (시나리오 및 다이어그램)
시나리오: 금융 사기 탐지 시스템
- 데이터 수집: 거래 로그·사용자 활동 데이터 수집 (Kafka)
- 정제: 이상 패턴 식별 (Spark)
- 저장: 정제 데이터 적재 (Redshift)
- 분석: ML 모델로 사기 거래 예측 (SageMaker)
| |
실무에서 효과적으로 적용하기 위한 고려사항
| 구분 | 항목 | 설명 |
|---|---|---|
| 설계 | 확장성 | 클라우드 네이티브 아키텍처 채택 |
| 보안 | 암호화 | 전송·저장 시 AES-256 적용 |
| 모니터링 | 대시보드 | 파이프라인 성능 시각화 (Grafana) |
8. 2025 년 기준 최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| AI 통합 | AutoML | 코드 없이 모델 구축 (H2O.ai) |
| 저장 기술 | LakeDB | 데이터 레이크·DB 통합 [5] |
| 처리 기술 | 엣지 컴퓨팅 | IoT 데이터 실시간 처리 [4] |
| 아키텍처 | 데이터 메시 | 분산 데이터 관리 (Data Mesh)[5] |
| 개발 환경 | Data IDE | 통합 데이터 개발 플랫폼 [10] |
9. 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| AI/ML | 생성형 AI | GPT-4 기반 데이터 정제 자동화 [4] |
| 보안 | 연합 학습 | 개인정보 보호 모델 학습 [4] |
| 클라우드 | 서버리스 | AWS Lambda 기반 이벤트 처리 [5] |
10. 앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 기술 | 양자 컴퓨팅 | 복잡 문제 초고속 해결 [4] |
| 표준 | 제로 ETL | 데이터 이동 최소화 [5] |
| 인력 | 시민 데이터 엔지니어 | Low-Code 도구 활용 확대 [5] |
11. 하위 주제별 추가 학습 필요 내용
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 클라우드 | AWS/GCP/Azure | 주요 플랫폼별 데이터 서비스 |
| AI | MLOps | 모델 배포·관리 자동화 |
| 보안 | GDPR·CCPA | 데이터 규정 준수 |
12. 추가 학습 필요 내용
| 카테고리 | 주제 | 설명 |
|---|---|---|
| 프로그래밍 | Python·Scala | Spark·Flink 개발 역량 |
| 도구 | dbt·Airflow | 데이터 변환·오케스트레이션 |
용어 정리
| 용어 | 설명 |
|---|---|
| ETL | 데이터 추출·변환·적재 프로세스 |
| Data Mesh | 분산 데이터 관리 아키텍처 |
| LakeDB | 데이터 레이크와 DB 통합 기술 |
참고 및 출처
Data Engineering 은 원시 데이터를 수집, 저장, 처리하여 분석 가능한 형태로 변환하는 과정을 다루는 분야.
이는 데이터 기반 의사결정과 인사이트 도출을 위한 핵심적인 역할을 수행한다.
중요성
- 비즈니스 의사결정 지원
- 실시간 데이터 기반 의사결정
- 예측적 분석 가능
- 비즈니스 인텔리전스 강화
- 디지털 트랜스포메이션 촉진
- 레거시 시스템 현대화
- 데이터 중심 문화 구축
- 비즈니스 프로세스 최적화
- 경쟁 우위 확보
- 고객 인사이트 발굴
- 운영 효율성 증대
- 혁신 기회 포착
발전 방향
기술적 트렌드
- 클라우드 네이티브: 클라우드 기반 서비스를 활용하여 확장성과 유연성을 높인다.
- 서버리스 아키텍처
- 컨테이너화
- 마이크로서비스
- 자동화
- DataOps
- MLOps
- 자동 스케일링
- 실시간 처리: 데이터를 생성 즉시 분석하여 신속한 대응을 가능하게 한다.
- 스트림 프로세싱
- 이벤트 기반 아키텍처
- 실시간 분석
도메인 트렌드
- AI/ML 통합: 인공지능과 머신러닝을 데이터 파이프라인에 통합하여 자동화와 최적화를 강화한다.
- 자동화된 특성 추출
- 모델 파이프라인
- 실시간 예측
- 데이터 거버넌스: 데이터 보안, 규정 준수, 품질 관리에 대한 중요성이 증가한다.
- 메타데이터 관리
- 데이터 카탈로그
- 규정 준수
- 데이터 민주화
- 셀프 서비스 분석
- 데이터 제품화
- 데이터 마켓플레이스
데이터 엔지니어링의 주요 구성 요소
. 데이터 아키텍처
데이터 모델링
- 논리적/물리적 데이터 모델
- 스키마 설계
- 데이터 관계 정의
저장소 설계
- 데이터 웨어하우스
- 데이터 레이크
- 하이브리드 아키텍처
확장성 계획
- 수평적/수직적 확장
- 분산 시스템 설계
- 성능 최적화
데이터 통합
ETL/ELT 프로세스
- 데이터 추출
- 데이터 변환
- 데이터 적재
데이터 품질 관리
- 데이터 검증
- 정합성 체크
- 오류 처리
데이터 보안
접근 제어
- 인증/인가
- 역할 기반 접근 제어
- 감사 로깅
데이터 보호
- 암호화
- 마스킹
- 개인정보 보호
데이터 엔지니어링 파이프라인과 각 단계별 설명
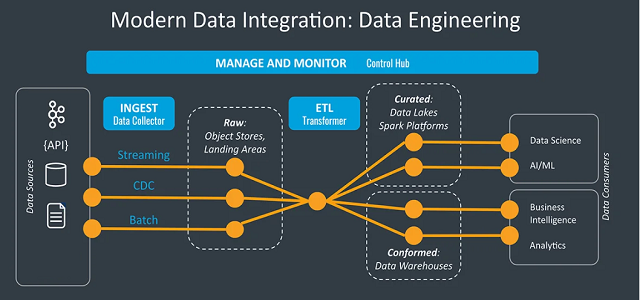
데이터 소스 (Source)
- 다양한 소스 (데이터베이스, API, IoT 장치 등) 에서 데이터를 추출한다.
- 실시간 또는 배치 방식으로 데이터를 수집한다.
데이터 수집 (Ingestion)
- 추출된 데이터를 파이프라인으로 가져온다.
- 데이터의 형식, 속도, 볼륨을 고려하여 적절한 수집 방법을 선택한다.
데이터 처리 (Processing)
- 수집된 데이터를 정제, 변환, 집계한다.
- ETL(Extract, Transform, Load) 또는 ELT(Extract, Load, Transform) 프로세스를 적용한다.
- 데이터의 품질을 검증하고 오류를 처리한다.
데이터 저장 (Storage)
- 처리된 데이터를 적절한 저장소에 저장한다.
- 데이터 웨어하우스, 데이터 레이크, 또는 특정 목적의 데이터베이스를 사용한다.
데이터 분석 및 시각화 (Analysis and Visualization)
- 저장된 데이터를 분석하고 인사이트를 도출한다.
- BI 도구, 대시보드, 리포팅 시스템을 통해 데이터를 시각화한다.
데이터 소비 (Consumption)
- 최종 사용자나 애플리케이션이 처리된 데이터를 활용한다.
- API, 데이터 마트, 또는 직접 쿼리를 통해 데이터에 접근한다.
핵심 기술 스택
- 프로그래밍 언어
- Python
- SQL
- Scala
- Java
- 프레임워크 & 도구
- Apache Spark
- Apache Kafka
- Apache Airflow
- dbt
- 클라우드 플랫폼
- AWS
- Google Cloud
- Azure
- Snowflake
용어 정리
| 용어 | 설명 |
|---|---|
Roadmap
참고 및 출처
데이터 파이프라인이란? | IBM
# 데이터 파이프라인이란 무엇인가요?
빅데이터의 세계, 3부: 데이터 파이프라인 구축 | JetBrains 블로그
데이터 파이프라인 개념 정리 | Product Analytics Playground
데이터파이프라인이란 무엇인가?
데이터 파이프라인 구축 - 이론
데이터 파이프라인 자세히 알아보기 | Seoyoung Hong
데이터 분석가가 직접 정의, 배포, 관리하는 뱅크샐러드 데이터 파이프라인
오토피디아 데이터 웨어하우스 구축하기
실시간 데이터 파이프라인 구축기 - Terraform으로 EKS를 띄워보자
더 나은 빅데이터 처리·분석을 위한 변화 (CDH의 Apache Hadoop 전환기)
The Architecture Of Serverless Data Systems
▲ 최신 데이터 인프라를 위한 새로운 아키텍처 2.0
데이터 엔지니어링이란
FMS(차량 관제 시스템) 데이터 파이프라인 구축기 1편. 스트리밍/배치 파이프라인 개발기
FMS(차량 관제 시스템) 데이터 파이프라인 구축기 2편. 신뢰성 높은 데이터를 위한 테스트 환경 구축기
제네시스 – 광고추천팀의 카프카 기반 스트리밍 데이터 플랫폼
Data platform 2022: Global expansion in petabytes
데이터 파이프라인 기본 원리와 원칙은 시간이 지나도 유효해야 한다(1/2)
데이터 파이프라인 기본 원리와 원칙은 시간이 지나도 유효해야 한다(2/2)
Citations:
[1] https://comp.utm.my/wp-content/uploads/filebase/academic_resource/SECPH%202023%202024.pdf
[2] https://kbig.kr/sites/default/files/pds/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0_%EC%9D%B8%EB%A0%A5%EC%96%91%EC%84%B1_%EC%BB%A4%EB%A6%AC%ED%81%98%EB%9F%BC(%EB%B0%B0%ED%8F%AC%EC%9A%A9).pdf
[3] https://wikidocs.net/179769
[4] https://news.hada.io/topic?id=18402
[5] https://digitalbourgeois.tistory.com/643
[6] https://product.kyobobook.co.kr/detail/S000210626592
[7] https://brunch.co.kr/@sparkplus/469
[8] https://dsti.school/applied-msc-in-data-engineering-ai/
[9] https://wonsjung.tistory.com/513
[10] https://news.hada.io/weekly/202453
[11] https://www.dongguk.edu/dandae/154
[12] https://www.snu.ac.kr/webdata/uploads/kor/file/2025/04/Graduate_Course_Summary_2024.pdf
[13] https://grant-documents.thevc.kr/256628_%5BTTA%5D+2023+%EC%8B%A0%EB%A2%B0%ED%95%A0+%EC%88%98+%EC%9E%88%EB%8A%94+%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EA%B0%9C%EB%B0%9C+%EC%95%88%EB%82%B4%EC%84%9C+-+%EC%9D%BC%EB%B0%98+%EB%B6%84%EC%95%BC.pdf
[14] https://www.slideshare.net/DONGMINLEE15/data-engineering-142510599
[15] https://www.snowflake.com/ko/blog/ai-data-predictions-2025/
[16] https://data-engineer-tech.tistory.com/69
[17] https://dataengineeringcommunity.substack.com/p/data-engineering-digest-april-2025
[18] https://wikidocs.net/222913
[19] https://brunch.co.kr/@@6uTE/58
[20] https://narangdesign.com/mail/jungwoo/202306/a1.html
[21] https://hmdev.vercel.app/2021%EB%85%84-Data-Engineering-%ED%8A%B8%EB%A0%8C%EB%93%9C
[22] https://www.reddit.com/r/dataengineering/comments/105bgbj/pursing_data_engineering_as_a_computer_science/
[23] https://www.sciencedirect.com/science/article/pii/S1877050923018380/pdf?md5=e444b8ccc4133f968c5c3b8b537b2e07&pid=1-s2.0-S1877050923018380-main.pdf
[24] https://www.pickl.ai/blog/data-science-for-computer-science-engineers/
[25] https://sunscrapers.com/blog/what-is-the-best-language-for-data-engineering/
[26] https://www.brainz.co.kr/tech-story/index/search_keyword/eNortjI0slJ6vWLHm-4Fr-eved09V8kaXDBlxgp1/search_field/eNortjIys1Jy1CsuTcpKTS7RdtQrSUwHksn5eSWpeSXFStZcMLkaCww~
[27] https://www.gknu.ac.kr/data/fileManageStorage/%EC%9C%B5%ED%95%A9%EC%A0%84%EA%B3%B5%EB%B3%84%20%EA%B5%90%EC%9C%A1%EA%B3%BC%EC%A0%95(25%EB%85%842%EC%9B%9424%EC%9D%BC).pdf
[28] https://jiniya.net/2025/04/code-complexity/
[29] https://www.yu.ac.kr/cse/grad/cse.do
[30] https://evcdc.koreatech.ac.kr/attach_file/52c9d5bf92554ee387caabf3514e46cf.pdf
[31] https://hrd4u.or.kr/portal/cmm/fms/FileDown.do?atchFileId=FILE_000000000600167&fileSn=1&bbsId=
[32] https://curieux.tistory.com/290
[33] https://www.cisp.or.kr/wp-content/uploads/2021/03/2.%EA%B3%B5%EA%B3%B5SW%EC%82%AC%EC%97%85-%EC%A0%9C%EC%95%88%EC%9A%94%EC%B2%AD%EC%84%9C-%EC%9E%91%EC%84%B1%EC%9D%84-%EC%9C%84%ED%95%9C-%EC%9A%94%EA%B5%AC%EC%82%AC%ED%95%AD-%EA%B0%80%EC%9D%B4%EB%93%9C-20210219.pdf
[34] https://assets.kpmg.com/content/dam/kpmg/kr/pdf/2020/kr-im-data-20200306.pdf
[35] https://jojaeguri.tistory.com/29
[36] https://www.cisp.or.kr/wp-content/uploads/2021/03/3.%EC%86%8C%ED%94%84%ED%8A%B8%EC%9B%A8%EC%96%B4%EC%82%AC%EC%97%85-%EC%9A%94%EA%B5%AC%EC%82%AC%ED%95%AD-%EB%B6%84%EC%84%9D%EC%A0%81%EC%9A%A9-%EA%B0%80%EC%9D%B4%EB%93%9C_20210219.pdf
[37] https://www.kiri.or.kr/report/downloadFile.do?docId=391039
[38] https://biz.katech.re.kr/bb/down.html?bid=1&fid=84&file=202412%2Fmv_17337910101710916730601.xlsx&force=1
[39] https://brunch.co.kr/@@1W5I/132
[40] https://kr.linkedin.com/posts/hyunsoo-ryan-lee_2025%EB%85%84-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%97%94%EC%A7%80%EB%8B%88%EC%96%B4%EB%A7%81%EC%97%90%EC%84%9C-%EB%9C%A8%EB%8A%94-5%EA%B0%80%EC%A7%80-%ED%8A%B8%EB%A0%8C%EB%93%9C-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%8A%94-%EC%9D%B4%EC%A0%9C-activity-7307700297072549888-PI7m
[41] https://kr.linkedin.com/posts/%EC%83%81%EA%B8%B8-%EB%B0%95-b6ab145a_the-future-of-data-engineering-dews-2025-activity-7275437377613938688-Hmos
[42] https://seo.goover.ai/report/202504/go-public-report-ko-c1513958-94fa-4661-88f9-5bedcac796d1-0-0.html
[43] https://brunch.co.kr/@@7pqA/177
[44] https://www.threads.com/@hyunsoo.it/post/DHUv_SZv8gN/%EB%8D%B0%EC%9D%B4%ED%84%B0%EC%9D%B4%EC%95%BC%EA%B8%B0-70-2025%EB%85%84-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%97%94%EC%A7%80%EB%8B%88%EC%96%B4%EB%A7%81%EC%97%90%EC%84%9C-%EB%9C%A8%EB%8A%94-5%EA%B0%80%EC%A7%80-%ED%8A%B8%EB%A0%8C%EB%93%9C-%EC%B4%88%EA%B1%B0%EB%8C%80-%EC%96%B8%EC%96%B4-%EB%AA%A8%EB%8D%B8llm%EC%9D%98-%EB%93%B1%EC%9E%A5-ai%EA%B0%80-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%B2%98%EB%A6%AC%EC%99%80-%EC%84%A4%EA%B3%84%EB%A5%BC-%EC%9E%90%EB%8F%99%ED%99%94%ED%95%98%EB%A9%B0-ra
[45] https://news.hada.io/topic?id=18402
[46] https://rivery.io/downloads/the-top-5-data-engineering-trends-heading-into-2025/
[47] https://brunch.co.kr/@hnote/161
[48] https://www.spri.kr/download/23630
[49] https://www.deloitte.com/kr/ko/services/tax/perspectives/customs-newsletter-2025-04-30.html
[50] https://fastcampus.co.kr/community/100383
[51] https://digitalbourgeois.tistory.com/643
[52] https://blogs.nvidia.co.kr/blog/industry-ai-predictions-2025/
[53] https://velog.io/@dlawlrb/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%97%94%EC%A7%80%EB%8B%88%EC%96%B4-%EB%A1%9C%EB%93%9C%EB%A7%B5%EC%9D%84-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
[54] https://www.keei.re.kr/boardDownload.es?bid=0022&list_no=123436&seq=1
[55] https://velog.io/@davidmin/Natural-Language-Processing-%EB%AA%A8%EB%93%88-%ED%95%99%EC%8A%B5-%EB%B8%94%EB%A1%9C%EA%B7%B8-%EA%B3%BC%EC%A0%9C
[56] https://discuss.pytorch.kr/t/llm-synthetic-data-survey/4764
[57] https://eair.tistory.com/46
[58] https://www.ibm.com/kr-ko/think/topics/transfer-learning
[59] https://vulter3653.tistory.com/33
[60] https://velog.io/@skh951225/%EB%AC%B4%EC%97%87%EC%9D%84-%EC%96%B4%EB%94%94%EC%84%9C-%EA%B3%B5%EB%B6%80%ED%96%88%EB%8A%94%EC%A7%802023.03
[61] https://fastcampus.co.kr/data_online_udacityawsengineering
[62] https://data-analysis-hagrid.tistory.com/71
[63] https://tech.kakao.com/2022/04/19/2022-kakao-tech-internship-data/
[64] https://aws.amazon.com/ko/certification/certified-data-engineer-associate/
[65] https://www.skelterlabs.com/blog/rag-vs-finetuning
Perplexity 로부터의 답변: pplx.ai/share
데이터 엔지니어링 (Data Engineering) 은 데이터의 수집, 처리, 저장, 분석을 위한 시스템을 설계하고 구축하는 분야로, 현대의 데이터 중심 비즈니스에서 핵심적인 역할을 수행합니다. 이 분야는 컴퓨터 과학, 소프트웨어 엔지니어링, 데이터베이스, 클라우드 인프라 등을 포괄하며, 데이터 사이언스와 인공지능의 기반을 제공합니다.
1. 주제의 분류 적절성
데이터 엔지니어링은 “Computer Science and Engineering” 분야에 속하는 것이 적절합니다. 이는 데이터 시스템의 설계, 알고리즘, 분산 처리, 데이터베이스, 네트워크, 클라우드 인프라 등 컴퓨터 과학과 소프트웨어 공학의 핵심 요소들을 포함하기 때문입니다.
2. 요약 설명 (200 자 내외)
데이터 엔지니어링은 대규모 데이터를 수집, 처리, 저장, 분석하는 시스템을 설계하고 구축하는 분야로, 데이터 기반 의사결정과 인공지능의 기반을 제공합니다.
3. 전체 개요 (200 자 내외)
데이터 엔지니어링은 데이터의 수집부터 저장, 처리, 분석까지의 전 과정을 담당하며, 안정적이고 확장 가능한 데이터 파이프라인과 인프라를 구축하여 데이터 사이언스, 머신러닝, 비즈니스 인텔리전스 등의 기반을 마련합니다.
4. 핵심 개념
데이터 파이프라인 (Data Pipeline): 데이터의 수집, 처리, 저장, 분석 과정을 자동화한 흐름
ETL/ELT: Extract-Transform-Load 또는 Extract-Load-Transform 방식의 데이터 처리
데이터 웨어하우스 (Data Warehouse): 분석을 위한 구조화된 데이터 저장소
데이터 레이크 (Data Lake): 구조화되지 않은 원시 데이터를 저장하는 저장소
워크플로우 오케스트레이션 (Workflow Orchestration): 데이터 처리 작업의 순서와 의존성을 관리하는 시스템
데이터 품질 (Data Quality): 정확성, 완전성, 일관성, 적시성 등의 데이터 특성 (Databricks)
5. 주제와 관련하여 조사할 내용
목적 및 필요성
데이터 기반 의사결정 지원: 정확하고 신뢰할 수 있는 데이터를 제공하여 비즈니스 의사결정을 지원합니다.
데이터 사이언스 및 머신러닝의 기반 마련: 분석과 모델링을 위한 고품질의 데이터를 제공합니다.
실시간 데이터 처리 및 분석: 스트리밍 데이터를 실시간으로 처리하여 즉각적인 인사이트를 도출합니다.
주요 기능 및 역할
데이터 수집 및 통합: 다양한 소스에서 데이터를 수집하고 통합합니다.
데이터 처리 및 변환: 데이터를 정제하고 변환하여 분석에 적합한 형태로 만듭니다.
데이터 저장 및 관리: 데이터를 효율적으로 저장하고 관리합니다.
데이터 파이프라인 구축 및 유지보수: 데이터 흐름을 자동화하고 안정적으로 운영합니다.
특징
확장성 (Scalability): 대용량 데이터를 효율적으로 처리할 수 있는 구조
유연성 (Flexibility): 다양한 데이터 소스와 포맷을 지원하는 구조
신뢰성 (Reliability): 데이터 처리의 정확성과 일관성을 보장하는 구조
핵심 원칙
데이터 품질 유지: 정확하고 일관된 데이터를 유지하는 것이 중요합니다.
자동화 및 오케스트레이션: 데이터 처리 과정을 자동화하여 효율성을 높입니다.
보안 및 개인정보 보호: 데이터의 보안과 개인정보 보호를 철저히 관리합니다.
주요 원리 및 작동 원리
데이터 엔지니어링의 주요 원리는 데이터를 수집, 처리, 저장, 분석하는 전 과정을 자동화하고 최적화하는 것입니다. 이를 위해 다양한 도구와 기술이 활용되며, 데이터 파이프라인을 통해 데이터 흐름을 관리합니다.
구조 및 아키텍처
데이터 엔지니어링의 구조는 일반적으로 다음과 같은 계층으로 구성됩니다:
데이터 수집 계층: 다양한 소스에서 데이터를 수집합니다.
데이터 처리 계층: 수집된 데이터를 정제하고 변환합니다.
데이터 저장 계층: 처리된 데이터를 저장합니다.
데이터 분석 계층: 저장된 데이터를 분석하여 인사이트를 도출합니다.
구성 요소
데이터 수집 도구: Apache Kafka, Flume 등
데이터 처리 도구: Apache Spark, Beam 등
데이터 저장소: Hadoop HDFS, Amazon S3 등
데이터 웨어하우스: Amazon Redshift, Google BigQuery 등
오케스트레이션 도구: Apache Airflow, Luigi 등
장점과 단점
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | 확장성 | 대용량 데이터를 효율적으로 처리할 수 있습니다. |
| 유연성 | 다양한 데이터 소스와 포맷을 지원합니다. | |
| 자동화 | 데이터 처리 과정을 자동화하여 효율성을 높입니다. | |
| ⚠ 단점 | 복잡성 | 시스템이 복잡하여 구축과 유지보수가 어렵습니다. |
| 비용 | 인프라 구축과 운영에 비용이 많이 들 수 있습니다. |
도전 과제
데이터 품질 관리: 정확하고 일관된 데이터를 유지하는 것이 어렵습니다.
실시간 데이터 처리: 스트리밍 데이터를 실시간으로 처리하는 데 기술적 어려움이 있습니다.
보안 및 개인정보 보호: 데이터의 보안과 개인정보 보호를 철저히 관리해야 합니다.
분류에 따른 종류 및 유형
| 분류 | 유형 | 설명 |
|---|---|---|
| 데이터 저장소 | 데이터 웨어하우스 | 분석을 위한 구조화된 데이터 저장소 |
| 데이터 레이크 | 구조화되지 않은 원시 데이터를 저장하는 저장소 | |
| 데이터 처리 방식 | 배치 처리 | 일정량의 데이터를 모아서 한 번에 처리하는 방식 |
| 스트리밍 처리 | 실시간으로 데이터를 처리하는 방식 | |
| 오케스트레이션 도구 | Apache Airflow | 워크플로우를 관리하는 오픈소스 도구 |
| Luigi | Python 기반의 워크플로우 관리 도구 |
실무 적용 예시
| 분야 | 적용 사례 | 설명 |
|---|---|---|
| 전자상거래 | 추천 시스템 | 고객의 행동 데이터를 분석하여 개인화된 상품을 추천합니다. |
| 금융 | 이상 거래 탐지 | 거래 데이터를 실시간으로 분석하여 이상 거래를 탐지합니다. |
| 제조 | 예측 유지보수 | 센서 데이터를 분석하여 장비의 고장을 예측하고 유지보수를 계획합니다. |
활용 사례
시나리오: 전자상거래 기업에서 고객의 행동 데이터를 분석하여 개인화된 추천 시스템을 구축합니다.
과정:
웹 로그, 구매 이력 등의 데이터를 수집합니다.
수집된 데이터를 정제하고 변환합니다.
데이터를 저장소에 저장합니다.
저장된 데이터를 분석하여 고객의 선호도를 파악합니다.
분석 결과를 바탕으로 개인화된 상품을 추천합니다.
다이어그램:
| |
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 항목 | 고려사항 | 설명 |
|---|---|---|
| 데이터 품질 | 정합성 확보 | 정확하고 일관된 데이터를 유지해야 합니다. |
| 인프라 설계 | 확장성과 탄력성 확보 | 수요 변화에 대응할 수 있도록 클라우드 기반 인프라 및 스케일 아웃 구조 설계가 필요합니다. |
| 배포 전략 | 지속적 통합/배포 (CI/CD) 적용 | 데이터 파이프라인의 코드, 설정, 테스트를 자동화하여 신속하고 안정적인 배포를 지원합니다. |
| 데이터 보안 | 권한 관리 및 암호화 적용 | 민감 데이터는 암호화하고, 접근 권한은 최소한으로 설정해야 합니다. |
| 모니터링 및 로깅 | 실시간 로그 및 오류 감지 | 파이프라인 장애나 성능 저하를 조기 발견할 수 있도록 실시간 모니터링 시스템을 구축합니다. |
| 데이터 거버넌스 | 메타데이터 관리와 추적성 보장 | 데이터의 출처, 흐름, 변경 이력을 관리하여 감사 및 품질 관리에 활용합니다. |
⚙ 성능을 최적화하기 위한 고려사항 및 주의할 점
| 항목 | 고려사항 | 설명 |
|---|---|---|
| 처리 방식 선택 | 배치 vs 스트리밍 | 데이터 성격과 실시간성 요구에 따라 적절한 처리 방식을 선택합니다. |
| 데이터 파티셔닝 | 분산 처리 성능 향상 | 시간, 지역, 사용자 ID 등으로 데이터를 파티셔닝하여 병렬 처리 성능을 향상시킵니다. |
| 스토리지 포맷 | 효율적인 I/O 처리 | Parquet, ORC 등 컬럼 기반 포맷은 분석과 압축에 효율적입니다. |
| 캐싱 전략 | 반복 쿼리 최적화 | 반복되는 데이터 접근은 Redis, Memcached 등의 캐싱 계층을 도입하여 성능을 향상시킵니다. |
| 리소스 자동 조절 | 오토스케일링 설정 | Kubernetes 나 클라우드 플랫폼의 오토스케일링 기능으로 처리량에 따라 자원을 자동 조절합니다. |
📈 2025 년 기준 최신 동향
| 주제 | 항목 | 설명 |
|---|---|---|
| 실시간 처리 | Lakehouse 기반 스트리밍 | Delta Lake, Apache Hudi 등에서 실시간 분석 지원 기능 강화 |
| 자동화 | DataOps | 파이프라인 개발부터 테스트, 배포, 모니터링까지의 전체 흐름 자동화 |
| 클라우드 네이티브 | Serverless 파이프라인 | AWS Glue, Google Cloud Dataflow 등 무서버 기반 데이터 처리 확산 |
| 데이터 보안 | Data Clean Rooms | 기업 간 데이터 공유 시 개인정보 보호를 위한 격리된 분석 환경 |
| AI 통합 | AI 기반 품질 진단 | 머신러닝을 통한 자동 데이터 품질 점검 및 이상 탐지 강화 |
🔍 주제와 관련하여 주목할 내용
| 주제 | 항목 | 설명 |
|---|---|---|
| 데이터 파이프라인 | Declarative Pipeline | 코드가 아닌 선언형 구성으로 파이프라인을 정의하는 방식 (예: dbt) |
| 데이터 품질 | Data Contracts | 데이터 생산자와 소비자 간 품질 보장을 위한 계약 기반 개발 방식 |
| 오케스트레이션 | Event-Driven Pipeline | 일정 기반이 아닌 이벤트 발생에 따라 작동하는 동적 워크플로우 구조 |
| 스토리지 | Lakehouse 아키텍처 | 데이터 레이크와 웨어하우스를 통합한 최신 저장 아키텍처 모델 |
| 데이터 접근 | Unified Query Layer | 다양한 저장소를 통합 쿼리할 수 있는 데이터 가상화 기술 (예: Starburst, Presto) |
🔮 앞으로의 전망
| 주제 | 항목 | 설명 |
|---|---|---|
| 데이터 엔지니어링 | 자동화 가속 | 코드 작성 최소화, 구성 기반 파이프라인이 대세로 자리잡음 |
| 인프라 운영 | 하이브리드/멀티 클라우드 확산 | 이기종 환경을 아우르는 데이터 처리 전략의 중요성 증가 |
| 데이터 보안 | AI 기반 보안 자동화 | 비정상 접근 및 이상 데이터 흐름을 탐지하는 AI 기반 보안 솔루션 확대 |
| 협업 | Cross-functional 팀 구성 | 데이터 엔지니어, 사이언티스트, 분석가가 함께 일하는 구조 확대 |
| 개발 문화 | GitOps + DataOps | 코드와 인프라, 데이터까지 Git 중심으로 관리하는 문화 정착 |
📚 학습해야 할 하위 주제 분류
| 카테고리 | 주제 | 간략 설명 |
|---|---|---|
| 데이터 모델링 | 스타 스키마, 정규화 | 분석 최적화 혹은 저장 최적화를 위한 데이터 구조 설계 |
| 처리 프레임워크 | Apache Spark, Flink | 대규모 데이터 처리를 위한 분산 처리 엔진 |
| 스토리지 기술 | Delta Lake, Iceberg | ACID 트랜잭션이 가능한 현대적 데이터 레이크 스토리지 |
| 오케스트레이션 | Airflow, Dagster | 워크플로우 자동화 및 스케줄링 도구 |
| 실시간 처리 | Kafka, Flink, Kinesis | 스트리밍 데이터 처리 기술 및 시스템 설계 |
📘 관련 분야 및 학습 주제
| 카테고리 | 주제 | 간략 설명 |
|---|---|---|
| DevOps | CI/CD for Data Pipelines | 데이터 엔지니어링 파이프라인의 테스트 및 배포 자동화 |
| 보안 | Data Tokenization & Masking | 민감 데이터 보호를 위한 처리 기법 |
| 클라우드 아키텍처 | Cloud-native Data Stack | 클라우드에 최적화된 데이터 엔지니어링 구성 요소 설계 |
| MLOps | 피처 스토어 및 데이터 버전 관리 | 모델 학습 및 재현성을 위한 데이터 관리 체계 |
| Observability | 데이터 관측성 시스템 | 로그, 메트릭, 트레이싱을 통한 데이터 흐름 감시 및 진단 체계 |
용어 정리
| 용어 | 설명 |
|---|---|
| ETL / ELT | 데이터 추출 (Extract), 변환 (Transform), 적재 (Load) 의 흐름 또는 순서를 의미하는 데이터 처리 방식 |
| 데이터 웨어하우스 | 분석 목적으로 최적화된 구조화된 데이터 저장소 (예: Snowflake, BigQuery) |
| 데이터 레이크 | 정형/비정형 데이터를 원시 상태로 저장하는 대규모 저장소 |
| 오케스트레이션 도구 | 데이터 워크플로우를 자동화 및 스케줄링하는 도구 (예: Airflow, Dagster) |
| Lakehouse | 데이터 웨어하우스와 데이터 레이크의 장점을 결합한 통합형 아키텍처 |
| DataOps | 데이터 파이프라인의 개발, 배포, 테스트, 모니터링을 자동화하고 최적화하는 접근 방식 |
참고 및 출처
필요하다면 각 구성 요소에 대한 시각적 다이어그램, 코드 예제, 아키텍처 상세 설명도 단계별로 제공해드릴 수 있습니다. 다음으로 어떤 내용을 더 알고 싶으신가요?
데이터 엔지니어링의 핵심 구성 요소에 대한 시각적 다이어그램, 코드 예제, 아키텍처 상세 설명을 아래와 같이 제공합니다.
📊 데이터 엔지니어링 아키텍처 다이어그램
데이터 엔지니어링 아키텍처는 일반적으로 다음과 같은 구성 요소로 이루어집니다:
데이터 소스 (Data Sources): 내부 데이터베이스, API, 로그 파일, IoT 센서 등 다양한 형태의 원천 데이터를 제공합니다.
데이터 수집 (Data Ingestion): Apache Kafka, AWS Kinesis, Google Pub/Sub 등을 사용하여 데이터를 실시간 또는 배치 방식으로 수집합니다.
데이터 처리 (Data Processing): Apache Spark, Flink, Beam 등을 활용하여 데이터를 변환, 정제, 집계합니다.
데이터 저장 (Data Storage): 데이터 웨어하우스 (Snowflake, BigQuery) 나 데이터 레이크 (S3, HDFS) 에 데이터를 저장합니다.
데이터 오케스트레이션 (Data Orchestration): Apache Airflow, Prefect, Dagster 등을 사용하여 워크플로우를 관리합니다.
데이터 소비 (Data Consumption): BI 도구 (Tableau, Looker) 나 머신러닝 모델을 통해 데이터를 분석하고 시각화합니다.(GeeksforGeeks)
이러한 구성 요소들은 데이터의 흐름을 원활하게 관리하고, 데이터 품질을 유지하며, 실시간 분석 및 예측 모델링을 가능하게 합니다.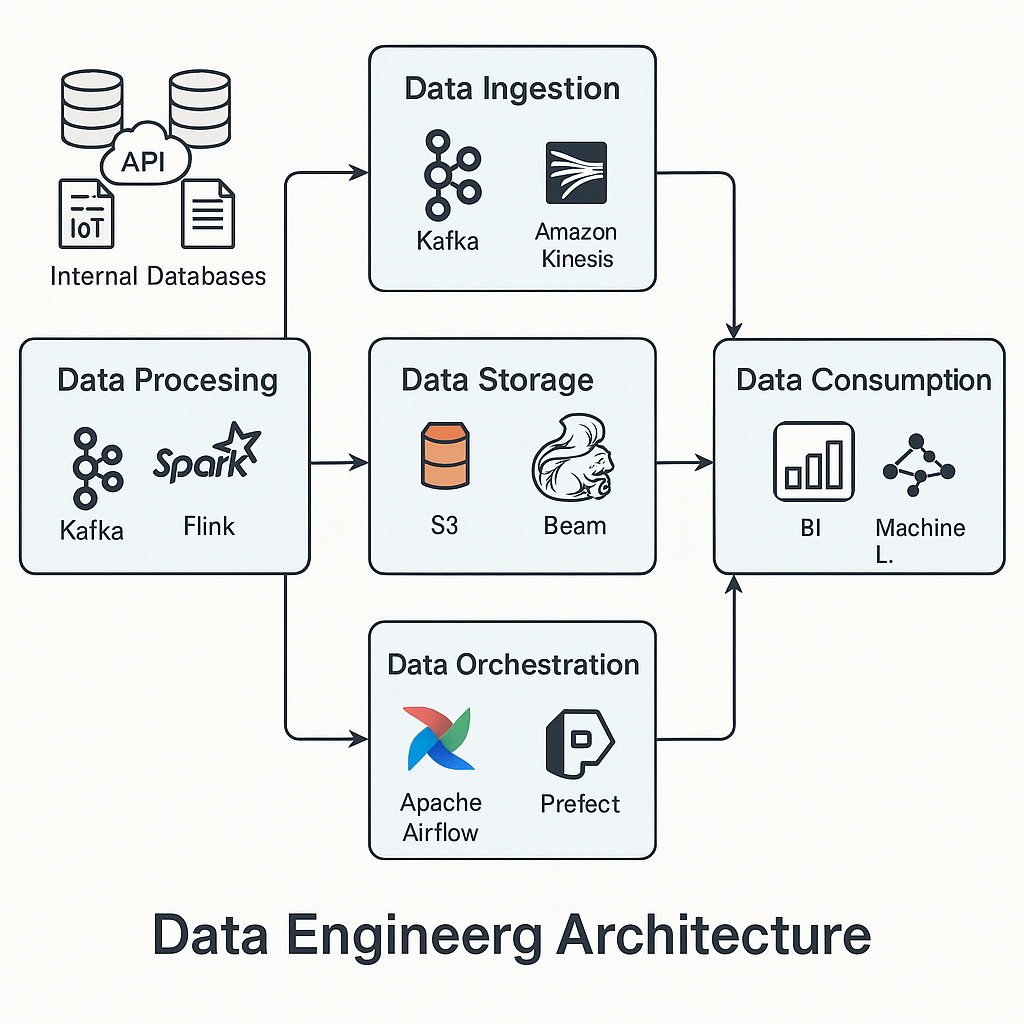
🧪 ETL 파이프라인 코드 예제 (Python 기반)
다음은 Python 을 사용하여 간단한 ETL(Extract, Transform, Load) 파이프라인을 구현한 예제입니다:
| |
이 코드는 CSV 파일에서 데이터를 읽어와 특정 조건에 따라 변환한 후, PostgreSQL 데이터베이스에 저장합니다.
🧱 아키텍처 상세 설명
데이터 엔지니어링 아키텍처는 다양한 구성 요소로 이루어져 있으며, 각 구성 요소는 특정한 역할을 수행합니다:
데이터 소스: 내부 시스템 (ERP, CRM), 외부 API, 로그 파일 등 다양한 형태의 데이터를 제공합니다.
데이터 수집: Apache Kafka, AWS Kinesis 등을 사용하여 데이터를 실시간으로 수집하거나, 배치 방식으로 데이터를 가져옵니다.
데이터 처리: Apache Spark, Flink 등을 활용하여 데이터를 변환, 정제, 집계합니다.
데이터 저장: 데이터 웨어하우스 (Snowflake, BigQuery) 나 데이터 레이크 (S3, HDFS) 에 데이터를 저장하여 분석 및 머신러닝 모델링에 활용합니다.
데이터 오케스트레이션: Apache Airflow, Prefect 등을 사용하여 데이터 파이프라인의 워크플로우를 관리하고, 스케줄링합니다.
데이터 소비: BI 도구 (Tableau, Looker) 나 머신러닝 모델을 통해 데이터를 분석하고 시각화하여 비즈니스 인사이트를 도출합니다.
이러한 아키텍처는 데이터의 수집부터 분석까지의 전 과정을 체계적으로 관리하며, 데이터 기반 의사결정을 지원합니다.
📚 참고 자료
추가적으로, 특정 도구나 프레임워크에 대한 상세한 정보나 구현 방법에 대해 궁금하신 점이 있으시면 언제든지 문의해 주세요.