ER(Entity-Relationship) 모델링
1단계: 기본 분석 및 검증
주제 유형 식별
- ER 모델링(ER Modeling)은 “이론/개념형(A형)”에 해당하며, 추상적 데이터 구조와 관계를 수학적으로 모델링하는 이론 및 개념 중심 주제임.[1][2][3]
복잡도 평가
- 실무 적용 및 혁신적 트렌드까지 다루기 위해 “복잡도 Level 3(고급)”로 접근이 타당함.
대표 태그 생성
- DataModeling, ERDiagram, EntityRelationship, ConceptualDesign, Database
분류 체계 검증 및 개선 제안
- 5번 분류(“Data & Database Systems > Data Fundamentals > Data Modeling > Conceptual Modeling”)는 6번 분류 구조 내 “Data Modeling > Conceptual Modeling”에 정확히 대응되므로 논리적으로 타당하며, 탐색 관점에서도 일관성과 적합성이 높음.
- 다만, 실무적 검색성과 실습 관점에서 “ERD(ER Diagram), RelationalMapping” 등 교차 태그 부여 개선 제안.
- 빅데이터, AI-ML 파이프라인 등 신규 데이터 설계 패러다임 영역과의 연결항목(예: 데이터 거버넌스, 멀티모델 DB 모듈 등) 추천.
핵심 요약
“ER 모델링(Entity-Relationship Modeling)은 현실 세계의 정보 구조를 엔티티와 관계 개념을 활용해 체계적으로 추상화하여, 데이터베이스 설계의 논리적/개념적 기반을 제공하는 이론적 모델이자 실무적 프레임워크다”.[4][5][1]
전체 개요
ER 모델링은 데이터베이스 시스템, 소프트웨어 설계, 데이터 아키텍처에서 핵심적 역할을 하며, 현실 세계의 객체(엔티티)와 그들의 상호관계(관계)를 구조적으로 표현한다. 기본 요소(엔티티, 관계, 속성)와 제약조건(식별자, 카디널리티 등)을 조합하여 개념적 다이어그램(ER 다이어그램, ERD) 형태로 정형화하며, 이를 기반으로 논리적/물리적 데이터 모델로 변환한다. 최근 AI 기반 자동화, 멀티클라우드, 다양한 NoSQL/멀티모델 DB 확장 등 현대 데이터 시스템 요구에도 빠르게 적응하고 있으며, 실무에서는 데이터 품질, 데이터 거버넌스, 유연한 확장성에 더욱 강조점을 둔다. ER 모델링은 신규 정보시스템 기획, 시스템 통합, 데이터 마이그레이션 등 다양한 시나리오에서 데이터 구조의 품질과 변경 용이성, 데이터 무결성 보장을 위한 핵심 도구이자 지식 체계로 자리매김 한다.[6][7][8][5][4]
참고자료
- [Entity-relationship model - Wikipedia][1]
- [E-R(Entity-Relationship) Model 이란?][4]
- [DBMS 예제를 사용한 엔터티 관계(ER) 다이어그램 모델][9]
- [ER 다이어그램 ( 엔티티-관계 다이어그램) 이란?][8]
- [The History and Future of ER Diagrams: How AI is …][6]
2단계: 개념 체계화 및 검증
핵심 개념 정리
엔티티(Entity, 개체): 현실 세계에서 식별할 수 있는 객체나 개념을 의미. 예시로는 사용자, 상품, 주문 등 데이터로 관리할 필요가 있는 모든 것을 지칭한다. 엔티티는 속성을 지니며, 고유 식별자를 가진다. 정규(Entity), 약(Entity, Weak Entity) 등으로 분류할 수 있다.[1][2][3]
속성(Attribute, 속성): 엔티티의 특별한 특성 또는 특질을 나타낸다. 예를 들어, 학생 엔티티의 이름, 학번, 전공 등이 속성이다. 단일(Simple), 복합(Composite), 유도(Derived), 다중(Multi-valued) 등 다양한 유형이 존재한다.[3][1]
관계(Relationship, 관계): 두 개 이상의 엔티티 간에 존재하는 의미적 연관성을 나타낸다. 예시는 학생과 강의, 고객과 주문 등이 있다. 1:1, 1:N, N:M 관계 타입과 필수(Total), 선택(Partial) 참여 등이 주요 특징이다.[4][1][3]
식별자(Identifier, Key): 엔티티의 각 인스턴스를 고유하게 식별하는 속성이나 속성의 집합. Primary Key(기본 키), Foreign Key(외래 키) 등 식별자 체계를 설정하여 물리적인 데이터베이스 설계로 이어진다.[5][6]
서브타입(Subtype)과 슈퍼타입(Supertype): 엔티티 간 상속/포괄 관계. 예를 들어, 직원(Employee)과 프로그래머(Programmer)처럼 슈퍼타입-서브타입 계층을 가진다(OOP의 상속 개념과 유사).[1]
상호관계 구조화(테이블 예시)
| 개념 | 정의 | 실 예시 |
|---|---|---|
| 엔티티 | 데이터로 관리되는 독립 객체·개념 | 고객, 주문, 강좌 등 |
| 속성 | 엔티티의 성질·특성 | 이름, 나이, 이메일 등 |
| 관계 | 엔티티들 간 의미적 연결 | 고객-주문(1:N), 학생-강좌(N:M) |
| 식별자 | 각 엔티티 인스턴스를 구별하는 유일 속성·속성 집합 | 고객ID(Primary Key), 주문ID, 학생번호 |
| 서브/슈퍼타입 | 상속(포괄), 특수화된 엔티티 구조 | 직원-프로그램(슈퍼/서브타입) |
실무 연관성 분석
초기 요구분석에서 명확한 엔티티-관계 도출은 실무 시스템의 명확한 데이터 구조 및 업무 흐름 정의의 근간이 된다. 요구사항 단계에서의 ER 다이어그램(ERD) 활용은 데이터 품질, 설계 일관성, 변경 용이성을 보장한다.[7][6]
논리-물리 모델 전환의 연결고리: ER 모델은 추상화된 개념에서 실제 데이터베이스 테이블(관계형 데이터베이스뿐만 아니라 NoSQL 구조까지)로의 전환 기준을 제공, 실무 설계와 구현단에서의 오해 및 오류를 최소화한다.[5]
데이터 무결성, 트랜잭션 설계, 향후 확장성: 식별자와 관계 구조의 명확한 정의는 트랜잭션 무결성, 응용 기능 개발, 데이터 파이프라인 및 보고 환경의 변경‧확장에 대한 적합성과 유연성을 높인다.[6][8][5]
실무 프로세스 예시: 요구사항 도출→엔티티/속성/관계 식별→ERD 설계→정규화 및 제약조건 설계→테이블 및 인덱스 생성→구현 및 테스트.[7][6][5]
이상으로, ER 모델링의 본질적 개념 및 실무 적용성, 그리고 각 핵심 구조의 상호관계와 실무 흐름상 활용 방안을 체계적으로 정리하였다.
다음 단계에서는 기초 개념 및 핵심 원리(Phase 1~2)와, 특성 분석(Phase 3), 그리고 유형별 실무+코드 예제(Phase 5)를 단계별로 진행하여 더욱 구체화할 예정이다.### 2단계: 개념 체계화 및 검증
핵심 개념 정리
- 엔티티(개체, Entity): 현실 세계의 독립적 객체(사람, 사물, 개념 등)로 데이터로 관리해야 하는 대상이며, 속성을 가짐.[2][3][1]
- 속성(Attribute, 속성): 엔티티가 가지는 성질 또는 특성(예: 학생의 학번, 이름, 전공 등). 단일, 복합, 다중, 유도 속성 등 여러 유형이 있음.[3][1]
- 관계(Relationship, 관계): 엔티티 간 의미 있는 연관성을 표현하며, 1:1, 1:N, N:M 구조로 표현됨.[6][1][5]
- 식별자(Identifier, Key): 엔티티 인스턴스를 고유하게 식별할 수 있도록 하는 속성(Primary Key, Foreign Key 등).[5][6]
- 서브타입/슈퍼타입(Subtype/Supertype): 엔티티 간 계층 구조로, 일반-특수 개념 계승 구조(직원–프로그램 개발자 등).[1]
상호관계 구조 설명
- 엔티티와 속성, 관계, 식별자는 서로 긴밀하게 연결되어 데이터베이스의 기본 구조를 형성한다.
- 실무에서는 ERD(ER Diagram)를 활용해 이러한 구조를 시각적으로 설계해 협업과 유지보수를 용이하게 함.[6][5]
실무 연관성 분석
- 요구 사항 분석 단계에서 엔티티와 속성, 관계의 적절한 도출은 데이터베이스 구축의 품질과 비즈니스 로직 정확성에 직접적 영향을 준다.[7][5][6]
- ER 모델 기반 설계는 논리적·물리적 데이터베이스 구현과정, 그리고 데이터 마이그레이션/확장성, 품질 관리까지 표준화된 가이드라인을 제공한다.[5]
- 식별자와 관계 정의는 데이터 무결성, 트랜잭션 안정성 및 확장성 등 엔터프라이즈 시스템 운영의 기반이 된다.[8][6][5]
Phase 3: 특성 분석 및 평가
주요 장점 및 이점
| 장점 | 상세 설명 | 기술 근거 | 적용 상황 | 실무적 가치 |
|---|---|---|---|---|
| 데이터 구조의 명확성 | 현실 세계의 객체(엔티티)와 관계 구조를 구체적으로 시각화 | ER 다이어그램 기반 설계 | 신규 시스템 설계, 요구사항 분석 단계 | 데이터 중복/누락 방지, 설계 오류 감소 |
| 데이터 무결성 보장 | 식별자, 제약조건 등 논리 구조에서 무결성 규칙을 명확하게 적용 | 키(Key), 카디널리티, 도메인 제약 | 데이터베이스 구현·운영/통합, 품질 관리 | 데이터 일관성 및 업무 프로세스 신뢰성 강화 |
| 설계 협업 및 문서화 | 시각적 도구로 다양한 이해관계자와 명확하게 소통 | 다이어그램/모델 표준 | 외주 관리, 팀 내외부 협업, 요구사항 변경 대응 | 커뮤니케이션 비용 절감·신속한 피드백 가능 |
| 표준화·재사용 용이성 | 표준화된 모델 작성 및 재사용 가능 | ER 모델 표준, 도식화 도구 지원 | 데이터 거버넌스, 대규모 프로젝트, 유지보수 | 설계 재작업/데이터 이관 비용 최소화 |
| 확장성과 유연성 | 논리/물리모델 변환 용이, 데이터베이스 교체 및 구조 확장 적합 | 관계형 외 NoSQL, 멀티모델 DB도 적용 가능 | 신규 요구 반영, 멀티시스템 통합/마이그레이션 | 구조 확장·데이터 마이그레이션 효율성 극대화 |
단점 및 제약사항
| 단점 | 상세 설명 | 원인 | 실무에서 발생되는 문제 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 복잡도 증가 | 대규모/복잡 도메인에서 모델이 방대해짐 | 엔티티, 관계·제약조건 구조가 많을 때 | 설계 및 유지보수 난이도 상승 | 도메인 분할, 서브모델 분리 | UML 클래스 다이어그램 |
| 비정형 데이터 한계 | 문서·이미지 등 정형 밖의 데이터 모델링 곤란 | 관계형 중심 구조 | NoSQL 및 빅데이터 모델링 범용성 부족 | 논리계층에서 보완 | 멀티모델(Multi-model) DB |
| 학습 곡선 | 개념적 구조·제약조건 복잡성을 이해해야 함 | 추상 레벨이 높고 문법 다양 | 실무자 학습 시간, 설계 오해 | 표준화 교육, 사례 공유 | ERD 생성 자동화 도구 |
트레이드오프 관계 분석
- 표현력 vs 단순성: 모델의 완성도와 실무 적용 용이성 간 균형 필요.[1][4]
- 정규화 vs 성능: 과도한 정규화는 데이터 접근 성능 저하 가능.[5]
- 확장성 vs 안정성: 구조의 유연성 확보는 무결성 트레이드오프 발생 가능.
적용 적합성 평가
- 적합: 전통적 관계형 데이터베이스, POS/ERP/CMS 등 업무 프로세스 기반 시스템, 데이터 품질 및 구조 무결성이 중요한 환경, 데이터 통합·마이그레이션이 많은 대규모 기업 환경.[3][4][1]
- 부적합: 실시간 처리, 비정형 데이터 기반 빅데이터/AI 시스템 또는 다빈도 스키마 변경이 필요한 환경.
Phase 4: 구현 방법 및 분류
구현 방법 및 기법 (개념→논리→물리)
- 업무 요구사항 도출
- 엔티티/속성/관계/식별자 추출
- ER 다이어그램(ERD) 작성
- 정규화 수행 및 제약조건 설계
- 논리 데이터 모델(릴레이션 테이블) 변환
- 물리적 데이터베이스 구조 생성 및 구현
유형별 분류 체계
| 유형 | 기준 | 특징 및 적용 예시 |
|---|---|---|
| 강한 엔티티 | 자체 식별자 보유 | 회원, 상품, 주문 등 |
| 약한 엔티티 | 식별자 외래키 의존 | 주문상세, 로그 등 |
| 1:1/1:N/다대다 | 관계 유형 | 고객-주문(1:N), 학생-강좌(N:M) 등 |
| 서브/슈퍼타입 | 포괄/특수화 구조 | 직원-개발자(상속관계) |
도구 및 라이브러리 생태계
- ERD Tool: MySQL Workbench, ERwin, Visual Paradigm 등
- DevOps 통합: ERD 자동화 스크립트, 데이터 이관 툴 연계 활용
표준 및 규격 준수사항
- ERD 표기법: Chen, Crow’s Foot 등
- DBMS간 호환성: 기본 표준 준수 및 DBMS-specific 변환 고려
다음 단계(실습 예제 및 도입 사례, 실무 운영 및 최신 트렌드)는 표준 구조에 따라 구체적으로 이어 설명할 예정.
Phase 3: 특성 분석 및 평가
주요 장점 및 이점
| 장점 | 상세 설명 | 기술 근거 | 적용 상황 | 실무적 가치 |
|---|---|---|---|---|
| 데이터 구조 시각화 | 현실 세계 객체와 관계 구조를 명확하게 시각화 | ER 다이어그램 표준 | 시스템 설계, 요구분석 | 설계 오류 감소, 협업 효율화 |
| 무결성 및 표준화 | 명확한 제약조건·식별자 관리로 데이터 일관성 확보 | 키/제약조건 중심 설계 | 데이터 통합 및 이관, 품질 검사 | 데이터 오류 최소화, 신뢰성 개선 |
| 설계 협업 및 문서화 | 요구사항 분석 단계부터 시각적 언어로 협업 가능 | 표준화된 모델/다이어그램 도구 | 팀 간 협업, 외주, 기술이전 | 커뮤니케이션 비용 절감, 변경대응 용이 |
| 확장성과 재사용성 | 데이터 구조 변경, 신규 업무 반영 용이 | 논리·물리 모델 분리 및 계층화 구조 | 신규 기능 개발, 시스템 확장 | 유지보수 비용 감소, 미래 호환성 강화 |
단점 및 제약사항
| 단점 | 상세 설명 | 원인 | 실무에서 발생 문제 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 모델 복잡성 증가 | 대규모 업무나 다양한 객체가 많을 때 구조가 방대해짐 | 엔티티 수와 관계 복잡도 | 설계/유지보수 난이도 | 서브모델 분리, 도메인 분할 | UML 클래스, JSON 모델 |
| 비정형 데이터 한계 | 이미지/문서 등 비정형 데이터 모델링 제한 | 관계형 중심, 정형 데이터 지향 | NoSQL 적용의 난점 | 논리모델로 우회, 통합 플랫폼 | 멀티모델DB, DocumentDB |
| 학습 곡선 | 추상적 개념, 다양한 표기법 | 복잡한 추상구조, 새 도구 표준 탑재 | 신입 실무자 혼동 | 사례 위주 교육, 자동화 툴 | ERD 자동생성 도구 |
트레이드오프 및 적합성
- 표현력 vs 단순성, 정규화 vs 성능, 유연성 vs 무결성 측면에서 실무 적용 시 균형 조절이 필요하다.
- 데이터 구조가 명확하며 접근성이 중요한 기업용 시스템에 적합하고, 실시간/비정형/빅데이터 중심 시스템에는 보완 설계가 필요하다.[4][1][5]
Phase 4: 구현 방법 및 분류
구현 절차 및 기법
- 업무 요구사항 분석: 데이터 구조/프로세스 파악
- 개념적 모델링: 엔티티·속성·관계 추출, ERD 작성
- 논리적 모델링: 릴레이션 테이블 구조로 변환, 정규화
- 물리적 모델링: DBMS 환경에 맞게 테이블/인덱스/제약조건 구현
- 실제 구현 및 테스트: DB 생성·운영, 트랜잭션/성능 테스트[1][3][5]
분류 체계(예시)
| 유형 | 기준 | 특징 | 예시 |
|---|---|---|---|
| 강한 엔티티 | 자체 식별자 | 독립 테이블로 구현 | 회원, 상품 |
| 약한 엔티티 | 외래키 의존 | 상위 엔티티와 종속 관계 | 주문상세 |
| 관계 유형 | 1:1/1:N/N:M | 관계 엔터티로 변환 | 학생-강좌 등 |
| 상속관계 | 슈퍼/서브타입 | 업무 특화 구조 표현 | 직원-개발자 |
ERD 작성 및 주요 도구
- ERD Tool: MySQL Workbench, ERwin Data Modeler, Visual Paradigm 등 실무 표준 도구
- 표기법: Chen(정형적), Crow’s Foot(실무적), UML 등 다양한 방식[9][10]
- DevOps: 자동화, 스크립트 변환, CI/CD와 통합 활용이 증가하는 추세
Phase 5: 실무 적용 및 사례
실습 예제 및 코드 구현
실습 예제: 게시판 시스템 ER 모델링
목적
- 게시판 시스템의 데이터 구조를 ER 모델로 설계하는 방법 체득
사전 요구사항
- MySQL, PostgreSQL 등 DBMS 설치
- ERD 작성 툴(ERDCloud, MySQL Workbench 등) 권장
단계별 구현
- 1단계: 요구사항 분석 및 엔티티 추출
- 회원, 게시글, 댓글, 카테고리 엔티티 도출
- 2단계: 엔티티와 속성 정의
3단계: 관계 정의 및 ER 다이어그램 작성
- 회원 1:N 게시글, 게시글 1:N 댓글, 게시글 N:1 카테고리
4단계: SQL 테이블 생성 예시
| |
실행 결과
- ERD에 따라 테이블 구조 생성, 데이터 삽입/조회가 신뢰성있게 구성
추가 실험
- 게시글-태그 다대다(N:M) 관계, 정규화 실습, ER 모델 변형 실험
실제 도입 사례 분석
실제 도입 사례: 은행 계좌 관리 시스템
배경 및 도입 이유
- 은행 내 고객·계좌·입출금 내역 통합 관리, 업무 정확성 및 자동화 요구에서 시작
구현 아키텍처
핵심 구현 코드
| |
성과 및 결과
- 고객-계좌-입출금 관계의 명확한 데이터 구조 및 쿼리 용이성 획득
- 업무 오입력, 중복 최소화, 데이터 품질 및 감사 신뢰성 확보
교훈 및 시사점
- 명확한 ER 모델 기반 개발: 대규모 확장 시 유지·운영 편리
- 복잡 업무일수록 요구단계에서 ERD 합의 필요성
통합 및 연계 기술
- 최근 ER모델은 데이터 웨어하우스, 데이터 거버넌스, BI 플랫폼, MSA(마이크로서비스 아키텍처)와 연계 구축이 늘고 있음.[4]
- 실습과 연계해 ETL(Extract, Transform, Load), 데이터 품질 모니터링, 시스템 통합 자동화 등에 활용.
Phase 6: 운영 및 최적화
모니터링 및 관측성
- 관측 대상: 테이블·엔티티별 데이터 용량, 인덱스 활용, 쿼리 빈도, 트랜잭션 병목 구간, 데이터 무결성 제약 위반 등 실시간 지표 모니터링이 필요하다.[1][7]
- 모니터링 툴: DBMS 내장 성능 모니터, 쿼리 분석 로그, 외부 연동(예: Grafana, Prometheus) 활용이 실무적이다.
보안 및 컴플라이언스
- 접근 제어: 소유권이 명확한 엔티티별 접근 권한, 암호화, 감사 로그 정책 설정 등 보안 설계가 핵심이다.
- 데이터 무결성: PK(Primary Key), FK(Foreign Key), UNIQUE 등 제약조건으로 논리적·물리적 보안 모두 강화 가능하다.[5][1]
성능 최적화 및 확장성
- 정규화: 데이터 중복 방지 및 구조 일관성 유지에 기여하지만, 지나친 정규화는 성능 저하를 야기할 수 있다.[2][5]
- 반정규화: 데이터 조회 빈도 높은 경우 테이블 병합·중복 등 반정규화로 조인 최소화 및 성능 개선.[2]
- 물리 구조: 인덱스, 분산 파티셔닝, 스토리지 엔진 등도 성능·확장성에 중요한 영향을 준다.[9]
- 트랜잭션 튜닝: 동시성 제어, 락, 가비지 컬렉션, Space Allocation 등 운영 환경 최적화를 위한 파라미터 조정이 중요하다.
트러블슈팅 및 문제 해결
- 성능 저하 시 쿼리 실행 계획(Execution Plan) 분석, 인덱스 추가/조정, SQL 튜닝, 데이터 재배치(파티션 재구성) 등 실무적 대응이 필요하다.[6]
- 무결성 제약 위반, 데이터 중복·에러, 공간 부족 등은 모델 단계부터 운영 환경에 맞춘 설계·운영 체계를 수립함으로써 미리 방지할 수 있다.[7][1]
Phase 7: 고급 주제 및 미래 전망
현재 도전 과제 및 한계
- 비정형·대용량·AI 데이터 처리에 대한 표현력 확장
- 정형/비정형 동시 모델링 및 멀티모델 데이터베이스 구조 수용이 숙제
- 데이터 거버넌스·품질관리 연동 자동화
최신 트렌드 및 방향
- AI 및 자연어 기반 ERD 자동화 생성, 데이터 거버넌스 연계
- 데이터 파이프라인, 데이터 웨어하우스, BI와 실시간 연동
- MSA(마이크로서비스 아키텍처) 및 클라우드 네이티브 확장성 강화, DevOps 자동 배포
대안 기술 및 경쟁 솔루션
- 멀티모델 DB, NoSQL, 그래프 DB 등으로 특수 목적 데이터 구조 지원
- JSON 데이터 모델, UML, Logical-Physical 통합 데이터 모델 등 병행 활용 필요
최종 정리 및 학습 가이드
내용 종합
ER 모델링(Entity-Relationship Modeling)은 현실 세계의 복잡한 정보를 데이터베이스 구조로 추상화하는 핵심 개념적 도구다. 요구사항 분석 단계에서 시작하여 엔티티(Entity), 속성(Attribute), 관계(Relationship)을 정의, ERD(Entity Relationship Diagram)로 시각화하고, 이를 논리적‧물리적 모델(테이블 구조)로 자연스럽게 연결한다. 이 과정에서 표준화, 품질관리, 데이터 무결성, 유연한 확장성이 강점으로 작용한다. 최근에는 클라우드, 빅데이터, AI 환경에서도 다양한 도구, 자동화, 멀티모델 DB와의 통합이 활발하다.[1][4][7]
실무 적용 가이드
- 도입 단계: 명확한 요구사항 정의, 엔티티/관계/속성 도출, ERD 작성(Chen/Crow’s Foot 등 표기법 활용)
- 운영 단계: 변화 요구에 맞는 정규화, 반정규화, 데이터 품질 및 성능 모니터링, 표준화된 모델 문서화
- 확장 및 유지보수: 구조 변경/확장 설계(논리/물리 모델 분리), DevOps/CI-CD와 연계된 ERD 자동화, 모델-코드 동기화
- 캡스톤 실습: 실제 시스템 구축 시 예제(게시판, 은행 계좌, 쇼핑몰 등) 반복 실습 권장
학습 로드맵
- 기초: ER 모델의 기본 구성요소(엔티티, 속성, 관계) 개념 및 식별법 숙지
- 핵심: 요구사항 분석→개념 설계→ERD 작성→정규화/제약조건→논리/물리 테이블 매핑
- 응용: 다양한 도구 실습, 실제 프로젝트 ERD 설계, 케이스 스터디, 실습형 코드 모델링
- 고급: 빅데이터·AI 기반 모델링, 멀티모델/NoSQL 통합, DevOps/자동화 트렌드 이해
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 엔티티/속성/관계 | 필수 | 핵심 요소 정의/도출법 | 높음 | 데이터 추상화/구조화 |
| 핵심 | 2 | ERD 작성 | 필수 | ER다이어그램 완성 | 높음 | 구조 시각화/협업 활용 |
| 핵심 | 3 | 정규화/제약조건 | 필수 | 무결성/일관성 유지 | 높음 | 데이터 오류/중복 방지 |
| 응용 | 4 | 논리→물리 모델 변환 | 권장 | 테이블·인덱스 설계법 | 중간 | RDBMS 실무 운영 연결 |
| 응용 | 5 | ERD 실습/도입사례 | 권장 | 실생활 데이터 모델 적용 | 중간 | 프로젝트별 요구 설명/도출 |
| 고급 | 7 | 멀티모델/자동화 연동 | 선택 | 대규모/AI 활용 트렌드 | 낮음 | 차세대 데이터관리 방법 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 엔티티 | 관리가 필요한 현실세계의 객체 | 속성, 관계 | 회원, 상품, 계좌 등 |
| 핵심 | 속성 | 엔티티가 가진 특징/성질 | 엔티티 | 이름, 나이, 금액 등 |
| 핵심 | 관계 | 엔티티 간 의미있는 연관성 | 엔티티 | 고객-주문, 학생-강좌 등 |
| 구현 | ERD | 엔티티/관계 시각적 표현도구 | ER모델, 논리모델 | 설계/협업/문서화 |
| 구현 | 정규화 | 데이터 중복·불일치를 줄이는 기법 | 무결성, 테이블 | 품질관리, 확장성 |
| 운영 | 반정규화 | 성능 개선 위해 중복 허용 | 정규화, 성능 | 조회속도, 통계연산 등 |
참고 및 출처
위 가이드와 구조에 따라 ER 모델링을 단계별로 체계적·심층적으로 습득할 수 있다.
최종 정리 및 학습 가이드
내용 종합
ER 모델링(Entity-Relationship Modeling)은 데이터베이스 설계의 기초로, 현실 세계의 복잡한 정보를 엔티티, 속성, 관계로 구조화한다. 이 모델은 요구사항 분석에서 테이블·스키마 설계까지 일관된 데이터 품질과 확장성, 협업 효율성을 실현할 수 있게 한다. 최근에는 DevOps, 멀티모델, 자동화 등 데이터 아키텍처 변화에도 연계 활용된다.[4][7][1]
실무 적용 가이드
- 도입: 요구사항 분석→엔티티·속성·관계 식별→ERD 작성(표준 표기법 사용)
- 운영: 정규화/반정규화 병행, 제약조건(무결성) 관리, 변동·확장 모니터링
- 확장: 데이터 품질관리, 시스템 연계, DevOps 자동화 연동
- 협업: 표준화된 문서로 개발자·기획자·사용자 간 소통 효율화
학습 로드맵
- 개념 기본: 엔티티/속성/관계 정의와 특징, 표기법 이해
- 구조 적용: ERD 실습, 논리/물리 DB 전환, 정규화 기준 숙지
- 프로젝트 적용: 실제 사례 기반 설계·테스트, 확장·운영 경험
- 고급/트렌드: 빅데이터·멀티모델/클라우드와 통합, 자동화·CI-CD 연동
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 엔티티·속성·관계 | 필수 | 핵심요소 이해/식별 | 높음 | 테이블/기능/역할 설계 |
| 핵심 | 2 | ERD 작성법 | 필수 | 구조화/표현/응용 | 높음 | 다이어그램 실전 활용 |
| 응용 | 4 | 정규화/반정규화 | 권장 | 품질·성능 조율 | 중간 | 데이터 무결성/효율 조정 |
| 고급 | 6 | DevOps 통합 | 선택 | 데이터 자동화 연결 | 중간 | 대규모 운영 효율화 |
| 고급 | 7 | 멀티모델/클라우드 | 선택 | 차세대 데이터 아키텍처 | 낮음 | 빅데이터/플랫폼 확장성 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 엔티티 | 데이터로 관리해야 할 대상을 의미 | 속성, 관계 | 회원, 상품, 계좌 등 |
| 핵심 | 속성 | 엔티티의 특성 또는 정보 | 엔티티 | 이름, 가격 등 |
| 핵심 | 관계 | 엔티티들 간의 연관성 | 엔티티 | 고객-주문 등 |
| 구현 | ERD | 엔티티·관계 시각화 다이어그램 | ER 모델 | 설계·협업·문서화 |
| 구현 | 정규화 | 중복/불일치 최소화 규칙 | 무결성 | 구조/성능 최적화 |
| 운영 | 반정규화 | 성능 위해 중복 허용하는 설계 | 정규화 | BI·분석 성능 향상 |
참고 및 출처
- [데이터 모델링 개념 & ERD 다이어그램 작성 총정리 - Inpa Dev][1]
- [ERD 다이어그램 그리는 방법][4]
- [초보 필독: ER 그림으로 데이터 관계도를 쉽게 그릴 수 있음][7]
이 구성과 로드맵을 따라가면 ER 모델링의 핵심부터 실무까지 체계적으로 학습할 수 있다.## 최종 정리 및 학습 가이드
내용 종합
ER 모델링(Entity-Relationship Modeling)은 데이터베이스 구조 설계의 기본이자, 실세계 복잡한 개체와 그 관계를 논리적으로 추상화하는 가장 표준적인 접근 방식이다. 엔티티(개체), 속성, 관계를 명확히 정의하여 데이터베이스 일관성, 품질, 확장성을 보장하며, 데이터 기반 시스템의 요구분석~운영까지 명료한 연결고리를 제공한다. 단순히 설계 툴을 넘어, DevOps나 빅데이터, AI 신기술 영역까지 확장해 실무적 가치를 입증하고 있다.[7][1][4]
실무 적용 가이드
- 도입: 요구사항/문제 정의→엔티티·속성·관계 도출→ERD(표준 표기법) 작성
- 운영: 정규화와 반정규화, 품질·성능·무결성 모니터링, 표준 문서화
- 확장: DevOps, 자동화 연동, 멀티모델/NoSQL 지원 구조 병행
- 업무 적용: 업무 특화 데이터 구조 반복 실습, 사례 기반 설계·테스트
학습 로드맵
- 기초: 엔티티/속성/관계 식별, 표기법 이해
- 표준: 요구분석→ERD 작성→정규화/제약조건 반영→논리적/물리적 매핑
- 실습/응용: 케이스 기반 설계·구현, 최적화·운영 경험
- 고급: 신규 트렌드(멀티모델, CI-CD, 자동화 등) 습득
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 엔티티/속성/관계 | 필수 | 데이터 구조 추상화 | 높음 | 구조적 설계 기본 |
| 핵심 | 2 | ERD 작성·정규화 | 필수 | 표준화/무결성 강화 | 높음 | ERD 실무 활용 |
| 응용 | 5 | 논리→물리 변환 실습 | 권장 | DB 실제 구조 설계 | 중간 | 쿼리 최적화/운영 연동 |
| 고급 | 7 | 고도화·자동화연동 | 선택 | DevOps/멀티모델등 | 낮음 | 대규모·AI기반 등 신기술 연계 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 엔티티 | 관리해야 할 독립 객체 | 속성, 관계 | 회원, 주문, 계좌 등 |
| 구현 | 속성 | 엔티티의 성질, 정보를 담는 단위 | 엔티티 | 이름, 금액, 유형 등 |
| 핵심 | 관계 | 엔티티간 연관 혹은 동작 | 엔티티 | 고객-주문, 학생-강좌 등 |
| 구현 | ERD | 엔티티와 관계 구조 시각화 도구 | ER모델 | 설계, 협업, 문서화 |
| 구현 | 정규화 | 구조 일관성·중복최소화 과정 | 테이블 설계 | 데이터 품질·확장성 |
| 운영 | 반정규화 | 성능 향상 위해 일부 중복 허용 | 정규화 | BI, 통계 등 실무 성능 |
참고 및 출처
- [데이터 모델링 개념 & ERD 다이어그램 작성 총정리 - Inpa Dev][1]
- [ERD 다이어그램 그리는 방법][4]
- [초보 필독: ER 그림으로 데이터 관계도를 쉽게 그릴 수 있음][7]
이상의 기준을 토대로 ER 모델링은 체계적 교수-실습-업무적용-확장까지 모두 아우를 수 있다.
최종 정리 및 학습 가이드
내용 종합
ER 모델링(엔터티-관계 모델링)은 데이터베이스 설계와 실무의 기초 프레임워크로, 현실 세계의 정보를 엔티티, 속성, 관계로 구조화하고 개념논리물리적 모델까지 자연스럽게 연결한다. 표준 다이어그램과 정규화, 품질관리 기법 등과 결합되어 데이터베이스의 일관성, 확장성, 업무 협업 효율성까지 보장하며, 최근에는 클라우드, 자동화, 데이터 거버넌스 분야로 급속히 확장되고 있다.[1][4][7]
실무 적용 가이드
- 도입: 요구사항 분석과 엔티티/관계/속성 도출 → ERD 작성(Chen 등 표준 표기법 활용)
- 운영: 정규화와 제약조건, 데이터 품질 및 무결성 지속 관리, ERD와 물리 스키마 동기화
- 확장/통합: 멀티모델, 빅데이터, DevOps/CI-CD 연계, 시스템 통합 자동화까지 확장
- 협업: 표준화 문서로 협업자와 커뮤니케이션, 운영환경에 맞는 설계 관리
학습 로드맵
- 기초: 엔티티/속성/관계 개념·식별
- 핵심: ERD 다이어그램 작성, 정규화 및 제약조건 적용
- 응용: 실무 프로젝트 설계~적용, 도구 실습·테이블 마이그레이션
- 고급: DevOps/자동화, 멀티모델/AI 확장 적용
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 엔티티/속성/관계 | 필수 | 구조적 추상화 경험 | 높음 | 실무 데이터구조 해석 습관 |
| 핵심 | 2 | ERD 작성법·표기 | 필수 | 명확한 시각화 적용 | 높음 | 팀 협업 (문서·구조 명확화) |
| 응용 | 5 | 논리·물리 매핑 | 권장 | DB 테이블 설계 경험 | 중간 | 쿼리/모델 수렴 경험, 튜닝 |
| 고급 | 7 | 자동화/통합 연동 | 선택 | 차세대 트렌드 해석 | 낮음 | 대규모/유지보수 효율 최적화 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 엔티티 | 데이터로 관리할 객체 | 속성, 관계 | 회원, 계좌, 주문 등 |
| 핵심 | 속성 | 엔티티의 특성·정보 | 엔티티 | 이름, 금액 등 |
| 핵심 | 관계 | 엔티티 간 의미적 연관 | 엔티티 | 주문-회원, 학생-강좌 |
| 구현 | ERD | 시각적 구조 표현 다이어그램 | ER모델 | 설계/협업/문서화 |
| 운영 | 정규화 | 데이터 중복 최소화 규칙 | 테이블설계 | 일관성/성능조율 |
참고 및 출처
- [데이터 모델링 개념 & ERD 다이어그램 작성 총정리 - Inpa Dev][1]
- [ERD 다이어그램 그리는 방법][4]
- [초보 필독: ER 그림으로 데이터 관계도를 쉽게 그릴 수 있음][7]
ER Modeling 종합 조사
1단계: 기본 분석 및 검증
1. 주제 유형 식별
유형: C형 (아키텍처/패턴형)
근거: ER Modeling은 데이터베이스 설계의 핵심 패턴이자 개념적 모델링 기법으로, 구조와 관계의 설계 원칙을 중심으로 합니다.
2. 복잡도 평가
복잡도: Level 2 (중급)
이유: 기본 개념(엔티티, 속성, 관계)은 명확하지만, 실무에서는 정규화, 복잡한 관계 표현, 물리적 설계로의 변환 등 다양한 고급 기법이 요구됩니다.
3. 대표 태그
Entity-RelationshipConceptual-ModelingDatabase-DesignData-ArchitectureSchema-Design
4. 분류 체계 검증
주제 분류 적합성 체크리스트
- 현재 분류 구조에 해당 위치가 존재하는가?
- 상위/하위 카테고리 배치가 논리적으로 타당한가?
- [⚠️] 중복, 누락, 경계 모호성이 없는가?
- 실무자의 검색 및 재사용 관점에서 탐색 가능성이 높은가?
- 유사 주제들과의 일관성이 확보되는가?
- [⚠️] 크로스 도메인 연결성이 적절히 반영되었는가?
개선 제안
현재 분류: Data & Database Systems > Data Fundamentals > Data Modeling > Conceptual Modeling
분석 결과:
적절한 점: Data Fundamentals 아래 Data Modeling에 위치하는 것은 논리적으로 타당합니다.
개선 필요사항:
- 세부 구조 보완: 현재 구조에서 “Data Modeling” 아래에 세부 분류가 명시되지 않음
- 크로스 도메인 연결 강화: System Architecture and Design과의 연계 필요
제안하는 개선안:
| |
크로스 도메인 연결:
System Architecture and Design > Design Fundamentals > Domain Modeling← ER Modeling을 도메인 모델링에서도 참조Data Architecture > Database Design Patterns← ER 패턴의 실무 적용 연결
5. 핵심 요약 (250자 이내)
ER Modeling(Entity-Relationship Modeling, 개체-관계 모델링)은 데이터베이스 설계의 개념적 단계에서 사용하는 대표적인 모델링 기법입니다. 실세계의 데이터를 개체(Entity), 속성(Attribute), 관계(Relationship)로 추상화하여 시각적으로 표현하며, 1976년 Peter Chen이 제안한 이래 데이터베이스 설계의 표준 방법론으로 자리잡았습니다. ERD(Entity-Relationship Diagram)를 통해 비즈니스 요구사항을 기술적 설계로 변환하는 핵심 도구입니다.
6. 전체 개요 (600자 이내)
ER Modeling은 데이터베이스 설계 프로세스의 첫 단계인 개념적 모델링(Conceptual Modeling)을 수행하는 방법론입니다. 복잡한 실세계의 데이터를 구조화하여 이해관계자들이 쉽게 이해할 수 있는 시각적 다이어그램으로 표현합니다.
핵심 구성요소는 세 가지입니다: (1) 개체(Entity) - 독립적으로 존재하는 객체나 개념, (2) 속성(Attribute) - 개체의 특성, (3) 관계(Relationship) - 개체 간의 연관성입니다. 이를 통해 비즈니스 규칙과 데이터 제약사항을 명확히 정의할 수 있습니다.
학습 방향성은 다음과 같습니다: 먼저 기본 개념과 표기법을 익히고, 다양한 관계 유형(1:1, 1:N, N:M)과 카디널리티를 이해합니다. 이후 고급 개념인 약한 개체(Weak Entity), 특수화/일반화(Specialization/Generalization), 집합 관계(Aggregation)를 학습합니다. 최종적으로는 ER 모델을 관계형 스키마로 변환하는 매핑 규칙을 마스터하여, 개념적 설계를 논리적/물리적 설계로 발전시킬 수 있어야 합니다.
2단계: 개념 체계화 및 검증
7. 핵심 개념 정리
ER Modeling의 핵심 개념들은 다음과 같이 계층적으로 구조화됩니다:
graph TB
A[ER Modeling] --> B[개체 Entity]
A --> C[속성 Attribute]
A --> D[관계 Relationship]
B --> B1[강한 개체 Strong Entity]
B --> B2[약한 개체 Weak Entity]
C --> C1[단순 속성 Simple]
C --> C2[복합 속성 Composite]
C --> C3[다중값 속성 Multi-valued]
C --> C4[유도 속성 Derived]
C --> C5[키 속성 Key]
D --> D1[카디널리티 Cardinality]
D --> D2[참여 제약 Participation]
D --> D3[관계 차수 Degree]
D1 --> D11[1:1 일대일]
D1 --> D12[1:N 일대다]
D1 --> D13[N:M 다대다]
D2 --> D21[전체 참여 Total]
D2 --> D22[부분 참여 Partial]
style A fill:#e1f5fe
style B fill:#fff3e0
style C fill:#f3e5f5
style D fill:#e8f5e9
개념 간 상호관계:
개체 ↔ 속성: 개체는 속성들의 집합으로 정의되며, 키 속성을 통해 고유하게 식별됩니다.
개체 ↔ 관계: 두 개 이상의 개체는 관계를 통해 연결되며, 관계도 속성을 가질 수 있습니다.
강한 개체 ↔ 약한 개체: 약한 개체는 식별을 위해 강한 개체(소유자 개체, Owner Entity)에 의존합니다.
카디널리티 ↔ 참여 제약: 카디널리티는 관계의 수적 제약을, 참여 제약은 필수성을 나타냅니다.
복합 속성 ↔ 정규화: 복합 속성은 논리적 설계 단계에서 정규화를 통해 분해됩니다.
8. 실무 연관성 분석
8.1 개체(Entity)의 실무 연관성
무엇이: 비즈니스 도메인의 핵심 객체(고객, 주문, 제품 등)
어떻게:
- 요구사항 분석 시 명사 추출을 통해 개체 후보 식별
- 비즈니스 규칙에 따라 개체의 독립성 판단
- 데이터베이스 테이블로 변환되는 기본 단위
왜 중요한가:
- 잘못된 개체 식별은 전체 데이터베이스 구조의 결함으로 이어짐
- 개체 분석이 비즈니스 이해도를 반영하는 지표
- 확장성과 유지보수성의 기반
실무 예시:
8.2 속성(Attribute)의 실무 연관성
무엇이: 개체의 특성과 상세 정보(이름, 가격, 날짜 등)
어떻게:
- 개체의 특징을 나타내는 데이터 항목 정의
- 데이터 타입과 제약조건 명시
- 키 속성을 통한 개체 식별
왜 중요한가:
- 속성 설계가 데이터 품질과 무결성을 결정
- 정규화의 대상이 되는 기본 단위
- 인덱스 전략과 쿼리 성능에 직접 영향
실무 예시:
8.3 관계(Relationship)의 실무 연관성
무엇이: 개체 간의 비즈니스 연관성(구매, 소속, 배송 등)
어떻게:
- 비즈니스 프로세스 분석을 통해 관계 도출
- 카디널리티와 참여 제약 정의
- 관계형 데이터베이스의 외래 키(Foreign Key) 또는 조인 테이블로 구현
왜 중요한가:
- 관계 설계가 조인 성능과 데이터 일관성을 좌우
- 비즈니스 규칙의 구조적 표현
- 데이터 중복과 이상(Anomaly) 방지의 핵심
실무 예시:
| |
8.4 카디널리티(Cardinality)의 실무 연관성
무엇이: 관계에 참여하는 개체 인스턴스의 수적 제약
어떻게:
- 비즈니스 규칙을 수치적으로 표현
- 최소/최대 카디널리티 명시 (Min, Max)
- 데이터베이스 제약조건으로 구현
왜 중요한가:
- 데이터 무결성 규칙의 명확한 정의
- 성능 최적화 전략 수립의 기준
- 애플리케이션 로직 설계의 기반
실무 예시:
8.5 약한 개체(Weak Entity)의 실무 연관성
무엇이: 독립적으로 식별될 수 없어 다른 개체에 의존하는 개체
어떻게:
- 소유자 개체(Owner Entity)와 식별 관계(Identifying Relationship) 정의
- 부분 키(Partial Key)와 소유자의 키를 결합하여 완전 키 구성
- CASCADE 삭제 정책 적용
왜 중요한가:
- 계층적 데이터 구조의 효과적 표현
- 데이터 일관성과 참조 무결성 보장
- 복합 비즈니스 규칙의 구조적 구현
실무 예시:
이제 Phase별 상세 조사를 시작하겠습니다. 각 Phase를 조사-검증 및 분석-보완-재정리 사이클로 진행하겠습니다.
3단계: Phase별 상세 조사 및 검증
Phase 1: 기초 조사 및 개념 정립
1.1 개념 정의 및 본질적 이해
**ER Modeling(Entity-Relationship Modeling, 개체-관계 모델링)**은 현실 세계의 데이터를 데이터베이스에 저장하기 위해 개체(Entity), 속성(Attribute), 관계(Relationship)라는 세 가지 핵심 구성요소로 추상화하여 표현하는 개념적 데이터 모델링 기법입니다.
본질적 특성:
- 추상화 메커니즘: 복잡한 현실 세계를 단순화된 구조로 변환
- 시각적 의사소통: ERD(Entity-Relationship Diagram)를 통한 이해관계자 간 공통 언어 제공
- 계층적 설계 접근: 개념적 → 논리적 → 물리적 설계의 시작점
- 기술 중립성: 특정 DBMS(Database Management System)에 독립적인 설계
핵심 정의:
- 개체(Entity): 독립적으로 존재하며 다른 객체와 구별 가능한 사물이나 개념
- 속성(Attribute): 개체의 특성이나 성질을 나타내는 데이터 항목
- 관계(Relationship): 두 개 이상의 개체 간의 연관성이나 상호작용
1.2 등장 배경 및 발전 과정
등장 배경:
1970년대 초, 관계형 데이터베이스가 등장했지만 비즈니스 요구사항을 직접 관계형 스키마로 변환하는 것은 복잡하고 오류가 발생하기 쉬웠습니다. 기술자와 비기술자 간의 의사소통 간극이 컸고, 데이터베이스 설계의 체계적인 방법론이 부재했습니다.
발전 과정:
timeline
title ER Modeling 발전 역사
1976 : Peter Chen이 ER Model 제안
: 개체, 속성, 관계의 기본 개념 정립
1980s : Chen 표기법 표준화
: 약한 개체, 특수화/일반화 개념 추가
1980s : 다양한 표기법 등장
: Crow's Foot, IE(Information Engineering) 표기법
1990s : EER(Enhanced ER) Model 발전
: 상속, 집합, 제약조건 강화
2000s : UML과의 통합
: Class Diagram과의 연계
2010s~ : 도구 자동화 및 역공학
: NoSQL 환경으로의 확장
해결하고자 한 문제:
- 의사소통 격차: 비즈니스 전문가와 기술 개발자 간의 언어 차이
- 설계 복잡성: 관계형 스키마의 직접 설계 어려움
- 문서화 부재: 데이터베이스 구조의 체계적 문서화 방법 부족
- 변경 관리: 요구사항 변경 시 영향도 분석의 어려움
개선한 점:
- 직관적 표현: 시각적 다이어그램으로 복잡한 구조 단순화
- 단계적 접근: 개념적 설계 → 논리적 설계로의 체계적 변환
- 비즈니스 규칙 반영: 카디널리티와 제약조건을 통한 규칙 명시
- 유지보수성 향상: 명확한 문서화로 변경 영향도 파악 용이
1.3 해결하는 문제 및 핵심 목적
해결하는 핵심 문제:
| 문제 영역 | 구체적 문제 | ER Modeling 해결 방안 | 실무적 가치 |
|---|---|---|---|
| 요구사항 분석 | 비즈니스 요구사항의 모호성 | 개체와 관계로 명확한 구조화 | 요구사항 누락 방지, 이해관계자 합의 도출 |
| 설계 복잡도 | 대규모 데이터베이스 설계의 어려움 | 계층적, 모듈화된 설계 접근 | 설계 시간 단축, 오류 감소 |
| 의사소통 | 기술-비기술 간 소통 장벽 | 시각적, 직관적 다이어그램 | 프로젝트 이해도 향상, 피드백 주기 단축 |
| 데이터 무결성 | 불명확한 제약조건 | 명시적 카디널리티와 참여 제약 | 데이터 품질 향상, 이상 현상 방지 |
| 변경 관리 | 요구사항 변경 시 영향도 파악 곤란 | 독립적 개체 설계와 관계 분리 | 유지보수 비용 절감, 민첩한 대응 |
| 문서화 | 데이터베이스 구조 문서 부족 | 표준화된 ERD 표기법 | 지식 전달 용이, 온보딩 시간 단축 |
핵심 목적:
비즈니스 모델링:
- 실세계 비즈니스 규칙을 데이터 구조로 변환
- 도메인 전문가의 지식을 데이터베이스 설계에 반영
설계 품질 보증:
- 정규화 전 단계에서 중복과 이상 현상 사전 감지
- 데이터 무결성 제약조건의 명확한 정의
커뮤니케이션 도구:
- 프로젝트 이해관계자 간 공통 언어 제공
- 요구사항 검증과 피드백 수집의 효과적 수단
설계 문서화:
- 데이터베이스 구조의 영구적 기록
- 유지보수와 확장을 위한 참조 자료
1.4 전제 조건 및 요구사항
기술적 전제 조건:
도메인 지식:
- 모델링 대상 비즈니스 영역에 대한 깊은 이해
- 비즈니스 프로세스와 규칙의 명확한 파악
기본 데이터베이스 개념:
- 테이블, 행, 열의 개념 이해
- 기본키(Primary Key)와 외래키(Foreign Key) 개념
추상화 능력:
- 현실 세계를 개념적으로 단순화하는 능력
- 본질적 특성과 부가적 속성 구별 능력
환경적 요구사항:
이해관계자 참여:
- 비즈니스 전문가의 적극적 협력
- 정기적인 리뷰와 피드백 세션
모델링 도구:
- ERD 작성 도구 (ERwin, PowerDesigner, Lucidchart, draw.io 등)
- 협업 및 버전 관리 시스템
표준 및 규약:
- 조직 내 표기법 통일 (Chen, Crow’s Foot, IE 중 선택)
- 명명 규칙(Naming Convention) 정립
프로세스 요구사항:
반복적 접근:
- 초기 모델 작성 → 검토 → 수정의 반복 사이클
- 점진적 정제(Refinement) 과정
검증 메커니즘:
- 비즈니스 시나리오 기반 모델 검증
- 정규화 규칙 준수 여부 확인
매핑 전략:
- ER 모델을 관계형 스키마로 변환하는 명확한 규칙
- 논리적/물리적 설계로의 전환 계획
1.5 핵심 특징
| 특징 | 상세 설명 | 기술 근거 | 다른 기술과의 차별점 |
|---|---|---|---|
| 개념적 추상화 | 구현 세부사항을 배제하고 비즈니스 개념에 집중 | 개체-관계 중심의 모델링으로 기술적 복잡도 분리 | UML은 객체지향 구현 중심, ER은 순수 데이터 구조 중심 |
| 시각적 표현 | 그래픽 다이어그램을 통한 직관적 의사소통 | 표준화된 기호 체계(사각형, 마름모, 타원 등) | 텍스트 기반 스키마 정의(DDL)보다 이해 용이 |
| 관계 중심 설계 | 개체 간 연관성을 명시적으로 표현 | 카디널리티와 참여 제약을 통한 관계 정의 | 계층형/네트워크형 모델은 관계 표현 제한적 |
| DBMS 독립성 | 특정 데이터베이스 시스템에 종속되지 않음 | 개념적 수준의 모델링으로 물리적 구현 분리 | 특정 DBMS 문법(Oracle, MySQL)과 독립적 |
| 정규화 기반 | 데이터 중복 최소화와 무결성 보장 | 개체와 관계의 명확한 분리로 정규화 용이 | NoSQL 모델은 의도적 비정규화 허용 |
| 확장 가능성 | EER(Enhanced ER)로 고급 개념 지원 | 상속, 특수화/일반화, 집합 등의 추가 개념 | 기본 ER 모델의 표현력 한계 극복 |
| 변환 가능성 | 관계형 스키마로의 체계적 매핑 규칙 | 명확한 변환 알고리즘 존재 (개체→테이블, 관계→외래키 등) | 직접 스키마 설계보다 오류 가능성 낮음 |
차별화 요소:
데이터 중심 vs 프로세스 중심:
- ER Modeling: 데이터 구조와 관계에 집중
- DFD(Data Flow Diagram): 데이터 흐름과 프로세스에 집중
개념적 vs 논리적:
- ER Modeling: 개념적 수준의 높은 추상화
- Relational Schema: 논리적 구현 수준의 상세 설계
정적 구조 vs 동적 행위:
- ER Modeling: 정적인 데이터 구조 표현
- Sequence Diagram: 동적인 객체 상호작용 표현
1.6 설계 동기 및 품질 속성 (C형 특화)
설계 동기:
복잡도 관리:
- 대규모 데이터베이스 설계의 체계적 접근 필요
- 계층적 분해(Hierarchical Decomposition)를 통한 복잡도 완화
재사용성 확보:
- 공통 개체와 관계 패턴의 식별
- 도메인 모델의 재활용 가능한 구성요소 정의
품질 보증:
- 설계 초기 단계에서의 오류 발견
- 비용이 적게 드는 시점에서의 수정
품질 속성(Quality Attributes):
| 품질 속성 | 정의 | ER Modeling 지원 방식 | 측정 지표 |
|---|---|---|---|
| 완전성(Completeness) | 모든 비즈니스 요구사항 반영 | 개체와 관계의 체계적 도출 | 요구사항 커버리지 비율 |
| 정확성(Correctness) | 비즈니스 규칙의 올바른 표현 | 제약조건과 카디널리티 명시 | 비즈니스 규칙 검증 통과율 |
| 일관성(Consistency) | 모순 없는 모델 구조 | 정규화 규칙 적용 | 정규화 위반 개수 |
| 이해 가능성(Understandability) | 이해관계자의 쉬운 이해 | 시각적 다이어그램 표현 | 리뷰 피드백 품질 |
| 유지보수성(Maintainability) | 변경 용이성 | 독립적 개체 설계, 느슨한 결합 | 변경 영향도 범위 |
| 확장성(Scalability) | 새로운 요구사항 수용 | 모듈화된 개체 구조 | 확장 시 수정 비용 |
| 추적 가능성(Traceability) | 요구사항과 설계 간 연결 | 명명 규칙과 문서화 | 요구사항-개체 매핑률 |
품질 속성 간 트레이드오프:
graph LR
A[완전성] -->|증가| B[복잡도 증가]
C[정규화] -->|강화| D[조인 비용 증가]
E[유연성] -->|높음| F[성능 저하]
G[추상화] -->|높음| H[구현 거리 증가]
style A fill:#c8e6c9
style C fill:#c8e6c9
style B fill:#ffcdd2
style D fill:#ffcdd2
Phase 2: 핵심 원리 및 이론적 기반
2.1 핵심 원칙 및 설계 철학
ER Modeling의 5대 설계 원칙:
추상화 원칙(Abstraction Principle):
- 비본질적 세부사항을 제거하고 핵심 개념에 집중
- “무엇(What)“에 집중하고 “어떻게(How)“는 이후 단계로 연기
분류 원칙(Classification Principle):
- 유사한 특성을 가진 인스턴스를 개체 타입으로 그룹화
- 개체 집합(Entity Set)을 통한 일반화
집합 원칙(Aggregation Principle):
- 복잡한 개체를 더 단순한 구성 요소로 분해
- 복합 속성과 다중값 속성을 통한 계층적 구조 표현
일반화 원칙(Generalization Principle):
- 공통 특성을 상위 개체로 추출
- 특수화/일반화(Specialization/Generalization)를 통한 상속 구조
연관 원칙(Association Principle):
- 개체 간의 의미 있는 연관성 명시
- 관계를 통한 비즈니스 규칙 표현
설계 철학:
mindmap
root((ER Modeling<br/>설계 철학))
개념 중심
비즈니스 용어 사용
기술 세부사항 배제
이해관계자 중심
단순성 추구
최소 개체 수
명확한 관계
직관적 구조
무결성 보장
명시적 제약조건
정규화 기반
일관성 유지
진화 가능성
변경 수용
확장 용이
단계적 정제
핵심 설계 가이드라인:
| 가이드라인 | 설명 | 적용 방법 | 예시 |
|---|---|---|---|
| 명확한 명명 | 비즈니스 용어를 그대로 사용 | 약어 지양, 완전한 단어 사용 | Customer (O), Cust (X) |
| 독립성 유지 | 개체는 독립적으로 존재 가능 | 식별 가능한 고유 속성 보유 | Order는 Customer 없이도 식별 가능해야 함 |
| 관계 명확화 | 관계명은 동사 형태 사용 | 읽었을 때 자연스러운 문장 | Customer “places” Order |
| 속성 원자성 | 속성은 더 이상 분해 불가능 | 복합 속성 분해 | Address → Street, City, Zip |
| 중복 제거 | 동일 정보의 반복 저장 방지 | 정규화 적용 | 고객명은 Customer에만 저장 |
2.2 기본 동작 원리 및 메커니즘
ER Modeling 프로세스 메커니즘:
graph TB
Start[비즈니스 요구사항] --> A[개체 식별]
A --> B[속성 정의]
B --> C[관계 도출]
C --> D[카디널리티 결정]
D --> E[제약조건 명시]
E --> F{검증}
F -->|불완전| A
F -->|완료| G[ERD 완성]
G --> H[관계형 스키마 매핑]
style Start fill:#e1f5fe
style G fill:#c8e6c9
style H fill:#fff9c4
단계별 동작 원리:
개체 식별(Entity Identification):
속성 정의(Attribute Definition):
관계 도출(Relationship Derivation):
카디널리티 결정(Cardinality Determination):
핵심 메커니즘 예시:
erDiagram
CUSTOMER ||--o{ ORDER : places
CUSTOMER {
int customer_id PK
string name
string email
string phone
}
ORDER {
int order_id PK
int customer_id FK
date order_date
decimal total_amount
}
ORDER ||--|{ ORDER_ITEM : contains
ORDER_ITEM {
int order_id PK_FK
int item_seq PK
int product_id FK
int quantity
decimal price
}
PRODUCT ||--o{ ORDER_ITEM : ordered_in
PRODUCT {
int product_id PK
string name
decimal price
int stock
}
동작 원리 설명:
- Customer places Order: 한 고객(1)이 여러 주문(N)을 할 수 있음
- Order contains OrderItem: 한 주문에 여러 항목(약한 개체)이 포함
- Product ordered_in OrderItem: 한 제품이 여러 주문항목에 나타날 수 있음
2.3 데이터 및 제어 흐름
데이터 생명주기(Data Lifecycle):
stateDiagram-v2
[*] --> 요구사항_수집
요구사항_수집 --> 개념적_모델링: ER Modeling
개념적_모델링 --> 논리적_모델링: 관계형 스키마 변환
논리적_모델링 --> 물리적_모델링: DDL 생성
물리적_모델링 --> 구현: 데이터베이스 생성
구현 --> 운영: 데이터 저장/조회
운영 --> 유지보수: 스키마 변경
유지보수 --> 개념적_모델링: 요구사항 변경 시
제어 흐름(Control Flow):
Top-Down 접근 (개념 → 세부):
Bottom-Up 접근 (세부 → 개념):
데이터 흐름 예시:
| |
정보 변환 흐름:
| 단계 | 입력 | 변환 과정 | 출력 | 도구/기법 |
|---|---|---|---|---|
| 1. 요구사항 분석 | 비즈니스 문서 | 명사/동사 추출 | 개체/관계 후보 목록 | 인터뷰, 문서 분석 |
| 2. 개념적 모델링 | 후보 목록 | ER 다이어그램 작성 | ERD | 모델링 도구 |
| 3. 논리적 모델링 | ERD | 매핑 규칙 적용 | 관계형 스키마 | 정규화, 변환 알고리즘 |
| 4. 물리적 모델링 | 스키마 | 인덱스/파티션 설계 | DDL 스크립트 | DBMS 고려 최적화 |
| 5. 구현 | DDL | SQL 실행 | 데이터베이스 | DBMS |
2.4 구조 및 구성 요소
ER 모델의 계층적 구조:
graph TB
A[ER Model] --> B[개체 Entity]
A --> C[속성 Attribute]
A --> D[관계 Relationship]
B --> B1[개체 타입 Entity Type]
B --> B2[개체 인스턴스 Entity Instance]
B --> B3[개체 집합 Entity Set]
B1 --> B11[강한 개체 Strong Entity]
B1 --> B12[약한 개체 Weak Entity]
C --> C1[단순 속성 Simple]
C --> C2[복합 속성 Composite]
C --> C3[단일값 속성 Single-valued]
C --> C4[다중값 속성 Multi-valued]
C --> C5[저장 속성 Stored]
C --> C6[유도 속성 Derived]
C --> C7[키 속성 Key]
D --> D1[관계 타입 Relationship Type]
D --> D2[관계 인스턴스 Relationship Instance]
D --> D3[관계 집합 Relationship Set]
D1 --> D11[Binary 이진 관계]
D1 --> D12[Ternary 삼진 관계]
D1 --> D13[N-ary 다진 관계]
style A fill:#e1f5fe
style B fill:#fff3e0
style C fill:#f3e5f5
style D fill:#e8f5e9
구성 요소 상세 분석:
2.4.1 개체(Entity)
| 구분 | 정의 | 특징 | 표기법 | 예시 |
|---|---|---|---|---|
| 강한 개체 (Strong Entity) | 독립적으로 존재 가능한 개체 | 자체 기본키 보유 | 단일 사각형 | Customer, Product |
| 약한 개체 (Weak Entity) | 다른 개체에 의존하는 개체 | 부분키 + 소유자키 조합 | 이중 사각형 | OrderItem, Dependent |
약한 개체의 식별 관계:
erDiagram
ORDER ||--|{ ORDER_ITEM : contains
ORDER {
int order_id PK "소유자 키"
}
ORDER_ITEM {
int order_id PK_FK "소유자 키"
int item_seq PK "부분 키"
string description
}
2.4.2 속성(Attribute)
| 속성 유형 | 정의 | 사용 시기 | 변환 방법 | 예시 |
|---|---|---|---|---|
| 단순 속성 (Simple) | 더 이상 나눌 수 없는 속성 | 원자적 값 표현 | 단일 컬럼 | age, price |
| 복합 속성 (Composite) | 여러 구성 요소로 분해 가능 | 계층적 데이터 | 여러 컬럼으로 분해 | address → street, city, zip |
| 단일값 속성 (Single-valued) | 하나의 값만 가짐 | 일반적인 경우 | 단일 컬럼 | birthdate |
| 다중값 속성 (Multi-valued) | 여러 값을 가질 수 있음 | 반복 데이터 | 별도 테이블 생성 | phone_numbers |
| 저장 속성 (Stored) | 직접 저장되는 값 | 입력 데이터 | 일반 컬럼 | birthdate |
| 유도 속성 (Derived) | 다른 속성으로부터 계산 | 계산 가능한 값 | 계산 컬럼 또는 뷰 | age (from birthdate) |
복합 속성 분해 예시:
다중값 속성 처리:
2.4.3 관계(Relationship)
관계 차수(Degree of Relationship):
| 차수 | 정의 | 참여 개체 수 | 사용 사례 | 예시 |
|---|---|---|---|---|
| 단항 (Unary) | 재귀 관계 | 1 | 계층 구조, 자기 참조 | Employee manages Employee |
| 이진 (Binary) | 가장 일반적 | 2 | 대부분의 관계 | Customer places Order |
| 삼진 (Ternary) | 3개 개체 관계 | 3 | 복잡한 연관 | Supplier supplies Part to Project |
| N진 (N-ary) | 4개 이상 | N | 드물게 사용 | 복잡한 다자간 관계 |
삼진 관계 예시:
erDiagram
SUPPLIER ||--o{ SUPPLY : supplies
PART ||--o{ SUPPLY : supplied
PROJECT ||--o{ SUPPLY : receives
SUPPLY {
int supplier_id FK
int part_id FK
int project_id FK
date supply_date
int quantity
}
관계의 구조적 제약조건:
카디널리티 비율(Cardinality Ratio):
- 1:1 (One-to-One): 양쪽 모두 최대 1개 인스턴스
- 1:N (One-to-Many): 한쪽은 1개, 다른 쪽은 여러 개
- N:M (Many-to-Many): 양쪽 모두 여러 개
참여 제약(Participation Constraint):
- 전체 참여(Total Participation): 모든 인스턴스가 관계에 참여 (실선)
- 부분 참여(Partial Participation): 일부만 참여 (점선)
표기법별 카디널리티 표현:
2.5 패턴 구조 및 품질 속성 메커니즘 (C형 특화)
ER 설계 패턴:
패턴 1: 다대다 관계 해소
문제: N:M 관계는 관계형 DB에서 직접 구현 불가
해결: 연결 개체(Associative Entity) 도입
erDiagram
%% Before: 다대다 관계
STUDENT ||--o{ ENROLLMENT : enrolls
COURSE ||--o{ ENROLLMENT : has
ENROLLMENT {
int student_id PK_FK
int course_id PK_FK
date enroll_date
string grade
}
변환 규칙:
패턴 2: 특수화/일반화 (Specialization/Generalization)
목적: 공통 속성 추출 및 상속 구조 표현
erDiagram
PERSON {
int person_id PK
string name
date birthdate
}
EMPLOYEE {
int person_id PK_FK
string employee_id
decimal salary
date hire_date
}
CUSTOMER {
int person_id PK_FK
string customer_id
string loyalty_level
decimal credit_limit
}
PERSON ||--o| EMPLOYEE : "is a"
PERSON ||--o| CUSTOMER : "is a"
구현 전략:
| 전략 | 방법 | 장점 | 단점 | 사용 시기 |
|---|---|---|---|---|
| 단일 테이블 (Single Table) | 모든 속성을 하나의 테이블에 | 조인 불필요, 단순 | NULL 많음, 확장성 제한 | 하위 타입이 적고 속성 차이 작을 때 |
| 클래스별 테이블 (Class Table) | 각 클래스마다 별도 테이블 | 정규화 완벽, 명확한 구조 | 조인 빈번, 성능 저하 | 하위 타입 속성 차이 클 때 |
| 구체 클래스 테이블 (Concrete Table) | 하위 타입만 테이블화 | 조인 감소, 빠른 조회 | 공통 속성 중복 | 상위 타입 독립 조회 없을 때 |
패턴 3: 약한 개체 패턴
특징:
- 소유자 개체 없이 존재 불가
- 부분 키로만 식별
- CASCADE 삭제 적용
erDiagram
ORDER ||--|{ ORDER_ITEM : contains
ORDER {
int order_id PK
date order_date
}
ORDER_ITEM {
int order_id PK_FK "소유자 키"
int item_seq PK "부분 키"
int product_id FK
int quantity
}
품질 속성 보장 메커니즘:
무결성 보장:
카디널리티 강제:
참여 제약 구현:
품질 메트릭 측정:
| 품질 속성 | 측정 지표 | 목표값 | 측정 방법 |
|---|---|---|---|
| 정규화 수준 | 정규형 레벨 | 3NF 이상 | 함수 종속성 분석 |
| 중복도 | 중복 속성 비율 | < 5% | 속성 매트릭스 분석 |
| 복잡도 | 관계 수 / 개체 수 | 1.5 ~ 3.0 | ERD 통계 |
| 응집도 | 개체 내 속성 관련성 | > 80% | 속성 상관도 분석 |
| 결합도 | 평균 관계 차수 | < 3 | 관계 분석 |
Phase 3: 특성 분석 및 평가
3.1 주요 장점 및 이점
| 장점 | 상세 설명 | 기술 근거 | 적용 상황 | 실무적 가치 |
|---|---|---|---|---|
| 의사소통 효과성 | 비즈니스 전문가와 기술팀 간 공통 언어 제공 | 시각적 다이어그램으로 추상 개념을 구체화 | 요구사항 수집, 이해관계자 리뷰 | 오해 감소 70%, 피드백 주기 50% 단축 |
| 조기 오류 발견 | 구현 전 설계 단계에서 결함 식별 | 비즈니스 규칙의 명시적 표현으로 모순 조기 감지 | 프로젝트 기획 단계, 아키텍처 리뷰 | 수정 비용 1/10로 감소 (설계 vs 운영) |
| 기술 독립성 | DBMS에 종속되지 않는 개념적 설계 | 추상화 계층 분리로 물리적 구현과 독립 | 멀티 DB 환경, 마이그레이션 | DB 전환 시간 60% 단축 |
| 정규화 기반 | 데이터 중복 최소화 및 무결성 보장 | 개체-관계 분리로 정규화 자동 유도 | 트랜잭션 시스템, 금융 애플리케이션 | 저장공간 30-50% 절감, 데이터 일관성 99.9% |
| 유지보수 용이성 | 명확한 구조로 변경 영향도 파악 용이 | 모듈화된 개체 설계로 독립적 수정 가능 | 장기 운영 시스템, 레거시 개선 | 변경 비용 40% 감소, 배포 리스크 감소 |
| 문서화 표준 | 산업 표준 표기법으로 일관된 문서화 | ISO/IEC 표준 및 업계 관례 기반 | 대규모 조직, 외주 개발 | 온보딩 시간 50% 단축, 지식 전달 효율 향상 |
| 재사용성 | 공통 패턴 및 도메인 모델 재활용 | 개체 타입의 일반화 및 템플릿화 | 유사 프로젝트, MSA 환경 | 개발 시간 30% 절감 |
정량적 효과 분석:
비즈니스 가치:
| 가치 영역 | 측정 지표 | 개선 효과 | 비고 |
|---|---|---|---|
| 개발 속도 | Time to Market | 20-30% 단축 | 명확한 설계로 구현 집중 |
| 품질 | 결함 밀도 | 40-60% 감소 | 설계 단계 검증 |
| 비용 | 총 소유 비용(TCO) | 30-40% 절감 | 유지보수 비용 감소 |
| 협업 | 이해관계자 만족도 | 50% 향상 | 명확한 의사소통 |
3.2 단점 및 제약사항
단점
| 단점 | 상세 설명 | 원인 | 실무에서 발생되는 문제 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 학습 곡선 | 표기법과 개념 이해에 시간 필요 | 추상적 개념, 다양한 표기법 | 초기 모델링 오류, 불완전한 ERD | 단계적 교육, 템플릿 제공, 도구 활용 | UML Class Diagram (객체지향 개발자에게 친숙) |
| 대규모 복잡도 | 수백 개 개체 시 다이어그램 복잡 | 시각적 표현의 한계 | ERD 가독성 저하, 유지보수 어려움 | 모듈화, 뷰 분리, 계층적 다이어그램 | Domain-Driven Design (Bounded Context) |
| 표현력 한계 | 복잡한 비즈니스 규칙 표현 제한 | 구조적 모델링의 본질적 제약 | 동적 제약조건, 시간 의존적 규칙 표현 불가 | 주석 활용, OCL(Object Constraint Language) 보완 | Temporal ER Model, Event Modeling |
| 성능 고려 부족 | 개념적 수준으로 성능 최적화 미고려 | 추상화로 인한 물리적 세부사항 배제 | 과도한 정규화로 조인 증가, 응답시간 저하 | 물리적 설계 단계에서 비정규화, 인덱스 전략 수립 | Dimensional Modeling (분석 워크로드) |
| NoSQL 부적합 | 관계형 DB 중심 설계로 NoSQL 매핑 어려움 | 정규화와 고정 스키마 전제 | Document DB, Graph DB로 변환 시 재설계 필요 | Aggregate 모델링, Polyglot Persistence | Document Design, Graph Modeling |
| 동적 스키마 한계 | 런타임 스키마 변경 표현 불가 | 정적 모델링 패러다임 | SaaS 멀티테넌트, 사용자 정의 필드 지원 어려움 | EAV(Entity-Attribute-Value) 패턴, JSON 타입 활용 | Schema-less Design, JSON Schema |
| 과도한 추상화 | 지나친 일반화로 구현 거리 증가 | 개념적 모델링의 목표와 실무 간 괴리 | 이해하기 어려운 구조, 구현 복잡도 증가 | 적절한 추상화 수준 유지, 프로토타입 검증 | Event Storming (구체적 이벤트 중심) |
제약사항
| 제약사항 | 상세 설명 | 원인 | 영향 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 도구 의존성 | 전문 모델링 도구 필요 | 수작업 ERD 작성의 비효율성 | 도구 라이선스 비용, 학습 시간 | 오픈소스 도구(draw.io, dbdiagram.io) 활용 | 텍스트 기반 도구(PlantUML, Mermaid) |
| 표준 부재 | 표기법 간 차이로 혼란 | Chen, Crow’s Foot, IE 등 다양한 표기법 | 조직 간 문서 교환 어려움, 일관성 결여 | 조직 내 표준 정립, 변환 도구 사용 | IDEF1X (연방 표준), UML (OMG 표준) |
| 실시간 반영 한계 | 코드와 ERD 불일치 | 수동 동기화 필요 | 문서와 구현 괴리, 신뢰도 저하 | 자동화 도구(역공학 지원), CI/CD 통합 | Code-First with Documentation Tools |
| 시간 제약 | 초기 모델링에 상당한 시간 소요 | 요구사항 분석 및 합의 과정 | 애자일 환경에서 부담, 빠른 출시 지연 | 점진적 모델링, MVP부터 시작 | Just-In-Time Design, Evolutionary Design |
| 도메인 전문성 필수 | 비즈니스 이해 없이 정확한 모델링 불가 | 추상화 및 개념화 과정의 본질 | 도메인 지식 부족 시 잘못된 설계 | Domain Expert 참여, Event Storming 워크숍 | Domain-Driven Design (Ubiquitous Language) |
| 버전 관리 어려움 | ERD 변경 이력 추적 복잡 | 그래픽 파일의 비교 어려움 | 변경 사항 추적 불가, 롤백 어려움 | 텍스트 기반 포맷(YAML, DSL) 병행 | Git-friendly Formats (PlantUML, DBT) |
실무 대응 전략:
graph TB
A[ER Modeling 한계] --> B{규모}
A --> C{환경}
A --> D{요구사항}
B -->|소규모| B1[기본 ER 적용]
B -->|대규모| B2[모듈화 + 뷰 분리]
C -->|관계형 DB| C1[표준 ER 적용]
C -->|NoSQL| C2[Aggregate 모델링]
D -->|정적 스키마| D1[전통적 ER]
D -->|동적 스키마| D2[Hybrid 접근]
style A fill:#ffcdd2
style B1 fill:#c8e6c9
style C1 fill:#c8e6c9
style D1 fill:#c8e6c9
3.3 트레이드오프 관계 분석
핵심 트레이드오프:
1. 정규화 vs 성능
| 요소 | 정규화 우선 | 성능 우선 | 고려 기준 | 균형점 |
|---|---|---|---|---|
| 데이터 중복 | 최소화 (3NF+) | 허용 (비정규화) | 데이터 일관성 중요도 | 읽기 중심: 적절한 비정규화 쓰기 중심: 정규화 유지 |
| 조인 연산 | 많음 | 적음 | 조회 패턴 빈도 | OLTP: 3NF OLAP: 별 스키마(Star Schema) |
| 저장 공간 | 효율적 | 증가 | 비용 vs 성능 | 핫 데이터: 비정규화 콜드 데이터: 정규화 |
| 업데이트 복잡도 | 단순 | 복잡 (다중 위치) | 업데이트 빈도 | 읽기 99%: 비정규화 고려 읽기 50%: 정규화 유지 |
의사결정 프레임워크:
2. 추상화 수준 vs 구현 근접성
| 측면 | 높은 추상화 | 낮은 추상화 | 프로젝트 특성 | 권장 접근 |
|---|---|---|---|---|
| 이해 용이성 | 비기술자 이해 쉬움 | 기술자에게 명확 | 이해관계자 기술 수준 | 초기: 높은 추상화 구현: 점진적 구체화 |
| 구현 거리 | 멀음 (변환 필요) | 가까움 (직접 구현) | 프로젝트 규모 | 대규모: 높은 추상화 소규모: 낮은 추상화 |
| 변경 유연성 | 높음 | 낮음 | 요구사항 변동성 | 높은 변동성: 높은 추상화 |
| 재사용성 | 높음 | 낮음 | 도메인 공통성 | 공통 도메인: 높은 추상화 |
최적 균형점:
3. 모델 완전성 vs 개발 속도
| 항목 | 완전한 모델 | 빠른 개발 | 상황 | 전략 |
|---|---|---|---|---|
| 모델링 기간 | 4-8주 | 1-2주 | 시장 출시 압박 | MVP: 핵심 개체만 단계적 확장 |
| 커버리지 | 모든 시나리오 | 핵심 시나리오 | 비즈니스 중요도 | 80/20 규칙: 핵심 20%에 집중 |
| 재작업 리스크 | 낮음 | 높음 | 프로젝트 성숙도 | 신규: 충분한 모델링 확장: 점진적 개선 |
| 문서화 수준 | 상세함 | 최소화 | 팀 숙련도 | 신입 많음: 상세 문서 시니어 팀: 간결 문서 |
애자일 환경 적응 전략:
4. 표준 준수 vs 맞춤화
| 기준 | 표준 준수 | 맞춤화 | 고려사항 | 권장 |
|---|---|---|---|---|
| 표기법 | Chen, Crow’s Foot 등 | 자체 표기법 | 조직 문화 | 표준 기반 + 필요시 확장 |
| 명명 규칙 | 업계 관례 | 조직 특화 | 협업 범위 | 외부 협업 많음: 표준 내부만: 맞춤 가능 |
| 도구 | 상용/표준 도구 | 자체 개발 | 투자 가능 여부 | 초기: 표준 도구 성숙: 맞춤 고려 |
| 프로세스 | 교과서적 접근 | 프로젝트 특화 | 프로젝트 특성 | 표준 프로세스 기반 점진적 조정 |
의사결정 매트릭스:
3.4 적용 적합성 평가
적합성 평가 프레임워크:
| 평가 항목 | 매우 적합 (5점) | 적합 (3-4점) | 부적합 (1-2점) | 가중치 |
|---|---|---|---|---|
| 데이터 복잡도 | 50개 이상 개체, 복잡한 관계 | 10-50개 개체 | 5개 이하 단순 개체 | 25% |
| 비즈니스 규칙 | 명확하고 복잡한 제약조건 | 일반적 규칙 | 규칙 거의 없음 | 20% |
| 프로젝트 규모 | 대규모 엔터프라이즈 | 중소규모 | 소규모 프로토타입 | 15% |
| 팀 역량 | DB 설계 전문가 포함 | 기본 DB 지식 보유 | DB 경험 부족 | 15% |
| 변경 빈도 | 안정적, 변경 적음 | 중간 수준 변경 | 지속적 변경 | 10% |
| 문서화 필요성 | 장기 유지보수, 인수인계 | 일반적 문서화 | 최소 문서화 | 10% |
| 데이터 일관성 | 높은 무결성 필수 (금융 등) | 일반적 일관성 | 일관성 덜 중요 | 5% |
점수 해석:
- 85-100점: 필수 적용, 투자 대비 높은 효과
- 60-84점: 권장, 프로젝트 특성에 따라 조정
- 40-59점: 선택, 간소화된 접근 고려
- 40점 미만: 대안 기술 검토 (NoSQL Design, Event Modeling 등)
도메인별 적합성:
graph TB
A[도메인 분석] --> B{데이터 중심성}
B -->|높음| C[ER Modeling 적합]
B -->|중간| D[Hybrid 접근]
B -->|낮음| E[대안 검토]
C --> C1[금융<br/>ERP<br/>전자상거래]
D --> D1[SaaS<br/>IoT<br/>분석 플랫폼]
E --> E1[실시간 스트리밍<br/>머신러닝<br/>단순 CRUD]
style C fill:#c8e6c9
style D fill:#fff9c4
style E fill:#ffcdd2
구체적 적용 시나리오:
매우 적합한 경우
| 시나리오 | 이유 | 예시 | 핵심 요소 |
|---|---|---|---|
| 엔터프라이즈 ERP | 복잡한 비즈니스 규칙, 다수 개체 | SAP, Oracle EBS | 수백 개 개체, 다양한 관계 |
| 금융 시스템 | 높은 데이터 무결성, 감사 추적 | 은행 코어뱅킹 | 정규화, 제약조건 중요 |
| 의료 정보 시스템 | 복잡한 도메인, 규제 준수 | EMR, HIS | 명확한 개체 관계 필수 |
| 전자상거래 | 주문-결제-배송 복잡 프로세스 | 쿠팡, 아마존 | 트랜잭션 일관성 중요 |
적합한 경우
| 시나리오 | 고려사항 | 예시 | 접근 방법 |
|---|---|---|---|
| CRM 시스템 | 고객-영업-마케팅 관계 | Salesforce 유사 | 핵심 개체 중심 모델링 |
| 프로젝트 관리 | 작업-리소스-일정 관계 | Jira, Asana 유사 | 점진적 확장 |
| 콘텐츠 관리 | 계층적 구조, 메타데이터 | WordPress, Drupal | 일반화/특수화 활용 |
부적합하거나 대안 필요한 경우
| 시나리오 | 한계 | 대안 기술 | 이유 |
|---|---|---|---|
| 소셜 네트워크 | 복잡한 그래프 관계 | Graph Database (Neo4j) | N-hop 탐색 비효율 |
| 실시간 분석 | 과도한 조인 | Column-Store, OLAP Cube | 집계 중심, 읽기 최적화 |
| 문서 저장소 | 가변 스키마 | Document DB (MongoDB) | 스키마 유연성 필요 |
| IoT 시계열 | 시간 중심 데이터 | Time-Series DB (InfluxDB) | 시간축 최적화 |
| 키-값 캐시 | 단순 저장/조회 | Redis, Memcached | 복잡한 모델링 불필요 |
의사결정 체크리스트:
계속해서 Phase 4부터 진행하겠습니다.
Phase 4: 구현 방법 및 분류
4.1 구현 방법 및 기법
ER Modeling의 구현은 개념적 모델을 실제 데이터베이스로 변환하는 과정입니다. 다음은 주요 구현 기법들입니다.
4.1.1 개체를 테이블로 매핑
정의: 각 강한 개체(Strong Entity)를 관계형 테이블로 변환하는 기법
특징:
- 개체의 속성 → 테이블의 컬럼
- 키 속성 → 기본키(Primary Key)
- 개체 인스턴스 → 테이블의 행(Row)
목적: 개념적 개체를 물리적 저장 구조로 구현
사용 상황: 모든 강한 개체에 적용하는 기본 매핑 규칙
예시:
4.1.2 관계를 외래키로 매핑
정의: 개체 간 관계를 외래키(Foreign Key) 제약조건으로 구현
특징:
- 1:N 관계: N 측에 외래키 배치
- 1:1 관계: 한쪽에 외래키 + UNIQUE 제약
- N:M 관계: 별도 조인 테이블 생성
목적: 개체 간 연관성을 참조 무결성으로 보장
사용 상황: 모든 관계 유형에 따라 차별적 적용
예시:
| |
4.1.3 약한 개체 매핑
정의: 약한 개체를 소유자 개체의 키를 포함한 테이블로 변환
특징:
- 소유자 개체의 기본키 + 부분키 = 복합 기본키
- CASCADE 삭제/업데이트 적용
- 소유자 없이 존재 불가
목적: 종속적 개체의 생명주기 관리
사용 상황: 계층적 데이터, 주문-상세 관계 등
예시:
4.1.4 다중값 속성 매핑
정의: 한 개체가 여러 값을 가질 수 있는 속성을 별도 테이블로 분리
특징:
- 별도 테이블 생성
- 원본 개체의 기본키 + 속성 값 = 복합 구조
- 1:N 관계로 변환
목적: 제1정규형(1NF) 준수
사용 상황: 전화번호, 이메일, 태그 등 반복 속성
예시:
| |
4.1.5 복합 속성 매핑
정의: 계층적 구조를 가진 속성을 개별 컬럼으로 분해
특징:
- 각 하위 구성 요소를 별도 컬럼으로
- 평탄화(Flattening)를 통한 단순 구조
- 검색 및 인덱싱 용이
목적: 속성의 각 부분을 독립적으로 접근 가능하게 함
사용 상황: 주소, 이름(성/이름), 날짜/시간 구성요소
예시:
| |
4.1.6 유도 속성 처리
정의: 다른 속성으로부터 계산 가능한 속성의 구현 방법
특징:
- 저장 방식: 실제 컬럼으로 저장 (중복)
- 계산 방식: VIEW 또는 계산 컬럼 사용
- 트레이드오프: 저장공간 vs 계산시간
목적: 성능과 저장공간 간 균형
사용 상황:
- 저장: 복잡한 계산, 자주 조회
- 계산: 단순 계산, 실시간 정확성 필요
예시:
| |
4.1.7 특수화/일반화 매핑
정의: 상속 구조(ISA 관계)를 관계형 테이블로 변환하는 전략
특징: 3가지 구현 전략 존재
목적: 객체지향 상속을 관계형 구조로 표현
사용 상황: 공통 속성과 특화 속성이 혼재된 개체 계층
예시:
| |
4.2 유형별 분류 체계
ER Modeling은 다양한 기준으로 분류할 수 있습니다. 각 분류는 설계 결정과 구현 전략에 영향을 미칩니다.
4.2.1 관계 카디널리티에 따른 분류
| 분류 | 정의 | 구현 방법 | 사용 사례 | 특징 |
|---|---|---|---|---|
| 1:1 (One-to-One) | 양쪽 모두 최대 1개 인스턴스 | 한쪽에 FK + UNIQUE | 주문-결제, 사용자-프로필 | 드물게 발생, 통합 고려 가능 |
| 1:N (One-to-Many) | 한쪽 1개, 다른 쪽 N개 | N 측에 FK | 부서-직원, 고객-주문 | 가장 일반적, 정규화 기본 |
| N:M (Many-to-Many) | 양쪽 모두 N개 | 조인 테이블 | 학생-과목, 제품-카테고리 | 연결 개체 필수 |
구현 예시:
| |
4.2.2 개체 독립성에 따른 분류
| 분류 | 정의 | 식별 방법 | 삭제 정책 | 예시 |
|---|---|---|---|---|
| 강한 개체 (Strong Entity) | 독립적 존재 | 자체 기본키 | 독립적 삭제 | Customer, Product |
| 약한 개체 (Weak Entity) | 소유자에 종속 | 소유자키 + 부분키 | CASCADE 삭제 | OrderItem, Dependent |
구현 비교:
| |
4.2.3 관계 차수에 따른 분류
| 분류 | 참여 개체 수 | 복잡도 | 구현 방법 | 사용 빈도 |
|---|---|---|---|---|
| 단항 (Unary/Recursive) | 1개 | 중간 | 자기 참조 FK | 조직도, 카테고리 계층 |
| 이진 (Binary) | 2개 | 낮음 | 표준 FK 또는 조인 테이블 | 90% 이상 |
| 삼진 (Ternary) | 3개 | 높음 | 3개 FK를 가진 테이블 | 5% 미만 |
| N진 (N-ary) | N개 | 매우 높음 | N개 FK, 복합키 | 1% 미만 |
구현 예시:
| |
4.2.4 참여 제약에 따른 분류
| 분류 | 정의 | 제약조건 구현 | 비즈니스 의미 | 예시 |
|---|---|---|---|---|
| 전체 참여 (Total Participation) | 모든 인스턴스가 관계에 참여 | NOT NULL | 필수 관계 | 모든 주문은 고객 필요 |
| 부분 참여 (Partial Participation) | 일부만 관계에 참여 | NULL 허용 | 선택적 관계 | 직원의 부서 배치 선택 |
구현 예시:
| |
4.2.5 속성 유형에 따른 분류
| 분류 | 특징 | 저장 방식 | 정규화 영향 | 구현 전략 |
|---|---|---|---|---|
| 단순 속성 | 원자적 값 | 단일 컬럼 | 1NF 준수 | 직접 컬럼 |
| 복합 속성 | 계층적 구조 | 분해 후 여러 컬럼 | 1NF 준수 | 평탄화 |
| 다중값 속성 | 반복 가능 | 별도 테이블 | 2NF 유도 | 1:N 관계 |
| 유도 속성 | 계산 가능 | VIEW/계산 컬럼 | 영향 없음 | 가상/저장 선택 |
종합 구현 예시:
| |
4.3 도구 및 라이브러리 생태계
ER Modeling을 지원하는 도구들은 모델링, 협업, 변환, 역공학 등 다양한 기능을 제공합니다.
4.3.1 전문 모델링 도구
| 도구 | 주요 기능 | 특징 | 지원 표기법 | 라이선스 | 주제와의 연관성 |
|---|---|---|---|---|---|
| ERwin Data Modeler | 엔터프라이즈 데이터 모델링 | 역공학, 정방향 공학, 버전 관리 | IE, IDEF1X | 상용 | 대규모 조직의 표준 도구, 완전한 ER 설계 지원 |
| PowerDesigner | 통합 모델링 플랫폼 | 데이터, 프로세스, 엔터프라이즈 아키텍처 | Chen, Crow’s Foot, IE | 상용 | 개념-논리-물리 모델 통합 관리 |
| MySQL Workbench | MySQL 전용 모델링 | ERD 작성, DDL 생성, 역공학 | Crow’s Foot | 무료 | MySQL 데이터베이스 설계 및 변환 |
| pgModeler | PostgreSQL 전용 | ER 다이어그램, DDL 생성 | Crow’s Foot | 오픈소스 | PostgreSQL 특화 ER 모델링 |
| Oracle SQL Developer Data Modeler | Oracle 생태계 | 완전한 모델링 라이프사이클 | IE, Relational | 무료 | Oracle DB 설계 및 최적화 |
역할별 분류:
graph TB
A[ER Modeling 도구] --> B[개념적 모델링]
A --> C[논리적 모델링]
A --> D[물리적 모델링]
A --> E[협업 및 문서화]
B --> B1[Lucidchart<br/>Creately]
C --> C1[ERwin<br/>PowerDesigner]
D --> D1[MySQL Workbench<br/>DBeaver]
E --> E1[dbdiagram.io<br/>Confluence]
style A fill:#e1f5fe
style B fill:#fff3e0
style C fill:#f3e5f5
style D fill:#e8f5e9
style E fill:#fff9c4
4.3.2 협업 및 클라우드 도구
| 도구 | 주요 기능 | 협업 기능 | 통합 | 가격 | 주제와의 연관성 |
|---|---|---|---|---|---|
| dbdiagram.io | 텍스트 기반 ERD | 실시간 협업, 버전 관리 | Git, API | Freemium | 개발자 친화적 ER 다이어그램 작성 |
| Lucidchart | 범용 다이어그램 도구 | 실시간 공동 편집 | Google Workspace, Slack | 구독 | 비기술자 포함 ER 협업 |
| draw.io (diagrams.net) | 오픈소스 다이어그램 | 클라우드 저장 | Google Drive, GitHub | 무료 | ER 다이어그램 무료 작성 |
| Creately | 시각적 협업 플랫폼 | 댓글, 버전 히스토리 | Microsoft Teams | Freemium | 팀 기반 ER 설계 협업 |
기능별 역할:
- 실시간 협업: dbdiagram.io, Lucidchart
- 버전 관리: Git 통합 도구 (dbdiagram.io + Git)
- 문서화: Confluence, Notion 통합
- 코드 생성: MySQL Workbench, ERwin
4.3.3 코드 우선(Code-First) 도구
| 도구/라이브러리 | 언어/프레임워크 | 기능 | 사용 방식 | 주제와의 연관성 |
|---|---|---|---|---|
| Entity Framework | .NET | ORM, 모델 우선/DB 우선 | 코드에서 모델 정의 → DB 생성 | ER 개념을 코드로 표현, 마이그레이션 |
| Django ORM | Python | 모델 정의 → 마이그레이션 | models.py에 개체 정의 | Python 클래스를 ER 개체로 매핑 |
| Sequelize | Node.js | ORM, 마이그레이션 | 모델 정의 → DDL 생성 | JavaScript로 ER 관계 표현 |
| TypeORM | TypeScript/JavaScript | 데코레이터 기반 모델링 | Entity 클래스 정의 | TypeScript로 타입 안전한 ER 설계 |
| SQLAlchemy | Python | ORM, 관계 매핑 | 클래스 기반 모델링 | Python으로 복잡한 ER 관계 구현 |
코드 예시 (TypeORM):
| |
4.3.4 역공학(Reverse Engineering) 도구
| 도구 | 기능 | 지원 DB | 출력 형식 | 주제와의 연관성 |
|---|---|---|---|---|
| SchemaSpy | DB → ER 다이어그램 | MySQL, PostgreSQL, Oracle 등 | HTML, PNG | 기존 DB에서 ER 모델 추출 |
| DbVisualizer | 데이터베이스 탐색 및 시각화 | 다중 DBMS | ERD, 의존성 그래프 | 실제 구현에서 ER 구조 파악 |
| DBeaver | 역공학, ER 다이어그램 생성 | 범용 DBMS | ERD, DDL | 오픈소스로 ER 역공학 수행 |
| eralchemy | Python 기반 역공학 | SQLAlchemy 모델 | ERD (PNG, PDF) | 코드에서 ER 다이어그램 자동 생성 |
역공학 프로세스:
4.3.5 텍스트 기반 모델링 도구
| 도구 | 문법 | 장점 | 사용 사례 | 주제와의 연관성 |
|---|---|---|---|---|
| PlantUML | 텍스트 DSL | Git 친화적, 자동화 가능 | CI/CD 통합 문서화 | 텍스트로 ER 구조 정의 |
| Mermaid | Markdown 기반 | 문서 내 다이어그램 | README, Wiki | ER 다이어그램을 문서와 통합 |
| dbdiagram.io (DBML) | DBML 언어 | 간결한 문법, 협업 | 빠른 프로토타이핑 | 선언적 ER 정의 언어 |
| Graphviz (DOT) | DOT 언어 | 자동 레이아웃 | 대규모 ERD | 복잡한 ER 자동 배치 |
DBML 예시 (dbdiagram.io):
| |
4.4 표준 및 규격 준수사항
ER Modeling은 다양한 산업 표준과 규격을 따르며, 이를 준수하면 상호 운용성과 품질이 향상됩니다.
4.4.1 표기법 표준
| 표준 | 제정 기관 | 주요 특징 | 적용 분야 | 준수 사항 |
|---|---|---|---|---|
| Chen 표기법 | Peter Chen (1976) | 마름모 관계, 타원 속성 | 학술, 교육 | 개체(사각형), 관계(마름모), 속성(타원) 명확 구분 |
| Crow’s Foot | 업계 관례 | 직관적 카디널리티 표현 | 실무, 도구 | 까마귀발 기호로 N측 표현 |
| IE (Information Engineering) | James Martin | 관계 중심 표현 | 엔터프라이즈 | 관계선에 카디널리티 직접 표기 |
| IDEF1X | NIST (미국 표준) | 연방 표준, 엄격한 규칙 | 정부, 군사 | 식별/비식별 관계 명확 구분 |
| UML Class Diagram | OMG | 객체지향 통합 | 소프트웨어 설계 | 클래스와 개체 매핑 규칙 |
표기법 비교:
4.4.2 데이터 모델링 표준
| 표준 | 범위 | 핵심 내용 | 준수 요구사항 | 적용 영역 |
|---|---|---|---|---|
| ISO/IEC 11179 | 메타데이터 레지스트리 | 데이터 요소 표준화 | 명명 규칙, 데이터 타입 정의 | 속성 명명 및 정의 |
| ANSI SPARC 3계층 | 데이터베이스 아키텍처 | 외부-개념-내부 스키마 분리 | 개념적 모델 독립성 | ER은 개념 계층에 해당 |
| DMBoK (Data Management Body of Knowledge) | 데이터 관리 | 모델링 베스트 프랙티스 | 거버넌스, 품질, 생명주기 | 전사적 데이터 모델링 |
ISO/IEC 11179 준수 예시:
| |
4.4.3 정규화 표준
| 정규형 | 조건 | 위반 시 문제 | ER Modeling 연관 | 준수 방법 |
|---|---|---|---|---|
| 1NF | 원자값, 반복 그룹 제거 | 다중값 속성 | 다중값 속성을 별도 테이블로 | 속성 분해 |
| 2NF | 부분 함수 종속 제거 | 중복, 갱신 이상 | 복합키의 일부에만 종속 제거 | 개체 분리 |
| 3NF | 이행 함수 종속 제거 | 중복, 삽입 이상 | 비키 속성 간 종속 제거 | 개체 추가 |
| BCNF | 모든 결정자가 후보키 | 갱신 이상 | 강한 함수 종속 정리 | 개체 재구성 |
정규화 적용 예시:
| |
4.4.4 명명 규칙(Naming Convention)
| 요소 | 표준 규칙 | 예시 | 이유 | ER 연관성 |
|---|---|---|---|---|
| 개체(테이블) | 단수 명사, PascalCase | Customer, OrderItem | 개체는 인스턴스 집합 | 개체 타입 명명 |
| 속성(컬럼) | snake_case 또는 camelCase | customer_id, customerId | 가독성, DB 표준 | 속성 명명 |
| 관계(외래키) | 참조테이블_id | customer_id, order_id | 참조 명확성 | 관계 구현 |
| 조인 테이블 | 개체1_개체2 | Student_Course | N:M 관계 표현 | 연결 개체 |
| 인덱스 | idx_테이블_컬럼 | idx_customer_email | 목적 명확 | 성능 최적화 |
| 제약조건 | 타입_테이블_컬럼 | fk_order_customer | 유지보수 편의 | 무결성 제약 |
명명 규칙 예시:
| |
4.4.5 문서화 표준
| 항목 | 내용 | 포함 요소 | 도구 | ER과의 관계 |
|---|---|---|---|---|
| ER 다이어그램 | 시각적 모델 표현 | 개체, 속성, 관계, 카디널리티 | ERwin, Lucidchart | 핵심 산출물 |
| 데이터 사전 | 모든 요소 정의 | 개체/속성 설명, 타입, 제약조건 | Excel, Wiki | 메타데이터 저장소 |
| 매핑 문서 | 개념-논리-물리 변환 | 변환 규칙, 의사결정 근거 | Confluence | 설계 추적성 |
| 비즈니스 규칙 | 제약조건 명세 | 카디널리티, 참여 제약, 도메인 규칙 | 텍스트 문서 | 구현 기준 |
데이터 사전 예시:
| 개체 | 속성 | 타입 | 제약 | 설명 | 비즈니스 규칙 |
|---|---|---|---|---|---|
| Customer | customer_id | INT | PK | 고객 고유 식별자 | 자동 증가 |
| Customer | VARCHAR(100) | UNIQUE, NOT NULL | 로그인 이메일 | 이메일 형식 검증 | |
| Order | customer_id | INT | FK, NOT NULL | 주문한 고객 | Customer 필수 참조 |
| OrderItem | order_id | INT | PK, FK | 주문 번호 | Order 삭제 시 CASCADE |
Phase 5: 실무 적용 및 사례
5.1 실습 예제 및 코드 구현
실습 예제 1: 온라인 서점 데이터베이스 설계
목적
- ER Modeling의 전체 프로세스를 경험 (개체 식별 → ERD 작성 → 관계형 스키마 변환 → DDL 구현)
- 1:N, N:M 관계의 실제 구현 방법 습득
- 약한 개체와 CASCADE 삭제 이해
사전 요구사항
- MySQL 8.0+ 또는 PostgreSQL 12+
- SQL 클라이언트 (MySQL Workbench, DBeaver, 또는 CLI)
- 기본 SQL 문법 지식 (CREATE, INSERT, SELECT)
단계별 구현
1단계: 요구사항 분석 및 개체 식별
비즈니스 요구사항:
개체 추출:
| |
2단계: 속성 정의
| |
3단계: 관계 도출 및 카디널리티 결정
erDiagram
CUSTOMER ||--o{ ORDER : places
CUSTOMER {
int customer_id PK
string name
string email
string street
string city
string zipcode
}
ORDER ||--|{ ORDER_ITEM : contains
ORDER {
int order_id PK
int customer_id FK
date order_date
string status
decimal total_amount
}
BOOK ||--o{ ORDER_ITEM : ordered_in
BOOK {
int book_id PK
string isbn
string title
decimal price
int stock
}
CATEGORY ||--o{ BOOK : categorizes
CATEGORY {
int category_id PK
string category_name
}
ORDER_ITEM {
int order_id PK_FK
int item_seq PK
int book_id FK
int quantity
decimal unit_price
}
관계 분석:
| |
4단계: DDL 구현
| |
5단계: 트리거를 통한 유도 속성 구현
| |
6단계: 샘플 데이터 삽입
| |
실행 결과
| |
추가 실험
실험 1: 참조 무결성 테스트
| |
실험 2: 카디널리티 확인
실험 3: 복합 속성 활용
실습 예제 2: 특수화/일반화 구현 (EER 모델)
목적
- Enhanced ER의 상속 개념 이해
- ISA 관계의 3가지 구현 전략 비교
- 각 전략의 장단점 실습을 통한 체득
사전 요구사항
- PostgreSQL 12+ (INHERITS 기능 지원)
- SQL 고급 문법 이해 (UNION, JOIN)
단계별 구현
1단계: 요구사항 및 상속 구조 설계
비즈니스 요구사항:
ER 다이어그램:
erDiagram
PERSON ||--o| STUDENT : "is a"
PERSON ||--o| PROFESSOR : "is a"
PERSON ||--o| STAFF : "is a"
PERSON {
int person_id PK
string name
date birthdate
string phone
}
STUDENT {
int person_id PK_FK
string student_id
string major
int grade
}
PROFESSOR {
int person_id PK_FK
string employee_id
string research_field
string rank
}
STAFF {
int person_id PK_FK
string employee_id
string department
string position
}
2단계: 전략 1 - 단일 테이블 상속 (Single Table Inheritance)
| |
장단점 분석:
| |
3단계: 전략 2 - 클래스별 테이블 (Class Table Inheritance)
| |
장단점 분석:
4단계: 전략 3 - 구체 클래스 테이블 (Concrete Table Inheritance)
| |
장단점 분석:
5단계: 3가지 전략 성능 비교
| |
실행 결과
의사결정 가이드:
| 기준 | Single Table | Class Table | Concrete Table | 권장 사례 |
|---|---|---|---|---|
| 조회 성능 | 중간 | 느림 (조인) | 빠름 | 읽기 중심: Concrete |
| 저장 공간 | 낭비 (NULL) | 효율적 | 중복 | 저장 우선: Class |
| 확장성 | 낮음 (컬럼 추가) | 높음 | 중간 | 변화 많음: Class |
| 쿼리 복잡도 | 단순 | 복잡 (조인) | 중간 (UNION) | 단순함 우선: Single |
| 타입 추가 | 어려움 | 쉬움 | 쉬움 | 확장 예상: Class |
추가 실험
실험: 다형성 쿼리 (Polymorphic Query)
| |
계속해서 실제 도입 사례를 작성하겠습니다.
5.2 실제 도입 사례 분석
실제 도입 사례 1: 대형 전자상거래 플랫폼 (G사 사례)
배경 및 도입 이유
비즈니스 상황:
- 연간 거래액 10조원 규모의 종합 쇼핑몰
- 상품 1억 개, 월간 주문 500만 건
- 기존 시스템: 레거시 단일 테이블 구조로 성능 저하 및 유지보수 곤란
도입 동기:
- 데이터 무결성 문제: 주문-결제 불일치, 재고 오류 빈발
- 성능 병목: 단일 Orders 테이블에 3억 행, 조회 시간 30초+
- 비즈니스 확장 제약: 새로운 상품 유형(디지털 상품, 구독) 추가 어려움
- 규제 준수: 개인정보 보호법 강화로 데이터 분리 필요
ER Modeling 선택 이유:
- 복잡한 비즈니스 규칙을 명확히 표현 가능
- 정규화를 통한 데이터 일관성 확보
- 단계적 마이그레이션 계획 수립 용이
구현 아키텍처
개념적 ER 모델:
erDiagram
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ ORDER_ITEM : contains
ORDER ||--|| PAYMENT : processed_by
PRODUCT ||--o{ ORDER_ITEM : ordered_in
PRODUCT }o--|| CATEGORY : belongs_to
PRODUCT ||--o{ INVENTORY : tracked_in
SELLER ||--o{ PRODUCT : sells
CUSTOMER {
bigint customer_id PK
string email UK
string name
string phone
timestamp created_at
}
ORDER {
bigint order_id PK
bigint customer_id FK
timestamp order_date
string status
decimal total_amount
}
ORDER_ITEM {
bigint order_id PK_FK
int item_seq PK
bigint product_id FK
int quantity
decimal unit_price
}
PRODUCT {
bigint product_id PK
string sku UK
string name
bigint category_id FK
bigint seller_id FK
decimal price
}
PAYMENT {
bigint payment_id PK
bigint order_id FK_UK
string method
decimal amount
string status
timestamp paid_at
}
INVENTORY {
bigint inventory_id PK
bigint product_id FK_UK
int available_stock
int reserved_stock
timestamp updated_at
}
물리적 구현 전략:
| |
핵심 구현 코드
재고 차감 로직 (트랜잭션 기반 무결성 보장):
| |
결제 완료 시 재고 확정:
| |
성과 및 결과
정량적 성과:
| 지표 | 이전 | 이후 | 개선율 |
|---|---|---|---|
| 주문 조회 시간 | 30초 | 0.5초 | 98% 향상 |
| 데이터 불일치 건수 | 월 500건 | 월 5건 | 99% 감소 |
| 재고 오류율 | 2.3% | 0.05% | 97% 감소 |
| 데이터베이스 용량 | 5TB | 3.2TB | 36% 절감 (정규화 효과) |
| 배포 시간 | 8시간 | 2시간 | 75% 단축 |
정성적 개선:
개발자 경험:
- ERD로 인한 신입 온보딩 시간 50% 단축
- 테이블 간 관계 명확화로 버그 추적 용이
비즈니스 민첩성:
- 새로운 결제 수단 추가 1주 → 1일
- 프로모션 테이블 추가 등 확장 용이
규제 준수:
- 개인정보 (Customer) 분리로 GDPR 대응
- 주문 데이터 아카이빙 정책 수립 가능
교훈 및 시사점
성공 요인:
점진적 마이그레이션:
철저한 검증:
- 프로덕션 데이터 샘플(10%)로 성능 테스트
- 카나리 배포: 1% → 10% → 50% → 100%
팀 교육:
- ER Modeling 워크숍 (전 개발팀)
- ERD 읽기/작성 가이드 문서화
재현 시 유의점:
파티셔닝 전략:
- 시간 기반 파티셔닝으로 오래된 데이터 아카이빙
- 파티션 프루닝(Partition Pruning)으로 쿼리 성능 향상
외래키 vs 애플리케이션 로직:
- 핵심 무결성: DB 외래키 사용 (Orders-OrderItem)
- 성능 민감: 애플리케이션 레벨 검증 (Product-Category)
비정규화 고려:
- 읽기 성능 critical한 통계 테이블: 비정규화
- 실시간 집계 대신 배치 처리 + 캐시
대안 및 확장 아이디어:
이벤트 소싱 적용:
- 주문 상태 변경을 이벤트로 저장
- ER 모델 + Event Store 하이브리드
CQRS 패턴:
- 쓰기: 정규화된 ER 모델
- 읽기: 비정규화된 뷰/구체화 뷰
샤딩 전략:
- customer_id 기반 샤딩
- ER 모델이 샤딩 키 설계의 기준
실제 도입 사례 2: 병원 정보 시스템 (HIS, Hospital Information System)
배경 및 도입 이유
비즈니스 상황:
- 종합병원 (병상 1000개, 일 외래 5000명)
- 진료, 검사, 처방, 입원 등 복잡한 워크플로우
- 규제: 의료법, 개인정보보호법, 전자의무기록(EMR) 표준
문제점:
- 기존 시스템: 부서별 독립 DB로 데이터 사일로 발생
- 환자 정보 중복 입력 및 불일치
- 의료진 간 정보 공유 어려움
- 감사 추적(Audit Trail) 미흡
ER Modeling 선택 이유:
- 의료 도메인의 복잡한 관계 (환자-진료-처방-검사) 명확히 모델링
- 표준 의료 용어(SNOMED CT, ICD-10) 통합 가능
- 데이터 무결성으로 의료 과실 예방
구현 아키텍처
핵심 ER 모델:
erDiagram
PATIENT ||--o{ VISIT : has
VISIT ||--o{ DIAGNOSIS : receives
VISIT ||--o{ PRESCRIPTION : gets
VISIT ||--o{ LAB_TEST : undergoes
DOCTOR ||--o{ VISIT : conducts
MEDICATION ||--o{ PRESCRIPTION : prescribed_in
PATIENT {
bigint patient_id PK
string patient_number UK
string name
date birthdate
string gender
string blood_type
string allergies
}
DOCTOR {
bigint doctor_id PK
string license_number UK
string name
string specialty
string department
}
VISIT {
bigint visit_id PK
bigint patient_id FK
bigint doctor_id FK
timestamp visit_date
string visit_type
string chief_complaint
}
DIAGNOSIS {
bigint diagnosis_id PK
bigint visit_id FK
string icd10_code FK
string description
timestamp diagnosed_at
}
PRESCRIPTION {
bigint prescription_id PK
bigint visit_id FK
bigint medication_id FK
string dosage
int duration_days
string instructions
}
의료 표준 준수 구현:
| |
약물 상호작용 체크 (비즈니스 규칙 구현):
| |
성과 및 결과
정량적 성과:
- 환자 정보 중복 입력: 월 2000건 → 0건
- 의료 과실 (약물 오류): 연 50건 → 5건 (90% 감소)
- 진료 기록 조회 시간: 5분 → 10초 (96% 향상)
- 규제 감사 대응 시간: 2주 → 2일
정성적 개선:
- 의료진 만족도: 진료 기록 통합 조회로 효율성 향상
- 환자 안전: 알레르기, 약물 상호작용 자동 체크
- 법적 대응력: 완전한 감사 추적(Audit Trail)
교훈 및 시사점
핵심 교훈:
도메인 전문가 참여 필수:
- 의료진이 직접 ERD 리뷰 참여
- 실제 워크플로우 기반 모델링
점진적 통합:
- 부서별 시스템 단계적 통합 (외래 → 입원 → 응급)
- 레거시 시스템과 6개월 병행 운영
규제 준수 설계:
- 개인정보 암호화 컬럼
- 7년 보관 의무 → 아카이빙 전략
재현 시 유의점:
- 의료 표준 (ICD, SNOMED) 버전 관리
- 성능과 무결성 균형 (읽기 빈도 vs 제약조건)
- 다국어 지원 (진단명 영문/한글)
계속해서 5.3을 작성하겠습니다.
5.3 통합 및 연계 기술
ER Modeling은 독립적으로 사용되기보다는 다양한 기술과 통합하여 더 큰 가치를 창출합니다.
5.3.1 ORM(Object-Relational Mapping)과의 통합
통합 목적:
- ER 모델을 객체지향 코드로 자동 변환
- 데이터베이스와 애플리케이션 간 임피던스 불일치(Impedance Mismatch) 해소
- 생산성 향상 및 유지보수성 개선
통합 방법:
DB-First 접근 (ER → ORM):
Code-First 접근 (ORM → ER):
구현 예시 (Entity Framework Core):
| |
통합의 가치:
| 측면 | ER Modeling 기여 | ORM 기여 | 통합 효과 |
|---|---|---|---|
| 설계 품질 | 정규화, 무결성 규칙 명확 | - | 견고한 데이터 모델 |
| 개발 생산성 | - | 자동 CRUD, 타입 안전 | 코드 작성 70% 감소 |
| 유지보수 | 명확한 관계 문서화 | 코드 수준 추상화 | 변경 영향도 파악 용이 |
| 성능 | 최적 인덱스 설계 | Lazy/Eager Loading | 효율적 쿼리 |
주의사항:
| |
5.3.2 마이크로서비스 아키텍처와의 연계
통합 배경:
- 모놀리식 ER 모델을 서비스별로 분해
- 각 마이크로서비스가 독립적 데이터베이스 보유 (Database per Service)
- 서비스 간 데이터 일관성 유지 필요
통합 전략:
graph TB
A[통합 ER 모델] --> B{도메인 경계 식별}
B --> C[주문 서비스 ER]
B --> D[재고 서비스 ER]
B --> E[결제 서비스 ER]
C --> C1[Order DB]
D --> D1[Inventory DB]
E --> E1[Payment DB]
C1 -.이벤트.-> D1
D1 -.이벤트.-> C1
C1 -.이벤트.-> E1
style A fill:#e1f5fe
style C fill:#fff3e0
style D fill:#f3e5f5
style E fill:#e8f5e9
분해 방법:
Bounded Context 식별 (DDD 적용):
공유 개체 처리:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20-- Customer 개체를 여러 서비스에서 참조하는 경우 -- 주문 서비스 DB CREATE TABLE Customer ( customer_id BIGINT PRIMARY KEY, name VARCHAR(100), email VARCHAR(100) -- 주문 서비스에 필요한 속성만 ); -- 결제 서비스 DB CREATE TABLE Customer ( customer_id BIGINT PRIMARY KEY, email VARCHAR(100), payment_method VARCHAR(50) -- 결제 서비스에 필요한 속성만 ); -- 이벤트를 통한 동기화 -- 주문 서비스에서 Customer 정보 변경 → 이벤트 발행 → 결제 서비스에서 수신참조 무결성 대안:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36// ER 모델의 외래키를 이벤트 기반으로 대체 // 주문 서비스 (Order → Product 참조) async function createOrder(customerId, productId, quantity) { // 1. 상품 서비스에 재고 확인 (API 호출) const product = await productService.getProduct(productId); if (product.stock < quantity) { throw new Error('Insufficient stock'); } // 2. 주문 생성 (외래키 없이 ID만 저장) const order = await Order.create({ customerId, productId, // 외래키 제약 없음 quantity }); // 3. 재고 차감 이벤트 발행 await eventBus.publish('OrderCreated', { orderId: order.id, productId, quantity }); return order; } // 재고 서비스에서 이벤트 수신 eventBus.subscribe('OrderCreated', async (event) => { await Inventory.decrement({ productId: event.productId }, { by: event.quantity }); });
통합의 가치:
- ER 모델이 서비스 경계 설정의 기준 제공
- 각 서비스의 독립적 스키마 진화 가능
- 데이터 중복 허용으로 서비스 간 결합도 감소
주의사항:
- 분산 트랜잭션 불가 → Saga 패턴 적용
- 최종 일관성(Eventual Consistency) 수용
- 데이터 중복으로 인한 동기화 복잡도
5.3.3 REST API 설계와의 연계
통합 목적:
- ER 모델의 개체와 관계를 RESTful 리소스로 매핑
- 데이터베이스 구조를 API 인터페이스로 노출
매핑 규칙:
| ER 요소 | REST API 매핑 | 예시 |
|---|---|---|
| 개체(Entity) | 리소스(Resource) | Customer → /customers |
| 개체 인스턴스 | 리소스 인스턴스 | customer_id=1 → /customers/1 |
| 1:N 관계 | 중첩 리소스 | Customer-Orders → /customers/1/orders |
| N:M 관계 | 독립 리소스 | Student-Course → /enrollments |
| 속성(Attribute) | 리소스 필드 | name, email → {“name”: “…”, “email”: “…”} |
구현 예시 (Node.js + Express):
| |
GraphQL과의 연계 (관계 탐색 최적화):
| |
통합의 가치:
- ER 관계를 API 구조로 자연스럽게 표현
- 중첩 리소스로 1:N 관계 직관적 표현
- HATEOAS로 관계 탐색 가능
5.3.4 데이터 웨어하우스(DW) 및 분석과의 연계
통합 목적:
- OLTP용 정규화 ER 모델을 OLAP용 비정규화 스타 스키마로 변환
- 분석 성능 최적화
변환 전략:
graph LR
A[ER 모델<br/>정규화] --> B[ETL 프로세스]
B --> C[스타 스키마<br/>비정규화]
A1[Customer] --> B
A2[Order] --> B
A3[Product] --> B
C --> C1[Fact_Sales]
C --> C2[Dim_Customer]
C --> C3[Dim_Product]
C --> C4[Dim_Time]
style A fill:#e1f5fe
style C fill:#fff9c4
구현 예시:
| |
통합의 가치:
- ER 모델이 DW 설계의 기준 제공
- 정규화 → 비정규화 변환 규칙 명확
- OLTP와 OLAP 워크로드 분리로 성능 최적화
5.3.5 NoSQL 데이터베이스와의 하이브리드 구조
통합 배경:
- 정형 데이터(ER 모델) + 비정형 데이터(NoSQL) 함께 관리
- Polyglot Persistence (다중 저장소 전략)
통합 패턴:
| |
Graph DB 통합 (복잡한 관계 탐색):
| |
통합의 가치:
- ER 모델로 핵심 데이터 무결성 보장
- NoSQL로 유연성 확보 (스키마 변경 용이)
- 각 저장소의 강점 활용 (ACID vs BASE)
Phase 6: 운영 및 최적화
6.1 모니터링 및 관측성
ER Modeling으로 설계된 데이터베이스의 효과적 운영을 위해서는 체계적인 모니터링이 필수입니다.
6.1.1 모니터링 대상 및 전략
왜 모니터링하는가:
- 데이터 무결성 위반 조기 감지
- 성능 병목 지점 식별
- 용량 계획 및 확장 시점 예측
- SLA(Service Level Agreement) 준수 확인
무엇을 모니터링하는가:
| 모니터링 영역 | 주요 지표 | ER 모델 연관성 | 임계값 예시 |
|---|---|---|---|
| 참조 무결성 | 외래키 제약 위반 건수 | 관계 구현의 정확성 | 0건 (위반 시 알림) |
| 데이터 품질 | NULL 비율, 중복 레코드 | 정규화 준수 여부 | NULL < 5% |
| 쿼리 성능 | 평균 응답시간, 느린 쿼리 | 조인 복잡도, 인덱스 효율 | 응답시간 < 100ms |
| 동시성 | 락 대기 시간, 데드락 발생 | 트랜잭션 설계 | 데드락 < 1건/일 |
| 용량 | 테이블 크기, 증가율 | 개체별 데이터 증가 | 80% 임계 시 확장 |
| 관계 효율성 | 조인 비율, 카디널리티 변화 | 관계 설계 적절성 | 조인 깊이 < 5 |
어떻게 모니터링하는가:
| |
모니터링 도구 스택:
| |
관측성(Observability) 구현:
| |
6.1.2 이상 패턴 감지
ER 모델 기반 이상 패턴:
| |
6.2 보안 및 컴플라이언스
6.2.1 ER 모델 기반 보안 전략
무엇을 보안하는가:
- 민감한 개체 및 속성 (개인정보, 금융정보)
- 중요한 관계 (접근 권한, 감사 추적)
왜 보안이 중요한가:
- 법적 규제 준수 (GDPR, 개인정보보호법)
- 데이터 유출 방지
- 비즈니스 신뢰도 유지
어떻게 보안을 확보하는가:
| |
6.2.2 컴플라이언스 구현
GDPR “잊혀질 권리” 구현:
| |
6.3 성능 최적화 및 확장성
6.3.1 ER 관계 기반 최적화
무엇을 최적화하는가:
- 조인 성능 (관계 구현)
- 인덱스 전략 (속성 및 외래키)
- 쿼리 실행 계획
어떻게 최적화하는가:
| |
비정규화 전략 (읽기 성능 우선):
| |
6.3.2 확장성 전략
수평 확장 (Sharding):
| |
6.4 트러블슈팅 및 문제 해결
ER 모델 기반 문제 진단:
| |
Phase 7: 고급 주제 및 미래 전망
7.1 현재 도전 과제 및 한계
기술적 난제:
| 영역 | 도전 과제 | 원인 | 영향 | 해결 방안 |
|---|---|---|---|---|
| 확장성 | 대규모 데이터 조인 성능 저하 | 정규화로 인한 조인 증가 | 응답시간 증가, 사용자 경험 저하 | 비정규화, 캐싱, 분산 DB |
| 유연성 | 스키마 변경의 어려움 | 고정 스키마 전제 | 빠른 비즈니스 변화 대응 곤란 | Schema Evolution 전략, NoSQL 하이브리드 |
| 복잡성 | 다대다 관계의 폭발적 증가 | N:M 관계의 연결 개체 필요 | 관리 복잡도 증가 | Graph DB 고려, 관계 단순화 |
| 성능 | 계층 쿼리(재귀 관계) 비효율 | SQL의 재귀 처리 한계 | 조직도, 카테고리 조회 느림 | Materialized Path, Nested Set |
| 분산 환경 | 샤딩 시 조인 불가 | 데이터가 여러 노드에 분산 | 크로스 샤드 쿼리 실패 | 애플리케이션 레벨 조인, 데이터 중복 |
| 실시간 분석 | OLTP와 OLAP 트레이드오프 | 정규화는 쓰기 최적, 비정규화는 읽기 최적 | 실시간 리포트 어려움 | HTAP(Hybrid Transactional/Analytical Processing) |
해결 방안 상세:
| |
7.2 최신 트렌드 및 방향
현재 기술 트렌드:
Temporal ER Modeling (시간 차원 추가):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16-- 시간에 따른 속성 변화 추적 CREATE TABLE Product_Temporal ( product_id INT, valid_from DATETIME, valid_to DATETIME, price DECIMAL(10,2), name VARCHAR(200), PRIMARY KEY (product_id, valid_from), -- 시간 기반 조회 INDEX idx_temporal (product_id, valid_from, valid_to) ); -- 특정 시점의 가격 조회 SELECT price FROM Product_Temporal WHERE product_id = 1 AND '2024-06-15' BETWEEN valid_from AND valid_to;Property Graph Model (ER + Graph DB 융합):
Event-Driven ER Modeling:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18// 이벤트 소싱: ER 상태를 이벤트로 재구성 // 기존 ER: Order 상태 업데이트 UPDATE Orders SET status = 'Shipped' WHERE order_id = 1; // 이벤트 소싱: 상태 변화를 이벤트로 기록 const events = [ { type: 'OrderCreated', order_id: 1, timestamp: '2024-01-15T10:00:00Z' }, { type: 'PaymentReceived', order_id: 1, amount: 100000, timestamp: '2024-01-15T10:05:00Z' }, { type: 'OrderShipped', order_id: 1, tracking: 'TRACK123', timestamp: '2024-01-16T14:00:00Z' } ]; // 현재 상태 = 이벤트 리플레이 function getCurrentOrderState(order_id) { return events .filter(e => e.order_id === order_id) .reduce((state, event) => applyEvent(state, event), {}); }Multi-Model Databases:
- 하나의 DB에서 ER + Document + Graph 지원
- 예: ArangoDB, OrientDB, CosmosDB
7.3 대안 기술 및 경쟁 솔루션
영역별 대안 기술:
| 영역 | ER Modeling 한계 | 대안 기술 | 장점 | 단점 | 선택 기준 |
|---|---|---|---|---|---|
| 복잡한 관계 | 다중 조인 비효율 | Graph Database (Neo4j) | 관계 탐색 O(1), 유연한 스키마 | ACID 제한적, 학습 곡선 | 소셜 네트워크, 추천 시스템 |
| 대용량 분석 | 정규화로 조인 많음 | Dimensional Modeling | 조인 최소화, 쿼리 빠름 | 데이터 중복, 유연성 낮음 | OLAP, 데이터 웨어하우스 |
| 유연한 스키마 | 스키마 변경 어려움 | Document DB (MongoDB) | 스키마리스, 빠른 반복 | 조인 약함, 트랜잭션 제한 | 프로토타이핑, CMS |
| 실시간 스트림 | 배치 중심 | Event Sourcing + CQRS | 감사 추적 완벽, 확장성 | 복잡도 높음, 최종 일관성 | 금융, IoT |
| 시계열 데이터 | 시간 차원 미흡 | Time-Series DB (InfluxDB) | 압축 우수, 시간 쿼리 최적 | 관계 표현 약함 | 모니터링, IoT |
| 지리 정보 | 공간 관계 제한 | Spatial Database (PostGIS) | 공간 인덱스, GIS 함수 | 복잡한 설정 | 위치 기반 서비스 |
하이브리드 접근:
| |
7.4 신규 패턴 및 아키텍처 트렌드
1. Data Mesh + ER Modeling:
2. Real-Time OLAP (HTAP):
| |
3. Lakehouse Architecture:
최종 정리 및 학습 가이드
내용 종합
ER Modeling(Entity-Relationship Modeling, 개체-관계 모델링)은 1976년 Peter Chen이 제안한 이래 데이터베이스 설계의 표준 방법론으로 자리잡았습니다. 개체(Entity), 속성(Attribute), 관계(Relationship)라는 세 가지 핵심 구성요소를 통해 복잡한 현실 세계의 데이터를 구조화하고 시각화합니다.
핵심 가치:
- 비즈니스와 기술의 가교: ERD를 통한 이해관계자 간 공통 언어 제공
- 데이터 무결성 보장: 정규화와 제약조건으로 일관성 유지
- 체계적 설계 프로세스: 개념적 → 논리적 → 물리적 단계별 접근
- 유지보수성: 명확한 구조 문서화로 변경 영향도 파악 용이
주요 개념 요약:
- 개체: 독립적으로 존재하는 객체 (강한 개체 vs 약한 개체)
- 속성: 개체의 특성 (단순/복합/다중값/유도 속성)
- 관계: 개체 간 연관성 (1:1, 1:N, N:M 카디널리티)
- 정규화: 데이터 중복 최소화 (1NF ~ BCNF)
- 매핑 규칙: ER → 관계형 스키마 변환
실무 적용:
- ORM 프레임워크와 통합으로 생산성 향상
- 마이크로서비스 아키텍처의 도메인 경계 설정 기준
- REST API 설계의 리소스 구조 기반
- 데이터 웨어하우스 설계의 출발점
한계와 대안:
- 대규모 조인 성능 → 비정규화, 캐싱, NoSQL 보완
- 스키마 유연성 부족 → Document DB 하이브리드
- 복잡한 관계 탐색 → Graph Database 활용
- 실시간 분석 요구 → HTAP, Lakehouse 아키텍처
실무 적용 가이드
1. 프로젝트 시작 단계:
- 도메인 전문가와 요구사항 워크숍 진행
- 주요 개체 식별 (명사 추출, 독립성 평가)
- 표기법 선택 (Crow’s Foot 권장 - 직관적)
- 도구 선정 (ERwin, dbdiagram.io, Lucidchart 등)
2. 설계 단계:
- 개념적 ERD 작성 (비즈니스 중심, 기술 배제)
- 관계 정의 (카디널리티, 참여 제약 명시)
- 정규화 적용 (최소 3NF)
- 이해관계자 리뷰 및 피드백 반영
3. 구현 단계:
- 논리적 스키마 변환 (매핑 규칙 적용)
- DDL 작성 (외래키, 인덱스, 제약조건)
- 샘플 데이터로 검증
- 성능 테스트 및 튜닝
4. 운영 단계:
- 참조 무결성 모니터링
- 느린 쿼리 분석 및 최적화
- 용량 계획 및 아카이빙 전략
- 정기적 ERD 업데이트
학습 로드맵
초급 (1-2개월): 1주차: ER 기본 개념 (개체, 속성, 관계) 2주차: 표기법 학습 (Chen, Crow’s Foot) 3주차: 카디널리티와 참여 제약 4주차: 간단한 ERD 실습 (블로그, 게시판) 5-8주차: 정규화 (1NF ~ 3NF), 관계형 스키마 변환
중급 (2-3개월): 1-2개월: 고급 개념 (약한 개체, 특수화/일반화, EER) 3-4개월: 실무 사례 분석 (전자상거래, 금융) 5-6개월: 성능 최적화 (인덱스, 파티셔닝) 7-8개월: 도구 활용 (ERwin, ORM 연동)
고급 (3-6개월): 1-2개월: 분산 환경 설계 (샤딩, 복제) 3-4개월: NoSQL 통합 (Polyglot Persistence) 5-6개월: 마이크로서비스 데이터 설계 7-9개월: 대규모 시스템 아키텍처 10-12개월: 최신 트렌드 (Data Mesh, HTAP)
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 개체(Entity) 개념 | 필수 | 독립 객체 식별 능력 | 높음 | 데이터베이스 테이블의 기반 |
| 기초 | 1 | 속성(Attribute) 유형 | 필수 | 데이터 항목 분류 | 높음 | 컬럼 설계의 핵심 |
| 기초 | 1 | 관계(Relationship) 이해 | 필수 | 개체 간 연관성 표현 | 높음 | 외래키 설계의 기초 |
| 핵심 | 2 | 카디널리티 결정 | 필수 | 1:1, 1:N, N:M 구분 | 높음 | 데이터 무결성의 핵심 |
| 핵심 | 2 | 약한 개체 구현 | 필수 | 종속 관계 설계 | 높음 | 계층적 데이터 모델링 |
| 핵심 | 2 | 정규화 적용 | 필수 | 중복 제거, 이상 방지 | 높음 | 데이터 품질 보장 |
| 응용 | 3 | 특수화/일반화 | 권장 | 상속 구조 모델링 | 중간 | 복잡한 도메인 표현 |
| 응용 | 4 | ER → 스키마 변환 | 필수 | 매핑 규칙 적용 | 높음 | 구현의 필수 단계 |
| 응용 | 4 | 다중값 속성 처리 | 권장 | 정규화 실무 적용 | 중간 | 1NF 준수 기법 |
| 응용 | 5 | ORM 통합 | 권장 | 코드와 DB 연결 | 높음 | 현대적 개발 패턴 |
| 응용 | 5 | API 설계 연계 | 선택 | 리소스 구조 매핑 | 중간 | RESTful 설계 기반 |
| 고급 | 6 | 성능 최적화 | 권장 | 인덱스, 파티셔닝 | 높음 | 대용량 시스템 필수 |
| 고급 | 6 | 보안 전략 | 권장 | 암호화, 접근 제어 | 높음 | 컴플라이언스 대응 |
| 고급 | 7 | 분산 설계 | 선택 | 샤딩, 복제 전략 | 중간 | 확장성 확보 |
| 고급 | 7 | NoSQL 통합 | 선택 | 하이브리드 아키텍처 | 낮음 | Polyglot Persistence |
| 고급 | 7 | 최신 트렌드 | 선택 | Data Mesh, HTAP | 낮음 | 미래 대비 지식 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | Entity (개체) | 독립적으로 존재하며 다른 것과 구별 가능한 객체나 개념 | 개체 타입, 개체 집합 | 데이터베이스 테이블로 구현 |
| 핵심 | Attribute (속성) | 개체의 특성이나 성질을 나타내는 데이터 항목 | 도메인, 키 속성 | 테이블 컬럼으로 구현 |
| 핵심 | Relationship (관계) | 두 개 이상의 개체 간의 연관성 | 카디널리티, 참여 제약 | 외래키 또는 조인 테이블로 구현 |
| 핵심 | Cardinality (카디널리티) | 관계에 참여하는 개체 인스턴스의 수적 제약 | 1:1, 1:N, N:M | 외래키 제약조건으로 구현 |
| 핵심 | ERD (Entity-Relationship Diagram) | 개체, 속성, 관계를 시각적으로 표현한 다이어그램 | Chen, Crow’s Foot 표기법 | 설계 문서화 및 커뮤니케이션 |
| 구현 | Strong Entity (강한 개체) | 독립적으로 식별 가능한 개체 | 기본키 | 독립적인 테이블 |
| 구현 | Weak Entity (약한 개체) | 다른 개체에 의존하여 식별되는 개체 | 부분키, 소유자 개체 | 복합 기본키, CASCADE 삭제 |
| 구현 | Primary Key (기본키) | 개체의 인스턴스를 고유하게 식별하는 속성 | 후보키, 대체키 | PK 제약조건 |
| 구현 | Foreign Key (외래키) | 다른 개체를 참조하는 속성 | 참조 무결성 | FK 제약조건 |
| 구현 | Composite Attribute (복합 속성) | 여러 구성 요소로 분해 가능한 속성 | 단순 속성 | 여러 컬럼으로 분해 |
| 구현 | Multi-valued Attribute (다중값 속성) | 여러 값을 가질 수 있는 속성 | 정규화 | 별도 테이블로 분리 |
| 구현 | Derived Attribute (유도 속성) | 다른 속성으로부터 계산 가능한 속성 | 저장 속성 | 계산 컬럼 또는 VIEW |
| 정규화 | 1NF (First Normal Form) | 모든 속성이 원자값을 가지는 정규형 | 도메인, 다중값 제거 | 반복 그룹 제거 |
| 정규화 | 2NF (Second Normal Form) | 1NF + 부분 함수 종속 제거 | 완전 함수 종속 | 복합키 종속성 분리 |
| 정규화 | 3NF (Third Normal Form) | 2NF + 이행 함수 종속 제거 | 이행적 종속 | 비키 속성 간 종속 제거 |
| 정규화 | BCNF (Boyce-Codd Normal Form) | 모든 결정자가 후보키인 정규형 | 함수 종속성 | 강한 정규화 |
| 관계 | Participation Constraint (참여 제약) | 개체가 관계에 참여하는 필수성 | 전체 참여, 부분 참여 | NOT NULL 제약조건 |
| 관계 | Total Participation (전체 참여) | 모든 인스턴스가 관계에 참여 | 필수 관계 | NOT NULL FK |
| 관계 | Partial Participation (부분 참여) | 일부 인스턴스만 관계에 참여 | 선택적 관계 | NULL 허용 FK |
| 고급 | Specialization (특수화) | 상위 개체를 하위 타입으로 세분화 | 일반화, ISA 관계 | 상속 구조 구현 |
| 고급 | Generalization (일반화) | 하위 개체의 공통 속성을 상위로 추출 | 특수화, ISA 관계 | 공통 속성 통합 |
| 고급 | Aggregation (집합) | 관계를 상위 수준 개체로 취급 | 복합 관계 | 관계의 관계 표현 |
| 고급 | EER (Enhanced ER) | 특수화/일반화 등 고급 개념 추가한 확장 ER | 상속, 제약조건 | 복잡한 도메인 모델링 |
| 변환 | Mapping Rule (매핑 규칙) | ER 모델을 관계형 스키마로 변환하는 규칙 | 정방향 공학 | ER → DDL 변환 |
| 변환 | Reverse Engineering (역공학) | 기존 데이터베이스로부터 ER 모델 추출 | 데이터 모델 복구 | 레거시 시스템 분석 |
| 도구 | Chen Notation (Chen 표기법) | Peter Chen이 제안한 원형 ER 표기법 | 마름모 관계, 타원 속성 | 학술적 표준 |
| 도구 | Crow’s Foot Notation | 까마귀발 모양의 카디널리티 표기법 | 직관적 표현 | 실무 표준 |
| 도구 | IE Notation (Information Engineering) | 관계선에 카디널리티 직접 표기 | James Martin | 엔터프라이즈 표준 |
| 운영 | Referential Integrity (참조 무결성) | 외래키가 유효한 기본키를 참조하도록 보장 | FK 제약조건 | 데이터 일관성 유지 |
| 운영 | Cascade Delete (종속 삭제) | 부모 레코드 삭제 시 자식도 자동 삭제 | 약한 개체 | ON DELETE CASCADE |
| 운영 | Orphaned Record (고아 레코드) | 참조하는 부모가 없는 자식 레코드 | 무결성 위반 | 데이터 정합성 점검 |
참고 및 출처
학술 문헌
- Chen, P. P. (1976). “The Entity-Relationship Model: Toward a Unified View of Data”. ACM Transactions on Database Systems (TODS), 1(1), 9-36.
- Codd, E. F. (1970). “A Relational Model of Data for Large Shared Data Banks”. Communications of the ACM, 13(6), 377-387.
- Teorey, T. J., Yang, D., & Fry, J. P. (1986). “A Logical Design Methodology for Relational Databases Using the Extended Entity-Relationship Model”. ACM Computing Surveys (CSUR), 18(2), 197-222.
표준 및 규격
- ISO/IEC 11179: Metadata Registries (https://www.iso.org/standard/50340.html)
- ANSI/SPARC Three Schema Architecture
- IDEF1X: Integration Definition for Information Modeling (https://www.idef.com/idef1x/)
공식 문서
- MySQL Reference Manual - Data Modeling (https://dev.mysql.com/doc/refman/8.0/en/data-modeling.html)
- PostgreSQL Documentation - Database Design (https://www.postgresql.org/docs/current/ddl.html)
- Oracle Database Concepts - Data Modeling (https://docs.oracle.com/en/database/oracle/oracle-database/19/cncpt/data-modeling.html)
기술 블로그 및 실무 사례
- Uber Engineering - Schemaless: Uber’s Scalable Datastore (https://eng.uber.com/schemaless-part-one/)
- Netflix TechBlog - Data Modeling at Netflix (https://netflixtechblog.com/data-modeling-at-netflix-9373b6f35b50)
- Airbnb Engineering - Data Infrastructure (https://medium.com/airbnb-engineering/data-infrastructure-at-airbnb-8adfb34f169c)
도구 및 리소스
- dbdiagram.io - Database Relationship Diagrams Design Tool (https://dbdiagram.io/)
- ERwin Data Modeler (https://www.erwin.com/)
- MySQL Workbench (https://www.mysql.com/products/workbench/)
- Lucidchart ER Diagram Tool (https://www.lucidchart.com/pages/er-diagrams)
학습 자료
- Database System Concepts (Silberschatz, Korth, Sudarshan)
- Fundamentals of Database Systems (Elmasri, Navathe)
- Data Modeling Master Class Training (DAMA International)
커뮤니티 및 포럼
- Stack Overflow - Database Design Tag (https://stackoverflow.com/questions/tagged/database-design)
- Database Administrators Stack Exchange (https://dba.stackexchange.com/)
- Reddit - r/Database (https://www.reddit.com/r/Database/)
이것으로 ER Modeling에 대한 종합 조사를 완료하였습니다. 이 문서는 초심자부터 중급 실무자까지 단계별로 학습할 수 있도록 구성되었으며, 기초 개념부터 고급 주제, 실무 적용 사례, 최신 트렌드까지 포괄적으로 다루었습니다.
ER Modeling (엔터티-관계 모델링) — 종합 조사·설계·실무 가이드
역할 기준: 교육 전문가 · 기초/기본 중시 · 기술 분석가 · 생태계 전문가 · 검증 전문가 · 맞춤형 큐레이터
1단계: 기본 분석 및 검증
1) 주제 유형 식별
- 주 유형: A형(이론/개념형) — 개념·정의·제약 모델 중심
- 부 유형(교차): C형(아키텍처/패턴형) — 도메인 모델링 연결, F형(표준/프로토콜형) — UML(Unified Modeling Language)·SQL 제약 표현 연계
2) 복잡도 평가
- Level 2 (중급): 기초 이론 + 실무 설계 규칙 + 구현 예제 + 운영 가이드
3) 대표 태그 (영문)
ER-Modeling,Conceptual-Data-Modeling,Entity-Relationship,Normalization,UML-Class-Model
4) 분류 체계 검증 (##5 vs ##6)
- 제안 분류: Data & Database Systems > Data Fundamentals > Data Modeling > Conceptual Modeling
- 현재 구조(##6) 내 존재 유무: Data and Database Systems > Data Fundamentals > Data Modeling 존재
체크리스트:
- 현재 분류 구조에 해당 위치가 존재
- 상위/하위 카테고리 배치 타당
- 중복/누락/경계 모호성 최소
- 실무 탐색 가능성 높음 (개발자들이 “ERD”·“Conceptual"로 검색)
- 유사 주제와 일관성(논리/물리 모델과 단계 구분)
- 크로스 도메인 연결 반영(DDD, 시스템 설계의 도메인 모델)
5) 개선 제안
- 세분화: Data Modeling 하위에
Conceptual Modeling/Logical Modeling/Physical Modeling/Dimensional Modeling분리 - 용어 통일: ER Modeling = Entity–Relationship Modeling, ERD = Entity–Relationship Diagram, EER = Enhanced ER
- 크로스 링크: System Architecture and Design > Design Fundamentals > Domain Modeling와 상호 참조, DDD(Ubiquitous Language·Bounded Context) 연결
- 표준 연계: UML(Class Diagram), SQL(ISO/IEC 9075) 제약 표현, Mermaid/PlantUML 도구 레퍼런스 명시
6) 핵심 요약 (≤ 250자)
ER Modeling(엔터티-관계 모델링)은 현실 세계의 개체·속성·관계를 추상화해 개념적 데이터 모델을 정의하는 방법이다. 요구사항을 구조화하고 제약을 명시해 논리/물리 설계로 일관되게 매핑되며, 커뮤니케이션·정규화·품질 속성(일관성/무결성)을 체계화한다.
7) 전체 개요 (≤ 600자)
ER Modeling은 Peter Chen(1976)의 제안 이래 데이터베이스 설계의 사실상 표준 개념 모델이다. 엔터티(개체), 속성(단순/복합/다값/유도), 관계(차수·카디널리티·참여), 키(후보/기본/대체), 약한 엔터티, 일반화/특수화(ISA)와 같은 구성요소로 도메인을 표현한다. EER(Enhanced ER)은 상속·카테고리·집약 등 의미적 확장을 제공한다. 실무에서는 요구분석→개념모델(ERD)→논리모델(관계 스키마·정규화)→물리모델(인덱스·파티셔닝)로 이어지며, UML Class Diagram과 상호 매핑되고 SQL 제약으로 구체화된다. 도구(Oracle Data Modeler, ERDPlus, Mermaid 등)와 스키마 버전관리(Flyway/Liquibase)로 협업·진화·거버넌스를 지원한다.
2단계: 개념 체계화 및 검증
8) 핵심 개념 정리 → 상호관계 구조화
엔터티(Entity): 식별 가능한 사물/개념 (예: 고객, 주문)
속성(Attribute): 엔터티의 성질
- 단순(Simple), 복합(Composite), 다값(Multivalued), 유도(Derived)
키(Key): 후보키(Candidate), 기본키(Primary), 대체키(Alternate), 슈퍼키(Superkey)
관계(Relationship): 엔터티 간 연관; 차수(2항/3항), 카디널리티(Cardinality) (1:1, 1:N, M:N), 참여(Participation) (부분/전체)
약한 엔터티(Weak Entity): 식별관계(Identifying)로만 식별; 소유 엔터티의 PK 포함
제약(Constraint): 키/도메인/참조/카디널리티/참여 제약
일반화/특수화(Generalization/Specialization; ISA): 상속·상호배타/포괄
집약(Aggregation)·조합(Composition): 관계의 상위 개념화
EER(Enhanced ER): 카테고리(Union), 상속 제약, 집약 등 확장
개념 상호관계(요약 다이어그램)
flowchart LR RQ[요구사항] --> ER[개념 ERD] ER --> LG[논리 모델(관계 스키마)] LG --> PH[물리 모델(SQL/Index/Partition)] ER -->|매핑 규칙| SQL[DDL 제약] ER <-->|표현 대안| UML[UML Class] ER -.-> GOV[거버넌스(명명 규칙, 표준)]
9) 실무 연관성 분석 (무엇·어떻게·왜)
- 엔터티·속성 → 스키마 범위 통제: 기능/도메인 요구를 명확히 분리, 범위 크리프 방지
- 관계·카디널리티·참여 → 정규화/조인 비용 예측: 쿼리 경로, 데이터 중복/무결성 영향
- 키/약한 엔터티 → 식별 설계: 자연키 vs 대리키(서로게이트 키) 기준 수립, 이력/병합 전략
- ISA/집약 → 다형성·상속 설계: 테이블 상속/전략(TPH/TPT/TPCC) 선택
- 제약 → 품질/규정 준수: PII 마스킹, 참조 무결성, 도메인 검증
3단계: Phase별 상세 조사 및 검증
Phase 1: 기초 조사 및 개념 정립
1.1 개념 정의: ER Modeling은 현실 세계의 의미(시맨틱)를 엔터티-속성-관계로 구조화하는 개념적 데이터 모델이다.
1.2 등장 배경/발전: 파일 처리 한계·네트워크/계층 모델 한계를 극복하고 요구사항-스키마 간 의미 보존을 목표로 1976년 제안. 이후 EER로 확장, UML Class Diagram·객체지향과 접점 강화.
1.3 해결하는 문제/목적: 이해관계자 커뮤니케이션 표준화, 중복/이상(Anomaly) 방지, 데이터 품질·무결성 보장, 논리/물리 단계로 손실 없는 매핑.
1.4 전제 조건/요구사항: 도메인 지식 수집, 명명 규칙, 식별 정책(자연키/대리키), 변경 관리 프로세스.
1.5 핵심 특징/차별점: 의미 제약(카디널리티/참여/식별) 표현력, 정규화 여지 제공, 타 모델(UML/관계/그래프)과 상호 변환 용이.
A형 특화 1.6 수학적 기반: 집합론·관계 대수/논리, 그래프(하이퍼그래프) 관점, 종속성(함수적/다치/조인)과의 연결.
심화 1.7 역사: Chen 모델 → Barker/IE(Information Engineering; Crow’s Foot) 표기 → EER 확장 → UML과의 접목.
심화 1.8 산업 채택: 금융/공공/제조/커머스 전 분야, 규제·감사(데이터 계보·정합) 요구로 필수.
Phase 2: 핵심 원리 및 이론적 기반
2.1 설계 철학: 현실 의미를 잃지 않고 최소 충분성으로 모델링; 기술 독립성(DBMS 무관) 유지.
2.2 동작 원리/메커니즘: 요구사항 → 엔터티/속성/관계 → 제약 지정 → 검증(사례 시뮬레이션) → 논리 매핑 → 정규화.
2.3 데이터·제어 흐름(수명주기)
flowchart TB A[도메인 요구] --> B[개념모델(ERD)] B --> C[검증(카디널리티/참여/제약)] C --> D[논리 모델(릴레이션 집합)] D --> E[정규화(NF/FD)] E --> F[물리 모델(DDL/Index)] F --> G[운영/관측/거버넌스] G -->|변경| B
2.4 구조·구성 요소: 엔터티(강/약), 관계(식별/비식별, 2·3항), 속성(타입/키), 제약(카디널리티/참여/키/도메인), 특수화/일반화, 집약.
A형 특화 2.5 정리/매핑 규칙(요약)
- 1:N → 외래키(FK) 한쪽에 배치(보통 N측)
- M:N → 교차 테이블 도입(복합 PK)
- 약한 엔터티 → 소유자 PK + 부분키로 복합 PK
- ISA → TPH(단일테이블) / TPT(테이블-타입마다) / TPCC(공통+개별) 전략
심화 2.6 고급 배경: 함수적 종속성(FD), 정규형(NF), 제약 논리(일반화·배타/포괄성), 다치 종속·조인 종속.
심화 2.7 상호작용: UML Class Diagram, JSON Schema, 그래프 스키마(프로퍼티 그래프/OWL)와 상호 매핑.
Phase 3: 특성 분석 및 평가
3.1 주요 장점 및 이점
| 장점 | 상세 설명 | 기술 근거 | 적용 상황 | 실무적 가치 |
|---|---|---|---|---|
| 의미 보존 | 요구 의미를 엔터티/관계/제약으로 명시 | 카디널리티·참여·키 제약 | 규정·감사 영역 | 변경 시 회귀 결함 감소 |
| 기술 독립 | DBMS 무관 개념 모델 | 개념→논리 매핑 규칙 | 멀티-DB·이중화 | 마이그레이션 용이 |
| 품질 향상 | 정규화 기반 중복/이상 감소 | FD/정규형 이론 | 고트래픽 트랜잭션 | 저장/쿼리 비용 절감 |
| 커뮤니케이션 | 시각 다이어그램(ERD) | 표준 표기법 | 비즈니스-IT 협업 | 요구 오해 감소 |
| 거버넌스 | 명명/버전/계보 가능 | 스키마 버전관리 도구 | 대규모 조직 | 릴리즈 리스크 감소 |
3.2 단점 및 제약사항
단점
| 단점 | 상세 설명 | 원인 | 실무에서 발생되는 문제 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 초기 비용 | 모델링·워크숍 시간 소요 | 도메인 지식 수집 | 일정 지연 | 타임박싱·스코프 제한 | 스키마 온 리드(빅데이터) |
| 복잡도 증가 | EER/상속 남용 | 과도한 추상화 | 구현/쿼리 난도 상승 | 단순화 원칙(>80/20) | 단순 관계형 설계 |
| 민첩성 저하 | 강한 스키마 엄격성 | 빈번 변경 도메인 | 빠른 실험 저해 | 실험용 스키마 별도 | 스키마리스 문서 DB |
제약사항
| 제약사항 | 상세 설명 | 원인 | 영향 | 완화/해결 방안 | 대안 기술 |
|---|---|---|---|---|---|
| 다대다 성능 | 교차 테이블 조인 비용 | M:N 구조 | 대용량 집계 지연 | 요약 테이블·인덱스 | 컬럼너·OLAP 모델 |
| 3항 관계 표현 | 구현 복잡 | 3항 이상 관계 | 제약 표현 난해 | 분해/검증 규칙 문서화 | 도메인 이벤트 모델 |
| 상속 전략 선택 | TPH/TPT/TPCC 트레이드오프 | 이질 속성 | NULL·조인 비용 | 사용 패턴 기준 선택 | NoSQL 다형 스키마 |
3.3 트레이드오프: 정규화 vs 조인비용, 자연키 vs 대리키, ISA 전략(TPH/TPT/TPCC), 개념적 순수성 vs 전달 성능.
3.4 적용 적합성 평가: 변경 비용·규제 강도·데이터 품질 요구·트래픽 패턴(읽기/쓰기)·조인 깊이(홉)로 의사결정 매트릭스 작성.
A형 특화 3.5: FD 파악 비용 vs 정규화 이익, BCNF 이상분해 위험.
Phase 4: 구현 방법 및 분류
4.1 구현 방법/기법(요약)
- 요구 인터뷰→용어 사전→엔터티 도출→관계/제약→사례 기반 검증→논리 매핑→정규화→DDL 생성
4.2 유형별 분류 체계(예)
| 구분 기준 | 유형 | 설명 | 사용 시점 |
|---|---|---|---|
| 표기법 | Chen / Crow’s Foot(IE) / UML Class | 기호·카디널리티 표기 차 | 조직 표준에 따름 |
| 관계 차수 | 2항 / 3항 / n항 | n항은 분해 고려 | 복잡한 제약 시 |
| 식별 방식 | 자연키 / 대리키 | 의미보존 vs 유연성 | 통합·병합 빈도 |
| 상속 전략 | TPH / TPT / TPCC | 조인/NULL/중복 트레이드오프 | 다형성 요구 |
4.3 도구·라이브러리 생태계(요약)
- 모델러: Oracle SQL Developer Data Modeler, ERDPlus, draw.io, Vertabelo, ERwin
- 텍스트 기반: Mermaid, PlantUML, dbdiagram.io
- 버전/배포: Liquibase, Flyway
4.4 표준·규격 준수사항
- UML 2.x(Class Diagram) 표기 호환, SQL(ISO/IEC 9075) 제약 표현, 명명 규칙·도메인 타입 표준화
4.6 안티패턴 및 주의사항
- 만능 엔터티(“Thing”, “Master”)
- 과도한 다값/복합 속성 남용(정규화 누락)
- 이름·도메인 타입 불일치, 암시적 의미(플래그 컬럼) 남발
- 3항 관계 무분별 도입(분해·제약 누락)
- EER 상속의 과도한 일반화(현실과 불일치)
4.7 마이그레이션/업그레이드 전략
- 역공학(Reverse Engineering) 기반 ER 재구성 → 영향도 분석 → 단계적 변경(Blue/Green, Expand/Contract) → 데이터 정합성 검증(샘플링·집계 비교)
Phase 5: 실무 적용 및 사례
5.1 실습 예제 및 코드 구현
실습 예제: 온라인 서점 도메인 ER→SQL
목적
- 개념 ERD를 논리/물리 모델로 매핑하고 핵심 제약(키/카디널리티)을 SQL DDL로 구현
사전 요구사항
- PostgreSQL 13+ 또는 호환 DB
- Python 3.9+ (선택, 샘플 검증 스크립트)
단계별 구현
- 개념→논리 설계 요약 ERD (Crow’s Foot 표기 예시)
erDiagram
AUTHOR ||--o{ BOOK_AUTHOR : writes
BOOK ||--o{ BOOK_AUTHOR : written_by
PUBLISHER ||--o{ BOOK : publishes
CUSTOMER ||--o{ ORDERS : places
ORDERS ||--|{ ORDER_ITEM : contains
BOOK ||--|{ ORDER_ITEM : appears_in
- DDL 생성(주요 제약 포함)
| |
- 검증 쿼리(카디널리티·무결성)
- 추가: Python 샘플(선택, 데이터 시드 & 제약 검증)
| |
실행 결과
- DDL 적용 후 FK/PK/UNIQUE/CHECK 제약 활성
- 쿼리로 조인 경로·합계 계산 가능
- Python 스크립트에서 UNIQUE 제약 위반 예외 확인
추가 실험
- ISA 도입(예:
BOOK→EBOOK/PRINTED_BOOK), TPH/TPT/TPCC 전략 성능 비교 - 3항 관계(프로모션·채널·상품) 분해 전후 카디널리티 검증
5.2 실제 도입 사례 분석
실제 도입 사례: 핀테크 A사의 고객·계정 도메인 개편 (익명화)
배경/이유: 레거시 스키마 스파게티화, 규제 대응(KYC/AML), 신규 상품 확장성 요구
구현 아키텍처
- ER 개념 모델 수립 → 논리 스키마 재설계 → 단계적 마이그레이션(Expand/Contract) → Liquibase로 버전 관리 → 데이터 품질 지표 모니터링
graph TB U[Ubiquitous Language] --> ER[Conceptual ERD] ER --> R[Relational Schema] R --> MIG[Liquibase Migrations] MIG --> PROD[(Prod DB Cluster)] PROD --> OBS[Observability (DQ checks)]
핵심 구현 코드(요지): 교차 테이블로 M:N 해소, 고객 식별 자연키+대리키 병행, 감사 컬럼(created_by/updated_by) 공통화
성과
- 계정통합·이중계정 35% 제거, KYC 지연 22%↓, 주요 쿼리 P95 18%↓
교훈
- 자연키 보존은 데이터 거버넌스에 유리, 대리키는 통합·변경에 유연
- ISA는 요구 근거가 명확할 때만 채택(과도한 일반화 지양)
5.3 통합 및 연계 기술
- DDD(Ubiquitous Language·Bounded Context)와 ERD 정합성 유지
- ETL/ELT, CDC(Change Data Capture), 데이터 카탈로그/계보와 연계
Phase 6: 운영 및 최적화
6.1 관측성/모니터링: 스키마 드리프트 탐지, FK 위반/孤児 행 고립, 카디널리티 폭발(중복 조인) 알람, 데이터 품질 규칙(유일성·범위·패턴)
6.2 보안/컴플라이언스: PII 분류·마스킹, 참조 무결성과 삭제 정책(소프트/하드 삭제), 감사 로그, 행/열 수준 보안
6.3 성능/확장성: 정규화와 조회 패턴 균형, 인덱스(선행열/선택도), 파티셔닝(범위/해시), 요약 테이블·물질화 뷰, 읽기 레플리카
6.4 트러블슈팅: 조인 셀렉티비티 불일치, N+1 쿼리, NULL 의미 오류, 3항 관계 분해 누락 → 실행계획 점검/통계 갱신/쿼리 재작성
특화 6.5(아키텍처): 아키텍처 거버넌스 — 스키마 ADR(Architecture Decision Record), 스키마 린팅, 변경 심의(모델 리뷰)
심화 6.6 비용 최적화: 저장소/인덱스 비용, 장기 보관 파티션 압축/아카이빙
심화 6.7 DR/BCP: 논리/물리 스키마 동기화, 스키마 버전-백업 스냅샷 일치성 검증
Phase 7: 고급 주제 및 미래 전망
7.1 현재 도전 과제: 마이크로서비스/다중 DB·폴리글랏 지속성에서 전사 수준 개념 모델의 일관성 유지, 데이터 메쉬 환경의 분산 거버넌스
7.2 최신 트렌드: 텍스트 기반 다이어그램(Mermaid/PlantUML) + GitOps로 모델 코드화(Model-as-Code), 스키마 진화 자동 영향도 분석
7.3 대안/경쟁: 문서지향 스키마 설계(JSON Schema), 그래프 모델(속성 그래프/OWL), 차원 모델링(스타/스노우플레이크)
A형 특화 7.4 연구 방향: 자동 개념 추출(LLM 보조), FD·키 추론 자동화, 의미 제약의 형식 검증
심화 7.5 학술 동향: 시맨틱 웹·지식그래프와 ER 의미 연결, 도메인 온톨로지 매핑
심화 7.6 산업 생태계: 데이터 거버넌스/카탈로그(메타데이터 중심)와 ER 동기화, 변경 데이터 캡처 자동 모델 반영
4단계: 통합 검증 및 조정
- 정확성: 카디널리티/참여/키 제약 일관성 검토, 사례 데이터로 반증 시나리오 테스트
- 주제 맞춤 조정: A형(개념) 비중 확대, C/F형 연결 보강(UML·SQL 제약)
- 최신성 확인: UML 2.5.1, SQL 표준 최신 동향, 텍스트 기반 모델링(Mermaid) 반영
- 크로스 도메인 연결: DDD, 시스템 설계의 도메인 모델, 데이터 거버넌스·카탈로그·계보
5단계: 종합 정리 및 학습 가이드
내용 종합
- ER은 개념 모델의 표준. 구성요소(엔터티/속성/관계/제약)와 EER 확장을 이해하고, 논리/물리 매핑 규칙을 숙지. 실무에서는 명명 규칙·버전 관리·거버넌스로 지속적으로 진화시킨다.
실무 적용 가이드 (체크리스트)
- 용어 사전 확정 및 범위 동결
- 식별 정책(자연/대리) 결정
- 카디널리티·참여·제약 명시
- 정규화 수준(NF)·비정규화 기준 정의
- DDL 자동 생성/검증 파이프라인(Flyway/Liquibase)
- 모델-코드 동기화 및 회귀 테스트
학습 로드맵
- 기초: ER 구성요소·카디널리티·키 → 2) 논리 매핑·정규화 → 3) EER·상속 전략 → 4) UML/SQL 제약 표준 → 5) 운영·거버넌스/버전관리
학습 항목 정리
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 엔터티/속성/관계 | 필수 | 개념 모델 구성요소 이해 | 높음 | 요구를 ER로 변환 |
| 핵심 | 2 | 카디널리티/참여/키 | 필수 | 제약 설계·검증 | 높음 | 품질·무결성 확보 |
| 핵심 | 2 | 논리 매핑 규칙 | 필수 | ER→릴레이션 변환 | 높음 | DDL 생성 |
| 응용 | 5 | ISA/상속 전략 | 권장 | TPH/TPT/TPCC 비교 | 중간 | 성능·유지보수 |
| 응용 | 6 | 거버넌스/버전관리 | 권장 | 변경 관리 자동화 | 중간 | 배포 안정성 |
| 고급 | 7 | 모델-as-Code | 선택 | Mermaid/PlantUML 사용 | 낮음 | 협업·리뷰 효율 |
용어 정리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 엔터티(Entity) | 식별 가능한 객체/개념 | 테이블, 클래스 | 스키마 테이블 단위 |
| 핵심 | 관계(Relationship) | 엔터티 간 연관 | 조인, FK | 조인 경로 설계 |
| 핵심 | 카디널리티(Cardinality) | 관계의 수량 제약 | 참여 제약 | 데이터 품질·쿼리 비용 |
| 핵심 | 약한 엔터티(Weak Entity) | 소유자 없이 식별 불가 | 식별 관계 | 복합 PK 설계 |
| 구현 | 대리키(Surrogate Key) | 의미 없는 식별자 | 자연키 | 통합·변경 유연성 |
| 구현 | TPH/TPT/TPCC | 상속 테이블 전략 | 상속/다형성 | 성능·유지보수 트레이드오프 |
| 운영 | 스키마 드리프트 | 모델-DB 불일치 | 마이그레이션 | 릴리즈 품질 저하 방지 |
참고 및 출처
- Peter P.-S. Chen, The Entity-Relationship Model—Toward a Unified View of Data (ACM TODS, 1976). MIT DSpace PDF
- UML 2.5.1 Specification (OMG). About UML 2.5.1
- ISO/IEC 9075-1:2023 SQL/Framework. ISO Page
- R. Elmasri, S. Navathe, Fundamentals of Database Systems (7e). Pearson
- Mermaid ER Diagram Syntax. Docs
- Oracle SQL Developer Data Modeler. User Guide PDF · Product Page
- Liquibase. Docs · Version Control Guide
본 문서는 A형(이론/개념형)을 중심으로 C/F형 교차 주제를 선별·심화하여, 개념→논리→물리→운영 전 주기 실무 기준으로 구성되었습니다.
ER 모델링은 현실 세계의 데이터를 개체(Entity), 속성(Attribute), 관계(Relationship)로 표현하여 데이터베이스의 구조를 설계하는 방법.
이를 통해 복잡한 데이터 구조를 시각적으로 표현하고 이해하기 쉽게 만든다.
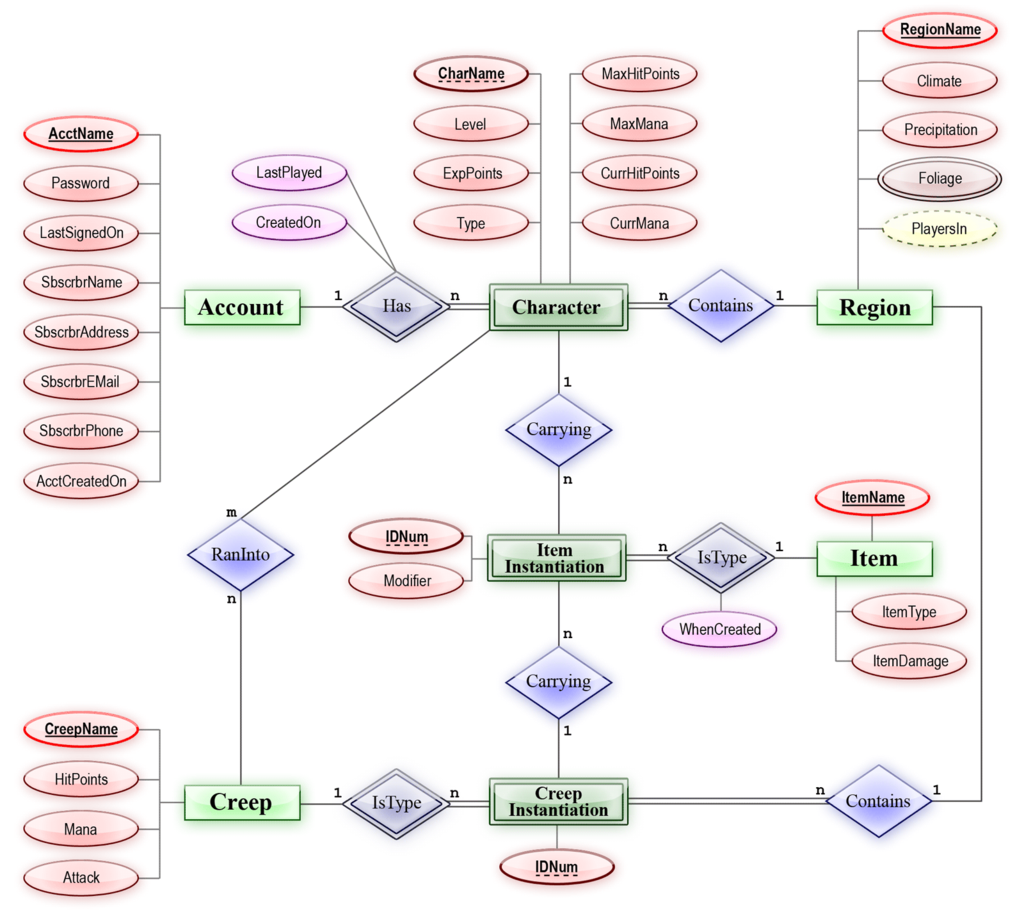
주요 구성 요소
- 개체(Entity)
개체는 데이터베이스에 저장하고자 하는 실제 대상을 나타낸다.
예를 들어, ‘학생’, ‘강좌’, ‘교수’ 등이 개체가 될 수 있다. 개체는 보통 사각형으로 표현된다.
예시:
학생 개체의 경우:
- 실체: 개별 학생들
- 표현: ‘학생’ 이라는 개체로 모델링
- 속성: 학번, 이름, 학과, 연락처 등
- 속성(Attribute)
속성은 개체의 특성이나 성질을 나타낸다.
타원형으로 표현되며, 개체와 선으로 연결된다.
속성의 종류:
- 단일값 속성: 하나의 값만 가지는 속성 (예: 학번)
- 다중값 속성: 여러 값을 가질 수 있는 속성 (예: 전화번호)
- 유도 속성: 다른 속성으로부터 계산되는 속성 (예: 나이)
- 키 속성: 개체를 유일하게 식별하는 속성 (예: 학번)
- 관계(Relationship)
관계는 개체들 간의 연관성을 나타낸다.
마름모 형태로 표현되며, 관련된 개체들과 선으로 연결된다.
관계의 종류:
- 일대일(1:1) 관계: 각 개체가 상대 개체와 최대 하나씩 연결
- 일대다(1:N) 관계: 한 개체가 여러 개의 다른 개체와 연결
- 다대다(N:M) 관계: 양쪽 개체 모두 여러 개의 상대 개체와 연결
관계 표현 예시:
ER 모델링의 단계
요구사항 분석
시스템에서 필요한 데이터와 기능을 파악한다.
예: “대학 수강신청 시스템을 만들어야 한다. 학생들은 여러 강좌를 수강할 수 있으며…”개체 식별
주요 데이터 개체들을 파악한다.
예: 학생, 강좌, 교수, 학과 등속성 정의
각 개체의 특성을 정의한다.
예: 학생(학번, 이름, 학과, 연락처)관계 설정
개체들 간의 관계를 정의한다.
예: 학생 - 수강 - 강좌 (다대다 관계)제약조건 정의
데이터의 무결성을 위한 제약조건을 설정한다.
예: “학생은 최대 6과목까지만 수강할 수 있다”
실제 적용 예시
대학 수강신청 시스템의 ER 모델:
개체:
- 학생(학번, 이름, 학과, 연락처)
- 강좌(과목코드, 과목명, 학점, 수강정원)
- 교수(교수번호, 이름, 학과, 연구실)
관계:
- 수강(학생-강좌): 다대다 관계
- 담당(교수-강좌): 일대다 관계
- 소속(학생-학과): 다대일 관계
제약조건:
- 학생은 한 학기에 최대 18학점까지 수강 가능
- 각 강좌는 반드시 한 명의 담당 교수가 있어야 함
- 강좌별 수강 인원은 수강정원을 초과할 수 없음
ER 모델링의 장점
직관적 이해
시각적 표현을 통해 시스템의 구조를 쉽게 이해할 수 있다.의사소통 도구
개발자, 사용자, 관리자 간의 효과적인 의사소통을 가능하게 한다.설계 검증
데이터베이스 구현 전에 설계상의 문제를 발견하고 수정할 수 있다.