Threads
스레드 (Thread) 는 하나의 프로세스 내에서 여러 실행 흐름을 동시에 수행할 수 있도록 하는 경량 실행 단위다.
자원을 공유하면서도 병렬로 처리할 수 있어 CPU 사용률을 극대화하며, 멀티코어 환경에서 반응성과 처리 성능 향상에 핵심적인 역할을 한다.
생성, 종료, 동기화, 스케줄링 등의 관리가 비교적 효율적이지만, 경쟁 상태, 데드락 등의 문제가 발생할 수 있어 주의가 필요하다.
웹 서버, 실시간 시스템, 데이터 처리 등 다양한 분야에서 쓰이며, 현대 소프트웨어에서 동시성과 병렬성을 구현하는 기반 기술로 활용된다.
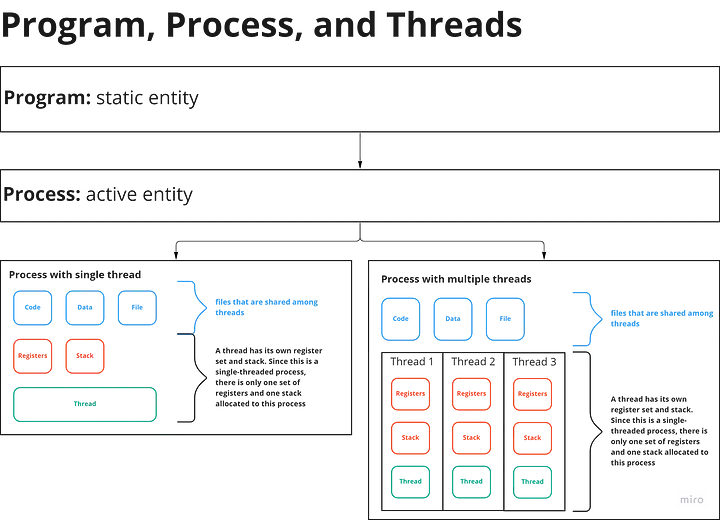
등장 배경 및 발전 과정
등장 배경
초기 컴퓨터 시스템은 단일 실행 흐름 기반의 순차 처리 방식으로, 하나의 작업이 완료되어야 다음 작업이 수행되는 구조였다. 그러나 운영체제의 발전과 함께 동시성 처리의 필요성이 대두되면서, 멀티프로세싱 구조가 도입되었고, 프로세스 내에서도 독립적인 실행 흐름이 필요한 상황이 많아지며 스레드 (Thread) 개념이 등장하게 되었다.
또한, 멀티코어 CPU 의 확산, 입출력 지연의 병목 해소, 대용량 데이터 처리 등의 요구가 커지면서, 스레드는 자원 효율성과 응답성 확보를 위한 핵심 메커니즘으로 자리잡게 되었다.
발전 과정
| 시기 | 발전 단계 | 주요 내용 |
|---|---|---|
| 1960 년대 | 초기 개념 도입 | IBM OS/360 에서 Task 구조 등장. 프로세스 개념보다 가벼운 실행 단위로 활용됨. |
| 1970~1980 년대 | 동시성 이론 정립 | 다익스트라의 세마포어, 뮤텍스 등 동기화 알고리즘 확립. UNIX 에서 사용자 수준 스레드 실험적 구현. |
| 1980 년대 후반 | Lightweight Process (LWP) 도입 | UNIX System V 에서 사용자 ↔ 커널 중간 계층으로 LWP 등장 |
| 1990 년대 | 실용화와 표준화 | POSIX Threads(Pthreads) 표준화. Windows NT, Solaris, Linux 등에서 커널 스레드 기반 멀티스레딩 제공 |
| 2000 년대 이후 | 병렬 프로그래밍 확대 | 멀티코어 프로세서 대중화 → 고성능 병렬 애플리케이션에서 스레드 활용 급증 |
| 최근 | 고수준 언어와 경량 스레드 | Java 의 Virtual Thread(Project Loom), Go 의 Goroutine, Python 의 Coroutine 등 경량 스레드 추상화 모델이 등장하며 효율성과 확장성 향상 |
목적 및 필요성
목적
| 항목 | 설명 |
|---|---|
| 병렬 처리 | 다수의 작업을 동시에 실행하여 전체 처리량을 증가시킴 |
| 반응성 향상 | UI 및 서버 등에서 사용자 요청에 대한 빠른 응답 보장 |
| 자원 효율성 | 메모리 및 생성 비용이 높은 프로세스보다 경제적 |
| 확장성 | 스레드 풀 등을 활용해 고부하 요청에 유연하게 대응 가능 |
| 작업 분할 | 복잡한 작업을 다수의 스레드로 나눠 독립 실행 가능 |
| 실행 제어 | 사용자/커널 수준의 스케줄링으로 유연한 실행 관리 가능 |
필요성
| 항목 | 설명 |
|---|---|
| 멀티코어 시대의 대응 | CPU 코어 수 증가에 따라 병렬 처리가 기본 전제가 됨 |
| 사용자 경험 중심 시대 | 애플리케이션의 지연 없는 반응이 기본 품질 요건이 됨 |
| 대규모 트래픽 시스템 증가 | 수많은 클라이언트 요청을 효율적으로 병렬 처리해야 함 |
| 복잡한 작업 구조화 | 작업을 잘게 나누고 동시에 실행함으로써 설계·유지보수 용이 |
| 비동기 시스템 연계 | 이벤트 루프, 논블로킹 I/O, Future 등과 조합 가능 |
핵심 개념
스레드 (Thread) 의 정의와 본질
스레드는 프로세스 내에서 실행되는 최소 실행 단위로, 각 스레드는 개별적인 스택 (Stack), 레지스터, 프로그램 카운터 (PC) 를 가지며, 프로세스의 코드, 데이터, 힙 등 메모리 공간은 공유한다.
이를 통해 스레드는 낮은 비용으로 병렬성 및 비동기 처리를 가능하게 한다.
스레드는 독립된 실행 흐름을 가지면서 자원을 공유하므로, 동기화 문제가 필연적으로 발생하며 이에 대한 해결이 필수적이다.
동시성 (Concurrency) vs. 병렬성 (Parallelism)
- 동시성: 여러 작업이 시간 분할 방식으로 실행되어 동시에 동작하는 것처럼 보이는 구조 (e.g., 싱글코어에서 인터리빙)
- 병렬성: 여러 작업이 실제로 동시에 실행되는 구조 (e.g., 멀티코어에서 여러 스레드 병렬 실행)
스레드 상태 모델
스레드는 다음과 같은 상태를 가지며, OS 스케줄러가 이 상태 전환을 관리한다:
- New: 생성된 초기 상태
- Runnable: 실행 준비 완료 상태 (스케줄 대기 중)
- Running: CPU 를 점유하고 실행 중
- Blocked/Waiting: 입출력 또는 동기화 대기 상태
- Terminated: 실행 종료
메모리 모델과 자원 공유
- 모든 스레드는 프로세스의 가상 메모리 공간 (코드/데이터/힙) 을 공유한다.
- 단, 스택 영역은 독립적으로 관리됨.
- 자원 공유는 효율을 높이지만, 경쟁 조건 (Race Condition), 데이터 불일치, 데드락 등의 동기화 문제가 수반됨.
사용자 수준 vs. 커널 수준 스레드
| 구분 | 사용자 수준 (ULT) | 커널 수준 (KLT) |
|---|---|---|
| 관리 주체 | 사용자 라이브러리 | 운영체제 커널 |
| 성능 | 전환 빠름, 비용 낮음 | 병렬 실행 가능, 전환 비용 높음 |
| 단점 | 전체 스레드 블로킹 가능성 | 생성/관리 오버헤드 큼 |
| 예시 | Python greenlet, 일부 코루틴 | POSIX Thread, Windows Thread |
핵심 개념과 실무 구현 연관성
| 영역 | 실무 연관성 |
|---|---|
| 성능 최적화 | 멀티코어 기반 CPU 자원을 병렬 사용 → 전체 처리량 (Throughput) 향상 |
| 응답성 개선 | UI 응답, 서버의 요청 처리 지연 감소 (비동기 백그라운드 처리) |
| 동기화 전략 | Mutex, Semaphore, Read-Write Lock, Lock-Free 등 사용 필수 |
| 리소스 효율성 | 스레드는 프로세스보다 경량 → 서버 리소스 절약 (Thread Pool 적용) |
| 스레드 안전 (Thread Safety) | 동시 접근 제어 → 상태 공유 객체 동기화, 불변 객체 사용 등 |
| 예외 처리 및 디버깅 | 스레드 디버깅은 어렵고 경쟁 상태/데드락 진단 필요 (툴 활용 권장) |
| 현대적 활용 | Java Virtual Threads (Project Loom), Go 의 Goroutine, Python 의 asyncio 등은 스레드를 추상화한 경량 동시성 모델을 제공 |
주요 기능 및 역할
| 기능 (Function) | 설명 | 관련 역할 (Role) |
|---|---|---|
| 독립적 실행 흐름 관리 | 각 스레드는 고유한 명령어 흐름을 가지고 병렬로 실행됨 | 작업 분할, 병렬 처리, 반응성 향상 |
| 공유 메모리 접근 | 동일 프로세스 내 다른 스레드와 코드, 데이터, 힙 공유 가능 | 자원 절약, 협업 처리, 데이터 일관성 유지 |
| 스케줄링 지원 | 커널 또는 사용자 레벨에서 CPU 시간 할당을 조정 | 우선순위 실행, 리소스 배분 최적화 |
| 동기화 메커니즘 지원 | 락, 세마포어, 모니터, 조건 변수 등을 통해 자원 접근을 안전하게 제어 | 경쟁 조건 방지, 일관성 유지, 데드락 예방 |
| TLS(Thread Local Storage) 제공 | 스레드 고유 데이터 공간을 확보하여 비공유 상태 유지 가능 | 독립성 보장, 스레드 기반 캐싱, 병렬 처리 안전성 강화 |
| 상태 전이 관리 (Lifecycle) | 생성, 대기, 실행, 종료 등 상태 기반 관리 가능 | 안정적 실행 흐름 제어, 자원 누수 방지, 오류 관리 |
| 우선순위 조정 기능 | 특정 스레드에 더 많은 실행 기회를 부여하여 긴급 작업 처리 가능 | 실시간 처리, 사용자 인터랙션 우선 대응 |
| 에러 격리 (Partial Failure) | 일부 스레드 장애가 전체 애플리케이션 중단으로 이어지지 않도록 처리 가능 | 시스템 안정성 확보, 장애 대응 유연성 |
스레드는 독립 실행 흐름, 공유 자원 접근, 스케줄링, 동기화 등 다양한 기능을 제공하며, 이를 기반으로 병렬 작업 처리, 자원 효율 향상, 사용자 반응성 강화 등의 역할을 수행한다.
특히 작업 분할, 백그라운드 처리, UI 블로킹 방지 등은 현대 애플리케이션의 성능과 사용자 경험에 직접적인 영향을 미친다.
또한 TLS, 우선순위 조정, 상태 전이 제어 등은 스레드 실행의 정밀한 제어를 가능하게 하여 확장성과 안정성을 동시에 확보하는 데 기여한다.
특징
| 카테고리 | 특징 | 설명 | 기반 개념 / 구현 요소 |
|---|---|---|---|
| 구조적 특징 | 경량성 (Lightweight) | 프로세스보다 생성/종료 비용 낮고, 문맥 전환 비용도 적음 | 스택/레지스터만 별도 유지 |
| 실행 컨텍스트의 독립성 | 각 스레드는 개별 스택과 레지스터, 프로그램 카운터 보유 | 독립 실행 흐름 유지 | |
| 자원 관리 | 자원 공유성 | 힙, 데이터, 코드 영역 등 프로세스 자원 공유 → 빠른 통신과 자원 사용 가능 | 단일 주소 공간 공유 |
| 유연한 확장성 | 스레드 수 증가가 상대적으로 쉬움. 동적 생성/종료, Thread Pool 구성 가능 | 동적 스레드 관리 | |
| 실행 특성 | 동시성 및 병렬성 | 멀티코어 및 시분할 기반 병렬 처리 가능. 스케줄러에 따라 병렬 실행 여부 결정 | 멀티코어 활용 |
| 스케줄링 가능성 | OS 기반 스케줄링 지원. 우선순위 기반, 라운드 로빈 등 다양한 정책 적용 가능 | OS 스케줄러 | |
| 오류 처리 | 낮은 Fault Isolation | 하나의 스레드 실패가 전체 프로세스에 영향을 줄 수 있음 | 프로세스 내 공유 구조 |
| 동기화 요구 | 동기화 필요성 | 자원 공유로 인해 Race Condition, Deadlock 등 발생 가능. Lock 기반 보호 필요 | Mutex, Semaphore 등 |
구조적 특징: 스레드는 프로세스보다 훨씬 가볍고, 각자의 실행 컨텍스트를 유지하므로 빠른 전환과 높은 확장성을 제공한다.
자원 관리: 동일 프로세스 내 자원 공유 구조 덕분에 빠른 데이터 교환이 가능하지만, 그만큼 동기화에 신중해야 한다.
실행 특성: 스레드는 병렬성과 동시성을 모두 구현할 수 있으며, OS 의 스케줄링 정책에 따라 다양한 실행 흐름을 지원한다.
오류 처리: 하나의 스레드 오류가 전체 애플리케이션에 영향을 줄 수 있어 적절한 예외 처리와 복원 전략이 필요하다.
동기화 요구: 자원 공유 구조로 인해 동기화는 필수이며, 락 메커니즘 없이 안전한 실행은 불가능하다.
핵심 원칙
Threads 를 구현하거나 운용할 때 지켜야 할 핵심 원칙은 크게 세 가지 축으로 구분된다:
- 정확성 (Consistency)
- 안정성 (Safety)
- 효율성 (Efficiency).
이들 원칙은 메모리 모델, 스케줄링 전략, 예외 처리 및 자원 분배까지 모든 레벨에서 적용된다.
| 카테고리 | 원칙 | 설명 |
|---|---|---|
| 💡 정확성 (Consistency) | Atomicity (원자성) | 연산이 완전히 수행되거나 전혀 수행되지 않도록 보장 |
| Visibility (가시성) | 한 스레드의 변경 사항이 다른 스레드에서 즉시 반영됨 | |
| Ordering (순서성) | 메모리 연산이 예측 가능한 순서로 실행되도록 보장 | |
| 🛡️ 안정성 (Safety) | Mutual Exclusion (상호 배제) | 공유 자원은 한 번에 하나의 스레드만 접근 가능 |
| Deadlock Prevention (데드락 방지) | 순환 대기 방지, 타임아웃 설정 등으로 데드락 회피 | |
| Failure Containment (에러 격리) | 스레드 오류가 전체 시스템에 영향을 주지 않도록 설계 | |
| ⚙️ 효율성 (Efficiency) | Minimal Sharing (공유 최소화) | 공유 자원을 줄여 경합 및 병목 최소화 |
| Scheduling Policy (스케줄링 정책) | 우선순위 기반, FIFO 등 정책에 따른 실행 효율 향상 | |
| Fairness (공정성) | 모든 스레드에 공평한 CPU 시간 분배 보장 | |
| Lock Granularity (락 범위 최적화) | 락의 범위를 적절히 조절하여 경합과 병목 방지 | |
| Thread Safety (스레드 안전성) | 다중 스레드 환경에서의 올바른 동작 보장 |
정확성은 모든 병행 환경에서 필수적인 기반이다. 연산의 원자성, 변경의 가시성, 실행 순서의 예측 가능성은 병렬 처리의 일관성을 확보하기 위한 핵심 조건이다. 특히 멀티코어 환경에서는 메모리 일관성과 가시성 확보가 중요하다.
안정성은 시스템이 비정상 상황에서도 예측 가능한 상태를 유지하게 만든다. 공유 자원에 대한 경쟁을 제어하고, 데드락 및 예외 상황이 전체 애플리케이션을 중단시키지 않도록 설계해야 한다. 특히 웹 서버나 실시간 시스템 등에서는 장애 고립 설계가 중요하다.
효율성은 성능 극대화와 관련되며, 자원 경합 최소화, 실행 스케줄링의 효율화, 스레드 간 공정한 자원 분배 등이 포함된다. 락의 범위를 줄이거나 Thread Local Storage 를 활용하는 전략은 병목을 줄이고 확장성을 높인다.
주요 원리 및 작동 방식
- 스레드는 독립적인 실행 컨텍스트를 갖고 공유 메모리 구조 내에서 병렬적으로 동작하며, 이를 통해 고성능 처리와 응답성 향상이 가능하다.
- 스레드의 상태 전이는 스케줄러, 자원 접근, 동기화 메커니즘에 따라 정해지며, 다양한 스케줄링 정책이 이를 제어한다.
- 사용자 수준과 커널 수준 스레드는 성능, 병렬성, 제어 권한 측면에서 차이가 존재한다.
주요 원리 (스레드의 작동 개념과 스케줄링 원리)
실행 컨텍스트 분리와 메모리 공유
- 스레드는 독립적인 실행 컨텍스트 (PC, 레지스터, 스택) 를 갖는다.
- 코드, 데이터, 힙 메모리는 모든 스레드가 공유하므로, 동시 접근에 대한 동기화가 필수이다.
사용자/커널 수준 스레드
- 사용자 수준 스레드 (ULT): 사용자 공간에서 생성/스케줄링. 빠르지만 한 스레드 블로킹 시 전체 블로킹.
- 커널 수준 스레드 (KLT): 커널이 생성/관리. 병렬 실행 가능, 비용 높음.
스레드 스케줄링 방식
| 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| Cooperative | 스레드가 자발적으로 CPU 양보 | 단순 구현, 예측 가능 | 한 스레드가 양보 안 하면 시스템 정지 |
| Preemptive | OS 가 강제로 CPU 회수 | 응답성 우수, 병렬성 가능 | 복잡한 동기화, Race Condition 발생 가능 |
| Time Slicing | 각 스레드에 실행 시간 할당 | 균형 있는 실행 | context switch 오버헤드 존재 |
작동 원리 (상태 전이 및 실행 구조)
스레드는 아래와 같은 상태 전이 흐름을 따른다:
stateDiagram-v2
[*] --> New : 스레드 생성
New --> Runnable : start() 호출
Runnable --> Running : 스케줄러 선택
Running --> Runnable : 타임슬라이스 종료
Running --> Blocked : 락/IO 대기
Running --> Waiting : wait(), join()
Running --> Terminated : 작업 완료
Blocked --> Runnable : 락 획득, I/O 완료
Waiting --> Runnable : notify(), join 종료
Terminated --> [*]
작동 구조 (스레드와 프로세스 간 구조도)
flowchart LR
P[프로세스] --> T1[스레드 1]
P --> T2[스레드 2]
P --> T3[스레드 3]
T1 --> S1[스택 1]
T2 --> S2[스택 2]
T3 --> S3[스택 3]
P --> SHARED["공유 자원 (코드, 데이터, 힙)"]
T1 --> SHARED
T2 --> SHARED
T3 --> SHARED
설명: 각 스레드는 자신의 실행 컨텍스트를 가지되, 프로세스의 공유 메모리 공간을 함께 사용한다.
구조 및 아키텍처
스레드는 프로세스 내에서 독립적인 실행 흐름을 가지며, Program Counter, Stack, Register Set, TCB 등의 필수 요소로 구성된다. 각 스레드는 고유한 스택과 실행 상태를 유지하며, 프로세스의 코드, 데이터, 힙 등을 공유한다. 또한, 필요에 따라 TLS를 통해 독립적인 전역 데이터를 사용할 수 있다.
flowchart TB
subgraph Process["📦 Process (단일 주소 공간)"]
direction TB
Code["Code Segment (공유)"]
Data["Data Segment (공유)"]
Heap["Heap (공유)"]
subgraph Thread1["🧵 Thread 1"]
PC1[Program Counter]
Reg1[Register Set]
Stack1[Stack]
TLS1[Thread Local Storage]
TCB1[Thread Control Block]
end
subgraph Thread2["🧵 Thread 2"]
PC2[Program Counter]
Reg2[Register Set]
Stack2[Stack]
TLS2[Thread Local Storage]
TCB2[Thread Control Block]
end
subgraph Thread3["🧵 Thread 3"]
PC3[Program Counter]
Reg3[Register Set]
Stack3[Stack]
TLS3[Thread Local Storage]
TCB3[Thread Control Block]
end
end
Scheduler[⚙️ Scheduler]
Scheduler --> TCB1
Scheduler --> TCB2
Scheduler --> TCB3
Heap --> Stack1
Heap --> Stack2
Heap --> Stack3
구성 요소
| 구성 요소 | 설명 | 필수 여부 | 공유 여부 |
|---|---|---|---|
| Thread ID | 스레드 고유 식별자 | 필수 | ✖ |
| Program Counter | 다음 명령어 주소 추적 | 필수 | ✖ |
| Stack | 함수 호출, 지역 변수 저장 | 필수 | ✖ |
| Register Set | 레지스터 값 저장 및 복원 | 필수 | ✖ |
| TCB (Thread Control Block) | 상태, 우선순위, 문맥 정보 포함 | 필수 | ✖ |
| Scheduler | 스레드 실행 시점 제어 | 필수 | ✖ (커널 공유) |
| TLS (Thread Local Storage) | 스레드 전용 전역 변수 저장 공간 | 선택 | ✖ |
| Shared Resources | 힙, 전역 변수, 파일 핸들 등 | 선택 | ✔ |
구현 기법 및 방법
| 구현 기법 유형 | 정의 | 구성 요소 | 작동 원리 | 목적 | 사용 상황 | 주요 특징 |
|---|---|---|---|---|---|---|
| 사용자 수준 스레드 (ULT) | 커널의 개입 없이 사용자 공간에서 라이브러리로 관리되는 스레드 | 사용자 스케줄러, 사용자 공간 컨텍스트 | 모든 전환 및 스케줄링은 사용자 레벨에서 처리 | 빠른 전환, 커널 호출 회피 | Green Thread, Go, Python asyncio, 코루틴 기반 시스템 | 전환 빠름, 하나가 블록되면 전체 블록, 커널 병렬성 없음 |
| 커널 수준 스레드 (KLT) | 운영체제가 직접 생성, 관리, 스케줄링하는 스레드 | 커널 스케줄러, 시스템 콜, 커널 컨텍스트 | OS 가 각 스레드를 별도로 인식하고 병렬 스케줄링 | 병렬 실행, 자원 보호, 안정성 확보 | 대부분의 현대 운영체제 (Linux NPTL, Windows Thread 등) | 병렬성 보장, 비용 높음, context switch 느림 |
| 하이브리드 모델 (M:N) | 여러 사용자 스레드를 소수 커널 스레드에 매핑하는 구조 | 사용자 스케줄러 + 커널 스레드 | 사용자 스레드가 커널 스레드 풀과 M:N 관계로 연결 | 효율과 병렬성 동시 확보 | 과거 Solaris, Go 런타임 (GOMAXPROCS 설정), Java Virtual Threads (Loom) | 병렬성 + 유연성, 구조 복잡, 관리 어려움 |
사용자 수준 스레드 (ULT) - Python Asyncio
| |
async def는 사용자 공간에서 실행 흐름을 정의.await asyncio.sleep()은 명시적 CPU 양보이며, 이는 전형적인 Cooperative 스케줄링.- 실제 커널 스레드는 1 개만 사용되고, 내부적으로는 경량 사용자 스레드처럼 작동함.
커널 수준 스레드 (KLT) 구현 예시 - Python threading 모듈
Python 의 threading.Thread 는 실제로 OS 커널 수준의 스레드 (KLT) 를 사용한다.
- CPython 은 native thread 사용
| |
threading.Thread는 내부적으로 커널에 직접 등록되는 native thread를 사용함.time.sleep()은 커널 단에서 스케줄링 블로킹 발생 → 해당 스레드는 OS 스케줄러가 직접 관리함.- 각 스레드는 별도 커널 컨텍스트로 작동 → 멀티코어에서 진정한 병렬 실행 가능.
- 하나의 스레드가 블로킹되어도 나머지 스레드에는 영향 없음.
하이브리드 스레드 모델 (M:N) 구현 예시 - Go 의 Goroutine + GOMAXPROCS
Go 는 대표적인 M:N 스케줄링 기반 하이브리드 모델을 런타임 차원에서 제공한다.
- Go 언어 예시 (
Goroutine: 수천 개의 사용자 스레드를 수 개의 커널 스레드에 매핑)
| |
go worker()는 경량 사용자 스레드 (Goroutine) 를 생성함. (M)GOMAXPROCS(2)는 런타임에 최대 2 개의 커널 수준 스레드 (N) 사용 지시.- Go 런타임은 자체 스케줄러 (P-model: Processor, Machine, Goroutine) 를 통해
M:N스케줄링 수행. - 하나의 커널 스레드가 블로킹되면 다른 커널 스레드로 goroutine 을 이동시켜 실행 지속 → hybrid 구조.
장점
| 카테고리 | 항목 | 설명 |
|---|---|---|
| 성능 최적화 | 경량 실행 단위 | 프로세스 대비 빠른 생성/소멸 및 낮은 컨텍스트 전환 비용 |
| 자원 효율성 | 메모리 공간 공유 | 스레드 간 메모리 및 자원 공유로 전체 사용량 감소 |
| 반응성 향상 | UI/백그라운드 분리 실행 | UI 지연 없이 백그라운드 작업 처리 가능, 사용자 경험 개선 |
| 확장성 및 병렬성 | 멀티코어 병렬 처리 | CPU 코어를 활용한 병렬 작업 분산 처리 |
| 확장성 및 병렬성 | 스레드 풀 기반 작업 처리 | 스레드를 재사용해 고부하 상황에서 효율적 자원 운영 가능 |
| 통신 및 구조 관리 | 스레드 간 데이터 전달 용이 | 동일 프로세스 공간을 사용하므로 별도 IPC 없이도 빠르게 전달 가능 |
| 통신 및 구조 관리 | 코드 구조 분리 | 동시 작업 분리로 유지보수성과 테스트 용이성 향상 |
성능 최적화 측면에서 스레드는 프로세스보다 경량화되어 생성, 종료, 전환 비용이 적어 고빈도 작업 처리에 유리하다.
자원 효율성은 스레드들이 메모리와 파일 핸들 등을 공유함으로써 전체 자원 소모를 줄이는 데 기여하며, 동시에 컨텍스트 전환 시 비용도 절감된다.
반응성 향상은 UI 스레드와 백그라운드 스레드의 분리를 통해 사용자 경험을 저해하지 않고 비동기 작업을 처리할 수 있게 만든다.
확장성 및 병렬성은 스레드가 멀티코어 CPU 를 기반으로 병렬 작업을 분산 처리할 수 있게 하며, 스레드 풀 활용을 통해 서버 등에서 고부하 처리도 효과적으로 대응할 수 있다.
통신 및 구조 관리 측면에서는 스레드 간 데이터 교환이 매우 빠르고 간단하며, 이를 통해 코드의 모듈화와 유지보수성이 향상된다.
단점과 문제점 그리고 해결방안
단점 (구조적 또는 본질적 제약)
| 항목 | 설명 | 해결책 |
|---|---|---|
| 동기화 복잡성 | 공유 자원 접근 시 동시성 이슈 발생 가능성 높음 | Mutex, Semaphore, Atomic 연산, Lock-free 구조 도입 |
| 디버깅 및 분석의 어려움 | 병렬 실행 흐름의 비결정성으로 버그 재현 및 추적 어려움 | Thread sanitizer, trace log, event timeline 도구 |
| 데드락 위험 | 락 획득 순서 오류로 무한 대기 상태 발생 | 자원 순서 지정, Lock timeout, Deadlock 회피 알고리즘 |
| 스레드 오버헤드 | 과도한 스레드 생성으로 CPU 스케줄링/컨텍스트 스위칭 비용 증가 | Thread Pool, 스레드 수 제한, 워크 큐 방식 |
| 메모리 관리 이슈 | 스레드 간 참조 누수나 종료 실패로 인한 메모리 누수 | 가비지 컬렉터 활용, 스마트 포인터, 약한 참조 설계 |
| 우선순위 역전 문제 | 낮은 우선순위 스레드가 자원 점유 시 고우선 스레드 대기 | Priority Inheritance, Aging 기법 |
스레드는 본질적으로 자원을 공유하므로 동기화가 필수지만, 그로 인해 복잡성과 디버깅 어려움이 따라온다. 또한, 다량의 스레드가 생성되면 오버헤드가 발생하며, 메모리 관리나 우선순위 역전과 같은 구조적 문제가 수반될 수 있다. 이를 해결하려면 동기화 전략 강화, Thread Pool 운영, 우선순위 제어 등의 관리 기법이 요구된다.
문제점 (실행 중 발생하는 동작 문제)
| 항목 | 원인 | 영향 | 탐지/진단 | 예방 방법 | 해결 기법 |
|---|---|---|---|---|---|
| Race Condition | 동기화 누락 또는 설계 미스 | 데이터 불일치, 예측 불가 동작 | Thread sanitizer, 로그 분석 | Lock, Atomic 연산, 불변 객체 | Mutex, Lock-free queue |
| Deadlock | 순환 자원 요청, 락 순서 충돌 | 시스템 정지, 무한 대기 | 락 그래프 분석, Thread Dump | 자원 순서 정의, 타임아웃 락 | Deadlock 회피/탐지 알고리즘 |
| Starvation | 스레드 우선순위 불균형 | 특정 작업 영구 대기 | 스케줄링 로그 분석 | Fair Scheduler, Aging | 우선순위 조정, Preemption |
| 우선순위 역전 (Inversion) | 낮은 우선순위 스레드가 자원 선점 | 고우선 스레드 대기 지연 | 스케줄링 트레이서 | Priority Inheritance 적용 | 우선순위 승격 알고리즘 |
| 스레드 누수 | 종료 누락, 대기 중 단절 | 메모리 점유 증가 | Thread 상태 모니터링 | 종료 시점 명시, Join 적용 | WeakRef, Finalizer 설계 |
| 과도한 CPU 점유 | Busy wait, 락 충돌 반복 | CPU 부하 급증 | 이벤트 기반 모니터링 | 조건 변수 사용, Sleep 사용 | Spinlock 제거, Event 기반 설계 |
스레드 운영 시 실시간으로 발생할 수 있는 문제들은 대부분 자원 경쟁과 스케줄링 불균형에서 기인한다. Race Condition 은 동기화 미비로 발생하며, Deadlock 은 락 충돌로 인한 전체 시스템 정지를 유발한다. Starvation 과 우선순위 역전은 스레드 간 불공정한 자원 분배로 연결되며, 종료 누락이나 과도한 CPU 사용은 시스템 성능을 저하시킬 수 있다. 이를 방지하기 위한 진단 도구, 스케줄링 전략, 동기화 제어가 실무에서 필수적이다.
도전 과제
| 카테고리 | 과제명 | 주요 원인 및 설명 | 해결 또는 대응 방안 |
|---|---|---|---|
| 동기화 성능 및 안정성 | 고성능 동기화 및 Thread Safety | 락 경합, 원자성 부족 | 락리스 구조, CAS, Read-Write Lock, 무상태 설계 |
| 메모리 모델 및 일관성 | 메모리 일관성 문제 | 캐시 불일치, 재정렬 | 메모리 배리어, 원자 연산, 일관성 보장 메커니즘 |
| 확장성 및 실행 오버헤드 | 스레드 수 증가에 따른 병목 | 컨텍스트 스위칭 증가, 자원 경합 | 이벤트 기반 모델, 코루틴, 액터 기반 전환 |
| 관찰 가능성 및 디버깅 | Race Condition 및 추적 어려움 | 병렬성 증가로 인한 원인 추적 곤란 | Trace, 로그 상관 분석, Visual Debugger, APM |
| 자원/에너지 최적화 | 실행 환경 적응 및 발열/전력 제어 | CPU 부하 증가 및 Idle Thread 누적 | Adaptative Thread Pool, Energy-aware Scheduling |
| 스케일 아웃 한계 | 단일 시스템 내 처리 한계 | Thread 자원 고갈, CPU 한계 | 분산 시스템, 멀티 프로세스 전환 구조 설계 |
| 에러 격리 | 스레드 장애 전파 문제 | 단일 프로세스 내 전체 영향을 줌 | 스레드 단위 격리, 비동기 오류 핸들링 구조 |
동기화 성능 및 안정성은 병렬 환경에서의 핵심 과제로, 락 경합을 줄이고 원자성 있는 연산을 보장하는 구조 설계가 필요하다. 락리스 자료구조나 CAS 같은 저오버헤드 동기화 방식이 점점 중요해지고 있다.
메모리 모델 및 일관성 문제는 멀티코어와 멀티캐시 구조에서 발생하며, 예측 불가능한 버그와 데이터 오류를 유발할 수 있다. 이를 해결하기 위한 메모리 배리어와 원자 연산 도입은 필수다.
확장성 및 실행 오버헤드는 스레드가 많아질수록 컨텍스트 스위칭과 메모리 소모가 증가하면서 병목이 발생한다. 이벤트 기반, 코루틴, 액터 모델 등이 대안이 된다.
관찰 가능성 및 디버깅은 병렬성 증가로 인해 버그를 재현하고 원인을 분석하는 일이 복잡해졌으며, 이를 해결하기 위한 로그 상관 분석, 트레이싱 시스템, 시각화 도구가 필요하다.
자원 및 에너지 최적화는 고성능 시스템에서 스레드가 에너지 소모 및 발열에 미치는 영향을 최소화하는 방안으로, 적응형 스레드 풀과 에너지 인식 스케줄링이 요구된다.
스케일 아웃 한계는 단일 머신 내 스레드 수 증가가 구조적 한계에 도달하는 경우로, 이를 분산 시스템으로 전환하거나 멀티 프로세스 구조로 보완해야 한다.
에러 격리는 스레드 하나의 장애가 전체 프로세스에 영향을 미치지 않도록 스레드 수준에서 오류를 캡슐화하고 독립적인 오류 복구 메커니즘을 갖춰야 한다.
분류 기준에 따른 종류 및 유형
| 카테고리 | 유형 | 설명 |
|---|---|---|
| 관리 주체 | 사용자 수준 스레드 (ULT) | 사용자 공간에서 라이브러리로 관리되며 커널에 인식되지 않음 |
| 커널 수준 스레드 (KLT) | 운영체제가 직접 생성, 관리하며 커널에 등록됨 | |
| 하이브리드 스레드 (M:N) | 사용자/커널 혼합, 여러 사용자 스레드가 커널 스레드에 매핑됨 | |
| 운영체제 지원 방식 | 1:1 모델 | 사용자 스레드 1 개 ↔ 커널 스레드 1 개 (ex. Linux NPTL) |
| N:1 모델 | 다수 사용자 스레드 ↔ 1 커널 스레드 (ex. Green Threads) | |
| M:N 모델 | M 사용자 스레드 ↔ N 커널 스레드 (ex. Go, Java Loom) | |
| 실행 방식 | 싱글 스레드 | 하나의 실행 흐름만 존재, 직렬 처리 |
| 멀티 스레드 | 여러 실행 흐름 병렬 또는 비동기 실행 가능 | |
| 실행 성격 | CPU 바운드 스레드 | 연산 중심, CPU 점유율 높음 |
| I/O 바운드 스레드 | 입출력 대기 중심, 대기 시간이 큼 | |
| 생명주기 | 데몬 스레드 | 백그라운드 작업용, 메인 스레드 종료 시 함께 종료됨 |
| 사용자 스레드 | 명시적 종료 필요, 메인 프로세스의 주 실행 단위 | |
| 우선순위 | 높은 우선순위 스레드 | 실시간 처리 또는 중요 이벤트 담당 |
| 낮은 우선순위 스레드 | 유지보수, 백업 등 비중요 작업 담당 |
관리 주체: 스레드가 어디에서 관리되는지에 따라 ULT, KLT, 하이브리드로 나뉜다. 커널이 인식하는지 여부에 따라 병렬성 확보와 비용이 다르며, 하이브리드는 최근 트렌드다.
운영체제 지원 방식: 스레드와 커널 간의 매핑 방식은 성능, 병렬성, 확장성에 큰 영향을 미친다. 1:1 은 단순하고 병렬성 강력, M:N 은 확장성과 효율성 뛰어남.
실행 방식: 싱글 스레드는 단일 흐름 기반으로 간단하나 확장성이 부족하며, 멀티 스레드는 병렬 처리 가능하나 동기화 관리가 필요하다.
실행 성격: CPU 바운드는 계산 중심, I/O 바운드는 대기 중심 작업에 적합하며 스케줄링 전략이 달라진다. 실제 서버 구성 시 유형 분리가 중요하다.
생명주기: 사용자 스레드는 명시적 종료가 필요하며, 데몬 스레드는 백그라운드용으로 종속적이며 자동 종료된다.
우선순위: 스레드의 스케줄링 결정에 큰 영향을 주며, 실시간 시스템이나 QoS 가 필요한 환경에서 중요하게 작용한다.
실무 사용 예시
| 카테고리 | 적용 사례 | 사용 기술/구조 | 목적 | 효과 |
|---|---|---|---|---|
| 웹 및 서버 아키텍처 | 웹 서버 (Apache, Nginx 등) | 스레드 풀, 논블로킹 I/O, worker thread | 동시 요청 처리 | 응답 속도 향상, 고부하 대응 |
| 사용자 인터페이스 처리 | 모바일 앱, 데스크탑 GUI 앱 | UI 스레드 + 백그라운드 작업자, 비동기 API | UX 개선, UI 블로킹 방지 | 사용자 반응성 향상 |
| 게임 및 실시간 엔진 | Unity, Unreal Engine | 렌더링, AI, 물리 연산용 멀티스레드 구조 | 실시간 처리, 부드러운 동작 | 프레임률 향상, 렌더링 지연 최소화 |
| 데이터 및 병렬 연산 | 과학 계산, 파이프라인 처리 | OpenMP, TBB, 생산자 - 소비자 패턴, 큐 구조 | 대규모 연산 병렬 처리 | 처리 속도 증가, 대기시간 감소 |
| DB 및 저장소 처리 | PostgreSQL, MySQL | worker thread, 커넥션 풀, 병렬 쿼리 | 동시 접속 처리, 쿼리 병렬화 | TPS 증가, 응답 속도 개선 |
| 멀티미디어 처리 | 비디오 인코딩/디코딩, 실시간 스트리밍 | GPU 가속, SIMD, 멀티스레드 디코더 구조 | 고속 데이터 처리, 병렬 인코딩 | 실시간 처리 가능, CPU 오버헤드 감소 |
웹 및 서버 아키텍처에서는 클라이언트 요청을 동시에 처리하기 위해 스레드 풀과 논블로킹 I/O 가 결합된다. 이 구조는 서버 처리량 (throughput) 증가와 응답 시간 단축에 매우 효과적이며, 대규모 트래픽 환경에서 반드시 사용된다.
사용자 인터페이스 처리에서는 UI 스레드와 백그라운드 스레드를 분리함으로써, 사용자 입력과 백엔드 연산이 동시에 수행되도록 한다. 이는 앱 반응성 (Responsiveness) 을 유지하는 핵심 기법이다.
게임 및 실시간 엔진에서는 렌더링, 물리 연산, AI 등을 각각 별도 스레드로 분리하여 병렬 처리함으로써, 게임의 실시간성과 프레임률 안정성을 확보한다.
데이터 및 병렬 연산 처리는 대용량 데이터를 빠르게 처리하기 위한 핵심 구조다. 생산자 - 소비자 패턴, 병렬 큐 처리, OpenMP 등의 병렬 프레임워크는 연산 성능을 극대화하는 데 유용하다.
데이터베이스 및 저장소 처리는 스레드를 활용해 병렬 쿼리를 실행하거나 연결 수요를 분산시켜, 데이터베이스 서버의 확장성과 응답성을 높이는 데 기여한다.
멀티미디어 및 스트리밍 환경에서는 비디오/오디오 인코딩·디코딩에 병렬 구조가 반드시 필요하다. 스레드 기반의 디코딩 구조와 SIMD, GPU 병렬처리를 함께 사용하는 것이 일반적이다.
활용 사례
사례 1: 멀티스레드 기반 웹 서버
시나리오: 멀티스레드 기반 웹 서버에서 요청 처리 성능 최적화
시스템 구성:
- 클라이언트 → 리버스 프록시 (Nginx) → 멀티스레드 기반 WAS (예: Tomcat, FastAPI) → DB
graph TD A[Client] --> B[Nginx] B --> C[Web Application Server] C --> D[Thread Pool] D --> E[DB Connection Pool]
Workflow:
- 클라이언트 요청 수신
- WAS 의 Thread Pool 에서 스레드 할당
- 요청 처리 및 DB 조회
- 결과 반환
역할:
- Thread Pool: 동시 요청에 대한 처리 스레드 제공
- 각 스레드: 요청별 비즈니스 로직 실행
- DB Connection Pool: 스레드당 DB 연결 자원 제공
유무에 따른 차이점:
| 구분 | Thread 사용 시 | 사용하지 않을 시 |
|---|---|---|
| 처리량 | 병렬 요청 처리로 증가 | 순차 처리로 성능 저하 |
| 응답 시간 | 짧음 | 길어짐 |
| 서버 리소스 | 효율적으로 사용 | 자원 낭비 우려 |
| 확장성 | 높음 (Thread Pool 활용) | 낮음 (병목 발생) |
구현 예시: Python FastAPI + ThreadPoolExecutor
| |
사례 2: 이미지 처리 서비스에서 다중 스레드를 활용한 배치 처리 시스템
시나리오: 대용량 이미지 처리 서비스에서 다중 스레드를 활용한 배치 처리 시스템
시스템 구성:
- 메인 스레드: 작업 스케줄링 및 결과 수집
- 워커 스레드 풀: 이미지 변환 작업 처리
- I/O 스레드: 파일 읽기/쓰기 전담
- 모니터링 스레드: 시스템 상태 감시
graph TD
Client[클라이언트 요청] --> MainThread[메인 스레드<br/>작업 스케줄링]
MainThread --> TaskQueue[작업 큐<br/>Task Queue]
TaskQueue --> WorkerPool[워커 스레드 풀<br/>Image Processing Workers]
WorkerPool --> Worker1[워커 스레드 1]
WorkerPool --> Worker2[워커 스레드 2]
WorkerPool --> WorkerN[워커 스레드 N]
Worker1 --> IOThread[I/O 스레드<br/>File Operations]
Worker2 --> IOThread
WorkerN --> IOThread
IOThread --> Storage[저장소<br/>File System]
MainThread --> Monitor[모니터링 스레드<br/>System Monitor]
Monitor --> Metrics[메트릭 수집<br/>Performance Data]
Workflow:
- 클라이언트 요청을 메인 스레드가 받아 작업 큐에 추가
- 워커 스레드들이 작업 큐에서 작업을 가져와 이미지 처리 수행
- I/O 스레드가 파일 읽기/쓰기 작업을 전담하여 워커 스레드 블로킹 방지
- 모니터링 스레드가 시스템 성능 지표를 지속적으로 수집
역할:
- 메인 스레드: 전체 시스템 조정 및 작업 분배
- 워커 스레드: CPU 집약적 이미지 처리 작업
- I/O 스레드: 디스크 I/O 최적화 및 버퍼링
- 모니터링 스레드: 성능 모니터링 및 이상 감지
유무에 따른 차이점:
- 스레드 사용 시: 멀티코어 활용으로 처리 시간 75% 단축, CPU 사용률 90% 이상
- 단일 스레드 시: 순차 처리로 인한 긴 처리 시간, CPU 코어 하나만 활용
구현 예시:
| |
사례 3: 실시간 웹 서버 멀티스레딩 시스템 구성
시나리오: 실시간 웹 서버에서 수백만 동시 접속자를 처리하기 위해 스레드 풀 (Thread Pool) 기반의 멀티스레딩 시스템 구성
시스템 구성:
- 요청 수신기 (Listener)
- 스레드 풀 (Worker Thread Pool)
- 큐 (Queue)
- 응답 처리기 (Responder)
- 공유 자원 (공용 메모리, 데이터베이스 등)
flowchart LR
Client(클라이언트)
Listener(요청 수신기)
Queue(요청 큐)
ThreadPool(스레드 풀)
Worker1(작업 스레드 1)
Worker2(작업 스레드 2)
WorkerN(작업 스레드 N)
Responder(응답 처리기)
DB(공유 자원/DB)
Client --요청--> Listener
Listener --큐에 요청 추가--> Queue
Queue --할당--> ThreadPool
ThreadPool --작업 분배--> Worker1
ThreadPool --작업 분배--> Worker2
ThreadPool --작업 분배--> WorkerN
Worker1 --데이터 조회/갱신--> DB
Worker2 --데이터 조회/갱신--> DB
WorkerN --데이터 조회/갱신--> DB
Worker1 --응답--> Responder
Worker2 --응답--> Responder
WorkerN --응답--> Responder
Responder --응답 전달--> Client
Workflow:
- 클라이언트가 요청을 보냄
- 요청 수신기가 요청을 큐에 저장
- 스레드 풀에서 빈 작업자 스레드가 요청을 할당받아 처리
- 처리 후 응답 처리기가 결과를 전송
역할:
- 각 스레드가 개별적으로 처리, 전체 처리량 극대화, 자원 최적 공유
유무에 따른 차이점:
- 스레드 미적용 시: 각 요청마다 프로세스 생성, 자원 낭비, 스케일 확장 한계
- 스레드 적용 시: 효율적 자원 사용, 동시 요청 처리 확장성 극대화
구현 예시:
| |
실무에서 효과적으로 적용하기 위한 고려사항 및 주의할 점
| 카테고리 | 항목 | 설명 | 권장사항 |
|---|---|---|---|
| 스레드 수 및 생명주기 관리 | 스레드 수 제한 | 과도한 스레드 생성 시 오히려 성능 저하 발생 | CPU 코어 수의 1~2 배 이내 유지 |
| 스레드 풀 사용 | 생성/종료 비용 최소화 및 재사용성 확보 | 큐 기반 ThreadPoolExecutor 활용 | |
| 동기화 및 자원 접근 제어 | 공유 자원 접근 보호 | 경쟁 상태, 데드락 방지를 위한 자원 제어 | 최소한의 동기화 적용, 락프리 구조 고려 |
| 자원 잠금 순서 고정 | 데드락 방지 위해 일관된 자원 획득 순서 유지 | acquire 순서 명시적 설계 | |
| 예외 처리 및 오류 대응 | 스레드별 예외 처리 구현 | 예외 미처리 시 전체 시스템에 영향을 줄 수 있음 | try-catch 블록 내 예외 핸들러 지정 |
| 타임아웃 설정 및 실패 복구 | 무한 대기 방지, graceful 종료 유도 | 타임아웃 기본값 설정 및 재시도 정책 포함 | |
| 성능 최적화 및 하드웨어 고려 | 컨텍스트 스위칭 최소화 | 스레드 간 전환이 빈번하면 캐시 무효화 등으로 성능 저하 | 스레드 수 조정, CPU affinity 고려 |
| 캐시 친화적 데이터 처리 설계 | 데이터 지역성 확보를 통해 캐시 히트율 증가 | 구조화된 데이터 접근 순서 설계 | |
| 디버깅 및 운영 가시성 | 로깅 및 상태 추적 체계 | 병렬 처리 중 디버깅이 어렵고, 로그 혼선 발생 | 스레드 이름 지정, Trace ID 부여, 레벨별 로깅 |
| 모니터링 및 실시간 진단 | 장애 탐지 및 성능 병목 추적이 어려움 | Prometheus, Grafana 등 연계 | |
| 자원 회수 및 종료 처리 | 스택 크기 설정 및 자원 회수 | 스택 오버플로우 및 미반환 리소스 문제 | 명시적 종료 훅 사용, shutdown 처리 정의 |
| 스레드 풀 종료 및 정리 | 실행 중 스레드가 종료되지 않으면 자원 누수 가능성 있음 | shutdown() 및 awaitTermination() 사용 |
스레드 수 및 생명주기 관리는 성능과 자원 효율성의 핵심으로, 스레드 풀의 적절한 크기 조정과 생명주기 통제가 매우 중요하다. 무한 생성은 오히려 시스템 부하를 증가시키므로 큐 기반 풀 구조를 추천한다.
동기화 및 자원 접근 제어는 병목과 데드락을 유발하는 주요 요인이며, 락의 범위를 좁히고 락프리 구조나 일관된 자원 획득 순서를 도입하는 것이 권장된다.
예외 처리 및 오류 대응은 스레드 수준에서 오류가 전체 시스템에 영향을 주지 않도록 캡슐화하는 것이 중요하다. 타임아웃과 재시도 정책을 포함한 복구 전략이 병행되어야 한다.
성능 최적화 및 하드웨어 고려는 스레드 간 전환을 최소화하고 CPU 캐시 친화적인 방식으로 데이터 접근을 설계해야 한다. 특히 NUMA 환경에서는 affinity 고려가 성능에 직접 영향을 준다.
디버깅 및 운영 가시성은 실시간 추적 및 문제 진단에 핵심적이다. 스레드별 로그 식별자 설정, 로깅 레벨 통제, APM 연동 등을 통해 운영 안정성을 높일 수 있다.
자원 회수 및 종료 처리는 시스템 안정성 보장의 마지막 단계다. 실행 중인 스레드를 정확히 종료하고, 미반환 자원을 수거하기 위한 종료 훅 및 shutdown API 호출이 필수다.
성능을 최적화하기 위한 고려사항 및 주의할 점
| 카테고리 | 고려사항 | 설명 | 권장사항 |
|---|---|---|---|
| 1. 스레드 풀 및 작업 관리 | 풀 크기 최적화 | 작업량과 CPU 수에 따라 유동적으로 조절 | 동적 튜닝, TPS 기반 풀 확장 |
| 작업 분산 | 불균형한 작업 분배로 인한 경합 및 병목 방지 | 작업 큐 기반 분할, 부하 분산 로직 적용 | |
| 과도한 생성 방지 | 스레드 생성/종료 반복은 성능 오버헤드 유발 | 스레드 풀 재사용 | |
| 2. 동기화 및 락 전략 | 락 경합 최소화 | 긴 락 구간은 병목 발생 가능 | 임계 구역 최소화, 세분화된 락 도입 |
| 락 프리 자료구조 | 경합 없이 병렬 처리 가능 | Atomic 연산, Lock-Free Queue | |
| 3. 메모리 및 캐시 활용 | 캐시 친화적 데이터 배치 | 캐시 라인 충돌 최소화, 데이터 접근 비용 절감 | 구조체 패딩, 캐시 라인 정렬 |
| Thread Local Storage 사용 | 스레드 간 공유 최소화로 캐시 효율 향상 | TLS 적용, 공유 최소화 | |
| False Sharing 방지 | 캐시 라인 간 중첩 접근으로 인한 성능 저하 | 구조체 padding, 데이터 간격 조절 | |
| 4. CPU/NUMA 최적화 | 프로세서 바인딩 | 중요 스레드를 특정 코어에 고정 | CPU Affinity 설정 |
| NUMA 인식 메모리 할당 | 메모리 접근 지역성 보장 | NUMA-aware Allocator 사용 | |
| 5. 문맥 전환 최소화 | 스레드 수 과다로 인한 전환 비용 증가 | 문맥 전환마다 캐시 무효화, 성능 저하 | 코어 수 기반 스레드 수 제한 |
| 비동기 처리 | 블로킹 대기 제거, CPU 자원 활용 극대화 | Non-blocking I/O, async 처리 적용 | |
| 6. 메모리 모델 및 일관성 | 메모리 가시성 확보 | CPU 또는 컴파일러의 재정렬로 인한 동기화 오류 가능 | volatile, 메모리 배리어 사용 |
| 메모리 일관성 보장 | 병렬 처리 간 쓰기 순서 불일치 방지 | Happens-Before 관계 설계, 동기화 전략 적용 |
스레드 풀 및 작업 관리: 스레드 풀 크기, 작업 큐, 생성 오버헤드는 성능 최적화의 기본. 스레드는 남발하지 말고 재사용하고, 작업은 균등하게 분배해야 한다.
동기화 및 락 전략: 락은 성능을 갉아먹는 주범이 될 수 있다. 락 범위는 좁히고, 락 프리 구조나 atomic 연산으로 경쟁을 최소화하는 것이 바람직하다.
메모리 및 캐시 활용: 캐시 효율은 고성능의 핵심이다. 데이터는 캐시 라인에 맞게 배치하고, TLS 를 활용하여 공유를 최소화하며, False Sharing 을 방지하는 것이 중요하다.
CPU 친화성 및 NUMA 고려: CPU 및 메모리 지역성 (Locality) 을 고려하면 캐시 히트율을 높이고 NUMA 환경에서 병목을 줄일 수 있다. CPU affinity 설정과 NUMA-aware 메모리 할당이 필요하다.
문맥 전환 및 비용 제어: 스레드 수가 많다고 좋은 게 아니다. 불필요한 컨텍스트 스위칭은 캐시 플러시와 오버헤드를 유발하며, 비동기 모델을 통해 효율적으로 자원을 사용해야 한다.
메모리 모델 및 일관성 보장: 병렬 실행 시 메모리 접근 순서나 가시성이 틀어지면 예측 불가능한 오류가 발생할 수 있다. 이를 방지하기 위해 메모리 배리어, volatile 변수, happens-before 관계 등을 설계에 반영해야 한다.
Thread 관련 현대 병행성 모델 비교, 병목 분석, Thread Pool 설계 전략
Thread 와 관련된 현대적 병행성 모델 비교 (Reactive, Actor 등)
모델 비교
| 기준 | Thread 기반 | Reactive 모델 | Actor 모델 |
|---|---|---|---|
| 구조 | 명시적 Thread 생성 및 동기화 | 이벤트 흐름 기반 비동기 | 메시지 전달 기반 병행성 |
| 실행 단위 | 스레드 (Thread) | 콜백 / Flow / 이벤트 | Actor (메시지 처리 단위) |
| 공유 메모리 | 공유 | 최소 또는 없음 | 없음 (자기 상태만 소유) |
| 동기화 필요성 | 높음 (Mutex 등) | 낮음 (상태 최소화) | 불필요 (상호 배제 보장) |
| 디버깅 난이도 | 높음 | 높음 (콜백 지옥) | 중간 (배포 단순화 가능) |
| 주요 언어/프레임워크 | Java, C++, Python | Spring WebFlux, RxJava, Project Reactor | Akka, Erlang, Elixir |
| 사용 목적 | 명확한 병렬 처리 제어 | I/O 바운드 비동기 처리 | 상태 기반 분산 처리 |
graph TD
subgraph Thread 모델
T1[Thread 1] -->|공유 자원| R1[Resource]
T2[Thread 2] --> R1
end
subgraph Reactive 모델
E1[Event] --> H1[Handler 1]
E2[Event] --> H2[Handler 2]
end
subgraph Actor 모델
A1[Actor 1] -->|Message| A2[Actor 2]
A2 -->|Message| A3[Actor 3]
end
- Thread 기반은 직접적인 병렬성과 실행 흐름 제어가 가능하지만 복잡성과 동기화 문제가 따릅니다.
- Reactive 모델은 이벤트 기반으로 I/O 에 특화되어 있으며, 스레드 수 최소화, 고성능 웹 API 처리에 적합합니다.
- Actor 모델은 상태를 각 Actor 가 소유하고 메시지로 통신하기 때문에 분산 시스템, 대규모 병행 처리에 강력합니다.
Thread 기반 아키텍처에서 발생 가능한 병목 지점 식별과 해결 전략
| 병목 지점 | 원인 | 탐지 방법 | 해결 전략 |
|---|---|---|---|
| Context Switching 과다 | Thread 과도 생성 및 스케줄링 비용 증가 | perf, top, htop, JVM Thread dump | Thread 수 제한, Pool 사용 |
| Lock 경합 | 동일 자원에 대해 많은 Thread 가 동시에 접근 | strace, Lock profiler, thread contention logs | 락 분할 (Shard), RCU, Read-Write Lock |
| I/O 블로킹 | DB, 파일 등 블로킹 I/O 로 인한 대기 | Tracing, I/O 분석 (iostat, dstat) | 비동기 I/O 도입, 캐싱 |
| Thread starvation | 우선순위 스레드가 점유하여 나머지 실행 지연 | CPU 사용률, 작업 지연 추적 | 우선순위 조정, 공정한 스케줄링 |
| 스레드 수 과도 | 스레드 생성/소멸 오버헤드 증가 | 스레드 사용 모니터링 | Thread Pool 사용, Queue 기반 처리 |
| DB connection pool 부족 | Thread 수 > DB connection pool 크기 | DB 커넥션 대기 시간 분석 | DB pool 크기 조정, Query 최적화 |
Thread Pool 설계 시 고려사항 및 동적 튜닝 기법
Thread Pool 설계 고려사항
| 고려 요소 | 설명 | 권장 설계 기준 |
|---|---|---|
| 최대 Thread 수 | 과도하면 Context Switching 증가 | (CPU core 수 * 2) + IO 대기 수 추정 |
| 작업 큐 크기 | 큐가 너무 크면 지연, 작으면 drop | 시스템 부하와 SLA 에 따라 조절 |
| Thread 생명주기 관리 | Idle 시 자동 소멸, 필요 시 재생성 | keepAliveTime 설정 |
| 거부 정책 (Rejection Policy) | 큐가 꽉 찼을 때 처리 방법 | CallerRunsPolicy, DiscardOldest 등 |
| 우선순위 기반 처리 | 작업 성격에 따라 Thread 배분 | 별도 우선순위 큐 구성 가능 |
동적 튜닝 기법
| 기법 | 설명 | 적용 방식 |
|---|---|---|
| Thread 개수 자동 조절 | TPS, 평균 응답 시간 기반으로 동적 변경 | JVM 의 ForkJoinPool, Elastic Thread Pool |
| Queue 압력 기반 Scaling | 큐 길이에 따라 스레드 확장/축소 | 백프레셔 (Backpressure) 연동 |
| 가비지 Thread 제거 | 일정 시간 이상 유휴 상태면 제거 | keepAliveTime + allowCoreThreadTimeout |
| 메트릭 기반 튜닝 | CPU 사용률, 작업 처리 시간 모니터링 | Prometheus, Micrometer, Grafana 기반 자동화 |
Thread 관련 주요 API 설계 원칙
스레드를 사용하는 시스템을 설계하거나, Thread 기반 API 를 구성할 때 반드시 지켜야 할 설계 원칙들을 다음과 같이 정리합니다.
| 원칙 | 설명 | 실무 적용 사례 |
|---|---|---|
| 명확한 책임 분리 | 스레드별로 수행할 작업이 명확하게 정의되어야 함 | 웹 요청 처리: 응답 전용 / DB 조회 전용 스레드 분리 |
| 상태 공유 최소화 | 가능하면 공유 메모리를 피하고 메시지 기반 통신으로 구성 | Go 의 goroutine + channel 패턴 |
| 스레드 안전성 (Thread-Safety) | 다중 스레드 환경에서도 데이터 무결성이 보장되어야 함 | Java ConcurrentHashMap, Python threading.Lock |
| 리소스 관리 자동화 | Thread Pool, 자동 종료, 예외 처리 등을 통해 자원 누수 방지 | Python 의 ThreadPoolExecutor 사용 |
| 오류 격리 및 복구 가능성 | 하나의 스레드 실패가 전체 시스템에 영향을 주지 않도록 설계 | Supervisor Pattern (예: Erlang/Elixir) |
| 시간 제한 (Time-out) 설정 | 블로킹 작업이나 대기 작업에는 반드시 타임아웃 설정 | HTTP 요청 처리 타임아웃 설정 |
정리 및 학습 가이드
내용 정리
스레드는 현대 컴퓨터 시스템에서 동시성과 병렬성을 구현하기 위한 핵심 실행 단위다.
하나의 프로세스 내에서 여러 스레드가 메모리와 자원을 공유하면서 독립적으로 실행되어 자원 활용의 효율성을 극대화하고, 반응성 향상과 병렬 처리 성능 개선을 가능하게 한다.
운영체제에 따라 커널 수준 (KLT), 사용자 수준 (ULT), 하이브리드 모델로 구현되며, 메모리 구조, 스케줄링 전략, 동기화 기법, 예외 처리 등 설계 시 고려해야 할 요소가 많다.
실무에서는 웹 서버의 동시 요청 처리, 모바일 UI 비동기 처리, 게임 엔진의 물리 연산, 데이터 파이프라인의 병렬 처리 등에서 광범위하게 활용되며, 스레드 풀 기반의 자원 최적화가 일반적이다. 스레드는 단순한 실행 단위를 넘어서 전체 시스템의 성능과 안정성을 좌우하는 설계 핵심 요소다.
기술 동향 분석
최근 동시성 기술은 " 경량화 " 와 " 자동화 " 를 중심으로 빠르게 진화하고 있다.
대표적으로 Go 의 고루틴, Kotlin 의 코루틴, Java 의 Virtual Thread(Project Loom) 는 기존 스레드 모델의 한계를 극복하고, 수천~수만 개의 동시 실행 흐름을 보다 적은 자원으로 처리할 수 있게 한다.
또한 락프리 (Lock-Free) 알고리즘, 무상태 구조 (Stateless Design), CAS(Compare-And-Swap) 기반 동기화 방식이 널리 도입되며 성능 병목과 데드락 위험을 줄이고 있다.
클라우드 네이티브 환경에서는 서버리스 구조, 오토스케일링, 자원 할당 제한 등을 고려한 스레드 최적화가 필수 요소로 떠오르고 있다.
이와 함께 스레드 안전 (Thread-safe) 라이브러리, 비결정적 버그 디버깅을 위한 분산 추적 시스템, 실시간 메트릭 수집 및 로깅 시스템과의 통합도 중요해지고 있다.
결론적으로 스레드는 단순한 실행 단위가 아니라 아키텍처적 자산으로 설계되어야 하며, 동시성 기술은 지속적으로 고성능·고가용성·고관찰성을 추구하는 방향으로 발전하고 있다.
학습 항목 정리
| 분류 | 주제 | 핵심 항목 | 중요도 |
|---|---|---|---|
| 기초 이론 | 스레드 개념 및 구조 | 스레드 정의, 스레드 vs 프로세스, 상태 전이도 | 기본 |
| 동시성 vs 병렬성 | 개념적 차이, 활용 예시, 선택 기준 | 기본 | |
| 구현 모델 | 사용자 수준 / 커널 수준 스레드 | ULT, KLT, Hybrid (M:N) 구조 및 예시 | 기본 |
| 언어별 구현 전략 | GIL (Python), Native Thread (C/C++), Virtual Thread (Java) | 기본 | |
| 동기화 | 기본 동기화 메커니즘 | Mutex, Semaphore, Condition Variable | 기본 |
| 고급 동기화 전략 | RW Lock, Barrier, Lock-free, Wait-free, 원자적 연산 | 심화 | |
| 메모리 모델 | 가시성, 순서 보장, 일관성 모델 (TMS, MESI 등) | 심화 | |
| 병행 제어 | 경쟁 상태 및 오류 | Race Condition, Deadlock, Starvation, Livelock | 심화 |
| 컨텍스트 스위칭 | 스위칭 비용, 최적화 전략, 커널 간섭 | 심화 | |
| 실행 모델 | 스케줄링 전략 | FCFS, Round Robin, Priority, MLFQ, Real-time | 기본 |
| 비동기 / 코루틴 | 이벤트 루프, async/await, Coroutine, Fiber | 실무 | |
| 성능 최적화 | 스레드 풀 구성 및 관리 | 작업 큐 설계, 크기 조정 전략, 동적 튜닝 | 실무 |
| I/O vs CPU 바운드 최적화 | 작업 분리, 비동기 처리, 스케줄링 분리 | 실무 | |
| NUMA 및 하드웨어 연계 | CPU 바인딩, 캐시 일관성, 병렬화와 코어 전략 | 실무 | |
| 디버깅 및 운영 | 스레드 추적 및 모니터링 | 로그, 트레이스, APM, 성능 지표 수집 | 실무 |
| 오류 탐지 및 복구 전략 | 데드락 탐지, 재시도, 사전 예약, 장애 허용성 설계 | 실무 | |
| 프로그래밍 패턴 | 병렬 처리 디자인 패턴 | Producer-Consumer, Master-Worker, Fork-Join | 실무 |
| 스레드 기반 아키텍처 사례 | 웹서버, 데이터 파이프라인, 분산 시스템 내 스레드 활용 | 실무 |
용어 정리
| 카테고리 | 용어 | 설명 |
|---|---|---|
| 운영 체제 및 구조 | 프로세스 (Process) | 실행 중인 프로그램 인스턴스. 고유 자원 소유. |
| 운영 체제 및 구조 | 스레드 (Thread) | 프로세스 내 실행 흐름 단위. 자원 공유. |
| 운영 체제 및 구조 | TCB | 스레드 상태 저장 구조체 (레지스터, 스택 포인터 등). |
| 스레드 실행 모델 | ULT | 사용자 공간에서 스케줄링되는 스레드. |
| 스레드 실행 모델 | KLT | 커널에 의해 직접 스케줄링되는 스레드. |
| 스레드 실행 모델 | Hybrid Thread Model | 사용자 스레드 여러 개가 커널 스레드에 매핑. |
| 스레드 실행 모델 | 그린 스레드 | 사용자 공간에서 운영. 커널 스케줄러 관여 없음. |
| 스레드 실행 모델 | 가상 스레드 | JVM/런타임에 의해 경량 스케줄링됨. |
| 스레드 실행 모델 | 협력 스레드 | 명시적 양보 (Cooperative Yield) 방식 스케줄링. |
| 동기화 및 병행성 제어 | 뮤텍스 | 상호 배제를 위한 동기화 객체. |
| 동기화 및 병행성 제어 | 세마포어 | 자원 접근 개수 제어 동기화 객체. |
| 동기화 및 병행성 제어 | 모니터 | 고수준 동기화 구조. 뮤텍스 + 조건 변수의 조합. |
| 동기화 및 병행성 제어 | Condition Variable | 조건 충족 시 스레드 실행 재개 제어. |
| 동기화 및 병행성 제어 | 스핀락 | 락 획득까지 루프 대기. 빠른 획득 시 적합. |
| 동기화 및 병행성 제어 | TLS | 각 스레드 전용 저장소로, 공유 없이 독립 실행. |
| 동기화 및 병행성 제어 | Lock-Free / Wait-Free / Obstruction-Free | 락 없이 진행하는 병행 제어 기법. |
| 문제 상황 및 오류 | 데드락 | 두 스레드가 서로 자원을 무한 대기. |
| 문제 상황 및 오류 | 기아 상태 | 우선순위 낮은 스레드가 자원을 지속적으로 획득하지 못함. |
| 문제 상황 및 오류 | 경쟁 상태 | 동시 접근으로 인한 예측 불가 상태. |
| 문제 상황 및 오류 | False Sharing | 서로 다른 스레드가 같은 캐시 라인을 공유해 성능 저하. |
| 성능 최적화 및 실행 전략 | 스레드 풀 | 재사용 가능한 스레드 집합으로 작업 처리. |
| 성능 최적화 및 실행 전략 | 워크 스틸링 | 유휴 스레드가 다른 스레드의 작업을 가져오는 전략. |
| 성능 최적화 및 실행 전략 | Affinity | 특정 CPU 코어에 스레드 고정. |
| 성능 최적화 및 실행 전략 | NUMA 최적화 | Non-Uniform Memory Access 에 따른 메모리 접근 전략. |
| 성능 최적화 및 실행 전략 | Context Switching | 스레드 전환을 위한 상태 저장 및 복원. |
| 운영 도구 및 진단 | Trace | 스레드 실행 흐름 및 병목 추적. |
| 운영 도구 및 진단 | APM | 어플리케이션 레벨에서 성능 모니터링 및 병목 분석. |
참고 및 출처
- Thread in Operating System - GeeksforGeeks
- Threads and its Types in Operating System - GeeksforGeeks
- Thread (computing) - Wikipedia
- Java Virtual Threads vs Thread - Baeldung
- Java’s Virtual vs Platform Threads and What’s New in JDK 24 - Medium
- Virtual thread - Wikipedia
- POSIX Threads (pthreads) - Wikipedia
- How to Use Java 21’s Virtual Threads in Real‑World Web Applications - JavaCodeGeeks