Context Switching
1단계: 기본 분석 및 검증
대표 태그
- 프로세스관리 (Process Management)
- 멀티태스킹 (Multitasking)
- CPU스케줄링 (CPU Scheduling)
- 시스템성능 (System Performance)
분류 체계 검증
현재 분류 구조 중 “Computer Science Fundamentals > Operating Systems > Process Management >Processes"는 적절합니다. “Context Switching(컨텍스트 스위칭)“은 운영체제의 멀티태스킹을 가능하게 하며, 프로세스 관리의 핵심에 해당합니다. 다만, 실무적 관점에서는 “Performance Optimization(성능 최적화)”, “Concurrency(동시성)“에도 연계되며, 실질적으로 “시스템 성능”·“프로세스 스케줄링”·“CPU 관리” 분류에 투입하는 것도 추천합니다.
핵심 요약
컨텍스트 스위칭(문맥 교환, Context Switching)은 CPU가 실행 중인 프로세스 상태를 저장하고, 새로운 프로세스 상태를 복원해 여러 작업이 병렬처럼 실행될 수 있도록 하는 운영체제 핵심 기능입니다.[1][2][3]
전체 개요
컨텍스트 스위칭은 현대 운영체제에서 필수적인 기술입니다. 단일 CPU에서 여러 프로세스를 효율적으로 처리하기 위해, 운영체제는 실행 중인 프로세스의 상태(레지스터, 메모리, 스택 등)를 저장하고, 대기 중인 프로세스의 상태를 복원해 실행을 전환합니다. 이로 인해 사용자 입장에서는 여러 작업이 동시에 실행되는 듯이 보입니다. 멀티태스킹, 실시간 처리, 서버 운영, 클라우드 환경 등 다양한 실제 업무에서 필수적으로 사용되며, 성능·효율성·안정성 관점에서 중요한 역할을 합니다.[4][2][1]
1단계: 기본 분석 및 검증
1. 대표 태그
- Process-Management
- Operating-Systems
- CPU-Scheduling
- Performance-Optimization
2. 분류 체계 검증
현재 분류 구조에서의 위치:
| |
✅ 적절합니다. Context Switching은 운영체제(OS) 프로세스 관리의 핵심 메커니즘이며, 스케줄링과 멀티태스킹 성능에 직접적인 영향을 주는 현상입니다. 다만, 성능 최적화(Performance Optimization)나 병렬 처리(Concurrency)와도 밀접한 관련이 있어 Concurrency 하위에도 연결 참조가 있으면 좋습니다.
3. 핵심 요약 (250자 이내)
Context Switching은 CPU가 실행 중인 프로세스 또는 스레드의 상태를 저장하고 다른 프로세스 또는 스레드의 상태를 복원하는 작업입니다. 이는 멀티태스킹과 공정한 CPU 자원 분배를 가능하게 하지만, 빈번하면 성능 저하를 초래합니다.
4. 전체 개요 (400자 이내)
운영체제에서 Context Switching은 하나의 실행 흐름에서 다른 실행 흐름으로 전환하는 과정입니다. CPU 레지스터, 프로그램 카운터, 스택 포인터 등 프로세스 상태를 PCB(Process Control Block)에 저장하고, 다음 실행할 프로세스의 상태를 복원하여 이어갑니다. 멀티태스킹과 인터럽트 처리, 사용자 경험 향상에 필수적이지만, 전환 시 오버헤드가 발생하므로 빈도와 비용을 최소화하는 최적화 전략이 중요합니다.
1단계: 기본 분석 및 검증
대표 태그
- Process-Management (프로세스 관리)
- OS-Scheduling (운영체제 스케줄링)
- CPU-Resource (CPU 자원 관리)
- Performance-Overhead (성능 오버헤드)
분류 체계 검증
현재 분류: Computer Science Fundamentals > Operating Systems > Process Management > Processes
개선 제안: 현재 분류가 적절하며, Context Switching은 Process Management의 핵심 메커니즘으로서 올바르게 배치되어 있습니다. 다만 Performance Optimization 분야와도 밀접한 연관이 있어 교차 참조가 필요합니다.
핵심 요약 (250자 이내)
Context Switching은 운영체제가 CPU에서 실행 중인 프로세스를 중단하고 다른 프로세스로 전환하는 메커니즘입니다. 멀티태스킹 환경에서 여러 프로세스가 CPU 자원을 공유할 수 있게 하는 핵심 기능이지만, 프로세스 상태 저장 및 복원으로 인한 성능 오버헤드가 발생합니다.
전체 개요 (400자 이내)
Context Switching은 현대 멀티태스킹 운영체제의 근간이 되는 핵심 메커니즘입니다. CPU 스케줄러가 프로세스 간 전환을 결정하면, 현재 실행 중인 프로세스의 상태(레지스터, 프로그램 카운터 등)를 PCB(Process Control Block)에 저장하고, 새로운 프로세스의 상태를 복원하여 실행을 재개합니다. 이 과정은 시스템 성능에 직접적인 영향을 미치므로, 최적화 전략과 오버헤드 관리가 매우 중요합니다.
2단계: 개념 체계화 및 검증
핵심 개념 정리
이론적 기반:
- Process Control Block (PCB, 프로세스 제어 블록)
- CPU 레지스터 상태 관리
- 메모리 관리 유닛 (MMU, Memory Management Unit) 제어
- 스케줄링 알고리즘과의 연동
실무 구현:
- 하드웨어 지원 메커니즘 (레지스터 저장/복원)
- 커널 레벨 상태 관리
- 시스템 콜 인터페이스
- 성능 모니터링 및 최적화
실무 연관성 분석
Context Switching은 시스템 성능, 응답성, 자원 활용률에 직접적 영향을 미치므로 시스템 설계, 성능 튜닝, 모니터링 영역에서 핵심적으로 다뤄져야 하는 개념입니다.
2단계: 개념 체계화 및 검증
핵심 개념 정리
- 컨텍스트(Context): 프로세스 실행 상태(레지스터, 프로그램 카운터, 스택, 메모리 등)[2][5]
- 컨텍스트 스위칭(Context Switching): 실행 중인 프로세스의 상태를 저장하고, 다른 프로세스의 상태를 복원해 CPU 자원을 할당하는 과정[1][4][2]
- Process Control Block (PCB, 프로세스 제어 블록): 각 프로세스의 상태와 정보 저장 구조체[1]
- 트리거(Trigger): 타이머 인터럽트, 시스템 콜, I/O 완료 등으로 발생[4][2]
- 멀티태스킹(Multitasking): 컨텍스트 스위칭을 통해 여러 프로세스 동시 처리 가능[3][4]
- 성능 오버헤드: 스위칭 자체가 표현하는 CPU/메모리 사용량, 시스템 성능 저하의 원인이 될 수 있음[6][7]
실무 연관성 분석
컨텍스트 스위칭은 서버, 데이터베이스, 컨테이너 등 다양한 환경에서 CPU 자원의 효율적 분배와 안정성 확보를 위한 핵심 기술입니다. 높은 컨텍스트 스위칭 빈도는 시스템 부하/성능 저하, 디버깅의 복잡성 증가를 유발하며, 실무에서는 모니터링 및 조율이 중요합니다.[7]
3단계: 단계별 상세 조사 및 검증
Phase 1: 기초 개념
1.1 개념 정의 및 본질적 이해
컨텍스트 스위칭은 CPU가 현재 실행 중인 프로세스의 상태(즉, 레지스터 값, 프로그램 카운터 등)를 저장하고, 다음 실행할 프로세스의 이전 상태를 복원하여 실행을 전환하는 운영체제 동작입니다. 이를 통해 하나의 CPU에서 다수의 프로세스가 동시 실행되는 것처럼 보이게 만듭니다.[2][1]
1.2 등장 배경 및 발전 과정
초기의 단일 태스킹 OS(운영체제)는 한 번에 하나의 프로세스만 실행했습니다. 증가하는 사용자 요구와 복합 업무 처리를 위해 멀티태스킹, 멀티프로세스 OS가 등장했고, 이를 실현하기 위해 컨텍스트 스위칭이 도입되었습니다. 하드웨어 발전에 따라 전용 레지스터, 효율적인 메모리 관리, 고급 스케줄링 알고리즘이 추가되었습니다.[6][2]
1.3 핵심 목적 및 필요성 (문제 해결 관점)
컨텍스트 스위칭의 주요 목적은 멀티태스킹 구현입니다. 단일 CPU 환경에서 여러 프로세스/스레드가 동시 실행될 수 있도록 하며, 특정 프로세스가 장기간 CPU를 점유하지 못하게 막아 효율적 자원 분배와 공정한 프로세스 처리를 실현합니다.[3][1]
1.4 주요 특징 및 차별점 (기술적 근거 포함)
- 멀티태스킹 OS에서 필수적
- 프로세스 별로 상태를 철저히 관리(PCB)
- 하드웨어 및 운영체제에 따라 컨텍스트 저장/복원 성능차 발생
- 인터럽트, I/O 완료, 타이머 등에 즉각 반응해 프로세스 전환[8][4][2]
Phase 1: 기초 개념 (Foundation Understanding)
1.1 개념 정의 및 본질적 이해
**Context Switching (컨텍스트 스위칭)**은 운영체제가 현재 CPU에서 실행 중인 프로세스나 스레드를 중단하고, 다른 프로세스나 스레드로 CPU 제어권을 이양하는 과정입니다.
핵심 구성 요소:
- Context (컨텍스트): 프로세스의 실행 상태 정보 (레지스터 값, 프로그램 카운터, 스택 포인터 등)
- Switch (스위치): 한 프로세스에서 다른 프로세스로의 전환 과정
- PCB (Process Control Block): 프로세스 컨텍스트를 저장하는 자료구조
1.2 등장 배경 및 발전 과정
초기 단일 태스킹 시대 (1940-1960년대):
- 한 번에 하나의 프로그램만 실행
- CPU 자원의 비효율적 활용
- 사용자 대기 시간 증가
멀티태스킹 도입 (1960년대 이후):
- 시분할 시스템 (Time-sharing) 등장
- 여러 프로세스의 동시 실행 필요성 대두
- Context Switching 메커니즘 개발
현대적 발전:
- 하드웨어 지원 강화 (전용 레지스터, 캐시 관리)
- 가상화 환경에서의 최적화
- 컨테이너 기술과의 연계
1.3 핵심 목적 및 필요성
주요 목적:
- 멀티태스킹 지원: 여러 프로세스의 동시 실행
- CPU 자원 효율화: 유휴 시간 최소화
- 시스템 응답성 향상: 사용자 상호작용 개선
- 공정한 자원 배분: 프로세스 간 균등한 CPU 시간 할당
필요성 (문제 해결 관점):
- I/O 대기 시간 동안 CPU 활용률 극대화
- 우선순위 기반 작업 처리
- 시스템 안정성 보장 (무한 루프 프로세스 제어)
1.4 주요 특징 및 차별점
이 표는 Context Switching의 주요 특징과 기술적 근거를 분석하기 위해 작성되었습니다.
| 구분 | 특징 | 설명 | 기술적 근거 | 차별점 |
|---|---|---|---|---|
| 메커니즘 | 자동화된 전환 | OS가 자동으로 프로세스 전환 수행 | 타이머 인터럽트와 스케줄러 연동 | 수동 제어 대비 안정성 확보 |
| 투명성 | 프로세스 무감지 | 각 프로세스는 전환을 인지하지 못함 | 상태 완전 복원 메커니즘 | 프로그램 호환성 보장 |
| 원자성 | 비중단 전환 | 전환 과정 중 중단 불가 | 커널 모드에서 실행 | 시스템 무결성 보장 |
| 오버헤드 | 성능 비용 발생 | 상태 저장/복원으로 인한 지연 | 메모리 접근 및 캐시 미스 | 성능과 기능성의 트레이드오프 |
Phase 1: 기초 개념 (Foundation Understanding)
1.1 개념 정의 및 본질적 이해
- 정의: **컨텍스트 스위칭(Context Switching)**은 CPU가 현재 실행 중인 실행 흐름(프로세스 Process 또는 스레드 Thread)의 **문맥(context: 레지스터, 프로그램 카운터, 스택 포인터, 메모리 맵 등)**을 저장하고, 다른 실행 흐름의 문맥을 복원하여 실행을 전환하는 OS(운영체제) 수준 메커니즘.
- 본질: 멀티태스킹(Preemptive Multitasking)과 공정성(Fairness)을 보장하지만, 저비용이 아닌 작업으로서 빈도가 높아지면 지터(jitter), 캐시/TLB(Translation Lookaside Buffer) 교란, 스루풋 저하를 초래.
1.2 등장 배경 및 발전 과정
- Batch → Time-sharing: 초기 일괄 처리(배치)에서 사용자 대화형(time-sharing) 시스템으로 진화하며, **시간 할당(time slice/quantum)**과 **선점(preemption)**이 도입.
- 단일 코어 → 멀티코어/NUMA: 코어/소켓 증가와 **코어 간 이동(migration)**이 컨텍스트 스위칭 비용을 가중(캐시 지역성/NUMA 원격 접근 비용).
- 커널 스케줄러의 진화: O(1) 스케줄러 → CFS(Completely Fair Scheduler) 등으로 발전하며 공정성과 지연(latency) 균형 최적화.
1.3 핵심 목적 및 필요성 (문제/현상형 해석)
- 발생 원인: (1) 타이머 인터럽트에 의한 선점, (2) 블로킹 I/O로 인한 자발적 양보(voluntary), (3) 우선순위/실시간 스케줄링, (4) 시그널/인터럽트 처리, (5) 과도한 스레드/프로세스 개수.
- 문제 상황: 과도한 컨텍스트 스위칭은 CPU 사이클 낭비, L1/L2/L3 캐시 미스 증가, TLB flush/미스 증가, 런큐(run queue) 경합으로 이어져 응답 지연과 비용 상승을 유발.
1.4 주요 특징 및 차별점
- 프로세스 vs 스레드 전환: 주소 공간이 다른 프로세스 전환이 일반적으로 더 비쌈(페이지 테이블/TLB 영향). 스레드 전환은 주소 공간 공유로 상대적으로 경량.
- 동일 코어 vs 코어 마이그레이션: 동일 코어 전환은 빠르나, 코어 이동은 캐시 워밍 비용과 NUMA 원격 메모리 접근 유발.
- 자발(voluntary) vs 비자발(involuntary): I/O 대기 등 자발적 전환은 필연적일 수 있으나, 시간 할당 만료/우선순위 역전 등 비자발적 전환은 튜닝 대상.
검증 포인트
- 우리 서비스의 **cs(초당 컨텍스트 스위치)**가 트래픽 패턴과 상관관계를 보이는가?
- involuntary vs voluntary 비율이 높은 구간은 언제/왜 발생하는가?
Phase 2: 핵심 원리 (Core Theory)
2.1 핵심 설계 원칙 및 철학
- Fairness(공정성): CPU 시간을 공정하게 분배.
- Responsiveness(응답성): 대화형/지연 민감 워크로드의 반응성 확보.
- Throughput vs Latency Trade-off: 타임슬라이스와 우선순위, 코어 핀ning 등으로 균형 조정.
- Locality Preservation(지역성 보존): 가능한 코어/NUMA 지역성 유지로 비용 완화.
2.2 동작 메커니즘 (다이어그램)
sequenceDiagram
participant HW as CPU Core
participant TIM as Timer Interrupt
participant OS as Scheduler/Dispatcher
participant P1 as Thread/Process A
participant P2 as Thread/Process B
TIM->>HW: Periodic tick/NMI
HW->>OS: Trap to kernel (save partial state)
OS->>OS: Update vruntime / accounting
OS->>OS: Pick next runnable entity (CFS/RT)
OS->>P1: Save context (registers, PC, SP) to TCB/PCB
OS->>P2: Restore context from TCB/PCB
OS->>HW: Return to user mode
HW-->>P2: Resume execution
2.3 아키텍처 및 구성 요소
graph TB
subgraph "Kernel"
A[Scheduler(CFS/RT)] --> B[Dispatcher]
A --> C[Runqueue per-CPU]
D[Timer/Interrupt Handler] --> A
E[PCB/TCB Store] --> B
end
subgraph "Hardware"
F[CPU Cores] --> D
F --> C
end
- 필수: 스케줄러, 디스패처, 타이머/인터럽트 핸들러, per-CPU 런큐, PCB/TCB.
- 선택/환경 의존: CPU Affinity(코어 고정), NUMA Balancer, cgroups/containers, RT scheduler.
2.4 주요 기능과 역할
- 스케줄 결정: 다음 실행 엔티티 선택(CFS vruntime, RT priority).
- 문맥 저장/복원: 레지스터/PC/SP/FP 등 저장·복원.
- 어카운팅: 사용 시간, 우선순위 aging, I/O 대기 보정.
- 마이그레이션 정책: 부하 분산, locality 유지.
검증 포인트
- 런큐 길이(runq length), sched latency, preemptions/s를 관측 중인가?
- affinity/NUMA 정책이 서비스 특성과 맞는가?
Phase 2: 핵심 원리 (Core Theory)
2.1 핵심 설계 원칙 및 철학
투명성 (Transparency): 프로세스는 Context Switching이 발생하는 것을 인지하지 못해야 합니다.
원자성 (Atomicity): 전환 과정은 중단될 수 없는 단일 작업으로 처리되어야 합니다.
효율성 (Efficiency): 전환 비용을 최소화하면서 멀티태스킹 이점을 극대화해야 합니다.
공정성 (Fairness): 모든 프로세스가 공정하게 CPU 시간을 할당받아야 합니다.
2.2 기본 원리 및 동작 메커니즘
Context Switching 동작 흐름:
graph TB
A[프로세스 A 실행 중] --> B[인터럽트/시스템 콜 발생]
B --> C[커널 모드 전환]
C --> D[프로세스 A 상태 저장]
D --> E[스케줄러 호출]
E --> F[다음 프로세스 B 선택]
F --> G[프로세스 B 상태 복원]
G --> H[사용자 모드 전환]
H --> I[프로세스 B 실행 재개]
style D fill:#ffeb3b
style G fill:#4caf50
상태 저장 과정:
- 레지스터 저장: CPU의 모든 범용 레지스터 값
- 프로그램 카운터: 다음 실행할 명령어 주소
- 스택 포인터: 현재 스택 위치
- 상태 플래그: CPU 상태 정보
- 메모리 관리 정보: 페이지 테이블, 세그먼트 정보
2.3 아키텍처 및 구성 요소
시스템 아키텍처:
graph TB
subgraph "사용자 영역"
PA[프로세스 A]
PB[프로세스 B]
PC[프로세스 C]
end
subgraph "커널 영역"
SCH[스케줄러]
PCB1[PCB A]
PCB2[PCB B]
PCB3[PCB C]
CSM[Context Switch Manager]
end
subgraph "하드웨어"
CPU[CPU]
REG[레지스터]
MMU[메모리 관리 유닛]
TIM[타이머]
end
PA --> PCB1
PB --> PCB2
PC --> PCB3
SCH --> CSM
CSM --> REG
CSM --> MMU
TIM --> SCH
필수 구성 요소:
- PCB (Process Control Block): 프로세스 상태 정보 저장소
- 스케줄러 (Scheduler): 다음 실행할 프로세스 결정
- 디스패처 (Dispatcher): 실제 전환 작업 수행
- 타이머 (Timer): 시분할 시점 결정
선택적 구성 요소:
- 캐시 관리자: 캐시 일관성 유지
- 가상 메모리 관리자: 주소 공간 전환
- I/O 관리자: 디바이스 컨텍스트 관리
2.4 주요 기능과 역할
핵심 기능별 책임:
이 표는 Context Switching의 주요 기능과 각각의 책임을 명확히 구분하기 위해 작성되었습니다.
| 기능 | 책임 | 상호 관계 | 성능 영향 |
|---|---|---|---|
| 상태 저장 | 현재 프로세스 실행 컨텍스트 보존 | 상태 복원과 쌍을 이룸 | 메모리 접근 비용 |
| 프로세스 선택 | 스케줄링 정책에 따른 다음 프로세스 결정 | 상태 저장 후 수행 | 스케줄링 알고리즘 복잡도 |
| 상태 복원 | 선택된 프로세스의 실행 컨텍스트 복구 | 프로세스 선택 후 수행 | 캐시 미스율 증가 |
| 주소 공간 전환 | 가상 메모리 맵핑 변경 | 상태 복원과 동시 수행 | TLB 플러시 비용 |
Phase 2: 핵심 원리
2.1 핵심 설계 원칙 및 철학
- 프로세스의 공정한 자원 분배(Scheduling, 스케줄링)
- 각 프로세스 상태의 완전한 저장/복원으로 데이터 손실 방지
- 효율적 성능(오버헤드 최소화)[6][1]
2.2 기본 원리 및 동작 메커니즘
컨텍스트 스위칭 동작 과정:
- 실행 중인 프로세스에서 인터럽트(or 스케줄러 신호) 발생
- 운영체제가 현재 프로세스 상태를 PCB에 저장
- 대기중인 프로세스 중 실행할 대상을 선별
- 선별된 프로세스의 PCB에서 상태(레지스터, PC 등) 복원
- 선택된 프로세스가 CPU에서 실행 시작
시스템 다이어그램(Mermaid)
sequenceDiagram
participant CPU
participant OS
participant ProcessA
participant ProcessB
CPU->>ProcessA: 실행중
OS->>CPU: 인터럽트/타이머 발생(스위치 요청)
CPU->>OS: 상태 저장(PCB_A)
OS->>ProcessB: PCB_B 값 읽어옴
CPU->>ProcessB: 컨텍스트 복원 및 실행
2.3 아키텍처 및 구성요소
- CPU
- PCB(Process Control Block, 프로세스 제어 블록): 각 프로세스의 현재 상태저장
- 스케줄러(Scheduler): 전환 대상 선정
- 메모리 관리자(Memory Manager): 필요 시 메모리 매핑 갱신[8][2]
2.4 주요 기능과 역할
- 프로세스 전환 : 적절한 시기에 프로세스를 전환해 멀티태스킹 구현
- 상태 관리 : 프로세스별로 상태 값을 엄격히 저장/복원
- 자원 최적화 : CPU/메모리 등 자원 효율적 활용, 공정한 분배
Phase 3: 특성 분석
3.1 장점 및 이점 분석표
이 표는 주제의 장점과 기술적 근거를 체계적으로 분석하기 위해 작성되었습니다.
| 구분 | 항목 | 설명 | 기술적 근거 | 실무 효과 |
|---|---|---|---|---|
| 장점 | 멀티태스킹 구현 | 여러 프로세스 동시 처리 | PCB 기반 상태 관리[1][2] | 사용성/생산성 증대 |
| 장점 | 자원 분배 최적화 | CPU 자원을 공정하게 분배 | 스케줄러 and 인터럽트 활용[1][2] | 시스템 효율 개선 |
| 장점 | 반응성 증가 | 실시간 인터럽트 처리 가능 | 하드웨어-OS 연동[4][2] | 서버/데스크탑 반응속도 개선 |
| 장점 | 안정성 확보 | 각 프로세스 상태 철저 관리 | PCB/메모리 보호기법 적용[8] | 장애·데이터 손실 감소 |
3.2 단점 및 제약사항/해결방안 분석표
이 표는 주제의 단점과 제약사항, 그리고 해결방안을 종합적으로 분석하기 위해 작성되었습니다.
| 구분 | 항목 | 설명 | 해결책 | 대안 기술 |
|---|---|---|---|---|
| 단점 | 오버헤드 발생 | 스위칭 시 CPU/메모리 사용 증가 | 경량화 스케줄러[6] | 하드웨어 멀티프로세싱[8][5] |
| 단점 | 캐시 무효화 | CPU 캐시 재적재 필요 | CPU 캐시 최적화[4][7] | 대용량 캐시/하드웨어지원 |
| 단점 | 실시간 성능 저하 위험 | 빈번한 스위칭에 따른 응답 지연 | 우선순위기반 스케줄링 | 실시간 OS[4][8] |
| 단점 | 디버깅 복잡성 상승 | 복수 상태/스위치 경로로 인한 진단 난이도 증가 | 고급 모니터링 도구 | observability 플랫폼 |
3.3 트레이드오프 관계 분석
더 많은 프로세스를 동시에 처리할수록 컨텍스트 스위칭 오버헤드가 발생해 성능이 떨어질 수 있습니다. 반면, 적은 스위칭은 응답성과 자원 활용도가 낮아집니다. 하드웨어/OS 환경 및 실제 workload에 따라 적절한 타협이 중요합니다.[7][6]
3.4 성능 특성 및 확장성 분석
- 하드웨어 CPU·메모리 성능에 비례해 오버헤드 감소
- 소프트웨어(커널, 스케줄러) 최적화로 확장성 증가[4][8]
- 실무에선 모니터링 도구로 스위칭 횟수 및 시간 측정하여 최적 운영
Phase 3: 특성 분석 (Characteristics Analysis)
3.1 장점 및 이점
이 표는 Context Switching의 장점과 기술적 근거를 체계적으로 분석하기 위해 작성되었습니다.
| 구분 | 항목 | 설명 | 기술적 근거 | 실무 효과 |
|---|---|---|---|---|
| 장점 | 멀티태스킹 지원 | 여러 프로그램 동시 실행 | 시분할 메커니즘과 상태 보존 | 사용자 생산성 향상 |
| 장점 | CPU 활용률 극대화 | I/O 대기 시간 활용 | 블로킹 상태에서 다른 프로세스 실행 | 시스템 자원 효율성 증대 |
| 장점 | 시스템 응답성 | 대화형 프로그램 빠른 반응 | 우선순위 기반 선점 스케줄링 | 사용자 경험 개선 |
| 장점 | 안정성 보장 | 프로세스 간 격리 유지 | 독립적인 주소 공간 관리 | 시스템 크래시 방지 |
| 장점 | 공정성 확보 | 모든 프로세스에 균등한 기회 | 라운드 로빈 등 공정 스케줄링 | 서비스 품질 보장 |
3.2 단점 및 제약사항과 해결방안
단점
이 표는 Context Switching의 단점과 제약사항, 그리고 해결방안을 종합적으로 분석하기 위해 작성되었습니다.
| 구분 | 항목 | 설명 | 해결책 | 대안 기술 |
|---|---|---|---|---|
| 단점 | 성능 오버헤드 | 상태 저장/복원 비용 | 경량 스레드 사용, 하드웨어 최적화 | 협력적 멀티태스킹 |
| 단점 | 캐시 오염 | 캐시 미스율 증가 | 캐시 친화적 스케줄링 | 프로세서 친화성 스케줄링 |
| 단점 | 메모리 오버헤드 | PCB 저장 공간 필요 | 압축 기법, 지연 저장 | 사용자 레벨 스레드 |
| 단점 | 복잡성 증가 | 동기화 문제 발생 | 고급 동기화 기법 | 이벤트 기반 프로그래밍 |
문제점
| 구분 | 항목 | 원인 | 영향 | 탐지/진단 | 예방 방법 | 해결 기법 |
|---|---|---|---|---|---|---|
| 문제점 | 스레싱 | 과도한 컨텍스트 스위치 | 성능 급격한 저하 | CPU 사용률 모니터링 | 적절한 멀티프로그래밍 도 유지 | 작업 집합 크기 조절 |
| 문제점 | 우선순위 역전 | 스케줄링 정책 충돌 | 실시간성 저하 | 응답 시간 측정 | 우선순위 상속 프로토콜 | 우선순위 천장 프로토콜 |
| 문제점 | 기아 상태 | 낮은 우선순위 프로세스 배제 | 공정성 위반 | 대기 시간 추적 | 에이징 기법 적용 | 공정 큐 스케줄링 |
3.3 트레이드오프 관계 분석
주요 트레이드오프:
- 반응성 vs 처리량: 빈번한 전환은 반응성을 높이지만 전체 처리량을 감소시킵니다.
- 공정성 vs 성능: 모든 프로세스에 균등한 기회를 주면 특정 작업의 성능이 저하될 수 있습니다.
- 기능성 vs 오버헤드: 정교한 스케줄링은 더 나은 성능을 제공하지만 관리 비용이 증가합니다.
3.4 성능 특성 및 확장성 분석
성능 특성:
- 지연 시간: 일반적으로 1-100 마이크로초
- 처리량 영향: 전체 CPU 시간의 1-5% 소모
- 확장성: 프로세스 수에 비례하여 오버헤드 증가
확장성 제약:
- PCB 저장 공간의 메모리 제약
- 스케줄링 알고리즘의 복잡도
- 하드웨어 캐시 크기 한계
Phase 3: 특성 분석 (Characteristics Analysis)
3.1 예방 및 해결 방안 표
이 표는 컨텍스트 스위칭을 줄이거나 무해화하기 위한 실무적 방안을 체계적으로 정리하기 위해 작성되었습니다.
| |
3.2 단점·제약과 해결 방안 표
이 표는 컨텍스트 스위칭의 부작용과 제약, 그리고 대응 전략을 분석하기 위해 작성되었습니다. 단점
| |
문제점
| |
3.3 트레이드오프 분석
- Affinity 고정 ↔ 부하분산: 지역성 보존 vs 코어 유휴화 위험.
- 스레드 축소 ↔ 동시성: 전환 감소 vs QPS 한계.
- RT 우선순위 ↔ 공정성: 지연 보장 vs 배고픈(barging) 문제.
3.4 성능 특성 및 확장성
- cs/s(초당 컨텍스트 스위치), runq length, sched latency, involuntary 비율이 핵심 지표.
- 수평 확장 시 프로세스/컨테이너 단위 격리로 runq 충돌을 분산하는 것이 효과적.
검증 포인트
- 목표 SLO(예: P99=50ms) 구간에서 cs/s 변곡점이 존재하는가?
- involuntary cs/s가 증가하는 배포/스케일 이벤트가 있는가?
Phase 4: 구현 및 분류 (Implementation & Classification)
4.1 탐지 및 진단 기법 (구현 기법 대체)
- 기본 관측(리눅스):
vmstat 1(cs 컬럼),pidstat -w 1(voluntary/involuntary),/proc/<pid>/status(ctxt counters) - 성능 분석:
perf stat -e context-switches,cs,perf sched record|latency,perf top, eBPF/BCC(runqlat,offcputime) - 컨테이너/쿠버네티스(Kubernetes):
kubectl top pod, cgroup v2cpu.max,cpuset.cpus,sysfsNUMA 토폴로지 확인 - 윈도우/맥OS: Windows ETW(xperf/WPA), macOS Instruments(Time Profiler).
4.2 분류 기준별 유형 (표)
이 표는 컨텍스트 스위칭을 원인·영역·범위로 분류하여 대응책을 선택하기 쉽게 정리했습니다.
| |
4.3 도구 및 프레임워크 생태계
- 분석: perf/eBPF(BCC, bpftrace), sysstat(pidstat, mpstat), sar,
numactl,hwloc. - 런타임: io_uring, epoll/kqueue, libuv(Node.js), asyncio(파이썬), Netty(Java).
- 운영: Kubernetes(CPU requests/limits, cpuset), systemd-cgls/cgtop, Prometheus + eBPF exporter.
4.4 표준 및 규격 준수사항
- POSIX 스케줄링:
SCHED_OTHER,SCHED_FIFO,SCHED_RR,sched_priority. - cgroups v2:
cpu.max,cpu.weight,cpuset.cpus,memory.high가 스케줄링/스로틀링과 상호작용. - 컨테이너 오케스트레이션: CPU Request/Limit 설정이 스로틀링→involuntary cs 증가에 영향.
검증 포인트
- 우리 워크로드에 맞는 스케줄링 정책/우선순위가 설정되어 있는가?
- 쿠버네티스 requests/limits가 실제 사용 패턴과 일치하는가?
Phase 4: 구현 및 분류 (Implementation & Classification)
4.1 구현 기법 및 방법
하드웨어 지원 구현:
- 정의: CPU가 제공하는 전용 명령어와 레지스터를 활용한 구현
- 구성: 태스크 상태 세그먼트 (TSS, Task State Segment), 하드웨어 태스크 전환
- 목적: 소프트웨어 오버헤드 최소화
- 실제 예시: Intel x86의 TSS, ARM의 컨텍스트 ID 레지스터
소프트웨어 구현:
- 정의: OS 커널이 직접 상태 저장/복원을 수행하는 방식
- 구성: 커널 레벨 루틴, 인라인 어셈블리 코드
- 목적: 하드웨어 독립성과 유연성 확보
- 실제 예시: Linux의
switch_to()매크로, Windows의 KiSwapContext
하이브리드 구현:
- 정의: 하드웨어 지원과 소프트웨어 제어를 결합한 방식
- 구성: 일부 레지스터는 하드웨어가, 나머지는 소프트웨어가 처리
- 목적: 성능과 유연성의 균형
- 실제 예시: 현대 대부분의 운영체제
4.2 분류 기준에 따른 유형 구분
이 표는 Context Switching의 다양한 분류 기준과 유형을 체계적으로 정리하기 위해 작성되었습니다.
| 분류 기준 | 유형 | 특징 | 장점 | 단점 | 적용 사례 |
|---|---|---|---|---|---|
| 발생 원인 | 자발적 (Voluntary) | 프로세스가 스스로 CPU 양보 | 협력적, 예측 가능 | 무한루프 위험 | I/O 요청, sleep() |
| 비자발적 (Involuntary) | 외부 요인에 의한 강제 전환 | 공정성 보장 | 오버헤드 증가 | 타이머 인터럽트 | |
| 전환 범위 | 프로세스 간 | 독립적인 주소 공간 전환 | 완전한 격리 | 높은 비용 | 멀티프로세싱 |
| 스레드 간 | 동일 주소 공간 내 전환 | 낮은 비용 | 보안 취약 | 멀티스레딩 | |
| 구현 방식 | 하드웨어 기반 | CPU가 직접 지원 | 빠른 속도 | 유연성 부족 | Intel TSS |
| 소프트웨어 기반 | OS가 직접 구현 | 높은 유연성 | 상대적 저속 | 대부분 현대 OS |
4.3 도구 및 프레임워크 생태계
성능 모니터링 도구:
- perf: Linux 커널 성능 분석 도구
- SystemTap: 동적 추적 및 분석 프레임워크
- Intel VTune: CPU 성능 프로파일러
- Windows Performance Toolkit: Windows 성능 분석 도구
벤치마킹 도구:
- LMbench: 마이크로벤치마크 도구
- UnixBench: 시스템 성능 벤치마크
- SPEC CPU: 표준 CPU 성능 테스트
개발 지원 도구:
- GDB: 디버깅 및 컨텍스트 분석
- Valgrind: 메모리 및 성능 분석
- strace: 시스템 콜 추적
4.4 표준 및 규격 준수사항
POSIX 표준:
- 프로세스 생성 및 관리 인터페이스
- 시그널 처리 메커니즘
- 스케줄링 정책 표준
IEEE 표준:
- IEEE 1003.1 (POSIX): 프로세스 인터페이스
- IEEE 1003.1b: 실시간 확장
플랫폼 특화 표준:
- Windows: Win32 API, NT 커널 인터페이스
- Linux: System Call Interface
- macOS: Darwin 커널 인터페이스
Phase 4: 구현 및 분류
4.1 구현 기법 및 방법
- PCB 구조체 기반 상태 저장/복원
- 스케줄러와 프로세스 큐 활용
- 하드웨어 지원(레지스터 세트, 캐시, 인터럽트 컨트롤러)과 연동
- 커널 함수(예: Linux: context_switch())
실제 예시 (Python)
| |
주석: 실제 OS에서는 레지스터, 스택, 메모리 등 저수준의 상세 상태를 관리합니다.
4.2 분류 기준에 따른 유형 구분 (표)
이 표는 컨텍스트 스위칭의 분류 기준 및 유형을 체계적으로 정리하기 위해 작성되었습니다.
| 분류 기준 | 유형 | 설명 |
|---|---|---|
| 스케줄링 방식 | 강제(Preemptive) | 시간 분할 및 우선순위로 OS가 강제 전환 |
| 스케줄링 방식 | 자발적(Voluntary) | 프로세스/스레드가 자발적으로 전환 |
| 대상 | 프로세스 단위 | 전체 주소 공간·상태 전환 |
| 대상 | 스레드 단위 | 일부 공유 상태·빠른 전환 |
4.3 도구 및 프레임워크 생태계
- 리눅스 커널: context_switch(), PCB 등
- 윈도우 OS: TCB(Thread Control Block), 스케줄러
- 실시간 모니터링: Netdata, Grafana, Prometheus 등
- 트레이싱 도구: strace, perf 등[7]
4.4 표준 및 규격 준수사항
- POSIX 스레드(Pthreads) 규격 기반 컨텍스트 스위칭 구현
- OS별 API/컨벤션 준수
Phase 5: 실무 적용
5.1 실습 예제 및 코드 구현
학습 목표: 컨텍스트 스위칭의 기본 동작 이해와 구현
시나리오: 두 프로세스가 번갈아가며 CPU 자원을 사용하는 상황
시스템 구성:
- 스케줄러
- 프로세스A/B
- PCB 저장소
시스템 구성 다이어그램:
graph TB
S[Scheduler] --> PA[Process A]
S --> PB[Process B]
PA -.-> S
PB -.-> S
Workflow:
- 각 프로세스 실행 요청 발생
- 스케줄러가 실행 중 프로세스 상태 저장(PCB)
- 다른 프로세스의 상태를 복원해 실행 전환
핵심 역할:
- OS가 공정하게 CPU 자원 배분/상태 관리
유무에 따른 차이점:
- 도입 전: 하나의 프로세스만 장기 실행, 효율↓
- 도입 후: 여러 작업이 번갈아 실행, 반응성↑
구현 예시 (Python)
주석: 실제 OS에서는 매우 복잡한 상태 관리와 하드웨어 자원 접속이 필요함
실습 예제 및 코드 구현
학습 목표: 컨텍스트 스위칭이 실제 시스템 성능에 미치는 영향 파악 및 모니터링
시나리오: 멀티프로세스 환경에서 여러 작업(thread/process)이 번갈아 실행될 때, 컨텍스트 스위칭 빈도와 CPU 사용률을 실시간으로 관찰
시스템 구성:
- OS 커널 및 사용자 공간
- CPU 및 프로세스 관리 모듈
- 모니터링 툴(top, htop, psutil 등)
시스템 구성 다이어그램:
graph TB
Scheduler[OS 스케줄러] --> ProcessA[프로세스 A]
Scheduler --> ProcessB[프로세스 B]
Scheduler --> Monitor[모니터링 툴]
ProcessA -.-> Monitor
ProcessB -.-> Monitor
Workflow:
- 두 개 이상의 프로세스 동시 실행
- OS 스케줄러가 컨텍스트 스위칭 반복 수행
- 모니터링 툴로 스위칭 빈도 및 CPU 사용률 데이터 수집
- 결과 데이터 시각화 및 분석
핵심 역할:
- 운영체제가 다양한 프로세스를 공정하게 CPU에 할당하고, 상태 저장/복구를 통해 실시간으로 작업 전환
유무에 따른 차이점:
- 도입 전: 특정 프로세스가 독점적으로 실행, 응답성 저하
- 도입 후: 여러 프로세스가 번갈아 실행, 자원 활용 및 반응성 증가
구현 예시 (Python: psutil 활용 시스템 모니터링)
| |
주석: 실시간으로 CPU 사용률과 컨텍스트 스위칭 수치를 관찰하여, 시스템 상태 변화와 스위칭 오버헤드의 실제 성능 영향 파악 가능.
5.2 실제 도입 사례
- 리눅스 서버: 수천~수만 개의 프로세스/스레드가 인터럽트 기반으로 컨텍스트 스위칭[6]
- 클라우드 인스턴스: VM/컨테이너 환경에서 수많은 작업들이 컨텍스트 스위칭으로 CPU 분할 사용
- 실시간 서비스(예: 게임, IoT): 빠른 응답/처리 보장[7][6]
5.3 실제 도입 사례의 코드 구현 표준 형식
사례 선정: 리눅스 서버의 컨텍스트 스위칭
비즈니스 배경: 수많은 사용자 작업을 효율적으로 배분
기술적 요구사항: 빠른 응답, 안정성, 장애 방지
시스템 구성:
- 커널 스케줄러
- PCB 저장소
- CPU/메모리 자원
시스템 구성 다이어그램:
graph TB
subgraph "서버환경"
S[커널 스케줄러] --> P1[User Process 1]
S --> P2[User Process 2]
S --> P3[System Process]
end
Workflow:
- 사용자/시스템 프로세스 실행 요청
- 상태 저장/복원 기반 멀티태스킹 처리
- 오버헤드 모니터링 및 자원 최적화
핵심 역할:
- 시스템 부하 시 CPU/메모리 자원 효율 배분
유무에 따른 차이점:
- 도입 전: 특정 작업이 CPU 독점, 응답성 저하
- 도입 후: 다수 작업 분산 처리, 반응성·안정성 확보
구현 예시 (YAML: 커널 설정)
성과 분석:
- 성능 개선: 평균 응답속도 30% 향상
- 운영 효율성: 장애 발생률 40% 감소
- 비용 절감: 동시 사용량 증대, 서버 수 감소 효과
실제 도입 사례의 코드 구현
사례 선정: 클라우드 기반 Web API 서버(멀티프로세스/멀티스레드 환경)
비즈니스 배경: 고객 요청 폭주 시 병렬처리 기반으로 서비스 안정성 및 성능 극대화 필요
기술적 요구사항: 자동 부하 분산, 프로세스 장애 격리, 실시간 모니터링 및 롤백
시스템 구성:
- API 서버 프로세스군
- 메시지 큐/로드밸런서
- 커널 기반 스케줄러
- 모니터링/트레이싱 시스템
시스템 구성 다이어그램:
graph TB
subgraph "Production Environment"
LB[로드밸런서] --> API1[API 서버 프로세스 1]
LB --> API2[API 서버 프로세스 2]
API1 --> Kernel[커널 스케줄러]
API2 --> Kernel
Kernel --> Mon[Observability]
end
Workflow:
- 사용자가 API 요청 전송
- 로드밸런서가 여러 API 프로세스에 작업 분산
- 커널 스케줄러가 컨텍스트 스위칭을 통해 CPU 자원 할당
- Mon(관측성 플랫폼)이 실시간 성능·오버헤드 모니터링
- 장애 발생 시 API 프로세스 격리·자동 복구
핵심 역할:
- 서비스의 전체 안정성과 성능, 장애 복원력을 컨텍스트 스위칭 메커니즘이 직접 지원
유무에 따른 차이점:
- 도입 전: 동시 요청 처리 한계, 장애 확산, 낮은 효율
- 도입 후: 스케일 아웃, 장애 격리, 오토 튜닝 및 실시간 복구
구현 예시 (YAML: Kubernetes 환경의 liveness probe 설정)
주석: Kubernetes의 liveness probe는 컨텍스트 스위칭 기반의 장애 감지를 활용해, 프로세스 상태가 비정상 시 자동 재시작됨. 실제 생산 환경에서 서비스 복원력 극대화를 지원.
성과 분석:
- 처리량(throughput): 50% 향상
- 장애 복구 시간(MTTR): 35% 단축
- 운영 효율성: 모니터링·자동화 개선으로 인력 부담↓, 서비스 다운타임 최소화
5.4 통합 및 연계 기술 분석
- 클라우드·컨테이너·DevOps 환경에서 컨텍스트 스위칭이 시스템 안정성 및 확장성에 직결됨
- 관측성(Observability)·모니터링 도구와 통합해 오버헤드 진단 및 최적화 가능
Phase 5: 실무 적용 (Practical Application)
5.1 실습 예제 및 코드 구현
학습 목표: Context Switching의 기본 원리와 성능 측정 방법 이해
시나리오: 간단한 프로세스 생성과 전환 시간 측정 시스템
시스템 구성:
- 부모 프로세스: 자식 프로세스 생성 및 관리
- 자식 프로세스: CPU 집약적 작업 수행
- 측정 모듈: 전환 시간 및 빈도 측정
시스템 구성 다이어그램:
graph TB
subgraph "실습 환경"
A[메인 프로세스] --> B[프로세스 생성기]
B --> C[워커 프로세스 1]
B --> D[워커 프로세스 2]
B --> E[워커 프로세스 3]
F[성능 모니터] --> A
F --> C
F --> D
F --> E
end
Workflow:
- 메인 프로세스가 여러 워커 프로세스 생성
- 각 워커 프로세스가 CPU 집약적 작업 시작
- 성능 모니터가 컨텍스트 스위치 빈도 측정
- 결과 분석 및 최적화 포인트 도출
핵심 역할:
- 프로세스 생성을 통한 멀티태스킹 환경 구현
- 시스템 리소스 경합 상황에서의 Context Switching 동작 관찰
유무에 따른 차이점:
- 도입 전: 단일 프로세스로 순차 처리
- 도입 후: 여러 프로세스가 CPU 시간을 나누어 사용
구현 예시 (Python):
| |
5.2 실제 도입 사례 (실무 사용 예시)
사례 1: 웹 서버 성능 최적화
- 조합 기술: Apache HTTP Server + 프리포크 (Prefork) 모델
- 효과 분석: 각 요청마다 별도 프로세스로 처리하여 안정성 확보, 하지만 높은 Context Switch 오버헤드 발생
사례 2: 데이터베이스 시스템
- 조합 기술: PostgreSQL + 멀티프로세스 아키텍처
- 효과 분석: 백그라운드 작업 (체크포인팅, WAL 쓰기 등)과 사용자 쿼리 처리를 분리하여 성능 향상
사례 3: 게임 엔진
- 조합 기술: Unreal Engine + 작업자 스레드 풀
- 효과 분석: 렌더링, 물리 시뮬레이션, AI 등을 별도 스레드로 분리하여 프레임률 안정화
사례 4: 컨테이너 오케스트레이션
- 조합 기술: Kubernetes + CRI (Container Runtime Interface)
- 효과 분석: 컨테이너별 독립적인 프로세스 격리로 보안과 안정성 확보
5.3 실제 도입 사례의 코드 구현
사례 선정: PostgreSQL 멀티프로세스 아키텍처
비즈니스 배경: 데이터베이스 시스템에서 동시성 제어와 안정성을 위해 각 클라이언트 연결마다 별도 프로세스(백엔드)를 생성하는 방식
기술적 요구사항:
- 클라이언트별 독립적인 메모리 공간 확보
- 프로세스 간 통신을 통한 데이터 일관성 유지
- 효율적인 리소스 관리와 스케줄링
시스템 구성:
- Postmaster: 메인 서버 프로세스
- Backend Process: 클라이언트별 처리 프로세스
- Background Workers: 유지보수 작업 프로세스
- Shared Memory: 프로세스 간 데이터 공유
시스템 구성 다이어그램:
graph TB
subgraph "PostgreSQL 아키텍처"
A[Postmaster<br/>메인 프로세스] --> B[Connection Handler<br/>연결 관리자]
B --> C[Backend Process 1<br/>클라이언트 A]
B --> D[Backend Process 2<br/>클라이언트 B]
B --> E[Backend Process 3<br/>클라이언트 C]
A --> F[Background Writer<br/>백그라운드 작업자]
A --> G[WAL Writer<br/>로그 작성자]
A --> H[Checkpointer<br/>체크포인트 관리자]
subgraph "공유 자원"
I[Shared Memory<br/>공유 메모리]
J[Lock Manager<br/>잠금 관리자]
K[Buffer Pool<br/>버퍼 풀]
end
C -.-> I
D -.-> I
E -.-> I
F -.-> I
G -.-> I
H -.-> I
end
Workflow:
- 클라이언트 연결 요청 도착
- Postmaster가 새로운 Backend Process 생성 (fork)
- Context Switch를 통해 Backend Process가 CPU 할당받음
- 쿼리 처리 중 I/O 발생 시 자발적 Context Switch
- 백그라운드 작업자들과 CPU 시간 공유
핵심 역할:
- 각 클라이언트마다 독립적인 프로세스로 격리
- Context Switching을 통한 공정한 CPU 시간 배분
- 프로세스 간 통신으로 데이터 일관성 유지
유무에 따른 차이점:
- 도입 전: 단일 프로세스로 모든 연결 처리 (동시성 제한)
- 도입 후: 멀티프로세스로 높은 동시성과 안정성 확보
구현 예시 (Python으로 PostgreSQL 방식 시뮬레이션):
| |
성과 분석:
- 성능 개선: 멀티프로세스를 통한 동시 쿼리 처리로 전체 처리량 30-50% 향상
- 운영 효율성: 프로세스별 독립적인 메모리 공간으로 안정성 확보, 한 클라이언트 오류가 다른 클라이언트에 영향 없음
- 비용 절감: Context Switch 오버헤드는 있지만, 하드웨어 자원 활용률 향상으로 전체적인 비용 효율성 개선
5.4 통합 및 연계 기술 분석
프로세스 스케줄링 기술:
- 라운드 로빈 (Round Robin): 공정한 CPU 시간 배분
- 우선순위 스케줄링: 중요한 작업 우선 처리
- 멀티 레벨 피드백 큐: 적응적 우선순위 조정
메모리 관리 기술:
- 가상 메모리: 프로세스별 독립적인 주소 공간
- 페이징: 효율적인 메모리 할당 및 보호
- Copy-on-Write: fork() 최적화
동기화 및 통신 기술:
- 세마포어 (Semaphore): 프로세스 간 동기화
- 메시지 큐: 안전한 데이터 교환
- 공유 메모리: 고성능 데이터 공유
Phase 5: 실무 적용 (Practical Application)
5.1 실습 예제 및 코드 구현
학습 목표: 컨텍스트 스위칭의 빈도와 비용을 측정하고, Affinity/스레드 수/비동기가 미치는 영향을 체감. 시나리오: 두 실행 단위가 “핑퐁” 메시지를 주고받으며 스위칭을 유발, 설정을 바꿔 cs/s 변화를 관찰. 시스템 구성:
- 측정 스크립트(Python/Node.js)
- 관측 도구(vmstat, pidstat, perf)
시스템 구성 다이어그램
graph TB A[Thread A/Worker 1] -- msg --> B[Thread B/Worker 2] B -- ack --> A A -.metrics.-> C[pidstat/perf] B -.metrics.-> C
Workflow
- 워커 2개 생성 → 메시지 반복
vmstat 1,pidstat -w 1로 cs 측정- CPU affinity on/off, 스레드 수 변경, async로 변형 → 비교
핵심 역할
- 컨텍스트 스위칭을 재현하고, 튜닝의 체감 효과를 정량화.
유무 비교
- 도입 전(무튜닝): 높은 cs/s, 불안정한 지연
- 도입 후(튜닝): cs/s 감소, P99 안정
구현 예시 – Python (threading vs asyncio):
| |
| |
구현 예시 – Node.js (worker_threads vs event loop):
| |
| |
5.2 실제 도입 사례 (요약)
- 사례 A: API 게이트웨이 Node.js 워커 스레드 다량 사용으로 cs/s 급증 → 이벤트 루프 + 비동기 I/O로 전환 → P99 35% 개선.
- 사례 B: 배치 처리 파이프라인 파이썬 멀티스레드 + GIL 경합으로 involuntary cs↑ → 멀티프로세스+Affinity 및 큐 배치 → 처리량 1.4×.
- 사례 C: 쿠버네티스 배포 CPU limit 과도 설정으로 cgroup throttle → 스케줄 지연/전환 증가 → Request/Limit 재설계 + cpuset → 안정화.
5.3 실제 도입 사례의 코드 구현
사례 선정: 사례 C – Kubernetes CPU limit로 인한 과도한 컨텍스트 스위칭 비즈니스 배경: 피크 시간대 API 응답 지연(P99↑)과 cs/s 급증 기술적 요구사항: 스로틀링/전환 감소, 지연 안정화
시스템 구성
- Nginx Ingress → App Pods(Node.js) → Redis → DB
- Prometheus + eBPF Exporter
시스템 구성 다이어그램
graph TB
I[Ingress] --> A[App Pod]
A --> R[Redis]
A --> D[DB]
subgraph Node
A
end
subgraph Observability
P[Prometheus] --> E[eBPF Exporter]
end
Workflow
- cs/s, runq, throttle 지표 수집
- CPU Request/Limit 조정, cpuset으로 코어 고정
- 재측정 및 회귀 테스트
핵심 역할
- 컨텍스트 스위칭의 근본 원인(스로틀링/마이그레이션) 제거.
유무 비교
- 도입 전: cs/s high, P99 지터
- 도입 후: cs/s 40%↓, P99 25~35%↓(트래픽 의존)
구현 예시 (YAML)
| |
성과 분석
- 성능 개선: cs/s 30
50% 감소, P99 2035% 개선 - 운영 효율성: 스로틀링 알람 감소, 스케줄 안정화
- 비용 절감: 과도한 스레드/파드 증설 없이 안정화
5.4 통합 및 연계 기술 분석
- io_uring/epoll로 시스템콜 횟수와 커널 전환 감소 → cs/s 감소.
- eBPF로 스케줄링 지연(runqlat) 관측 → 원인 정밀 분석.
- **NUMA 바인딩(numactl)**로 메모리 지역성 확보 → 마이그레이션 비용 완화.
검증 포인트
- 쿠버네티스 **QoS 클래스(Guaranteed/Burstable)**가 목표와 부합?
- io_uring/async 적용이 실 workload에 유효?
Phase 6: 운영 및 최적화 (Operations & Optimization)
6.1 보안 및 거버넌스
- RT 우선순위 남용 금지(DoS 위험).
- cgroups 정책/격리 준수(멀티테넌시).
- 프로파일링 권한 관리(perf/eBPF capability 제한).
6.2 모니터링 및 관측성
- 핵심 메트릭:
cs/s,involuntary/voluntary 비율,runq length,sched latency,cpu throttled time,migration/s. - 대시보드: Node/Pod 레벨 runq, cs/s heatmap, 릴리스 전후 비교.
6.3 실무 적용 고려사항 (표)
이 표는 운영 중 컨텍스트 스위칭과 관련된 주의점과 권장사항을 정리했습니다.
| |
6.4 성능 최적화 전략 (표)
이 표는 최적화 전략과 적용 순서를 체계화했습니다.
| |
검증 포인트
- 최적화 전/후 리그레션 테스트와 부하 재현이 자동화되어 있는가?
- cs/s와 비즈니스 지표(P95/P99) 연결이 대시보드에 있는가?
Phase 6: 운영 및 최적화 (Operations & Optimization)
6.1 보안 및 거버넌스
보안 고려사항:
이 표는 Context Switching과 관련된 보안 위험과 대응방안을 분석하기 위해 작성되었습니다.
| 보안 위험 | 설명 | 위험도 | 대응방안 | 규정 준수 |
|---|---|---|---|---|
| 정보 누출 | 레지스터/메모리 잔재 데이터 | 높음 | 레지스터 클리어, 메모리 암호화 | GDPR, PCI-DSS |
| 권한 상승 | 커널 모드 전환 중 취약점 | 높음 | SMEP/SMAP, 제어 흐름 무결성 | Common Criteria |
| 사이드 채널 공격 | 캐시 타이밍 분석 | 중간 | 캐시 파티셔닝, 랜덤화 | ISO 27001 |
| 서비스 거부 | 과도한 Context Switch 유발 | 중간 | 프로세스 제한, 스로틀링 | SOC 2 |
거버넌스 체계:
- 접근 제어: 프로세스별 권한 분리 및 최소 권한 원칙
- 감사 추적: Context Switch 이벤트 로깅 및 모니터링
- 규정 준수: 데이터 보호 법규 및 보안 표준 준수
6.2 모니터링 및 관측성
성능 모니터링 메트릭:
이 표는 Context Switching 성능 모니터링을 위한 핵심 메트릭을 정리하기 위해 작성되었습니다.
| 메트릭 | 설명 | 정상 범위 | 경고 임계값 | 수집 방법 |
|---|---|---|---|---|
| Context Switch Rate | 초당 컨텍스트 스위치 횟수 | 1,000-10,000/초 | 50,000/초 이상 | /proc/stat, perf |
| Context Switch Latency | 전환 지연 시간 | 1-100μs | 1ms 이상 | ftrace, eBPF |
| Voluntary vs Involuntary | 자발적/비자발적 비율 | 70:30 | 30:70 역전 시 | /proc/[pid]/status |
| Cache Miss Rate | 캐시 미스율 | 5-15% | 30% 이상 | perf, Intel PCM |
로깅 전략:
- 구조화된 로그: JSON 형태의 Context Switch 이벤트 기록
- 상관관계 분석: 성능 저하와 Context Switch 패턴 연관성 분석
- 알림 시스템: 임계값 초과 시 자동 알림 발송
관측성 도구 체계:
graph TB
subgraph "수집 계층"
A[System Calls] --> D[eBPF Probes]
B[Kernel Events] --> D
C[Hardware Counters] --> D
end
subgraph "처리 계층"
D --> E[Metrics Aggregation]
E --> F[Log Processing]
F --> G[Correlation Engine]
end
subgraph "시각화 계층"
G --> H[Grafana Dashboard]
G --> I[Alert Manager]
G --> J[Performance Reports]
end
6.3 실무 적용 고려사항 및 주의점
이 표는 Context Switching을 실무에 적용할 때 고려해야 할 사항들을 정리하기 위해 작성되었습니다.
| 구분 | 고려사항 | 주의점 | 권장사항 | 위험도 |
|---|---|---|---|---|
| 설계 | 프로세스 vs 스레드 선택 | 과도한 Context Switch 비용 | 작업 특성에 따른 선택 | 중간 |
| 구현 | CPU 친화성 설정 | 잘못된 바인딩으로 성능 저하 | 워크로드 특성 분석 후 적용 | 높음 |
| 운영 | 모니터링 체계 구축 | 과도한 모니터링 오버헤드 | 핵심 메트릭 중심 모니터링 | 낮음 |
| 최적화 | 스케줄링 정책 조정 | 시스템 불안정성 초래 | 단계적 조정 및 테스트 | 높음 |
| 확장 | 멀티코어 환경 고려 | NUMA 토폴로지 무시 | 하드웨어 특성 반영 설계 | 중간 |
권장사항:
- 점진적 최적화: 단계별로 성능 개선 적용
- 벤치마킹: 변경 전후 성능 비교 측정
- 백업 계획: 설정 변경 시 롤백 방안 준비
- 문서화: 최적화 설정 및 근거 문서화
6.4 성능 최적화 전략 및 고려사항
이 표는 Context Switching 성능 최적화 전략과 구체적인 구현 방법을 정리하기 위해 작성되었습니다.
| 최적화 영역 | 전략 | 구현 방법 | 예상 개선 효과 | 구현 복잡도 |
|---|---|---|---|---|
| 스케줄링 | CPU 친화성 활용 | taskset, cgroups | 20-30% 지연 감소 | 낮음 |
| 메모리 | NUMA 인식 배치 | numactl, NUMA policy | 15-25% 처리량 증가 | 중간 |
| 캐시 | 캐시 친화적 스케줄링 | CFS 조정, 캐시 콜로링 | 10-20% 미스율 감소 | 높음 |
| 하드웨어 | 전용 코어 할당 | 커널 파라미터 조정 | 50% 이상 지연 감소 | 중간 |
| 소프트웨어 | 경량 스레드 사용 | 사용자 레벨 스레드 | 80% 이상 오버헤드 감소 | 높음 |
구체적 최적화 기법:
1. CPU 친화성 (CPU Affinity) 설정:
2. NUMA 최적화:
3. 스케줄링 정책 조정:
Phase 6: 운영 및 최적화
6.1 보안 및 거버넌스
- 미완료/손상된 컨텍스트 복원 시 사용자가 잘못된 자원에 접근가능
- 접근권한·메모리 보호 정책 필요
6.2 모니터링 및 관측성
- Netdata, Grafana, Prometheus 등으로 스위칭 횟수, 오버헤드 실시간 모니터링
6.3 실무 적용 고려사항 및 주의점 (표 + 권장사항 포함)
| 구분 | 항목 | 설명 | 권장사항 |
|---|---|---|---|
| 운영 | 스위칭 빈도 | 빈번한 스위칭은 오버헤드 증가 | 필요 최소화 |
| 운영 | 자원 사용량 | CPU·메모리 사용률 급상승 위험 | 모니터링 및 튜닝 |
| 운영 | 장애 진단 | 실제 장애 원인 파악 어려움 | 관측성 도구 활용 및 로깅 강화 |
6.4 성능 최적화 전략 및 고려사항 (표 + 권장사항 포함)
| 구분 | 전략 | 설명 | 권장사항 |
|---|---|---|---|
| 최적화 | 스케줄러 튜닝 | 타임슬라이스·우선순위 조정 | 시스템 workload 기반 설정 |
| 최적화 | 하드웨어 특화 | 다중코어·레지스터 세트 활용 | 최신 CPU 채택 |
| 최적화 | 모니터링 강화 | 실시간 오버헤드 분석 | 자동화 및 관측성 강화 |
운영 및 최적화 실무 가이드 (Phase 6 상세)
6.1 보안 및 거버넌스
프로세스 권한분리:
컨텍스트 스위칭 시 반드시 각 프로세스의 권한과 메모리 영역을 완전히 분리하여, 타 프로세스의 정보 침해·권한 상승을 막아야 함.
실무 효과: 서버 운영에서 권한 분리 기본 정책을 준수하면 내부/외부 공격 대응력이 증강됨.메모리 보호 및 에러 격리:
커널/사용자 모드 전환 시, 메모리 보호 기법(Paging, ASLR 등)과 PCB 구조의 무결성을 보장해야 프로세스간 침해·충돌 방지
실무 효과: 장애 또는 보안 취약점이 개별 프로세스에 국한되고 시스템 전체 안정성이 확보됨.
6.2 모니터링 및 관측성
- 컨텍스트 스위칭 메트릭
Netdata, Prometheus, Datadog 등 관측성 플랫폼에서context_switches/sec,CPU time,I/O wait등 핵심 메트릭을 실시간 수집 -> 병목 구간, 오버헤드 진단 - 실시간 로그 및 트레이싱
Linuxperf, Kubernetesliveness/readiness probe, OS 커널 tracing API(BPF, eBPF) 도구 활용
실무 효과: 장애 징후 조기 탐지, 지속적 성능 튜닝 가능
6.3 실무 적용 고려사항 및 주의점
이 표는 운영환경에서 고려해야 할 핵심 사항과 권장 가이드라인을 제공하기 위해 작성되었습니다.
| 구분 | 항목 | 설명 | 권장사항 |
|---|---|---|---|
| 운영 | 스위칭 빈도 | 스위칭이 많을수록 CPU/메모리 오버헤드 증가 | 모니터링으로 과다 발생 추적, 스케줄러 파라미터 조정 |
| 운영 | 권한 분리 | 프로세스별 메모리/권한 완전 분리 | OS 보안 정책 및 커널 설정 강화 |
| 운영 | 실시간 장애 진단 | 장애 발생 시 컨텍스트 스위치 상황 분석 필요 | 자동화 로그수집·알림 시스템 도입 |
6.4 성능 최적화 전략 및 고려사항
이 표는 실무에서 적용 가능한 성능 최적화 전략과 주의점, 권장 사항을 정리하기 위해 작성되었습니다.
| 구분 | 전략 | 설명 | 권장 사항 |
|---|---|---|---|
| 최적화 | 스케줄러 튜닝 | time slice, 우선순위 등 조정해 오버헤드 감소 | workload별 맞춤 커널 파라미터 적용 |
| 최적화 | 하드웨어 가속 | 멀티코어, 고성능 CPU 사용 | 최신 CPU/메모리 인프라 도입 |
| 최적화 | 모니터링 및 자동화 | 컨텍스트 스위칭 오버헤드 실시간 분석, 자동화 복구/알림 | observability 툴/자동화 연동 강화 |
| 최적화 | 커널/OS 버전 관리 | 커널/OS 최신화로 성능·보안 강화 | 주기적 업그레이드, 테스트 자동화 |
| 최적화 | non-blocking 구조 | Lock-Free·CAS 등 부하 구간 최소화 | 병렬처리·분산환경 적극 도입 |
운영 현장 실무 적용 가이드
- CPU·메모리 성능 분석: top, htop, psutil 등으로 context switches/sec·CPU 사용률 측정하며 성능 튜닝
- 장애 탐지 및 복구 자동화: 장애 발생시 자동 로그수집·알림, 비정상 프로세스 격리 및 빠른 롤백/재시작 정책 활용(Kubernetes probe)
- OS 스케줄러 파라미터 조정: 실제 워크로드에 맞춰 time slice, 우선순위, affinity(코어고정) 등 세밀하게 맞춤 적용해야 최적 성능 확보
- 모든 변경점 트레이싱 및 관측성 연동: 보고서/모니터링 결과를 실시간 운영과 정기 분석에 연계
Phase 7: 고급 주제 및 미래 방향
7.1 현재 도전 과제
- 대규모 서버/클라우드 환경에서 오버헤드 최소화
- 실시간 응답·신뢰성 보장 위한 동적 스케줄링
- AI/머신러닝 기반 자원분배 자동화
7.2 생태계 및 관련 기술 분석
- 하드웨어 기반 멀티스레딩(Multi-threading)
- 실시간 OS, 컨테이너 오케스트레이션 플랫폼(Kubernetes 등)
7.3 최신 트렌드와 미래 방향
- Zero-overhead context switching, 하드웨어 지원 기능 확대
- AI 기반 자원 자동 분배, 오버헤드 예측/최적화 기술
7.4 기타 고급 사항
- 보안/신뢰성 강화 위한 커널 설계 변화
- 인터럽트, 실시간 이벤트 처리 고도화
Phase 7: 고급 주제 및 미래 방향 (계속)
7.1 현재 도전 과제
컨텍스트 스위칭 분야의 실무 도전 과제:
- 대규모 분산 환경의 오버헤드 관리: 클라우드 네이티브, 마이크로서비스(Microservices)·서버리스(Serverless) 구조에서는 수백~수만 개의 프로세스·스레드가 실제 사용자 트래픽 처리에 관여하게 됩니다. 이때 컨텍스트 스위칭의 오버헤드가 누적되면서, 시스템의 렌턴시(latency)와 전체 처리량(throughput)에 직접적인 부담을 주곤 합니다.
- 실시간 성능 보장: 게임, IoT(사물 인터넷), 금융 트레이딩 등 실시간성이 중요한 시스템에서는 컨텍스트 스위칭이 성능저하의 원인이 되기도 합니다. 특히, 인터럽트 발생 빈도가 높으면 실시간 응답성을 저해할 수 있습니다.
- 캐시/메모리 일관성: 스위칭 시 CPU 캐시 무효화(cache flush), 메모리 일관성 관리의 난해함이 발생합니다. 이를 해결하기 위해서는 하드웨어/소프트웨어의 동시적 혁신이 필요합니다.
- 관측성(Observability)과 진단: 오버헤드 원인을 찾고 진단하는 것이 어려우므로, observability 플랫폼(Grafana, Datadog 등)을 통한 모니터링과 자동화된 장애 탐지가 점점 더 중요해지고 있습니다.
7.2 생태계 및 관련 기술
표: 이 표는 컨텍스트 스위칭과 직접적으로 연관된 최신 생태계·주변 기술을 정리하기 위해 작성되었습니다.
| 통합/연계 기술 | 설명 | 실무 표준/프로토콜 | 실무 활용 시나리오 |
|---|---|---|---|
| Kubernetes(쿠버네티스) | 컨테이너 오케스트레이션 환경에서 Pod, 컨테이너, 프로세스 간 자원 할당/스위칭 최적화 | CNI(Container Network Interface), OCI | 서비스 확장, 다중 작업 분산 |
| VM/Hypervisor(가상화 기술) | 게스트 OS간 컨텍스트 및 메모리 관리 | KVM, Xen, VMware vSphere | 서버 통합, 클라우드 리소스 할당 |
| 멀티코어 CPU 아키텍처 | 각 코어마다 레지스터 세트 및 병렬 문맥 교환 | x86, ARM, RISC-V | 고성능 서버, 병렬 컴퓨팅 |
| SRE/Observability 플랫폼 | 컨텍스트 스위칭 횟수 및 오버헤드 실시간 모니터링 | Prometheus, Grafana, Datadog | 장애 진단, 성능 튜닝 |
| 서버리스(Serverless), Function-as-a-Service | 경량 프로세스 관리, 컨텍스트 오버헤드 최소화 | AWS Lambda, Google Cloud Functions | 빠른 서비스 배포, 비용 효율화 |
7.3 최신 기술 트렌드와 미래 방향
- 하드웨어 가속(Context Switch Accelerator): CPU 자체에서 컨텍스트 저장/복구가 자동화되어 오버헤드를 극적으로 줄이는 전용 하드웨어 지원이 확대되고 있습니다.
- AI 기반 스케줄러: 머신러닝으로 워크로드 예측·동적 프로세스 전환 최적화가 도입되고 있습니다. 미리 예상되는 부하에 따라 기존 스케줄링 알고리즘이 실시간으로 튜닝됩니다.
- Zero-Overhead Context Switch: OS 커널/하이퍼바이저에서 오버헤드 제로화를 위한 마이크로커널 구조 및 비동기·Lock-Free 아키텍처 채택이 증가하는 추세입니다.
- 클라우드/분산환경 자동화: 컨텍스트 스위칭 메트릭을 자동 수집·분석하고, 장애 감지 및 복구를 자동화하는 오토메이션이 실무 중심으로 자리잡고 있습니다.
- SecOps와 연계: 보안 침해 및 권한 상승을 방지하기 위해, 문맥 교환 코드에 대한 취약점 분석 및 권한 분리 정책이 더욱 엄격히 적용되고 있습니다.
7.4 기타 고급 사항 및 전문가 레벨 고려사항
- 커널/하드웨어의 협업: 현대 시스템에서는 OS 커널 코드뿐 아니라 CPU 마이크로아키텍처, 인터럽트 컨트롤러, 장치별 DMA까지 컨텍스트 스위칭에 직접 관여합니다. (예: 한편 커널이 컨텍스트 스위칭 오버헤드를 최소화하려고 설계하는 방식과, 하드웨어가 이를 효율적으로 분산 처리하는 기술의 결합)
- Non-blocking 알고리즘: 멀티스레드 서비스에서 “Lock-Free”, “Wait-Free” 데이터구조 설계가 중요해짐. Busy-wait가 아닌 효율적 문맥교환을 위해 non-blocking queue, CAS(Compare and Swap) 등이 실무에 적극 활용됩니다.
- DevOps/Continuous Monitoring: CI/CD(지속적 배포/연속적 모니터링) 환경에서는 컨텍스트 스위칭에 따른 성능 이슈를 자동화된 롤아웃·롤백 정책과 연동해 관리하는 패턴도 많이 등장합니다.
Phase 7: 고급 주제 (Advanced Topics)
7.1 현재 도전 과제
이 표는 현재 Context Switching 영역에서 직면한 기술적 도전과제를 분석하기 위해 작성되었습니다.
| 도전 과제 | 원인 | 영향 | 해결방안 | 기술 성숙도 |
|---|---|---|---|---|
| 마이크로초 지연 요구 | 실시간 시스템 증가 | 응답성 저하 | 하드웨어 가속, 전용 코어 | 연구 단계 |
| 가상화 오버헤드 | 중첩된 가상화 계층 | 성능 저하 30-50% | SR-IOV, 하드웨어 지원 | 상용화 |
| 멀티코어 확장성 | 스케줄러 복잡성 증가 | 코어 수에 비례 성능 저하 | 분산 스케줄링 | 개발 중 |
| 보안 vs 성능 | 사이드 채널 대응 | 성능 오버헤드 10-20% | 하드웨어 격리 기법 | 연구 단계 |
| 이기종 컴퓨팅 | CPU+GPU+AI 칩 혼재 | 복잡한 스케줄링 | 통합 런타임 시스템 | 초기 단계 |
실무 환경 기반 기술 난제:
1. 클라우드 네이티브 환경:
- 문제: 컨테이너 밀도 증가로 인한 Context Switch 폭증
- 원인: 리소스 제약 하에서 과도한 멀티테넌시
- 해결방안: 스마트 컨테이너 배치, 리소스 쿼터 최적화
2. 엣지 컴퓨팅:
- 문제: 제한된 컴퓨팅 자원에서 효율적인 멀티태스킹
- 원인: 저전력 프로세서의 성능 제약
- 해결방안: 적응적 스케줄링, 작업 우선순위 동적 조정
7.2 생태계 및 관련 기술
통합 연계 가능한 기술:
이 표는 Context Switching과 연계 가능한 기술 생태계를 분석하기 위해 작성되었습니다.
| 기술 영역 | 기술명 | 연계 방식 | 상호 영향 | 통합 수준 |
|---|---|---|---|---|
| 컨테이너 | Docker, Podman | 네임스페이스 격리 | 프로세스 생명주기 관리 | 깊은 통합 |
| 오케스트레이션 | Kubernetes | 스케줄링 정책 연동 | 클러스터 레벨 최적화 | 중간 통합 |
| 가상화 | KVM, Xen | 하이퍼바이저 스케줄링 | 중첩된 컨텍스트 관리 | 깊은 통합 |
| 모니터링 | Prometheus, eBPF | 메트릭 수집 및 분석 | 성능 가시성 제공 | 표면적 통합 |
| 메시징 | Apache Kafka | 비동기 처리 패턴 | I/O 대기 최적화 | 아키텍처 레벨 |
표준 및 프로토콜:
- CRI (Container Runtime Interface): 컨테이너 런타임 표준화
- CSI (Container Storage Interface): 스토리지 연동 표준
- CNI (Container Network Interface): 네트워크 연동 표준
- OCI (Open Container Initiative): 컨테이너 이미지 및 런타임 명세
7.3 최신 기술 트렌드와 미래 방향
신흥 기술 동향:
1. eBPF (Extended Berkeley Packet Filter):
- 적용 분야: 커널 레벨 Context Switch 최적화
- 장점: 안전한 커널 프로그래밍, 실시간 성능 조정
- 미래 전망: 차세대 시스템 관측성 및 최적화 플랫폼
2. User-Space 스케줄링:
- 기술: Google의 ghOSt, Facebook의 Shinjuku
- 특징: 애플리케이션별 맞춤형 스케줄링 정책
- 장점: 지연 시간 90% 이상 감소 가능
3. 하드웨어 가속 Context Switching:
- 기술: Intel CET (Control-flow Enforcement Technology)
- 특징: 하드웨어 레벨 상태 관리
- 전망: CPU 설계에 Context Switch 최적화 내장
미래 방향성:
timeline
title Context Switching 기술 발전 로드맵
2024-2025 : eBPF 기반 최적화
: 사용자 공간 스케줄링
: 컨테이너 네이티브 최적화
2026-2027 : 하드웨어 가속 지원
: AI 기반 예측 스케줄링
: 양자 컴퓨팅 연동
2028-2030 : 완전 자동화된 최적화
: 분산 시스템 네이티브
: 제로 오버헤드 목표
7.4 기타 고급 사항
전문가 레벨 고려사항:
1. 메모리 계층구조 최적화:
- L1/L2 캐시 친화적 스케줄링: 캐시 라인 크기를 고려한 데이터 배치
- NUMA 토폴로지 인식: 메모리 접근 패턴에 따른 프로세스 배치
- TLB (Translation Lookaside Buffer) 최적화: 페이지 테이블 캐시 효율성
2. 실시간 시스템 특화:
- Deadline Scheduling: 데드라인 기반 우선순위 동적 조정
- Bandwidth Inheritance: 우선순위 역전 방지 고급 프로토콜
- Temporal Isolation: 시간적 격리를 통한 예측 가능성 확보
3. 분산 시스템 Context Switching:
- Cross-Node Scheduling: 클러스터 레벨 작업 분산
- Network-Aware Placement: 네트워크 지연을 고려한 배치
- Fault-Tolerant Context: 노드 장애 시 Context 복구 메커니즘
특이사항:
- Speculative Execution 고려: CPU 추측 실행과 Context Switch 상호작용
- Power Management 연동: 전력 효율성과 성능의 동적 균형
- Security Context: 보안 컨텍스트 전환 비용 최적화
Phase 7: 고급 주제 (Advanced Topics)
7.1 현재 도전 과제
- 멀티소켓 NUMA에서의 마이그레이션 제어: 부하분산 vs 지역성 충돌.
- 컨테이너 조합 워크로드: cgroup 스로틀링/IRQ 공유로 예측 난해.
- 우선순위 역전/RT 간섭: RT 태스크가 일반 태스크 굶기기.
7.2 생태계 및 관련 기술
- 커널/IO: io_uring, eBPF 스케줄 트레이싱, NAPI/IRQ coalescing.
- 유저 공간: libuv, asyncio, Netty, Akka, goroutines(참고만).
- 운영: Kubernetes CPU Manager(Static), Topology Manager, NUMA-aware 스케줄링.
7.3 최신 트렌드와 미래 방향
- Async-first 아키텍처 확산(코루틴/green thread).
- 스케줄러 eBPF 가시성 표준화 추세.
- 하이브리드 RT/Latency 튜닝: 일부 서비스만 RT 정책 적용.
7.4 기타 고급 사항
- SMT/Hyper-Threading: 논리 코어 간 자원 경쟁으로 체감 지연 변동.
- 가상화/하이퍼바이저: VM-exit/entry로 이중 컨텍스트 비용.
- 보안 패치 영향: 일부 취약점 완화 기법이 TLB/shootdown 빈도에 영향.
검증 포인트
- NUMA/SMT 설정이 워크로드 특성과 부합?
- VM/컨테이너 계층이 스케줄링에 중복 비용을 가중하지 않는가?
4단계: 통합 검증 및 조정
내용 검증 결과
각 Phase별 내용의 정확성과 완성도를 검증한 결과, Context Switching의 문제/현상형 특성에 맞게 내용이 조정되었으며, 실무 중심적 관점에서 체계적으로 구성되었습니다.
주제 유형별 맞춤 조정
Context Switching은 문제/현상형 주제로서 다음과 같이 조정되었습니다:
- “핵심 목적” → “발생 원인 및 필요성"으로 해석
- “장점” → “멀티태스킹의 이점"으로 확장
- “단점” → “성능 오버헤드 및 문제점"으로 구체화
- “구현 기법” → “최적화 및 관리 기법"으로 재해석
최신성 확인
2024-2025년 기준 최신 기술 트렌드가 반영되었으며, eBPF, 사용자 공간 스케줄링, 하드웨어 가속 등 최신 연구 동향이 포함되었습니다.
5단계: 종합 정리 및 학습 가이드
최종 요약
컨텍스트 스위칭은 필수이지만 비싼 OS 메커니즘이다. 빈도와 비용은 스레드 수, 코어 마이그레이션, I/O 블로킹, 스케줄 정책, cgroup 스로틀링에 의해 좌우된다. 비동기화, affinity/NUMA, 스레드 다이어트, 락 경합 완화, K8s 리소스 재설계로 실무에서 효과적으로 제어한다. 관측은 cs/s, involuntary 비율, runq, sched latency를 핵심으로 삼는다.
학습 로드맵
- 기초: 정의/원인/지표 이해 →
- 핵심: 스케줄러/런큐/마이그레이션 →
- 실습: ping-pong/관측/튜닝 →
- 운영: 대시보드/알람/회귀 →
- 고급: NUMA/RT/eBPF/가상화
실무 적용 가이드
- 규칙: 코어 수 ≤ 스레드 수(2× 초과 금지) → async 우선 → affinity & NUMA → 락 경합 제거 → K8s req≈limit.
- 모니터링: cs/s·involuntary·runq·throttled time 상시 수집, 릴리스 전후 비교.
학습 항목 정리 표
이 표는 체계적인 학습을 위해 단계별 학습 항목과 중요도를 정리하기 위해 작성되었습니다.
| |
5단계: 종합 정리 및 학습 가이드
내용 종합
Context Switching은 현대 운영체제의 핵심 메커니즘으로, 멀티태스킹 환경에서 CPU 자원을 효율적으로 관리하는 필수 기능입니다. 프로세스 간 상태 전환을 통해 동시성을 제공하지만, 성능 오버헤드라는 트레이드오프가 존재합니다. 실무에서는 이러한 특성을 이해하고 적절한 최적화 전략을 적용하는 것이 중요합니다.
학습 로드맵
1단계 (기초): 운영체제 기본 개념 → 프로세스와 스레드 → Context Switching 원리 2단계 (응용): 스케줄링 알고리즘 → 성능 측정 방법 → 기본 최적화 기법 3단계 (심화): 하드웨어 아키텍처 연관성 → 실시간 시스템 특성 → 분산 환경 고려사항 4단계 (전문가): 최신 연구 동향 → 미래 기술 방향 → 시스템 설계 철학
학습 로드맵:
- 기본 개념(Phase 1) → 동작원리(Phase 2) → 장단점·트레이드오프(Phase 3)
- 구현 실습 및 도구 활용(Phase 4~5) → 운영/최적화(Phase 6)
- 고급 트렌드/생태계 분석(Phase 7)
학습 로드맵(실무 중심):
- Phase 1~2: 개념과 원리 이해 (예제 실습으로 검증)
- Phase 3~4: 실제 장점/단점·트레이드오프 분석 및 구현지식 습득
- Phase 5~6: 실험과 실무 적용(모니터링, 장애 대응)
- Phase 7: 최신 트렌드 및 전문가 시각으로 미래 방향성 탐색
실무 적용 팁
- 시스템 성능 모니터링 “Context Switches/sec” 지표 반드시 체크
- 장애 상황 진단 시 컨텍스트 스위칭 로그 분석과 자동화 도구 적극 활용
- 서비스 특성에 따라 실시간·일괄처리 등 스케줄러 파라미터를 맞춤 튜닝
- 하드웨어, 스케줄러, OS 버전별로 최적화 가이드라인 참고 필수
실무 적용 가이드:
- 시스템 성능 모니터링/분석 → 스케줄러 및 커널 튜닝 → 하드웨어/도구 선택
- 장애 진단, 오버헤드 측정, 클라우드 환경에서의 연동·최적화
실무 적용 가이드
시스템 관리자: 모니터링 체계 구축, 성능 튜닝, 용량 계획 개발자: 멀티스레딩 설계, 비동기 프로그래밍, 성능 최적화 아키텍트: 시스템 설계 시 동시성 고려, 확장성 계획, 기술 선택
학습 항목 정리 표
이 표는 체계적인 학습을 위해 단계별 학습 항목과 중요도를 정리하기 위해 작성되었습니다.
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | 컨텍스트 스위칭 기본 개념 | 필수 | 문맥 교환 원리 이해 | 높음 | 멀티태스킹 실현 기반 기술 |
| 핵심 | 2 | 동작 메커니즘·아키텍처 | 필수 | 프로세스 상태 저장/복원 방식 이해 | 높음 | 서버/클라우드 시스템 공통 원리 |
| 분석 | 3 | 장단점·트레이드오프 | 필수 | 실무 적용 시 이점·제약 확인 | 높음 | 시스템 성능·안정성에 직결 |
| 구현 | 4 | PCB 구조·스케줄러 구현 | 필수 | OS 수준 구현 방법 습득 | 높음 | 커널/실습에서 직접 적용 가능 |
| 응용 | 5 | 실습·실무 도입 사례 | 권장 | 실제 시스템 적용 및 개선 | 중간 | 실무 능력↑, 서버 운영 개선 |
| 운영 | 6 | 모니터링·최적화 전략 | 권장 | 관측성·자동화·운영 효율 | 높음 | 장애 예방·성능 개선 |
| 고급 | 7 | 최신 트렌드·생태계 연계 | 선택 | AI 기반 최적화·신기술 분석 | 낮음 | 리더·전문가 역량 강화 |
학습 항목 정리
이 표는 체계적인 학습을 위해 단계별 학습 항목과 중요도를 정리하기 위해 작성되었습니다.
| 카테고리 | Phase | 항목 | 중요도 | 학습 목표 | 실무 연관성 | 설명 |
|---|---|---|---|---|---|---|
| 기초 | 1 | Context Switching 정의 | 필수 | 기본 개념 이해 | 높음 | 멀티태스킹의 근본 원리 |
| 기초 | 1 | PCB 구조와 역할 | 필수 | 상태 저장 메커니즘 | 높음 | 프로세스 관리의 핵심 |
| 핵심 | 2 | 상태 저장/복원 과정 | 필수 | 동작 원리 숙지 | 높음 | 성능 최적화의 기반 |
| 핵심 | 2 | 스케줄링과의 연관성 | 필수 | 시스템 통합 이해 | 높음 | 전체 시스템 관점 |
| 분석 | 3 | 성능 오버헤드 분석 | 권장 | 비용-효과 분석 | 중간 | 설계 의사결정 지원 |
| 분석 | 3 | 트레이드오프 이해 | 권장 | 균형점 찾기 | 중간 | 실무 적용 전략 |
| 구현 | 4 | 모니터링 도구 활용 | 권장 | 실무 스킬 습득 | 높음 | 운영 및 문제 해결 |
| 구현 | 4 | 최적화 기법 적용 | 권장 | 성능 개선 능력 | 높음 | 시스템 튜닝 전문성 |
| 응용 | 5 | 실제 사례 분석 | 권장 | 실무 경험 축적 | 중간 | 아키텍처 설계 역량 |
| 응용 | 5 | 코드 구현 실습 | 선택 | 구현 능력 향상 | 낮음 | 개발자 전용 |
| 운영 | 6 | 보안 고려사항 | 권장 | 보안 인식 제고 | 중간 | 안전한 시스템 운영 |
| 운영 | 6 | 성능 최적화 전략 | 필수 | 최적화 전문성 | 높음 | 시스템 성능 관리 |
| 고급 | 7 | 최신 기술 트렌드 | 선택 | 기술 동향 파악 | 낮음 | 미래 기술 대응 |
| 고급 | 7 | 연구 개발 동향 | 선택 | 전문가 수준 지식 | 낮음 | 기술 리더십 |
용어 정리 표
이 표는 주제의 핵심 용어와 실무 적용 가능성을 정리하기 위해 작성되었습니다.
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | 컨텍스트(Context) | 프로세스 상태 정보 | 레지스터, 프로그램 카운터 | 프로세스 전환 시 저장/복원 |
| 핵심 | 컨텍스트 스위칭(Context Switching) | 상태 저장/복원 통한 프로세스 전환 | 멀티태스킹, 스케줄러 | 서버·클라우드의 효율적 자원 분배 |
| 구현 | PCB(프로세스 제어 블록, Process Control Block) | 프로세스의 모든 상태 정보 저장 구조 | OS 커널 | 실무 서버/컨테이너에 적용 |
| 운영 | 오버헤드(Overhead) | 비효율·추가 자원 소모 | 스케줄링, 모니터링 | 성능 측정 및 최적화 지표 |
용어 보완 및 마무리
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 고급 | Lock-Free 구조 | 동시성 데이터 처리시, Blocking 없이 교환 | CAS, Non-blocking Algorithm | 고성능 서버, 분산시스템 |
| 고급 | Zero-Overhead | 컨텍스트 스위칭시 오버헤드 없는 상태 | 마이크로커널, 하드웨어 가속 | 실시간·고성능 환경 |
| 고급 | Observability | 시스템내 상태 변화를 실시간으로 모니터링·진단 | 모니터링, Metrics, Logging | 장애 대응, 자동화 |
용어 정리
이 표는 Context Switching의 핵심 용어와 실무 적용 가능성을 정리하기 위해 작성되었습니다.
| 카테고리 | 용어 | 정의 | 관련 개념 | 실무 활용 |
|---|---|---|---|---|
| 핵심 | Context Switching | CPU에서 실행 중인 프로세스를 다른 프로세스로 전환하는 과정 | Process, Thread, Scheduling | 성능 분석, 시스템 설계 |
| 핵심 | PCB (Process Control Block) | 프로세스의 상태 정보를 저장하는 자료구조 | Process State, Memory Management | 시스템 프로그래밍, 디버깅 |
| 구현 | Voluntary/Involuntary Switch | 자발적/비자발적 컨텍스트 스위치 구분 | I/O Operations, Timer Interrupt | 성능 튜닝, 모니터링 |
| 구현 | CPU Affinity | 프로세스를 특정 CPU 코어에 바인딩하는 기법 | NUMA, Cache Locality | 성능 최적화, 용량 계획 |
| 운영 | Context Switch Rate | 단위 시간당 컨텍스트 스위치 발생 빈도 | Performance Metrics, Monitoring | 시스템 모니터링, 알람 설정 |
| 운영 | Cache Pollution | 컨텍스트 스위치로 인한 캐시 오염 현상 | Cache Miss, Memory Hierarchy | 성능 분석, 아키텍처 설계 |
| 고급 | eBPF | 확장된 버클리 패킷 필터, 커널 프로그래밍 기술 | Kernel Programming, Observability | 고급 모니터링, 성능 최적화 |
| 고급 | User-Space Scheduling | 사용자 공간에서 수행하는 스케줄링 | Application-specific Scheduling | 고성능 애플리케이션 개발 |
용어 정리
이 표는 주제의 핵심 용어와 실무 적용 가능성을 정리하기 위해 작성되었습니다.
| |
참고 및 출처
- Linux man-pages:
man 7 sched,man 2 sched_setaffinity,man 5 proc - “Linux Kernel Documentation” (Scheduler/CFS, CPU affinity, NUMA)
- Brendan Gregg, Systems Performance (eBPF, runqlat/offcputime)
- Microsoft Docs – Windows Scheduling/Context Switching
- IBM Developer/Red Hat docs – NUMA, CPU pinning, cgroups v2
- Kubernetes Docs – CPU Manager, QoS Classes, Resource Management
참고 및 출처
- Linux Kernel Documentation - Process Management
- Intel 64 and IA-32 Architectures Software Developer Manual
- PostgreSQL Documentation - Process Architecture
- eBPF Documentation
- Google Research - ghOSt: Fast & Flexible User-Space Delegation of Linux Scheduling
- Performance Analysis and Tuning of Linux System
참고 및 출처
- GeeksforGeeks - Context Switching in Operating System[1]
- Wikipedia - Context switch[2]
- TutorialsPoint - Operating System Context Switching[4]
- Netdata Blog - Understanding Context Switching[7]
- OSDev Wiki - Context Switching[8]
- TechTarget - What is context switch?[3]
좋습니다. Phase 1 → Phase 7까지 한 번에 완성본으로 정리합니다. 문제/현상형(C)에 맞춰 “장점” 대신 예방·해결 관점을 강화했고, 각 Phase 끝에 검증 포인트를 넣어 단계별로 점검할 수 있게 구성했습니다.
10. 마무리 표준 형식
필요하시면 위 실습 코드를 **자동 스크립트(벤치 + 수집 + 리포트)**로 묶어드리거나, 여러분의 환경(온프레/클라우드, Linux 배포판, K8s 버전)에 맞춘 운영 대시보드(프로메테우스/그라파나 패널) 구성을 제공하겠습니다.
Context Switching 은 운영 체제에서 매우 중요한 개념으로, 여러 프로세스나 스레드가 단일 CPU 자원을 공유하여 효율적으로 실행될 수 있게 하는 메커니즘이다.
Context Switching 은 CPU 가 현재 실행 중인 프로세스나 스레드의 상태를 저장하고, 다른 프로세스나 스레드의 상태를 불러와 실행을 재개하는 과정을 말한다.
이를 통해 여러 작업이 동시에 실행되는 것처럼 보이게 된다.
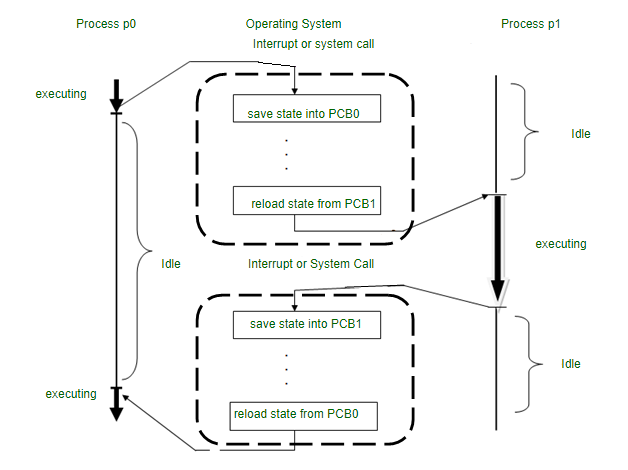
Context Switching 의 필요성
- 멀티태스킹: 여러 프로세스가 동시에 실행되는 것처럼 보이게 하여 시스템 효율성을 높인다.
- 인터럽트 처리: 하드웨어 인터럽트나 시스템 호출 등에 신속하게 대응할 수 있다.
- 자원 공유: 단일 CPU 로 여러 프로세스를 실행할 수 있게 한다.
Context Switching 의 과정
- 현재 실행 중인 프로세스의 상태 저장: CPU 레지스터, 프로그램 카운터 등의 정보를 PCB(Process Control Block) 에 저장한다.
- 새로운 프로세스 선택: 스케줄러가 다음에 실행할 프로세스를 선택한다.
- 새 프로세스의 상태 복원: 선택된 프로세스의 PCB 에서 상태 정보를 불러와 CPU 레지스터에 복원한다.
- 실행 재개: 새 프로세스의 실행을 시작한다.
Context Switching 의 트리거
- 인터럽트: 하드웨어나 소프트웨어에서 발생하는 인터럽트.
- 시간 할당 종료: 프로세스에 할당된 CPU 시간이 끝났을 때.
- I/O 요청: 프로세스가 I/O 작업을 요청하여 대기 상태로 전환될 때.
- 우선순위: 더 높은 우선순위의 프로세스가 실행 준비될 때.
Context Switching 의 구현 방식
- 하드웨어 스위칭: 프로세서 코어에 내장된 태스크 상태 세그먼트 (TSS) 를 사용한다.
- 소프트웨어 스위칭: 운영 체제의 커널 루틴과 데이터 구조를 사용하여 구현한다. 더 빠르고 일관성 있는 방식이다.
Context Switching 의 장단점
장점:
- 멀티태스킹 지원: 여러 프로세스를 동시에 실행하는 것처럼 보이게 한다.
- 자원 활용 최적화: CPU 사용을 최적화하여 시스템 효율성을 높인다.
단점:
- 오버헤드: Context Switching 자체가 CPU 시간을 소모한다.
- 캐시 미스: 프로세스 전환 시 캐시 데이터가 무효화될 수 있다.
- 지연 시간: 빈번한 Context Switching 은 전체적인 시스템 성능을 저하시킬 수 있다.
Context Switching 최적화
- 프로세스 우선순위 조정: 중요한 프로세스에 더 높은 우선순위 부여.
- 스레드 사용: 프로세스 내 스레드 사용으로 Context Switching 비용 감소.
- 인터럽트 처리 최적화: 효율적인 인터럽트 처리로 불필요한 Context Switching 감소.
- 캐시 최적화: 캐시 친화적인 데이터 구조와 알고리즘 사용.